
多语言语法高亮,第一部分:JScript
4.96/5 (54投票s)
2003年2月13日
12分钟阅读
295790
6125
使网页上的源代码自动高亮成为现实(支持 C、C++、JScript、VBScript、XML)

Outline
这是2篇系列文章的第一篇。在本文中,我们讨论了技术和思想,并提供了一个 Javascript 解决方案。在第二部分中,将提供一个 C# 解决方案。
不幸的是,对于 JScript 用户,我将不更新 JScript 代码,而只专注于 C#。:)
引言
你是否曾想过 CP 团队是如何在其编辑的文章中高亮源代码的?我猜不是手工完成的,他们一定有一些巧妙的代码来实现这一点。
然而,如果你环顾网络上的论坛,你会发现很少有人拥有此功能,甚至几乎没有。这很可惜,因为有颜色的源代码更容易阅读。事实上,如果在论坛中能自动根据你喜欢的着色方案为源代码着色,那就太棒了。
编写本文的最后一个(但同样重要)原因是想在一个项目中学习正则表达式、javascript 和 DOM。
源代码完全用 JScript 编写,因此它可以包含在服务器端或客户端的网页中。
使用的技术包括:
- 正则表达式
- XML DOM
- XSL 转换
- CSS 样式
在阅读本文时,我将假设你对正则表达式、DOM 和 XSLT 的了解不多,尽管我在这三个领域也是新手。
实时演示
CP 不允许在文章中使用script 或 form 标签。要体验实时演示,请下载支持“JScript”的页面(请参阅下载部分)。转换概述
 |
| 解析管道 |
所有方框将在下一章中详细讨论。我将在这里简要概述该过程。
首先,会加载一个语言语法规范文件(语言规范框)。此规范是一个由用户提供的纯 xml 文件。为了加快速度,会对该文档进行预处理(预处理框)。
为简单起见,我们假设我们有要着色的源代码(代码框)。请注意,稍后我将展示如何将着色应用于整个 HTML 页面。解析器使用预处理过的语法文档,构建一个表示已解析代码的 XML 文档(解析框)。解析器使用的技术是将代码分割成一系列不同类型的节点:关键字、注释、字面量等。
最后,将应用 XSLT 转换到已解析的代码文档,将其渲染为 HTML,并提供 CSS 样式以匹配所需的显示效果。
解析过程
构建解析器的理念受 Kate 文档(参见 [1])的启发。
代码被视为一系列上下文。例如,在 C++ 中:
- 关键字:if、else、while 等...
- 预处理指令:#ifdef、...
- 字面量: "..."
- 行注释:// ...
- 块注释:/* ... */
- 以及其他。
对于每个上下文,我们定义了规则,这些规则具有 3 个属性:
- 用于匹配字符串的正则表达式
- 规则匹配文本的上下文:属性
- 规则之后文本的上下文:上下文
规则之间具有优先级。例如,我们会先查找 /* ... */ 注释,然后是 // ... 行注释,然后是字面量,等等。
当使用正则表达式匹配规则时,匹配字符串将被赋予属性上下文,当前上下文将被更新为上下文,并继续解析。图表显示了上下文之间的可能路径。可以看到,有些规则不会导致需要上下文。
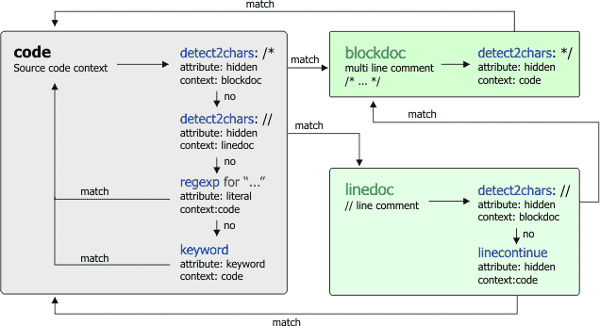
| |
| 上下文动态 |
让我稍微解释一下下面的图表。假设我们处于 code 上下文中。我们将查找代码规则的第一个匹配项:/**/, //, "...", keyword。此外,我们必须考虑到它们的优先级:关键字在注释块中实际上不是关键字,因此优先级较低。这项任务通过正则表达式可以轻松自然地完成。
一旦找到匹配项,我们就查找触发该匹配的规则(始终遵循规则的优先级)。因此,像这样的病态情况可以得到很好的解析。
// a keyword while in a comment由于在注释中,while 不被视为关键字。
可用规则
目前有 5 种可用规则:
- detect2chars:检测由 2 个字符组成的模式。
- detectchar: 检测由 1 个字符组成的模式。
- linecontinue: 检测行尾
- keyword: 检测关键字系列中的关键字
- regexp: 匹配正则表达式。
regexp 是迄今为止最强大的规则,因为所有其他规则在内部都用正则表达式表示。
语言规范
根据上述规则和上下文,我们派生了一个 XML 结构,如下面的 XSD 模式所示(我不太懂 xsd,但 .Net 生成了这个漂亮的图表...)
