
RaptorDB - 文档存储
4.96/5 (272投票s)
NoSql、基于JSON的文档存储数据库,具有编译后的.net映射函数、自动混合位图索引和LINQ查询过滤器(现支持独立服务器模式、备份和主动恢复、事务、服务器端查询、MonoDroid支持、HQ-Branch复制、Linux上的运行、.net
 | 文档存储数据库引擎 |
前言
RaptorDB 的代码在github上 https://github.com/mgholam/RaptorDB-Document,我将积极维护并为此项目添加功能,因为我对此深信不疑。我将使本文档和源代码保持同步。
RaptorDB 也在 nuget 上:PM> Install-Package RaptorDB_doc
引言
本文档是我关于持久化字典的上一篇文章的自然延续,它现在是一个功能齐全的NoSql文档存储数据库。虽然键值存储很有用,但它不像“真正的”数据库那样对每个人都有用,这些数据库具有“列”和“表”。RaptorDB 使用了以下文章中的技术
fastJSON:JSON对象序列化和反序列化器,可在以下位置找到(https://codeproject.org.cn/Articles/159450/fastJSON)fastBinaryJSON:二进制格式JSON序列化器,可在以下位置找到(https://codeproject.org.cn/Articles/345070/fastBinaryJSON)miniLog4net:一个mini log4net替代品,可在以下位置找到(https://codeproject.org.cn/Articles/136118/Mini-Drop-in-Replacement-for-log4net)WAHBitArray:用于BitArrays的字对齐混合压缩技术,可在以下位置找到(https://codeproject.org.cn/Articles/214997/Word-Aligned-Hybrid-WAH-Compression-for-BitArrays)hOOt:全文搜索引擎,可在以下位置找到(https://codeproject.org.cn/Articles/224722/hOOt-full-text-search-engine)RaptorDB 键值存储:使用MGIndex进行索引,可在以下位置找到(https://codeproject.org.cn/Articles/316816/RaptorDB-The-Key-Value-Store-V2)
RaptorDB 在混合位图索引方面进行了一些高级研发(一年多),类似的技术正被Microsoft的Power Pivot for Excel和美国能源部伯克利实验室的fastBit项目用于跟踪粒子模拟的万亿字节信息。只有我们中间的极客才关心这些东西,普通人更喜欢坐在布加迪威龙里驾驶,而不是惊叹于技术底蕴。到达这里对我来说是一段漫长的旅程,因为我必须从零开始创造很多技术,希望
RaptorDB 将成为.net平台上的一个重要替代品,用于替代那些基于java或c++的文档数据库。RaptorDB 让编程重拾乐趣,正如您在示例应用程序部分所见。为什么?
开发RaptorDB 的主要驱动力是使开发人员和支持人员的工作更轻松,开发软件产品本身就够难了,而当需求和想法发生变化时,在现实世界中只会变得更难。RaptorDB 的优点可以概括为:- 开发更轻松:编写更少的代码意味着更少的错误和更少的测试。
- 更改更快:无需编辑数据库模式,也无需使用其他工具的麻烦。
- 知识要求最低:您不需要了解SQL语言、索引技术、配置参数,只需普通的C#(VB.net)即可。
- 维护更简单:更改是隔离的,因此您可以自由地进行更改,而不必担心破坏其他地方。
- 设置时间和成本最低:要开始使用,您只需要.net框架和IDE,无需设置数据库服务器、运行脚本、编辑配置文件等(即使在上网本上也能使用)。
- 执行速度极快:所有这些都在廉价笔记本电脑和上网本上以令人炫目的速度完成,速度甚至超过了昂贵的服务器。
为什么是另一个数据库?
有些人说,为什么还要创建一个新的数据库,而不是使用现有的数据库,或者为“X”数据库编写一个.net驱动程序?对此,我回答如下:- 我相信,纯.net可以做得更好,比如以80%的硬盘速度运行。
- 编写驱动程序和跨进程边界的封送处理可能会有性能损失。
- 实现基础算法是一个学习过程。
- 我们必须突破可能的界限,才能看到唯一的限制是我们自己的想象力和决心。
- 有人会发现它有用,谁知道它会不会成为“大玩家”之一,它们都是从小“玩家”开始的。
可能的用途
您可以在以下场景中使用RaptorDB 的文档存储版本:
- 基于Web的应用程序的后端存储
- 论坛
- 博客
- 维基
- 内容管理系统
- 网站
- 轻松构建SharePoint克隆。
- 需要存储的独立应用程序(不再需要为电话簿应用程序安装SQL Server)。
- 实际业务应用程序(有Caveats)。
我们如何使用数据
在深入研究文档数据库之前,让我们先研究一下我们最初是如何使用数据的,这将使我们更好地理解我们的立场以及如何更好地利用非关系型技术。- 查看事物列表(客户、产品、库存交易……列表)
- 过滤事物列表(X国客户)
- 汇总事物列表(库存数量总和)
- 搜索事物(类似于过滤,但可能跨越多个列表)
- 查看文档(打开发票号123)
- 透视列表或构建智能报表
- 过滤列表
- 汇总列表
什么是文档存储数据库?
文档数据库或存储是一类存储系统,它们将整个对象层次结构保存到磁盘,并在不使用关系表的情况下检索它。为了帮助搜索这类数据库,大多数文档存储数据库都有一个映射函数,该函数提取所需数据并将其保存为“视图”以供以后浏览和搜索。这些数据库摒弃了传统意义上的事务和锁定机制,提供高数据吞吐量和“最终一致性”的数据视图。这意味着保存管道不会因为插入操作而被阻塞,并且读取数据最终会反映已完成的插入(允许映射函数和索引器有时间工作)。这样做的后果非常有吸引力:
- 无模式设计 (即保存它)
- 您无需提前定义表和列。
- 您的应用程序可以根据需要进行演变和扩展,而无需处理模式问题。
- 操作速度 :
- 您读取的数据与首次保存时相同,因此您可以在一次磁盘操作中读取整个对象层次结构,而无需多次读取表并使用检索到的数据来修补对象。
- 消除了锁和死锁,因此速度更快,可扩展性更好。
- 应用程序设计简洁 :
- 应用程序的数据访问层要简单得多。
- 可以随时根据客户的要求对应用程序进行更改。
- 开发成本降低:更简洁的代码意味着开发和测试更快、更容易,并且对开发人员和维护人员的知识要求更低。
- 历史数据:能够保留更改历史记录(对于业务应用程序至关重要)。
- 复制简单轻松:由于数据已经封装(原始文档),因此复制简单无痛,只需传输文档并在另一端保存即可,而不会出现关系模型中表不一致的问题。
- 运营成本节省:无需RDBM服务器许可证即可节省大量成本,特别是对于Web托管和云端应用程序。
离谱!关系型纯粹主义者尖叫……
大多数使用关系型数据库的人在听到“最终一致性”而不是表时会惊恐万分。 大多数企业在数据有效性方面具有很大的灵活性,并非所有数据项都需要相同的粒度,并且在这种情况下,他们有处理“异常”情况的流程,并且工作得很好。例如,如果您卖出了10件商品,然后去仓库发现这些商品昨晚在漏雨屋顶下被雨淋坏了,那么企业会尝试找到另外10件商品,否则就会打电话给客户解释他们的订单可能会延迟。因此,拥有最新的库存记录很好,但企业可以没有它。
这种思维模式对于那些被“关系型数据库”思维影响而没有接触过实际运行业务的人来说需要一些时间来适应,他们会因为这种想法而惊慌失措。自从关系模型出现以来的过去40年里,我们被灌输的许多东西都来自于数据规范化的概念,这种概念迫使我们将数据分解成相同事物的离散块。这主要是由于数据存储容量的不足,并且一直沿用至今,这给数据库引擎带来了巨大的负担,需要优化连接和查询计划才能恢复到最初输入的内容。此外,规范化的概念是一种误称,因为您可以拥有重复数据,只要确保它们彼此同步即可。
近年来,关系模型的大部分思维已经改变,因为“数据库服务器”不再是独立的,而是应用程序的一部分,并通过应用程序进行访问,而不是直接调用。这就是应用程序开发中的分层思维,它创建了一个数据访问层,该层可以轻松地进行隔离和控制。这种变化将安全性设置、规范化要求等负担从RDBM服务器上解脱出来,因为所有这些都从应用程序服务前端完成,例如Facebook的API,它抽象了网站的使用,您不必直接访问表。因此,RDBM服务器内置的许多功能对于现代应用程序来说是未使用的,您可以将数据库嵌入到应用程序中,作为一层而不是一个单独的进程。
适合所有人吗?
