
ASP.NET C# 搜索引擎(高亮显示、JSON、jQuery & Silverlight)
更专业的 ASP.NET C# 搜索,提供完善的文档摘要、查询高亮和 RIA 显示选项

背景
本文是紧接前面的六个 Searcharoo 示例的延续
Searcharoo 1 是一个简单的搜索引擎,它抓取文件系统。非常粗糙。
Searcharoo 2 添加了一个“爬虫”来索引网页链接,然后进行多词搜索。
Searcharoo 3 保存目录以便需要时重新加载;抓取了 FRAMESETs 并添加了停用词、启用词和词干提取。
Searcharoo 4 添加了非文本文件类型(例如 Word、PDF 和 Powerpoint)、更好的robots.txt 支持以及远程索引控制台应用程序。
Searcharoo 5 在 Medium Trust 环境下运行,并将 FilterDocument 重构为 DownloadDocument 及其子类,用于索引 Office 2007 文件。
Searcharoo 6 添加了照片/图像和地理坐标的索引;并在地图上显示搜索结果。
版本 7 简介
已进行以下添加:
- 存储每个索引文档的全部“内容”,以便结果页面可以显示文本摘录并高亮显示搜索关键字。
- 使用 iTextSharp 增强了 PDF 索引,以便从元数据中提取文档标题,而不是仅在结果中显示文件名,并且即使
IFilter失败(可能由于 Acrobat 安装问题),也尝试“手动”索引 PDF 文件。 - 正确处理“默认文档”设置,以防止在“页面”具有多个可访问 URL 时出现重复结果,因为该页面被配置为 Web 服务器上的“默认文档”(例如,IIS 中的default.htm或default.aspx;或许多 UNIX 服务器中的index.html)。
- 添加一个JSON结果“服务”(类似于6.0版中的 Kml 输出)
- 添加一个jQuery驱动的 AJAX/HTML 页面,该页面使用 JSON 提供漂亮、易于自定义的结果页面
- 添加一个Silverlight 2.0 客户端,该客户端使用 JSON 提供更丰富的搜索体验
- 错误修复包括:
- brad1213 发现(并修复)了一个 bug,即 HTML 注释中的链接仍然被跟随
- brad1213 建议的修复方法是,在 URL 重定向后将其添加到“已访问”集合中。
在索引期间存储完整的文档文本
早在 2008 年 10 月,SMeledath 询问结果中显示的描述如何能从页面本身获取……我提出了一个方法但当时没有时间实现——直到现在。
在 Searcharoo 的早期版本中,索引只包含每个单词与包含该单词的文档 URL 之间的“链接”。该单词出现的次数或该单词出现的位置在索引过程中会丢失(请参阅5.0版了解旧目录结构的讨论)。这使得无法在结果页面上显示“摘录”,因为索引只存储前 350 个字符(或 META description 标签)——主要是因为它更容易编程。
版本 7 显著改变了索引的“结构”以存储更多数据:对于每个单词-文档对,我们还存储该单词在源文档中的位置。例如:在解析完标点符号和空格后,每个单词都被分配一个索引,第一个单词的位置为零,后续每个单词的位置加一。我们还存储文档的完整文本,因此可以提取文本的任何部分。
旧的和新的目录序列化文件(默认名称为z_searcharoo.xml)之间的主要区别在于:

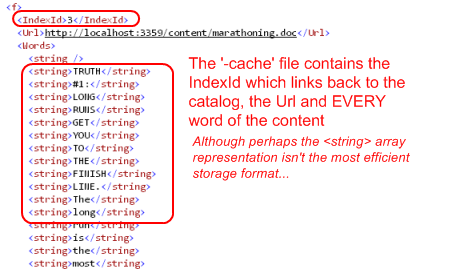
但是,还有更多——有一个新的文件名为z_searcharoo-cache.xml,其中包含每个文档的完整文本(包括标点符号),这将使我们能够在结果页面上显示文档文本的任何部分。
高亮显示结果中的匹配项
大部分代码会忽略z_searcharoo-cache.xml文件,因为它不是执行实际搜索所必需的。只有在Search.cs的 GetResults() 方法中,在结果列表已经构建完毕后,才会使用缓存来生成带有高亮关键字的文档“描述”。