 |
| 语言规范模式。单击图像查看完整尺寸。 |
我将在本文中简要讨论语言规范文件。有关更多详细信息,请查看 xsd 模式或 highlight.xml 规范文件(针对 C++)。基本上,您必须定义关键字系列,选择上下文并编写规则以在它们之间进行转换。
节点
| 名称 | 类型 | 父节点 | 描述 |
| highlight | 根 | none |
根节点 |
| needs-build | 一个(可选) | highlight | 如果文件需要预处理,则为“yes” |
| save-build | 一个(可选***) | highlight | 如果文件在预处理后需要保存,则为“yes” |
| keywordlists | E | highlight | 包含关键字系列的子节点的节点 |
| keywordlist | E | keywordlist | 一个关键字系列 |
| id | A | keywordlist | 字符串标识符 |
| pre | 一个(可选) | keywordlist | 关键字前面的正则表达式 |
| post | 一个(可选) | keywordlist | 关键字末尾的正则表达式 |
| regexp | 一个(可选*) | keywordlist | 匹配关键字系列的正则表达式。由预处理器构建 |
| kw | E | keywordlist | 包含关键字的文本或 CDATA 节点 |
| languages | E | highlight | 包含语言作为子节点的节点 |
| language | E | languages | 语言规范 |
| contexts | E | language | 上下文节点的集合 |
| 默认 | A | contexts | 标识默认上下文的字符串 |
| context | E | contexts | 包含规则作为子节点的上下文节点 |
| id | A | context | 字符串标识符 |
| attribute | A | context | 上下文将存储在其中的节点名称。 |
| detect2chars** | E | context | 检测字符对的规则。(例如:/*) |
| char | A | detect2chars | 模式的第一个字符 |
| char1 | A | detect2chars | 模式的第二个字符 |
| detectchar** | E | context | 检测一个字符的规则。(例如:") |
| char | A | detectchar | 要匹配的字符 |
| keyword** | E | context | 匹配关键字系列的规则 |
| family | A | keyword | 系列标识符,必须与 /highlight/keywordlists/keyword[@id] 匹配 |
| regexp | E | context | 用于匹配的正则表达式 |
| expression | A | regexp | 正则表达式。 |
- *: 此参数是可选的,前提是进行预处理。通常的做法是始终进行预处理,或者进行一次预处理并将“save-build”参数设置为“yes”,以便保存预处理结果。请注意,如果修改了语言语法,则必须重新预处理。
- **: 所有这些元素都有另外两个属性:
attribute (optional) A a rule 将存储匹配字符串的节点名称。如果未设置或等于“hidden”,则不创建节点。 context A a rule 下一个上下文。 - ***: 客户端 Javascript 不允许写入文件。因此,此选项仅适用于服务器端执行。
预处理
在预处理阶段,我们将构建稍后用于匹配规则的正则表达式。本节大量使用了正则表达式。如前所述,这不是一个正则表达式教程,因为我也是这个主题的新手。我发现一个非常有用的工具是Expresso(参见 [3]),一个正则表达式测试机。关键字系列
构建关键字系列的正则表达式很简单。你只需要使用|将关键字连接起来。<keywordlist ...>
<kw>if</kw>
<kw>else</kw>
</keywordlist>将被匹配\b(if|else)\b
生成的正则表达式将作为属性添加到 keywordlist 节点。
<keywordlist regexp="\b(if|else)\b">
<kw>if</kw>
<kw>else</kw>
</keywordlist>
当使用函数库时,通常会有通用的函数头,例如 OpenGL。
glVertex2f, glPushMatrix(), etc...