尽管有上述所有优点,但文档存储数据库并非适合所有人、所有情况。主要的区别在于您是否需要“毫秒级”的全局数据一致性(这是RDBM系统的基石)。如果数据有效性不是问题,或者您对某个特定时间点有效的结果感到满意,例如今天的库存计数在上午9:00有效,那么根据我的经验,对于大多数Web应用程序和可能是90%的业务应用程序来说,您可以这样做(这并不意味着这些数据库在非工作时间不一致,但通常是秒级)。
如果您不愿意牺牲这种级别的定时并发性,那么NoSql / 文档存储数据库就不适合您。根据我的经验,不愿这样做更多的是开发人员/设计师的心理障碍,而不是应用程序和用户的技术要求。
特点
RaptorDB 在构建时考虑了以下功能:
- 核心功能 :
- 基于
RaptorDB的持久化字典算法构建(因此您获得了所有这些好处)。 - 纯.net构建,因此通过驱动程序跨进程边界进行数据封送处理可以带来显著的性能优势。
- 体积小巧,仅194 KB(甚至比伟大的SQLite还小)。
- 视图中存储的
字符串为UTF8或Unicode格式。 - 文档可以存储为ASCII JSON,JSON标准本身已将Unicode编码为ASCII格式,或者为提高速度可以存储为二进制JSON。
- 嵌入式设计。
- 网络上的数据传输经过压缩。
- v1.6中添加了事务支持。
- 基于
- 视图存储 :
- 您无需为
string列指定宽度,RaptorDB可以处理任意大小的字符串(但索引限于普通字符串列的最大255字节)。 - 视图(映射函数的输出)以二进制而非JSON格式保存数据(索引速度更快)。
- 主列表/视图基于对象类型定义,可立即访问已保存的对象(立即调用主映射函数)。
- 您无需为
- 文档存储 :
- 还可以保存
byte[]数据,以便您可以保存文件等(这些文件保存在单独的存储文件中)。
- 还可以保存
- 索引引擎 :
- 支持使用Word Aligned Hybrid (WAH)压缩的视图的特殊混合位图索引。
- 自动索引视图(自维护,无需管理)。
- 所有列都使用
MGIndex进行索引。 - 对
string列的快速全文搜索支持(您可以选择对视图中的字符串进行普通搜索或全文搜索)。
- LINQ查询处理器 :
- 查询过滤器解析器,支持嵌套括号、
AND和OR表达式。
- 查询过滤器解析器,支持嵌套括号、
- 映射函数引擎 :
- 映射函数是编译后的.net代码,而不是像竞争对手那样使用JavaScript(速度提高了一个数量级,请参阅性能测试)。
- 映射函数可以访问API以执行查询和获取文档(您可以在其中编写复杂的业务逻辑)。
- 映射函数对保存的数据进行类型检查,这使得读取数据更容易,并且一切都更加一致。
限制
此版本存在以下限制:
- 需要至少.net 4(使用Task库)。
- 文档和视图项目数限制为40亿项或
Int32。 - 此版本与键值存储版本不兼容。
视图上的聚合.目前不支持独立服务版本。- 目前不支持文档的修订检查。
- 不支持分片/
复制。 - 查询过滤器仅适用于右侧为字面值的条件(例如,
Name='bob'而不是StatusColumn > LastStatusColumn引用另一个列)。 在事务模式下,当前活动线程看不到其自身的数据更改。
规则
为了帮助您更好地使用RaptorDB,以下是一些规则,它们将帮助您:
- 对于您要保存的每种类型的对象,都必须有一个主视图。
- 如果视图的
ConsistentView = True,它将充当主视图。 - 如果主视图的
TransactionMode = True,那么对它以及与之关联的所有视图的所有操作都将在事务中进行,并且如果任何视图失败,将Rollback。 - 在事务模式下,
BackgroudIndexing被关闭。 - 事务中的查询只能看到其自身的更新。
竞争对手
有许多竞争存储系统,其中一些我研究过,如下所示:
- MongoDB (c++):很棒的数据库,我喜欢它,也是RaptorDB的主要灵感来源,尽管我对它的32位4Gb数据库大小限制和内存映射文件设计有些不满,这些设计可能很容易损坏。(如果有人想知道,多态性在mongodb中有解决方法)。
- CouchDB / CouchBase (erlang):文档数据库的另一个标准。设计优雅。
- RavenDB (.net):由Ayende完成的工作,这是一个基于Windows ESENT存储系统的.net文档数据库。
- OrientDB (java):性能指标令人印象深刻。
性能测试
所有测试均在我笔记本上进行,该笔记本配备AMD K625 1.5Ghz CPU、4Gb DDR2内存、WD 5400rpm HDD、Win7 Home 64位,Windows评级为3.9。Javascript 与 .NET 编译映射函数
当今大多数文档数据库使用JavaScript语言编写映射函数,而在RaptorDB中,我们使用编译后的.net代码。以下示例来自http://www.silverlight.net/content/samples/sl2/silverlightchess/run/default.html网站,这是一个国际象棋应用程序,该测试肯定不全面,但它确实显示了一个合理的计算密集型比较。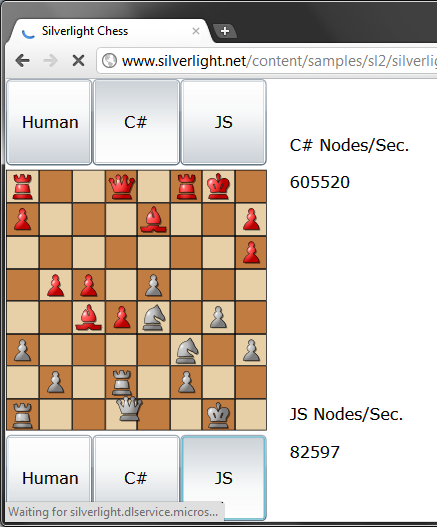
正如您所见,即使是在Google Chrome(V8 JavaScript引擎)中,它可能是目前最快的JavaScript处理器,.net代码(在Silverlight中,完整的.net版本可能更快)也比它快约8倍。
通过这次非科学测试,除了编译代码之外,不应该使用任何其他东西来编写映射函数。
对象插入性能
根据文档和视图定义的复杂性,您可以期望从RaptorDB获得约10,000个文档/秒的吞吐量(基于我的测试系统)。查询性能
验证NoSql数据库使用情况的真正测试是查询测试,您已经将数据存入,取出的速度有多快。RaptorDB会将查询处理时间输出到日志文件中,正如您从下面的示例中看到的,大多数查询时间都花在实际获取数据上,而查询计划是在毫秒范围内执行的(位图索引的力量)。2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 40.0023
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 33.0019
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 300
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 1.0001
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 469.0268
2012-04-29 12:38:40|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 25875
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 4.0002
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 6.0003
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 500
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query bitmap done (ms) : 0
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows fetched (ms) : 677.0387
2012-04-29 12:38:45|DEBUG|1|RaptorDB.Views.ViewHandler|| query rows count : 50000
如果你想折磨某人,让他编写一个LINQ提供程序!
我花了大约一个月的时间进行深入研究、调试和试验,才弄清楚LINQ提供程序接口及其工作原理。虽然本节的标题有点苛刻,但我希望它能传达当时我感受到的挫败感。
公平地说,最终的结果非常干净、简洁、优雅。不可否认,这只是LINQ的表达式求值部分,并且只是您为了一个完整的LINQ提供程序所需要经历的一小部分。这对我来说是RaptorDB所需要的一切,所以我会尝试在这里解释它是如何完成的,供任何想要继续研究的人参考,因为关于这个主题的资源非常稀少。
对于RaptorDB,我们想要一个LINQ中的“where”子句解析器,它本质上会过滤视图数据并为我们提供行,这是通过以下命令完成的:
int j = 1000;
var result = db.Query(typeof(SalesInvoice),
(SalesInvoice s) => (s.Serial > j && s.CustomerName == "aaa")
);
我们关注的主要部分是这一行:
(SalesInvoice s) => (s.Serial > j && s.CustomerName == "aaa")
从这里,我们想解析表达式:给定SalesInvoice类型(用于表示属性/列名,仅此目的),过滤条件是[序列号大于j且客户名称为“aaa”]或计数大于零。从这一点开始,查询引擎必须确定使用的“列名”,从索引文件中获取它们,并从该索引中获取相关值,然后对结果应用逻辑算术来获得我们想要的东西。
LINQ解析的怪癖
解析LINQ查询时有两个怪癖:
- 变量(上面例子中的j)被替换为编译器占位符,而不是值。
- 所有工作都在VisitBinary方法中完成,用于逻辑表达式解析和子句求值,因此您必须同时区分和处理它们。
RaptorDB中的LINQ解析器如何工作
在RaptorDB中,我们希望能够根据表达式的顺序和逻辑来提取和查询每个子句的索引。由于索引是基于WAHBitArray 构建的,结果将是一个WAHBitArray 。所有这些都是在以下非常小的代码(与编写语言解析器相比)中完成的:
delegate WAHBitArray QueryExpression(string colname, RDBExpression exp, object from);
internal class QueryVisitor : ExpressionVisitor
{
public QueryVisitor(QueryExpression express)
{
qexpression = express;
}
public Stack<object> _stack = new Stack<object>();
public Stack<object> _bitmap = new Stack<object>();
QueryExpression qexpression;
protected override Expression VisitBinary(BinaryExpression b)
{
this.Visit(b.Left);
ExpressionType t = b.NodeType;
if (t == ExpressionType.Equal || t == ExpressionType.LessThan || t == ExpressionType.LessThanOrEqual ||
t == ExpressionType.GreaterThan || t == ExpressionType.GreaterThanOrEqual)
_stack.Push(b.NodeType);
this.Visit(b.Right);
t = b.NodeType;
if (t == ExpressionType.Equal || t == ExpressionType.NotEqual ||
t == ExpressionType.LessThanOrEqual || t == ExpressionType.LessThan ||
t == ExpressionType.GreaterThanOrEqual || t == ExpressionType.GreaterThan)
{
// binary expression
object lv = _stack.Pop();
ExpressionType lo = (ExpressionType)_stack.Pop();
object ln = _stack.Pop();
RDBExpression exp = RDBExpression.Equal;
if (lo == ExpressionType.LessThan)