加载缓存中的文件内容(到一个数组)后,我们使用一些巧妙的定位来循环遍历它,找到内容中的*第一个*匹配单词,抓取它周围约 100 个单词,然后循环遍历这 100 个单词并高亮显示*所有*匹配项。

如果听起来像个 hack:它确实(有点)。Google 的结果通常会识别文档中出现匹配项的多个部分,并显示多个(用省略号...分隔)——但我将把它留给未来的版本(或者让别人尝试)……

增强的 PDF 索引
CodeProject 用户 inspire90 询问了如何在搜索结果中显示 PDF“标题”,但我当时并没有立即找到解决方案。另一位用户 brad1213 提供了一个使用 iTextSharp 的有效代码片段。brad1213 的代码直接添加到了Spider.cs中。
将此行为纳入对象模型需要对 PDF 索引过程进行一些重构,以便 PDF 文档的处理方式与其他需要IFilter接口的文件类型略有不同。以前,爬虫过程没有区分 PDF 和任何其他它无法“原生解析”的文件——它只是将处理交给IFilterDocument.cs类。
版本 7 现在有一个PdfDocument,它继承自FilterDocument,这样我们就可以在GetResponse方法中添加 iTextSharp 解析。

但是,这个新子类有一个小问题——FilterDocument的设计并不适合扩展……FilterDocument.GetResponse()方法将*所有内容*都紧密耦合在一起了!

我真不敢相信我写了那个!要继承这个类,基本上需要从头开始重新实现GetResponse,因为没有任何“钩子”来帮助实现者“继承”任何行为。我确定有更好的方法,但我选择将大部分“功能”转移到几个*核心方法中……

……这样PdfDocument就可以*使用它们*,但在中间进行额外的iTextSharp处理(使用最初仅用于传递给IFilter的临时文件)。

虽然不是完美的,但重构后的代码*确实*允许子类利用FilterDocument的代码来下载和保存文件的临时副本(之后再删除),同时仍然执行自己的操作(使用iTextSharp)。我很有信心存在一个更好的模式来处理这种类关系——如果我找到它,我会更新文章。
“默认”文档处理
Patrick Stuart 询问了一个关于他遇到的“重复”结果的问题——结果发现是/default.aspx(或者你的“默认”是什么)被索引了多次(例如,当 URL 以“*/*”或“*/default.aspx*”结尾时)。
为了解决这个问题,我们添加了额外的代码来操作“已访问”列表——当一个 URL 匹配“默认文档”模式之一时,我们将*所有可能的“默认文档”组合添加到_Visited集合中。处理的三个模式是:
- http://searcharoo.net/SearcharooV7/ - 末尾带斜杠的默认页面
- http://searcharoo.net/SearcharooV7 - 末尾不带斜杠的默认页面或未指定页面名称
- http://searcharoo.net/SearcharooV7/default.aspx - 指定了默认页面(Searcharoo 配置中设置为“default.aspx”)
随着索引的进行,任何 URL 的变体都会被标记为“已访问”,从而防止目录(和结果)中出现重复。
更新后的代码如下(注意三种不同的“条件”,其中不同的 URL 可能指向同一个“默认”页面):