您可以使用 pre 属性(它接受一个正则表达式作为参数)来跳过重写所有 kw 项中的 gl 的麻烦。<keywordlist pre="gl" ...>
<kw>Vertex2f</kw>
<kw>PushMatrix</kw>
</keywordlist>将被匹配\bgl(Vertex2f|PushMatrix)\b您也可以使用 post 在关键字后添加正则表达式。以我们的 OpenGL 示例为例,有些方法在末尾带有字符来指示参数类型:glCoord2f:接受 2 个浮点数,glRaster3f:接受 3 个浮点数,glVertex4v:接受一个大小为 4 的浮点数数组。
post 和正则表达式,我们可以轻松匹配它。<keywordlist pre="gl" post="[2-4]{1}(f|v){1}" ...>
<kw>Vertex</kw>
<kw>Raster</kw>
</keywordlist>将被匹配\bgl(Vertex2f|PushMatrix)[2-4]{1}(f|v){1}\b
字符串字面量
这是一个关于正则表达式的小练习:如何在 C++ 中匹配字面字符串?请记住,它必须支持 \",以及行尾的 \。
我的答案(记住我还是新手)是:
"(.|\\"|\\\r\n)*?((\\\\)+"|[^\\]{1}")我在以下字符串上测试了这个表达式:"a simple string"
---
"a less \" simple string"
---
"a even less simple string \\"
---
"a double line\
string"
---
"a double line string does not work without
backslash"
---
"Mixing" string "can\"" become "tricky"
---
"Mixing \" nasty" string is \" even worst"
上下文
上下文正则表达式也是通过连接规则的正则表达式来构建的。该值将作为属性添加到 context 节点。
<context regexp="(...|...)">
控制预处理是否必要
可以通过在根节点 highlight 中指定以下参数来跳过预处理阶段或保存“预处理过的”语言规范文件:| Attribute | 描述 | 默认值 |
| need-build | 如果需要预处理,则为“yes” | 是 |
| save-build | 如果将预处理过的语言规范保存到磁盘,则为“yes” | 否 |
Javascript 调用
预处理阶段是通过 Javascript 方法 loadAndBuildSyntax 完成的。
// language specification file
var sXMLSyntax = "highlight.xml";
// loading is done by loadXML
// preprocessing is done in loadAnd... It returns a DOMDocument
var xmlDoc = loadAndBuildSyntax( loadXML( sXMLSyntax ) );
解析
我们将使用上面的语言语法来构建一个源 XML 树。这个树将由一系列上下文节点组成。我们可以开始解析字符串(伪代码如下):
source = source code;
context = code; // current context
regExp = context.regexp; // regular expresion of the current context
while( source.length > 0)
{
在这里我们遵循这个过程:- 找到上下文规则的第一个匹配项
- 存储匹配前的源代码
- 找到匹配的规则
- 处理规则参数
match = regExp.execute( source );
// check if the rules matched something
if( !match)
{
// no match, creating node with the remaining source and finishing.
addChildNode( context // name of the node,
source // content of the node);
break;
}
else
{
匹配前的源代码必须存储在一个新节点中。 addChildNode( context, source before match);
我们现在需要找到匹配的规则。这是通过方法 findRule 完成的,该方法返回规则节点。然后使用属性和上下文参数处理规则。
// getting new node
ruleNode = findRule( match );
// testing if matching string has to be stored
// if yes, adding
if (ruleNode.attribute != "hidden")
addChildNode( attribute, match);
// getting new context
context=ruleNode.context;
// getting new relar expression
regExp=context.regexp;
}
}
在此方法结束时,我们构建了一个包含上下文的 XML 树。例如,考虑经典的“Hello world”程序如下:
int main(int argc, char* argv[])
{
// my first program
cout<<"Hello world";
return -1;
};
这个示例被翻译成以下 XML 结构:<parsedcode lang="cpp" in-box="-1">
<reservedkeyword>int</reservedkeyword>
<code> main(</code>
<reservedkeyword>int</reservedkeyword>
<code> argc, ></code>
<reservedkeyword>char</reservedkeyword>
<code> * argv[])
{
</code>
...