exp = RDBExpression.Less;
else if (lo == ExpressionType.LessThanOrEqual)
exp = RDBExpression.LessEqual;
else if (lo == ExpressionType.GreaterThan)
exp = RDBExpression.Greater;
else if (lo == ExpressionType.GreaterThanOrEqual)
exp = RDBExpression.GreaterEqual;
_bitmap.Push(qexpression("" + ln, exp, lv));
}
if (t == ExpressionType.And || t == ExpressionType.AndAlso ||
t == ExpressionType.Or || t == ExpressionType.OrElse)
{
// do bitmap operations
WAHBitArray r = (WAHBitArray)_bitmap.Pop();
WAHBitArray l = (WAHBitArray)_bitmap.Pop();
if (t == ExpressionType.And || t == ExpressionType.AndAlso)
_bitmap.Push(r.And(l));
if (t == ExpressionType.Or || t == ExpressionType.OrElse)
_bitmap.Push(r.Or(l));
}
return b;
}
protected override Expression VisitMethodCall(MethodCallExpression m)
{
string s = m.ToString();
_stack.Push(s.Substring(s.IndexOf('.') + 1));
return m;
}
protected override Expression VisitMember(MemberExpression m)
{
var e = base.VisitMember(m);
var c = m.Expression as ConstantExpression;
if (c != null)
{
Type t = c.Value.GetType();
var x = t.InvokeMember(m.Member.Name, BindingFlags.GetField, null, c.Value, null);
_stack.Push(x);
}
if (m.Expression != null && m.Expression.NodeType == ExpressionType.Parameter)
{
_stack.Push(m.Member.Name);
return e;
}
return e;
}
protected override Expression VisitConstant(ConstantExpression c)
{
IQueryable q = c.Value as IQueryable;
if (q != null)
_stack.Push(q.ElementType.Name);
else if (c.Value == null)
_stack.Push(null);
else
{
_stack.Push(c.Value);
if (Type.GetTypeCode(c.Value.GetType()) == TypeCode.Object)
_stack.Pop();
}
return c;
}
}
大部分工作都在VisitBinary 方法中完成(用于求值逻辑[&& || ]操作和子句[b>3]),因此要区分两者,使用栈来存储子句值以供进一步处理。VisitBinary 将递归调用表达式的左侧和右侧,因此需要一个位图栈来聚合表达式的结果。
该类的构造函数接受两个由调用者提供的委托,用于处理对底层索引的句柄,该类在二进制子句完全解析时调用这些索引。结果被推入位图栈。
VisitMember 方法负责将编译器生成的常量值代码替换为适当的值(上面例子中的j)。
其余代码通常用于提取“列名”,而不带前缀(s.Serial -> Serial 等)。
示例应用程序
要使用RaptorDB ,您只需执行以下步骤:
- 定义您的实体(纯c#对象),就像进行领域驱动开发一样。
- 为您的基本实体创建一个主视图。
- 将您的视图注册到RaptorDB。
- 保存和查询您的数据。
- 根据您的需求添加新视图。
正如您下面将看到的,这非常简单,您无需学习任何新知识,也无需担心配置或在运行时破坏内容,因为编译器将在编译时捕获您的错误。
一个很棒的功能是完全没有SQL相关的任何东西,相关的模式痛苦,以及必须切换到数据库管理产品来定义和检查表和列,因为一切都在您的源文件中。
1. 创建实体
您应该做的第一件事是定义您的实体或数据类(称为领域驱动开发),这些是普通的c#(vb.net)类或POCO,如下所示:
public class LineItem
{
public decimal QTY { get; set; }
public string Product { get; set; }
public decimal Price { get; set; }
public decimal Discount { get; set; }
}
public class SalesInvoice
{
public SalesInvoice()
{
ID = Guid.NewGuid();
}
public Guid ID { get; set; }
public string CustomerName { get; set; }
public string Address { get; set; }
public List<LineItem> Items { get; set; }
public DateTime Date { get; set; }
public int Serial { get; set; }
public byte Status { get; set; }
}
上面的内容没有什么特别之处,只是缺少您需要做的任何额外工作,例如添加属性等(甚至是Serializable),因为它们是不需要的。
2. 创建视图
接下来,您需要为实体创建主视图,如下所示:
public class SalesInvoiceView : View<SalesInvoice> // create a view for the SalesInvoice type
{
public class RowSchema // define the schema for this view
{
public NormalString CustomerName; // CustomerName is a normal string index
public DateTime InvoiceDate;
public string Address;
public int Serial;
public byte Status;
}
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Schema = typeof(SalesInvoiceView.RowSchema);
this.Mapper = (api, docid, doc) =>
{
api.Emit(docid, doc.CustomerName, doc.Date, doc.Address, doc.Serial, doc.Status);
};
}
}
这也相当直接。
- 此视图用于
SalesInvoice对象类型。 RowSchema是一个定义此视图列的类。- 您可以将此类命名为任何名称,只要将其注册到Schema属性即可。
- 支持所有值类型(
int、string、decimal等)。 NormalString是一种特殊类型,它指示索引器将此列索引为字符串,因此在查询时您必须指定所有字符串。- 如果您指定了一个字符串属性,那么RaptorDB将在此列上执行全文索引,因此您可以在查询时搜索该列中的单词。
BackgroundIndexing控制索引器在此视图上的工作方式(即,如果为false,则阻止保存直到每个文档都被索引)。AddFireOnTypes控制此视图何时根据输入文档类型被调用。Mapper是用于填充此视图(即从输入文档提取信息)的映射函数,如果需要,您可以在此处添加逻辑。项目的顺序必须与您定义的模式相同。- 使用
api,您可以Fetch文档,log调试信息,并Query另一个视图。
3. 注册视图
注册视图就像这样简单:
rap.RegisterView(new SalesInvoiceView());
RaptorDB 将对您的视图进行一些检查,如果一切正常,它将返回true,这意味着您可以使用了。
4. 保存和查询数据
现在您可以使用RaptorDB 并保存文档,如下所示:
var inv = new SalesInvoice()
{
Date = FastDateTime.Now,
Serial = i % 10000,
CustomerName = "me " + i % 10,
Status = (byte)(i % 4),
Address = "df asd sdf asdf asdf"
};
inv.Items = new List<LineItem>();
for (int k = 0; k < 5; k++)
inv.Items.Add(new LineItem()
{ Product = "prod " + k, Discount = 0, Price = 10 + k, QTY = 1 + k });
rap.Save(inv.ID, inv); // save to RaptorDB
查询就像编写LINQ谓词一样简单,如下所示:
var q = rap.Query(typeof(SalesInvoice), // call by the view type or the primary document type
(SalesInvoice s) => (s.Serial < j) && (s.Status == 1 || s.Status == 3));
q = rap.Query("SalesItemRows", // call by the view name
(LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3"));
正如您所见,您可以通过指定视图的类型(或主视图的文档类型)或通过调用视图的字符串名称来以两种方式调用查询。
屏幕截图
从下面的图片中,您可以看到测试应用程序正在工作。RaptorDB被配置为进行后台索引,因此在12秒内插入了100,000个文档,并且主视图已填充(500个项目的查询结果),并且后台索引器正在填充定义的其他视图,在几次查询后显示最终的50,000个项目结果。

工作原理

上图显示了
RaptorDB 工作原理的高层视图:文档首先插入到存储文件中,然后立即调用主映射函数来生成文档的主视图,此时控制权返回给调用方法。在经过一定时间后,将调用其他映射函数来为该文档生成其他视图。在使用
RaptorDB 文档数据存储时,您必须了解一些术语,这些术语是:
- 文档 :是一个对象/实体,它被序列化为JSON
- DocID :是一个唯一标识文档的Guid,必须随文档一起提供
- 视图 :类似于标准的数据库表
- 映射函数 :是一个函数,它接收一个文档并从该文档中发出值到一个视图
- 索引 :用于在查询视图时检索信息。
什么是视图?
视图是文档中的值列表,通过文档中的GUID 属性与该文档绑定。您可以将视图想象成一个多维文档对象的二维图像,通常用于特定目的。例如,如果您有一个发票文档,一个视图将是这些发票的列表,用于浏览它们,如下所示:
{ invoice GUID, date, invoice number, status, salesman name }
另一个视图将如下所示,供会计部门使用:
{ invoice GUID, date, total sales amount, total sales discounts, salesman name, customer name }
什么是映射函数?
映射函数是一段代码,您编写它来接收一个文档对象并“发出”一个值列表(通常来自该文档,您可以自由发出任何内容,但大多数时候它会以某种方式与该文档相关)到一个“视图”。“主视图”有什么用?