在app.config中为Indexer.exe设置网站的默认文档,以便正确解析它们。
<!-- Default document filename: served in folder roots [v7] -->
<add key="Searcharoo_DefaultDocument" value="default.aspx" />
未来的/进一步的增强可以是让代码自动检测任何具有*完全相同内容*的其他页面的情况,并进行自动去重……但就目前而言,这个 URL 比较似乎解决了最常见的 bug。
JSON 结果“服务”
我看到了这篇关于支持 Silverlight 的 Live Search 的文章,并决定尝试以同样的方式启用 Searcharoo。与文章不同的是,我决定尝试使用JSON,这样我也可以构建一个jQuery前端。
JSON(或JavaScript 对象表示法)是一种使用纯 JavaScript“对象字面量”表示数据的机制(例如序列化的对象图):它看起来像简单的键值对集合(带有嵌套和分组在[]中的“集合”)。将常规结果页面使用的ResultFile类转换为 JSON 如下所示:
[
{"name":"CIA - The World Factbook -- United Kingdom"
,"description":"Tower Hamlets**, Trafford, Wakefield***
, Walsall, Waltham Forest**, Wandsworth**, Warrington
, Warwickshire*, West Berkshire****, Westminster***
, West Sussex*, Wigan, Wiltshire*, Windsor and Maidenhead******
, Wirral, Wokingham****, Wolverhampton, Worcestershire*
, strongYork*****; strongNorthern Ireland - 24 districts
, 2 cities*, 6 counties**; Antrim, County Antrim**
, Ards, Armagh, County Armagh**, Ballymena, Ballymoney
, Banbridge, Belfast*, Carrickfergus, Castlereagh, Coleraine, "
,"url":"https://:3359/content/uk.html"
,"tags":""
,"size":"57299"
,"date":"10/18/2008 3:02:49 PM"
,"rank":6
,"gps":"0,0"
},
{"name":"kilimanjaro"
,"description":"to pay US$40 Departure tax.
Check with your travel agent. Tanzania - Australian passport holders US$50
, British passport holders US$50, Canadian passport holders US$50
, strongNew strongZealand passport holder US$50
Medical Information and Vaccinations: Vaccinations:
You must have an International Certificate of Yellow Fever
Vaccination if crossing borders within "
,"url":"https://:3359/content/kilimanjaro.pdf"
,"tags":""
,"size":"182794"
,"date":"10/18/2008 3:01:53 PM"
,"rank":2
,"gps":"0,0"
}]
为了*创建*此输出,我们可以使用与 6.0 版中的 KML 输出相同的SearchPageBase基类——创建 JSON 输出很简单,只需修改 ASPX 标记,用 {} 和 "" 代替 XML。

jQuery JSON “客户端”
鉴于 JSON 输出(可以通过简单 URL 访问,例如/SearchJson/New%20York.js或/SearchJson.aspx?searchfor=New%20York),我们现在可以非常简单地使用 JavaScript 或优秀的jQuery库(现在“支持”于微软)来*访问*结果。下面的 HTML 页面可以使用 JSON(使用 jQuery):有一个文本输入框和按钮,可以捕获搜索词并构建 URL,jQuery 的$.getJSON()方法检索数据,将其评估为对象,其余代码将 HTML 输出到页面上的div中。

下面的结果可能*看起来*与“标准”ASPX 页面相似——但正如你在上面的 HTML 中看到的,该页面几乎完全由 jQuery 使用 JSON 结果生成。在下载的Web.UI项目中查找jSearcharoo.html文件。

Silverlight 2.0 JSON “客户端”
JSON“服务”也可以为 Silverlight 2.0 应用程序提供结果,使用MSDN上描述的JsonArray和JsonObject类。首先,我们将使用一个简单的Grid和一个TextBox、Button和ListBox来包含结果,设计一个简单的 XAML 用户界面。我们将把一个类绑定到ListBox,该类看起来*非常相似(如果不是完全相同)*到上面的 JSON 格式,因此ListBox.ItemTemplate DataTemplate由StackPanel中的简单控件组成,这些控件与相同的字段名(url、name、description)进行数据绑定。