这是结果 XML 文件的规范:| 节点名称 | 类型 | 父节点 | 描述 |
| parsedcode | 根 | 文档的根节点 | |
| lang | A | parsedcode | 语言类型:c、cpp、jscript 等。 |
| in-box | A | parsedcode | -1 表示应将其包含在 pre 标签中,否则包含在 code 标签中。 |
| code | E | parsedcode | 非特殊源代码 |
| 等等…… | E | parsedcode |
Javascript 调用
上述算法在 applyRules 方法中实现。
applyRules( languageNode, contextNode, sCode, parsedCodeNode);
其中
languageNode是当前语言节点 (XMLDOMNode),contextNode是起始上下文节点 (XMLDOMNode),sCode是源代码 (String),parsedCodeNode是已解析代码的父节点 (XMLDOMNode)
XSLT 转换
一旦有了代码的 XML 表示,您就可以使用 XSLT 转换对其进行任何操作。
标题
每个 XSL 文件都以一些声明和其他标准选项开头。
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:output encoding="ISO-8859-1" indent="no" omit-xml-declaration="yes"/>
由于必须保留源代码缩进,我们禁用了自动缩进,并且还省略了 xml 声明。
<xsl:output encoding="ISO-8859-1" indent="no" omit-xml-declaration="yes"/>
基本模板
<xsl:template match="cpp-linecomment">
<span class="cpp-comment">//<xsl:value-of select="text()"
disable-output-escaping="yes" /></span>
</xsl:template>
此模板应用于节点 cpp-linecomment,它对应于 C++ 中的单行注释。
我们将 CSS 样式应用于此节点,方法是将其封装在 span 标签中,并指定 CSS 类。
此外,我们不希望对此进行字符转义,因此我们使用:
<xsl:value-of select="text()" disable-output-escaping="yes" /></span>
Parsedcode 模板
这里会变得有点复杂。众所周知,当您想要创建更高级的样式表时,XSL 会很快变得非常复杂。下面是 parsedcode 的模板,它做的事情很简单但看起来很丑:
检查 in-box 参数是否为 true,如果为 true,则创建 pre 标签,否则创建 code 标签。
<xsl:template match="parsedcode">
<xsl:choose>
<xsl:when test="@in-box[.=0]">
<xsl:element name="span">
<xsl:attribute name="class">cpp-inline</xsl:attribute>
<xsl:attribute name="lang">
<xsl:value-of select="@lang"/>
</xsl:attribute>
<xsl:apply-templates/>
</xsl:element>
</xsl:when>
<xsl:otherwise>
<xsl:element name="pre">
<xsl:attribute name="class">cpp-pre</xsl:attribute>
<xsl:attribute name="lang">
<xsl:value-of select="@lang"/>
</xsl:attribute>
<xsl:apply-templates/>
</xsl:element>
</xsl:otherwise>
</xsl:choose>
</xsl:template>
Javascript 调用
这是您必须稍微自定义方法的地方。渲染是在 highlightCode 方法中完成的。
highlightCode( sLang, sRootTag, bInBox, sCode)其中
sLang是标识语言的字符串(C++ 为 "cpp"),sRootTag将是封装代码的节点名称。例如,对于带框的代码是pre,对于内联代码是code,bInCode是一个布尔值,如果in-box需要设置为 true,则为 true。sCode是源代码。- 它返回修改后的代码。
文件名硬编码在 highlightCode 方法中:语言规范是 hightlight.xml,样式表是 highlight.xsl。在文章中,XML 语法嵌入在 xml 标签中,并且可以通过 id 简单访问。
将代码转换应用于整个 HTML 页面。
那么现在您可能想知道如何将此转换应用于整个 HTML 页面?嗯,令人惊讶的是,这可以...2行完成!事实上,有一个方法 String::replace(regExp, replace),它可以将与正则表达式 regExp 匹配的子字符串替换为 replace。故事中最好的部分是 replace 可以是一个函数……所以我们只需要(几乎)传递 highlightCode 就完成了。
例如,我们想匹配包含在 pre 标签中的代码。
// this is javascript
var regExp=/<pre>(.|\n)*?<\/pre>/gim;
// render xml
var sValue = sValue.replace( regExp,
function( $0 )
{
return highlightCode("cpp", "cpp",$0.substring( 5, $0.length-6 ));
}
);
实际上,会进行一些语言名称的检查,所有这些计算都隐藏在 replaceCode 方法中。
在您的网站中使用这些方法
ASP 页面
要在您的 ASP 网站中使用高亮方案:- 将 Javascript 代码放在 asp 页面中的 script 标签之间。
<script language="javascript" runat="server"> ... </script>
- 在需要的地方包含此页面。
- 修改
processAndHighlightCode方法以满足您的需求。 - 修改 handleException 方法以将异常重定向到 Response。
- 将此方法应用于您要修改的 HTML 代码。
- 使用相应的类更新您的
css样式。
演示应用程序
演示应用程序是CodeProject Article Helper的一个修改版本。在 pre 或 code 中输入代码即可看到结果。
更新历史
| 日期 | 描述 |
|---|---|
| 02-20-2002 |
|
| 02-17-2002 | 样式表中的小改动。 |
| 02-14-2003 |
|
| 02-13-2003 | 初始发布。 |
参考文献
| [1] | Kate 语法高亮系统文档文件。 |
| [2] | Code Project Article Helper,Jason Henderson |
| [3] | Expresso - 构建和测试正则表达式的工具,Hollenhorst |
| [4] | 文章第二部分 |