主视图是一个视图,其映射函数将在文档保存后立即被调用,并且没有延迟。这样您就可以立即获得这些文档的列表,而不必等待。为了说明这一点的重要性,请看以下示例:您有一个销售应用程序,销售人员添加他们的发票,您希望在保存后看到这些发票,原因很简单,您想对该项目启动销售工作流程,所以您必须看到它,而且您不想等待映射函数“最终”触发。
显然,映射函数应该是最小化的,并且只显示所需的内容。您可以过度发射大量数据到此列表,但您会失去性能。
RaptorDB中的主要角色
RaptorDB 包含以下部分:- RaptorDB主接口:您的代码看到的,以及其他部分的加载器。
- 存储文件 :一种快速的多线程文件存储机制,用于文档存储和视图数据。
- 视图 :见下文
- ViewManager :见下文
- ViewHandler :见下文
ViewHandler

View负责:
- 存储视图数据
- 根据查询使用情况对列进行索引
ViewManager
View Manager负责以下事项:- 加载和创建视图
- 编译视图映射函数。
- 跟踪对象类型与视图之间的映射,或者在插入/更新时应将哪个视图发送给对象。
- 跟踪发送到视图的最后文档和存储记录号。
- 定期使用新传入的文档更新视图。
查询执行器
查询执行器将执行以下操作:- 解析LINQ表达式。
- 检查列名是否存在于视图模式中,此处将捕获验证错误。
- 检查是否存在用于过滤器中使用的列的索引。
- 提取所需的位图索引。
- 提取已删除记录的位图。
- 执行过滤器并从视图存储中获取视图行。
RaptorDB设置
为了使RaptorDB 正常工作,您必须遵循以下步骤:
- 为对象定义一个主视图,该视图允许通过列表立即访问插入的对象,支持继承对象以简化操作,因此您可以为基类定义一个。
保存过程
保存过程遵循以下步骤:
GetPrimaryListForType():将尝试获取对象类型的主映射函数,并递归遍历层次结构直到找到。SaveData():将数据保存到存储文件,在日志文件和内存日志中创建日志条目,后台索引器将处理日志。SavePrimaryView():将调用此类型的主映射函数。SaveInOtherViews():将保存到任何其他已定义的视图。
视图和映射函数
视图是对象结构中的数据项列表,类似于表模型中的行集合。映射函数负责接收对象并为视图生成行。映射函数的前提是预先计算“查询”,然后在需要时获取结果。
映射引擎将执行以下操作:
- 找到上一个处理的DocID并递增。
FindMapFunctionsForType():要为此对象执行的映射函数列表。ExecuteMapFunction():在对象上执行,并检索带有DocID引用的新视图行。DeleteFromView(DocID):标记删除DocID的旧值。InsertView(newData):将来自映射函数的新数据添加到视图。
- 找到下一个DocID并递归处理。
MG索引的强大之处
位图索引是一种索引形式,它在一系列位中存储值在行中的存在情况。例如,如果您有100万条记录,并且正在搜索Name列中的“bob”,那么Name列的b+树可能如下所示,当您在叶节点中找到“bob”时,您将获得一个BitArray,表示该列中的“bob”的存在情况,按记录编号索引。因此,如果该BitArray的第3位是1,则表示第3行中有“bob”等等。很容易看出这是一种非常紧凑且高效的存储和检索机制。
* 上图显示的是b+树/位图索引结构,而不是使用字典的MGIndex,但原理相同。
真正的强大之处在于下面的示例,您想查询“Name='bob' and Code=between(1,3)”的内容,查询处理器将获取过滤器,解析该过滤器的值,并生成如下的执行计划:

正如您从上面的图表所看到的,执行计划是一系列BitArrays,您所要做的就是根据解析的过滤器执行位算术逻辑,并将BitArrays进行{AND、OR、NOT}运算。这些操作通常在毫秒范围内完成,即使您的数据库中有数百万行。结果是一个位置索引的行查找器,指向行内容,您从磁盘读取,并发送给调用者,其中1表示读取行,0表示跳过行内容(即100001... -> 读取记录号:1,6,...)。
全文搜索
对于string 列,RaptorDB 支持全文搜索以在行中查找单词。为此,RaptorDB 使用了内置于hOOt 全文搜索引擎的技术。被淘汰的部分
以下功能已被移除,可能会在下一版本中加入:- 结果分页。
基于LINQ的聚合(sum、count等)。- 存储中的压缩支持。
- 使用统计信息和监控信息。
- 查询缓存。
视图模式更改。- 文档的修订检查。
闭幕词
这是一个正在进行中的项目,如果有人想加入,我将非常高兴。
附录 v1.2
此版本中添加了一些主要功能,它们是:
- 视图版本控制
- 全文索引属性
- 字符串查询
- 查询视图类型
视图版本控制
在此版本中,您可以更改视图模式或属性,还可以为现有文档添加新视图,并让引擎重建视图。这通过视图定义中的Version 属性进行控制。
您有责任增加此版本号,您可以决定何时增加以及何时有意义。RaptorDB 将仅检查版本号并采取相应行动。
全文索引
一个破坏性更改是删除了视图模式中的NormalString 类型,并用string 和[FullText] 属性替换了它,这更简单、用户友好。
public class RowSchema // define the schema for this view
{
[FullText]
public string CustomerName; // CustomerName is a hOOt index
public DateTime InvoiceDate;
public string Address;
public int Serial;
public byte Status;
}
字符串查询
RaptorDB 现在可以解析字符串LINQ查询并为您提供结果。这可以在更新的控制台应用程序中看到。您可能希望在源代码中坚持使用LINQ,但这在您需要用户在UI中生成过滤器时可能很有用。
此功能将在服务器版本中更为普遍,因为LINQ不会在边界上序列化。
一个有趣的功能是,您可以获得接近SQL语法的查询,例如:
var q = rap.Query(typeof(SalesItemRows),
"product = \"prod 1\" or product = \"prod 3\""));
其中列可以不区分大小写,并且您可以使用单个‘=’而不是C#样式的‘||’等来使用“或”。
查询视图类型
现在,您可以将视图类型传递给Query函数进行查询。
var q = rap.Query(typeof(SalesItemRows),
((LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3"));
附录 v1.3
此版本中添加了一些主要功能:
- 结果模式行
- Windows查询应用程序
- 客户端LINQ聚合
- api.EmitObject
结果模式行
您的查询结果现在将返回View.Schema 对象的列表,这允许客户端数据绑定和LINQ聚合查询。
Windows查询应用程序
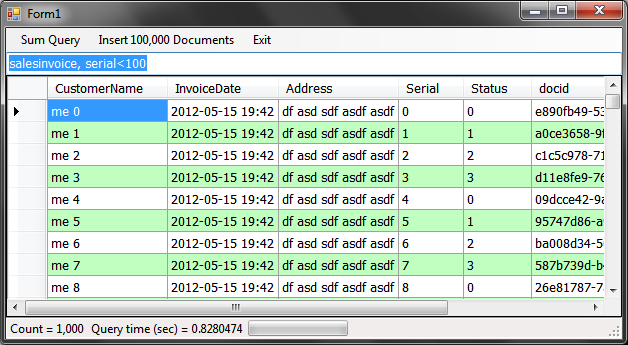
添加了一个Windows应用程序项目来展示RaptorDB 的数据绑定功能。您可以执行与控制台应用程序相同的功能,但具有视觉反馈。要查询视图,只需在文本框中输入您的视图名称和查询字符串,然后按Enter键。
在菜单中添加了客户端sum,这将为您提供以下结果。

客户端LINQ聚合
您可以执行如下的客户端聚合查询,这非常强大。
var q = rap.Query(typeof(SalesItemRowsView), (LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3"));
// grouping
List<SalesItemRowsView.RowSchema> list = q.Rows.Cast<SalesItemRowsView.RowSchema>().ToList();
var e = from item in list group item by item.Product into grouped
select new { Product = grouped.Key,
TotalPrice = grouped.Sum(product => product.Price),
TotalQTY = grouped.Sum(product => product.QTY)
};
以上的主要点是Cast 方法,它将为您提供类型,以便您可以对其进行求和。
api.EmitObject
为了帮助您编写更少的代码,您可以在映射代码中使用api.EmitObject 方法,它会匹配给定的对象与视图模式列名,您必须确保名称匹配。
this.Mapper = (api, docid, doc) =>
{
if (doc.Status == 3 && doc.Items != null)
foreach (var item in doc.Items)
api.EmitObject(docid, item);
// instead of writing the following
//api.Emit(docid, item.Product, item.QTY, item.Price, item.Discount);
};
附录 v1.4
此版本进行了许多重大更改,其中一些是:
-
将源代码重构为单独的项目。
-
服务器模式
参数
以下是Globals.cs 文件中控制RaptorDB 工作的一些参数:
| 参数 | 默认值 | 描述 |
<code>BitmapOffsetSwitchOverCount | 10 | 切换点,重复项存储为WAH位图而不是记录号列表 |
<code>PageItemCount | 10,000 | 页面内的项目数 |
<code>SaveIndexToDiskTimerSeconds | 60 | 后台保存索引计时器秒数(例如,每60秒将索引保存到磁盘) |
<code>DefaultStringKeySize | 60 | 默认字符串键大小(字节,存储为UTF8) |
<code>FlushStorageFileImmetiatley | false | 立即刷新到存储文件 |
<code>FreeBitmapMemoryOnSave | false | 保存时压缩并释放位图索引内存 |
SaveAsBinaryJSON | true | 将文档保存为存储文件中的二进制JSON。 |
TaskCleanupTimerSeconds | 3 | 删除已完成的任务计时器(清理任务队列) |
BackgroundSaveViewTimer | 1 | 如果启用,则为到其他视图保存计时器的秒数 |
BackgroundViewSaveBatchSize | 1,000,000 | 在后台视图保存事件中处理多少个文档 |
调整、性能和一致性
通过设置某些参数,您可以使用RaptorDB 从同步到最终一致性的方式。您可以决定需要完全一致到最终一致的数据处理部分的哪些部分。这可以通过视图定义中的一些属性来完成。
BackgroundIndexingConsistentSaveToThisView
显然,在同步模式下,吞吐量会降低。
服务器模式
在此版本中,您可以在服务器模式下运行RaptorDB ,它将接受来自客户端的TCP连接。此版本中的视图可以构建到DLL文件中,并部署在服务器的“Extensions”文件夹中,服务器将在启动时自动读取并使用它们。TCP端口号和数据文件夹文件是可配置的。
RaptorDBServer.exe

RaptorDBServer 允许您将RaptorDB 安装为Windows服务或在命令行上运行,使用-i参数可以安装多个服务实例,这些实例可以通过-n名称和-p端口参数区分。
客户端使用
使用RaptorDB 作为客户端就像以下操作一样简单:
RaptorDBClient db = new RaptorDB.RaptorDBClient("localhost", 90 , "admin", "admin"); // server, port, username, password
通过此接口,嵌入式版本的所有功能都可用。
服务器使用
您可以通过以下方式在自己的代码中以服务器模式启动RaptorDB :
var server = new RaptorDBServer(90, @"..\..\..\RaptorDBdata"); // port, data folder
IRaptorDB接口
为了使使用嵌入式版本或客户端版本的体验无缝,例如您可以先启动嵌入式版本,然后根据您的使用情况逐步迁移到客户端服务器版本,因此创建了IRaptorDB 接口来将您与更改隔离。您可以在提供的示例查询执行器程序中看到这一点。
自我应用

我在测试MongoDB 时做了一个Scrum Backlog/Todo List类型的应用程序,所以我决定将其移植到RaptorDB 。转换过程非常简单和琐碎,这主要是由于文档数据库的性质。唯一的变化是MongoDB 返回实际对象的列表,而RaptorDB 不返回,所以当您需要一个对象时,您需要执行Fetch。
不幸的是,我使用了商业组件,所以不能在这里发布源代码。下面是源代码差异:
MongoDB源代码
public partial class frmMain : Form
{
public frmMain()
{
InitializeComponent();
}
Mongo _mongo;
IMongoDatabase _db;
IMongoCollection<ToDo> _collection;
private void eXITToolStripMenuItem_Click(object sender, EventArgs e)
{
// TODO : message box here
this.Close();
}
private void exGrid1_RowDoubleClick(object sender, Janus.Windows.GridEX.RowActionEventArgs e)
{
openitem();
}
private void openitem()
{
var r = exGrid1.GetRow();
if (r != null)
{
ShowItem(r.DataRow as ToDo);
}
}
private void ShowItem(ToDo item)
{
frmTODO f = new frmTODO();
f.SetData(item);
var dr = f.ShowDialog();
if (dr == DialogResult.OK)
{
var o = f.GetData() as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
_collection.Save(o);
FillCollection();
}
}
private void frmMain_Load(object sender, EventArgs e)
{
_mongo = new Mongo();
_mongo.Connect();
_db = _mongo.GetDatabase("mytodo");
_collection = _db.GetCollection<ToDo>();
FillCollection();
exGrid1.AddContextMenu("delete", "Delete", null);
exGrid1.AddContextMenu("open", "Open", null);
exGrid1.ContextMenuClicked += new JanusGrid.ContextMenuClicked(exGrid1_ContextMenuClicked);
}
void exGrid1_ContextMenuClicked(object sender, JanusGrid.ContextMenuClickedEventArg e)
{
if (e.MenuItem == "delete")
{
DialogResult dr = MessageBox.Show("delete?", "DELETE",
MessageBoxButtons.YesNo, MessageBoxIcon.Stop,
MessageBoxDefaultButton.Button2);