下面的 C# 代码显示了这一点。重要的元素是:
- 构造带有查询文本的 JSON URL
- 使用
WebClient启动对结果的异步请求 - 使用
JsonArray解析 JSON 并循环遍历数组以填充我们的SearchResult对象 - 通过
ItemsSource将SearchResults“绑定”到 UI——DataTemplate负责格式化。
(注意:你需要手动**添加引用**到System.Json、System.Runtime.Serialization、System.Runtime.Serialization.Json。)
/// <summary>
/// Start async request for JSON
/// http://msdn.microsoft.com/en-us/library/cc197953(VS.95).aspx
/// </summary>
private void Search_Click(object sender, RoutedEventArgs e)
{
string host = Application.Current.Host.Source.Host;
if (Application.Current.Host.Source.Port != 80)
host = host + ":" + Application.Current.Host.Source.Port;
//host = "localhost:3359";
Uri serviceUri = new Uri("http://"+host+"/SearchJson.aspx?searchfor=" + query.Text);
WebClient downloader = new WebClient();
downloader.OpenReadCompleted +=
new OpenReadCompletedEventHandler(downloader_OpenReadCompleted);
downloader.OpenReadAsync(serviceUri);
}
/// <summary>
/// Receive JSON stream, parse into objects and bind to ListBox
/// http://msdn.microsoft.com/en-us/library/cc197957(VS.95).aspx
/// </summary>
void downloader_OpenReadCompleted(object sender, OpenReadCompletedEventArgs e)
{
if (e.Error == null)
{
using (Stream responseStream = e.Result)
{
JsonArray resultStream = (JsonArray)JsonArray.Load(responseStream);
var results = from result in resultStream
select result;
List<SearchResult> list = new List<SearchResult>();
foreach (JsonObject r in results)
{
var result = new SearchResult
{
name = r["name"] ,description = r["description"]
,url = r["url"],size = r["size"],date = r["date"]
};
list.Add(result);
}
resultList.ItemsSource = list;
}
}
}
这就是最终的 Silverlight 2.0 应用程序的外观(搜索“dollar”结果显示)。因为我们使用了 Silverlight 的HyperlinkButton,所以文档标题是可点击的链接,指向搜索结果页面。

Silverlight 2.0 项目是一个单独的下载,可以使用Visual Web Developer 2008 Express打开(其余的 Searcharoo 代码仍然是 .NET 2.0,可以在 Visual Studio 或 Express 2005 中打开)。在下载的Web.UI项目中查找Silverlight.html和Silverlightaroo.XAP文件。
Bug 修复
页面重定向时可能出现重复索引
brad1213(他曾几次为 Searcharoo 做出贡献)帮助解决了与上面讨论的 _Visited 处理相关的另一个“错误情况”——当一个页面重定向到另一个位置时,会索引生成的 HTML,但*只有“原始”URL 被标记为“已访问”(可能导致目录中出现重复)。他的解决方案是简单地将 URL 添加到 _Visited 列表*之后*才能跟踪重定向。
跟随 HTML 中被注释掉的链接
brad1213 还找出了解(HTML 注释内的链接,即<!-- -->中的链接)这个应该被忽略的问题的解决方案。修复方法是在 HtmlDocument(第 295 行)中添加这个正则表达式替换:
htmlData = Regex.Replace(htmlData , @"<!--.*?[^" +
Preferences.IgnoreRegionTagNoIndex + "]-->" , "" ,
RegexOptions.IgnoreCase | RegexOptions.Singleline);
代理对错误(PDF 索引)
会员 4130814 报告了一个在索引 PDF 后序列化目录时出现的错误。我能够重现它,并且(我认为)通过这个简单的语句来从string中删除“null”来修复它。
this.All += sb.ToString().Replace('\0', ' ');
我不太确定为什么那些null会悄悄地进入到搜索的文本中。
结论
本文混合了“请求的功能”(关键字高亮显示、重复项删除)和“新玩具”(JSON、jQuery 和 Silverlight)。你可以在网上了解更多关于 jQuery 的知识,以及为什么 JSON 是 XML 的替代方案。
更新
- 09-03-09:ZIP 下载已更新,部分原因是此Zip/Xap 问题,并更新了Silverlight和jQuery代码。