if (dr == DialogResult.Yes)
{
var o = exGrid1.GetRow().DataRow as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
FillCollection();
}
}
if (e.MenuItem == "open")
openitem();
}
private void FillCollection()
{
var o = _collection.FindAll();
BindingSource bs = new BindingSource();
bs.AllowNew = true;
bs.AddingNew += new AddingNewEventHandler(bs_AddingNew);
bs.DataSource = o.Documents;
exGrid1.DataSource = bs;
exGrid1.AutoSizeColumns(true);
}
void bs_AddingNew(object sender, AddingNewEventArgs e)
{
e.NewObject = new ToDo();
}
private void addToolStripMenuItem_Click(object sender, EventArgs e)
{
ShowItem(new ToDo());
}
bool _editmode = false;
private void editInPlaceToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == false)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.AutoEdit = true;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.RecordUpdated += new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded += new EventHandler(exGrid1_RecordAdded);
_editmode = true;
}
}
void exGrid1_RecordAdded(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
_collection.Save(o);
}
void exGrid1_RecordUpdated(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as ToDo;
var doc = new Document();
doc["GUID"] = o.GUID;
_collection.Remove(doc);
_collection.Save(o);
}
private void normalModeToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == true)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.RecordUpdated -= new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded -= new EventHandler(exGrid1_RecordAdded);
_editmode = false;
}
}
void FontToolStripMenuItemClick(object sender, EventArgs e)
{
FontDialog ofd = new FontDialog();
ofd.Font = this.Font;
if (ofd.ShowDialog() == DialogResult.OK)
{
this.Font = ofd.Font;
exGrid1.AutoSizeColumns(true);
}
}
private void designerToolStripMenuItem_Click(object sender, EventArgs e)
{
//try
{
JanusGrid.ExGrid grid = new JanusGrid.ExGrid();
grid.Name = "GridControl";
MemoryStream ms = new MemoryStream();
exGrid1.SaveLayoutFile(ms);
ms.Seek(0l, SeekOrigin.Begin);
grid.LoadLayoutFile(ms);
Janus.Windows.GridEX.Design.GridEXDesigner gd = new Janus.Windows.GridEX.Design.GridEXDesigner();
//try
{
gd.Initialize(grid);
System.ComponentModel.Design.DesignerVerb dv = gd.Verbs[0];
dv.Invoke(grid);
}
//catch { }
gd.Dispose();
ms = new MemoryStream();
grid.SaveLayoutFile(ms);
ms.Seek(0l, SeekOrigin.Begin);
exGrid1.LoadLayoutFile(ms);
exGrid1.ResumeLayout();
}
//catch { }
}
}
| RaptorDB源代码
public partial class frmMain : Form
{
public frmMain()
{
InitializeComponent();
}
RaptorDB.RaptorDB rap;
private void eXITToolStripMenuItem_Click(object sender, EventArgs e)
{
// TODO : message box here
rap.Shutdown();
this.Close();
}
private void exGrid1_RowDoubleClick(object sender, Janus.Windows.GridEX.RowActionEventArgs e)
{
openitem();
}
private void openitem()
{
var r = exGrid1.GetRow();
if (r != null)
{
ToDo t = (ToDo)rap.Fetch((r.DataRow as TodoView.RowSchema).docid);
ShowItem(t);
}
}
private void ShowItem(ToDo item)
{
frmTODO f = new frmTODO();
f.SetData(item);
var dr = f.ShowDialog();
if (dr == DialogResult.OK)
{
var o = f.GetData() as ToDo;
rap.Save(o.GUID, o);
FillCollection();
}
}
private void frmMain_Load(object sender, EventArgs e)
{
rap = RaptorDB.RaptorDB.Open("mytodo");
rap.RegisterView(new TodoView());
FillCollection();
exGrid1.AddContextMenu("delete", "Delete", null);
exGrid1.AddContextMenu("open", "Open", null);
exGrid1.ContextMenuClicked += new JanusGrid.ContextMenuClicked(exGrid1_ContextMenuClicked);
}
void exGrid1_ContextMenuClicked(object sender, JanusGrid.ContextMenuClickedEventArg e)
{
if (e.MenuItem == "delete")
{
DialogResult dr = MessageBox.Show("delete?", "DELETE", MessageBoxButtons.YesNo, MessageBoxIcon.Stop, MessageBoxDefaultButton.Button2);
if (dr == DialogResult.Yes)
{
var o = exGrid1.GetRow().DataRow as ToDo;
//rap.Delete(o.GUID, o); // FIX : implement this
FillCollection();
}
}
if (e.MenuItem == "open")
openitem();
}
private void FillCollection()
{
var o = rap.Query(typeof(TodoView));
BindingSource bs = new BindingSource();
bs.AllowNew = true;
bs.AddingNew += new AddingNewEventHandler(bs_AddingNew);
bs.DataSource = o.Rows;
exGrid1.DataSource = bs;
exGrid1.AutoSizeColumns(true);
}
void bs_AddingNew(object sender, AddingNewEventArgs e)
{
e.NewObject = new TodoView.RowSchema();
}
private void addToolStripMenuItem_Click(object sender, EventArgs e)
{
ShowItem(new ToDo());
}
bool _editmode = false;
private void editInPlaceToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == false)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.AutoEdit = true;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.True;
exGrid1.RecordUpdated += new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded += new EventHandler(exGrid1_RecordAdded);
_editmode = true;
}
}
void exGrid1_RecordAdded(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as TodoView.RowSchema;
ToDo t = new ToDo();
FillProperties(t, o);
rap.Save(t.GUID, t);
}
private void FillProperties(ToDo t, TodoView.RowSchema o)
{
// fill properties
t.Category = o.Category;
t.Date = o.Date;
t.Done = o.Done;
t.Priority = o.Priority;
t.Project = o.Project;
t.Status = o.Status;
t.Subject = o.Subject;
t.TimeEstimate = o.TimeEstimate;
}
void exGrid1_RecordUpdated(object sender, EventArgs e)
{
var o = exGrid1.GetRow().DataRow as TodoView.RowSchema;
ToDo t = (ToDo)rap.Fetch(o.docid);
if (t == null) t = new ToDo();
FillProperties(t, o);
rap.Save(t.GUID, t);
}
private void normalModeToolStripMenuItem_Click(object sender, EventArgs e)
{
if (_editmode == true)
{
exGrid1.AllowEdit = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.AllowAddNew = Janus.Windows.GridEX.InheritableBoolean.False;
exGrid1.RecordUpdated -= new EventHandler(exGrid1_RecordUpdated);
exGrid1.RecordAdded -= new EventHandler(exGrid1_RecordAdded);
_editmode = false;
}
}
void FontToolStripMenuItemClick(object sender, EventArgs e)
{
FontDialog ofd = new FontDialog();
ofd.Font = this.Font;
if (ofd.ShowDialog() == DialogResult.OK)
{
this.Font = ofd.Font;
exGrid1.AutoSizeColumns(true);
}
}
private void designerToolStripMenuItem_Click(object sender, EventArgs e)
{
//try
{
JanusGrid.ExGrid grid = new JanusGrid.ExGrid();
grid.Name = "GridControl";
MemoryStream ms = new MemoryStream();
exGrid1.SaveLayoutFile(ms);
ms.Seek(0L, SeekOrigin.Begin);
grid.LoadLayoutFile(ms);
Janus.Windows.GridEX.Design.GridEXDesigner gd = new Janus.Windows.GridEX.Design.GridEXDesigner();
//try
{
gd.Initialize(grid);
System.ComponentModel.Design.DesignerVerb dv = gd.Verbs[0];
dv.Invoke(grid);
}
//catch { }
gd.Dispose();
ms = new MemoryStream();
grid.SaveLayoutFile(ms);
ms.Seek(0l, SeekOrigin.Begin);
exGrid1.LoadLayoutFile(ms);
exGrid1.ResumeLayout();
}
//catch { }
}
private void refreshToolStripMenuItem_Click(object sender, EventArgs e)
{
FillCollection();
}
private void frmMain_FormClosing(object sender, FormClosingEventArgs e)
{
rap.Shutdown();
}
}
|
这是视图定义:
public class TodoView : RaptorDB.View<ToDo>
{
public class RowSchema : RaptorDB.RDBSchema
{
public DateTime Date;
public string Project;
public string Subject;
public string Status;
public string Category;
public bool Done;
public int Priority;
public int TimeEstimate;
}
public TodoView()
{
this.isPrimaryList = true;
this.Name = "Todolist";
this.isActive = true;
this.BackgroundIndexing = false;
this.Schema = typeof(RowSchema);
this.Mapper = (api, docid, doc) =>
{
api.EmitObject(docid, doc);
};
}
}
一致视图
自v1.3以来,添加了“一致视图”的概念,它允许您让非主视图像主视图一样工作,并在RaptorDB 的Save调用中完成数据插入和更新。
这允许您覆盖视图的后台填充,并实时更新视图。显而然,这样做会带来性能损失。
您只需要将视图的ConsistentSaveToThisView 属性设置为True 。
项目指南
您应该了解以下一些指南,它们将帮助您充分利用RaptorDB以及可能的应用程序设计:
- 创建一个实体项目来存放您的数据对象:因为“实体/数据”对象将被您的UI/业务逻辑/数据存储到处使用,所以最好为它们创建一个项目,您可以将其包含在其他项目中,这将迫使您采用仅数据的心态,并将您与将“表单”代码包含在实体中并弄乱引用隔离开来。(例如,在数据访问代码中包含UI组件引用)。
- 将您的视图模式定义包含在实体项目中:因为视图行模式将在您的视图和UI中使用(用于绑定到查询结果),所以最好将其包含在您的“实体”项目中。您可以将其放在视图项目中,但您需要将该项目包含在UI/逻辑项目的引用中并相应地部署。
附录 v1.5
此版本中添加了更多主要功能:
- 备份和主动恢复
- 用户
- 删除文档和删除文件
- 杂项
备份和主动恢复
此版本中添加了备份和恢复功能。备份可以手动或在服务器模式下每天午夜自动进行(目前是硬编码的)。
备份将从上一备份集增量进行,这意味着每次调用Backup 都会创建一个增量备份文件。第一次调用Backup 将执行完整备份,直到RaptorDB 中的最后一个文档。
备份文件在“Data\Backup”文件夹中创建,这些文件通常压缩到95%。该文件夹中维护了一个计数器,该计数器将指示文档存储文件中的最后一个备份位置。
恢复是通过调用Restore 方法完成的,RaptorDB 将开始处理“Data\Restore”文件夹中的文件。恢复过程是非阻塞的,您可以同时使用RaptorDB 。一旦备份文件被处理并恢复,它将被移动到“Data\Restore\Done”文件夹。
恢复文档是一个累加过程,也就是说,如果存在具有相同GUID的现有文档,则将对其进行修订,并作为重复项存在。
用户
身份验证用户现在将检查users.config 文件以获取用户名和密码哈希。
您可以通过调用AddUser 方法来添加用户或更改用户密码。
删除
此版本添加了删除文档和文件的功能,这将把Guid 标记为已删除(它们仍然存在于存储文件中)。删除的文档现在在重建视图和恢复备份时进行处理。
杂项
为了提高服务器模式下的性能,网络流量将通过NetworkClient.cs 文件中的配置限制Param.CompressDataOver 进行压缩,默认设置为1MB,这意味着任何超过1MB的数据都将使用MiniLZO进行压缩。
在用字符串查询过滤时,RaptorDB 现在支持Guid 和DateTime 值,即:
CreateDate = "2012/5/30 11:00" and docid = "f144c10f-0c9e-4068-a99a-1416098b5170"
附录 v1.6 - 事务
虽然事务通常不是NoSQL运动的一部分,但根据用户的要求,它对于需要控制数据流的“业务应用程序”是必需的。在这些情况下,事务非常有意义,并增加了RaptorDB 在这些应用程序中使用的价值。
您需要做的就是将主视图的TransactionMode 属性设置为True ,然后对该视图以及关联的文档类型视图的所有保存都将在事务中一致地处理。在您的映射器方法中,您可以构建复杂的业务逻辑并根据需要Rollback ,如果没有回滚或异常发生,事务将自动提交。
在回滚或异常发生时,不会将任何数据写入docs文件存储,也不会对索引进行任何更新,因此RaptorDB 将处于一致状态。
示例
下面是一个带有为事务模式操作设置的属性的示例视图定义。
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
public class RowSchema : RDBSchema
{
[FullText]
public string CustomerName;
public DateTime Date;
public string Address;
public int Serial;
public byte Status;
}
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.TransactionMode = true; // <-- all you need to set
this.Schema = typeof(SalesInvoiceView.RowSchema);
this.Mapper = (api, docid, doc) =>
{
if (doc.Serial == 0) // <-- some complex business logic
api.RollBack(); // <-- rollback this transaction
api.EmitObject(docid, doc);
};
}
}
由于该视图是主视图,因此所有其他视图更新都将在该事务中进行,如果内部视图回滚,那么整个事务和更新都将被回滚。所有更新将以一致的方式在单个线程中完成。
附录 v1.7 - 服务器端查询
在v1.7之前,您必须在客户端执行聚合查询,这意味着数据必须传输到客户端才能正常工作。显然,当您的视图中有大量数据行时,这会非常耗时且占用带宽(即使有自动压缩)。为了克服这一点,在此版本中,您可以创建“存储过程”之类的函数,您可以将其部署到服务器上,在服务器上执行聚合查询,然后仅将结果传输到客户端。
这是通过以下源代码示例完成的:
public class ServerSide
{
// so the result can be serialized and is not an anonymous type
// since this uses fields, derive from the BindableFields for data binding to work
public class sumtype : RaptorDB.BindableFields
{
public string Product;
public decimal TotalPrice;
public decimal TotalQTY;
}
public static List<object> Sum_Products_based_on_filter(IRaptorDB rap, string filter)
{
var q = rap.Query(typeof(SalesItemRowsView), filter);
List<SalesItemRowsView.RowSchema> list = q.Rows.Cast<SalesItemRowsView.RowSchema>().ToList();
var res = from item in list
group item by item.Product into grouped
select new sumtype // avoid anonymous types
{
Product = grouped.Key,
TotalPrice = grouped.Sum(product => product.Price),
TotalQTY = grouped.Sum(product => product.QTY)
};
return res.ToList<object>();
}
}
您只需要创建一个具有参数类型结构的函数,该函数接收IRaptorDB 接口和一个字符串过滤器属性。
要在代码中调用此方法,您只需执行以下操作:
var q = rap.ServerSide(Views.ServerSide.Sum_Products_based_on_filter,
//"product = \"prod 1\"" // string type filter
(LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3")
).ToList();
dataGridView1.DataSource = qq;
ServerSide 方法允许您以LINQ或字符串格式提供过滤器,就像正常的Query 调用一样。
怪癖
通常,聚合查询使用匿名类,编译器在编译时生成返回类类型,您会神奇地获得工作正常的代码。匿名类型无法序列化,也没有getter/setter,因此在进行sum查询时,您必须自己定义返回类型(这很不方便,因为您必须键入更多内容)。
从上面的代码示例中,您可以看到我定义了sumtype 类,它封装了sum查询的数据结构。由于我定义了带有字段而不是属性(无getter/setter)的类,因此您还必须派生该类RaptorDB.BindableFields 类型,以便数据绑定能够工作,并且基类库控件可以绑定到它并显示数据。
同样,由于ServerSide返回object[],而BCL DataGrid不理解这一点,您需要在使用ToList之前将结果转换为泛型列表,然后再进行数据绑定。
附录 v1.8.3 计数和分页
在此版本中,我添加了以极快的方式在服务器上Count数据并返回结果的功能,因此您可以执行以下操作:
int c = rap.Count("SalesItemRows", "product = \"prod 1\""); // string version
int cc = rap.Count(typeof(SalesItemRowsView),
(LineItem l) => (l.Product == "prod 1" || l.Product == "prod 3")); // linq version
此外,您现在还可以分页查询结果,以提高网络性能,因此所有Query重载都接受start和count参数。
Result q = rap.Query("SalesItemRows", "product = \"prod 1\"", 100, 1000); // skip 100 and give me 1000 rows
附录 Logo 设计
应广大用户要求,我在此添加了新的 Logo 提案,您可以投票选出。
| 新 Logo | 新 Logo | 提案人:Bill Woodruff |
 |
附录 v1.9.0
此版本进行了大量更改,其中最重要的是:
- 支持 MonoDroid
- 新的 Query 模型和类型化结果
- Bug 修复
MonoDroid 支持
在购买了 Asus TF700 Android 平板电脑后,我决定尝试让RaptorDB在上面运行。坏消息是 MonoDroid 不支持CodeDOM,所以我不得不使用Reflection.Emit重写了RaptorDB的一小部分,效果相当不错。成功编译代码后,我发现它在 Android 上不起作用,在调试时,我发现问题出在 Windows '\' 和 Unix '/' 之间的路径分隔符字符差异上,所以我将所有代码更改为使用Path.DirectorySeparatorChar。
这是一个非常令人兴奋的发展,为在移动设备上使用RaptorDB打开了大门。我将在另一篇文章中详细介绍这一点。
新的 Query 模型
现在您可以编写以下代码:
int c = rap.Count<SalesInvoiceView.RowSchema>(x => x.Serial < 100);
var q = rap.Query<SalesInvoiceView.RowSchema>(x => x.Serial < 100, 0, 10); // start at 0 take 10
dataGridView1.DataSource = q.Rows; // Rows is List<SalesInvoiceView.RowSchema>
q= rap.Query<SalesInvoiceView.RowSchema>("serial <100"); // string filter
string s = q.Rows[0].CustomerName; // results are now typed so you don't need casting
如您所见,您可以定义所需的模式并编写非常简短的 LINQ 语句,RaptorDB将确定您的模式所属的视图,并为您提供类型化的结果,因此无需进行类型转换。这意味着更少的输入,这总是很棒的。旧的查询模型仍然有效。
注释:
- 使用此样式时,您可以自由地自己定义视图的模式,并将它们定义在视图程序集之外(最有可能在您的“实体”程序集中),并在应用程序中获得类型化的结果,而无需依赖
RDBSchema。现在,在执行此操作时,您必须确保在模式中定义docid属性,如果您希望 .NET 的数据绑定与 BCL 控件一起使用,则必须定义属性(商业组件也可以绑定到字段,但 BCL 不能)。 -
使用自己的模式时,您可以使用
view.FullTextColumns属性,并为全文索引提供列名(支持任何大小写)。
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
// define your own row schema below (you must define a 'docid' property)
// this can be in any assembly that this view can see
public class RowSchema // my own schema not derived from RDBSchema
{
public string CustomerName { get; set; }
public DateTime Date { get; set; }
public string Address { get; set; }
public int Serial { get; set; }
public byte Status { get; set; }
public bool Approved { get; set; }
public Guid docid { get; set; } // must exist
}
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 3;
//// uncomment the following for transaction mode
//this.TransactionMode = true;
this.Schema = typeof(SalesInvoiceView.RowSchema);
// you can define full text column this way also
this.FullTextColumns = new List<string> { "customername" };
this.Mapper = (api, docid, doc) =>
{
//int c = api.Count("SalesItemRows", "product = \"prod 1\"");
if (doc.Serial == 0)
api.RollBack();
api.EmitObject(docid, doc);
};
}
}
Bug 修复
还进行了大量 Bug 修复和增强,其中最突出的是位图索引上的 Not 查询现在会扩展以包含所有视图行,并且在视图重建时可以正确处理已删除的文档。不幸的是,用于已删除文件处理的存储文件已更改,并且不向后兼容。
附录 v1.9.2
现在支持不区分大小写的列搜索,方法是设置模式列上的CaseInsensitive属性,或将列名添加到视图的CaseInsensitiveColumns属性中(后者适用于您不想将依赖项传播到RaptorDB中,即在不依赖RaptorDB的情况下定义实体类和模式定义作为独立 DLL)。
...
public class RowSchema : RDBSchema
{
[FullText]
public string CustomerName;
[CaseInsensitive]
public string NoCase; // case insensitive searching
public DateTime Date;
public string Address;
public int Serial;
public byte Status;
public bool Approved;
}
public SalesInvoiceView()
{
...
this.Schema = typeof(SalesInvoiceView.RowSchema);
this.CaseInsensitiveColumns.Add("nocase"); // this or the attribute
此外,现在支持在 LINQ 中查询!=或NotEqual。
int c = rap.Count<SalesInvoiceView.RowSchema>(x => x.Serial != 100);
附录 v2.0.0
在此版本中,添加了对原始文档进行全文搜索的功能,而无需考虑视图。为了支持这一点以及获取文档更改的功能,存储文件已更改,因此现有存储文件中的数据将无法使用(存储文件升级功能暂时省略,如果您需要此功能,请联系我)。
要使用新功能,您只需:
int[] results = rap.FullTextSearch("search"); // hoot/lucene style query string
object o = rap.FetchVersion(results[0]); // fetch the first in the list
获取文档的更改历史记录
int[] history = rap.FetchHistory(guid);
object o = rap.FetchVersion(history[0]);
文件存储(字节)的接口相同:FetchBytesHistory()和FetchBytesVersion()。
附录 v2.0.5
在此版本中,RaptorDB现在通过以下配置点支持内存限制:
Global.MemoryLimit:默认值为100,意味着如果GC.GetTotalMemory()的值大于 100mb,则开始释放内存。您可以增加此值以在内存中存储更多索引数据以提高性能。GC.GetTotalMemory提供的值与任务管理器中的值不完全相同(您会在任务管理器中看到更高的值)。Global.FreeMemoryTimerSeconds:默认值为60秒,会触发以检查内存使用情况并根据需要进行释放。
此外,为了使事情更加健壮,视图索引数据将按时保存到磁盘,这将加快关闭速度。
附录 v3.0.0 - 复制
此版本进行了大量更改,可视为重大升级,部分更改如下:
- 所有数据文件都以共享读取模式打开,因此您可以复制正在运行的服务器的数据文件夹以进行在线备份。
- 已添加 cron 调度程序用于定时作业。
- 数据文件的新存储格式。
- 使用
Global.RequirePrimaryView = false以键/值模式运行。 - 脚本视图
- HQ-Branch 复制
新的存储格式
为了克服灵活性上的一个重大缺点,以及我最初决定将格式做得太脆弱的糟糕决定,我已经将存储文件格式更改为下图所示:

这种新格式有望成为最后的破坏性更改,因为它比以前更灵活、更健壮。
版本。新格式以以下 2 种模式运行:
- 元数据模式:每条记录都有关联的元数据。
- 原始模式:用于视图数据存储,没有元数据。
元数据以 BinaryJSON 格式存储,但您可以选择 BinaryJSON 或文本 JSON 进行对象序列化,反序列化器将为您提供您选择的正确格式(在同一个文件中)。元数据目前具有以下属性(将来可能会添加更多属性而不会破坏兼容性):
- 对象类型名称(完全限定)
- 已删除
- 已复制
- 键值
- 序列化对象字节大小
- 保存的日期和时间
Cron 调度
已添加 cron 调度守护程序,以便您可以控制RaptorDB内部的各个方面。Cron 一开始可能会令人生畏,但一旦您掌握了它,它就非常、非常强大。为了帮助您入门,这里有一个快速入门指南:
- Cron 的分辨率为一分钟。
- cron 字符串格式为:
Minutes Hours Day_Of_Month Month_Of_Year Day_Of_Week - 您在占位符中输入数字。
- 您可以在占位符中输入星号(*),表示“每”。
- 您可以使用连字符(-)输入范围,中间不带空格:
0-10表示零到十。 - 您可以使用逗号(,)输入离散值,中间不带空格:
2,4,6。 Day_Of_Week从 0=星期日开始……- 您可以使用斜杠(/)指定除数。
- 您可以省略尾随值,假设为(*):
*/5等同于*/5 * * * *。
示例
* * * * * : every minute */10 * * * * : every 10 minutes 0 * * * * : every hour at the top of the hour 0 0 * * * : every day at midnight * 0 * * * : every minute between midnight and 1am 15 * * * * : every hour at 15 minutes past the hour 0 12 * * 1,2,3,4,5 : every week day at 12 noon */2 * * * * : every even minute 0-30/3 9-17 * * * : every third minute at the top of each hour from 9am to 5pm
C# 脚本视图
您现在可以以脚本形式定义视图,并将它们放在服务器上的 Views 文件夹中,RaptorDB将自动构建并使用它们。这是一个强大的功能,允许您使用记事本(或您选择的任何文本编辑器)在运行时调整视图定义。
- 如果您需要在脚本文件中引用,可以在顶部添加以下内容(通常用于访问实体类,例如下面的示例中的 SalesInvoice):
// ref : filename.dll - 您可以在脚本文件中为动态视图定义行模式(显然,如果您需要从客户端代码中访问属性,例如
row.Name等,那么行模式应该在别处定义,并在客户端和服务器上像数据实体类一样引用它)。 - 如果行模式在脚本文件中定义,那么在运行时使用时,脚本 DLL 文件将被传输到客户端并加载,以便反序列化能够正常工作,您可以看到您的数据。这是一个非常强大的功能。
// ref: views.dll
using System;
using System.Collections.Generic;
using RaptorDB;
namespace SampleViews
{
[RegisterView]
public class testing : View<SalesInvoice>
{
// row schema defined in the script file
// and will be transferred to the client when needed
public class RowSchema : RDBSchema
{
public string Product;
public decimal QTY;
public decimal Price;
public decimal Discount;
}
public testing()
{
this.Name = "testing";
this.Description = "";
this.isPrimaryList = false;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 3;
this.Schema = typeof(RowSchema);
this.Mapper = (api, docid, doc) =>
{
foreach (var i in doc.Items)
api.EmitObject(docid, i);
};
}
}
}
复制
此版本中的一个主要功能是RaptorDB能够跨进程边界和服务器复制数据。这允许您在不同位置创建和维护“企业”应用程序。RaptorDB 以半在线总部/分支机构风格实现复制,数据会定期在服务器之间传输。
- 目前,TCP 连接没有高级安全功能,因此如果您确实需要,建议您首先在服务器之间设置 VPN 连接。

复制可以视为以下内容:
- 什么:您想复制什么,即需要传输的文档类型。
- 哪里:数据应该去哪里或目标点。
- 何时:数据应该何时传输或数据移动的频率。
- 如何:数据应该如何传输或使用的协议。
如何目前是基于 TCP 的数据序列化协议,端口号可自定义,默认为9999。何时是基于 cron 的计划。
设置复制
为了使复制正常工作,您需要 1 个主服务器或总部服务器和至少 1 个分支服务器。要设置复制,您需要编辑 HQ 服务器上的RaptorDB-Replication.config文件,并编辑其他服务器上的RaptorDB-Branch.config文件。
- 所有操作都将在 RaptorDB 的数据目录中的 Replication 文件夹中进行。
- 您也可以在嵌入式模式下进行复制,并配置上述文件。
- 您可以配置每次传输多少项,默认值为 10,000 个文档,这是为了限制文件大小,以便于在网络上传输。
- 您可能会配置 cron 作业,以便在一段时间内进行复制,例如每 5 分钟从午夜到凌晨 1 点,如果服务器上可能生成超过 10,000 个文档。
故障排除
如果数据传输包中保存的文档在目标机器上无法反序列化,则可能发生故障。
- 所有操作和异常都记录在数据文件夹的日志文件中。
- 如果复制收件箱包含类似“0000000n.error.txt”的文件,则表示发生了错误,其内容将显示了问题的所在以及有问题的 JSON。
- 如果无法克服异常,您可以递增“0000000n.counter”文件来跳过有问题的文档。
- 如果发生故障,您可以选择性地删除复制文件夹中的文件,甚至删除整个文件夹,系统将重新启动,并且鉴于文档是可传输且本质上是可重入的,一切应该都没问题。
所有操作都是可恢复的,并在重启或发生错误后从最后一点继续。
配置文件
此版本中的所有配置文件都带有“RaptorDB-”前缀,因此前版本中的“users.config”文件现在是“RaptorDB-Users.config”。
- 引擎启动时会检查是否有配置文件,如果没有,则会创建一个带有“-”前缀的示例文件,您可以对其进行编辑并从模板重新启动。
RaptorDB.config
下面是通用配置文件(JSON 格式)的示例:
{
"BitmapOffsetSwitchOverCount" : 10,
"BackgroundSaveToOtherViews" : true,
"DefaultStringKeySize" : 60,
"FreeBitmapMemoryOnSave" : false,
"PageItemCount" : 10000,
"SaveIndexToDiskTimerSeconds" : 60,
"FlushStorageFileImmediatley" : false,
"SaveAsBinaryJSON" : true,
"TaskCleanupTimerSeconds" : 3,
"BackgroundSaveViewTimer" : 1,
"BackgroundViewSaveBatchSize" : 1000000,
"RestoreTimerSeconds" : 10,
"FullTextTimerSeconds" : 15,
"BackgroundFullIndexSize" : 10000,
"FreeMemoryTimerSeconds" : 60,
"MemoryLimit" : 100,
"BackupCronSchedule" : "0 1 * * *",
"RequirePrimaryView" : true,
"PackageSizeItemCountLimit" : 10000
}
此文件本质上是 RaptorDB 的内部参数,因此您可以在不重新编译服务器的情况下在运行时微调引擎。
- 如果您不确定,建议不要更改这些设置。
RaptorDB-Replication.config
下面是服务器端复制配置文件(JSON 格式)的示例:
{
"ReplicationPort" : 9999,
"Where" :
[
{
"BranchName" : "b1",
"Password" : "xxxxx",
"What" : "default",
"When" : "0 * * * *"
},
{
"BranchName" : "b2",
"Password" : "yyyyy",
"What" : "b2",
"When" : "*/5 * * * *"
},
],
"What" :
[
{
"Name" : "default",
"Version" : 1,
"PropogateHQDeletes" : true,
"PackageItemLimit" : 10000,
"HQ2Btypes" : [""],
"B2HQtypes" : ["*"]
},
{
"Name" : "b2",
"Version" : 1,
"PropogateHQDeletes" : false,
"PackageItemLimit" : 0,
"HQ2Btypes" : [""],
"B2HQtypes" : ["namespaceX.type1", "namespaceY.*"]
}
]
}
主要有两个部分:“where”和“what”。
- 您首先定义分支服务器的 where 部分,其中包括“when”cron 计划和下面的“what”引用名称。下面部分。
- 您可以定义一个“default”what 配置,或者一个名为“what”的分支。
HQ2Btypes是将类型从 HQ 传输到分支的类型。B2HQtypes是将类型从分支传输到 HQ 的类型。- 类型定义为 .net 类型名称的列表。
- 类型列表中的
""表示无。 *是匹配该定义的多个类型的占位符,因此“*”表示发送所有内容,“namespaceX.*”表示发送所有匹配“namespaceX”的命名空间,依此类推。- 您可以将包文档计数限制为一个数字,或将其设置为 0,表示“RaptorDB.config”中定义的全局限制。
PropogateHQDeletes控制在 HQ 中删除文档时,分支服务器上的文档是否也删除。- 密码以明文形式存储,没有任何加密。
RaptorDB-Branch.config
下面是分支配置文件(JSON 格式)的示例:
{
"ServerAddress" : "192.168.1.6",
"ServerReplicationPort" : 9999,
"Password" : "xxxxx",
"BranchName" : "b1"
}
只需填写您分支服务器的数据即可。
- 密码以明文形式存储,没有任何加密。
文件夹结构
DATA Folder
|
|- Replication > (branch mode)
| |-: branch.dat
| |
. |- Inbox >
| |-: 0000000n.mgdat.gz,
|
|- Outbox >
- 如果收件箱包含类似“0000000n.counter”的文件,则表示发生了错误,文本在“0000000n.error.txt”中。
- 如果无法克服异常,您可以递增“counter”文件来跳过有问题的文档。
- 在分支模式下,文件将下载到收件箱文件夹。
- “Replication”文件夹中的“branch.dat”存储复制计数器信息。
DATA Folder
|
|- Replication > (HQ mode)
| |-
| |
| |- Inbox >
| | |
. | |- BranchName1 >
| | |-: 0000000n.mgdat.gz
| | |
|
|- Outbox >
| |
| |- BranchName1 >
| |- BranchName2 >
- 如果收件箱包含:“0000000n.error.txt”,则表示发生了错误。
- 如果无法克服异常,您可以递增“counter”文件来跳过有问题的文档。
- *.last 文件存储分支最后传输的文档计数器。
附录 v3.1.0 - 查询排序
在此版本中,已删除旧式查询模型(指定类型等),取而代之的是新模型,您可以使用通用接口并指定行模式。
另一个重大更新是能够根据视图列对数据进行排序,这在进行分页时非常有用。因此,重载现在支持“orderby”字符串参数,您可以在其中指定要排序的列。通过在字符串后附加“desc”可以按降序排序。
// page the results in 10's and sort in decrementing order on the serial column
var q = rap.Query<SalesInvoiceViewRowSchema>(x => x.Serial < 100, 0, 10, "serial desc");
附录 v3.1.3 - 自我实践和实际使用
我最近有机会将理论付诸实践,在实际环境中使用了RaptorDB,并完全基于它构建了一个业务应用程序。细节我将省略,因为它不像概念和最佳实践那么重要。
版本 3.1.1 到 3.1.3 中发生的大部分变化都是创建该应用程序所获得的见解的直接结果。
令人惊讶的是,应用程序的核心是两个大小为 200kb 的 DLL,与使用的华丽 UI 组件(超过 30mb)相比,这简直是微不足道的。
序列号和行号
大多数应用程序都需要一种在数据库层生成的唯一递增编号(行号、ID 等),那么如何在RaptorDB中实现这一点呢?
假设我们有
class Invoice { InvoiceNumber : int }
在发票视图的映射函数中,添加了以下api方法:
Mapper = (api, guid, doc) =>
{
if (doc.InvoiceNumber == 0) // check if not set in the doc
doc.InvoiceNumber = api.NextRowNumber(); // get a row number
api.EmitObject(guid, doc);
};
这里有一个关于RaptorDB如何保存数据的附注。
- 通常,
RaptorDB会将文档先保存到 doc 存储,然后再保存到视图。在这种情况下,对于InvoiceNumber,文档将以 0 保存,当我们获取该发票时,行号将丢失。
- 幸运的是,如果为该文档的“primary view”启用了
Transactions,则保存顺序会颠倒,如下所示:- 首先调用相关视图。
- 如果一切正常(即没有
RollBack),则将文档保存到磁盘。 - 因此,对于我们的
InvoiceNumber,任何对其(或其他任何属性)的更改,如果来自调用映射函数,都将被保留并保存。
从视图中删除
通常,插入和更新视图很容易,但是如何从视图中删除呢?如果您在视图上启用了DeleteBeforeInsert = true,那么RaptorDB将按Guid删除文档,然后再插入新数据。因此,您只需要为带有删除标志的发票执行以下操作:
Mapper = (api, guid, doc) =>
{
if (doc.isDeleted == false) // if the delete flag is not set on the invoice
{
if (doc.InvoiceNumber == 0)
doc.InvoiceNumber = api.NextRowNumber();
api.EmitObject(guid, doc);
}
};
或者,您可以保存一个子类,如DeleteSupplierRequest,并使用此映射器:
Mapper = (api, guid, doc) =>
{
if (doc.GetType() != typeof(DeleteSupplierRequest)) // otherwise it is deleted
{
doc.orgItem.Compute();
doc.Description = doc.orgItem.Description;
api.EmitObject(guid, doc);
}
};
以上两者都不会向视图输出任何行,因此结合DeleteBeforeInsert,您就可以从视图中删除了数据。
这里有一个非常重要的注意事项:
- 我们不会丢失任何数据,因为
RaptorDB是追加式的,并且存储了您保存的所有文档,无论是否已删除。因此,如果您需要,可以更改映射器并重建视图以进行恢复等。如果您知道文档的Guid,可以通过FetchHistory()或FetchHistoryInfo()(后者提供更改日期)获取其历史记录。
对其他视图的操作
RaptorDB的一个设计缺陷是,您不能直接更改视图数据,除了文档被分配用于处理的视图。例如,您不能在映射函数中插入或更改另一个视图中的数据(这可能会在更高版本中改变,但目前没有),也不能将非子类(非相关)对象分配给视图,因此唯一的方法是自己以编程方式进行保存。 if (_raptorDB.Save(_invoice.GUID, _invoice))
{
// reload to get changed values (invoice number)
var inv = (Invoice)_raptorDB.Fetch(_invoice.GUID);
if (inv == null)
return false;
_invoice = inv;
// save all products
_invoice.Items.ForEach(x => _raptorDB.Save(x.id, x));
// save supplier request data here
foreach (var i in _invoice.Items)
{
SupplierRequest s = new SupplierRequest(_invoice, i);
_raptorDB.Save(s.GUID, s);
}
return true;
}
现在,可以争辩说上面的代码将在您的服务器业务层上运行,但如果它在Invoice保存的映射函数中,会更清晰。
开发技巧
这里有一些有用的开发技巧:
- 虽然您可以随时递增
view.Version号(如果您已部署到客户端,则必须这样做),但对于视图更改,调试的快速解决方法是删除 views 文件夹,RaptorDB将重建该视图。 - 对于业务应用程序,您可能应该设置
BackgroundIndexing = false和TransactionMode = true,这样您就可以立即看到更改,并且视图映射函数中的文档操作得以保留。 - 创建单独的实体和视图项目,并将模式定义放在实体项目中。这样,您就可以操作和处理
Query()的返回值,并获得智能感知语句补全。
附录 v3.1.4 - ViewDelete & ViewInsert
继续我的自我实践和实际使用,我正在将另一个应用程序从 MySql 迁移到RaptorDB,并遇到了直接删除和插入视图的需求,因为重构应用程序以适应面向文档的版本过于繁琐,所以现在您可以这样做:
// this will directly delete rows from the view with the schema of PermissionSchema
int rowsdeleted = raptorDB.ViewDelete<PermissionsSchema>(x => x.Path == "there"); // based on this filter
// create a row schema object to insert
var c = new PermissionsSchema();
c.docid = Guid.NewGuid();
c.Path = "here";
// insert the above row into a view with the schema of PermissionSchema
raptorDB.ViewInsert<PermissionsSchema>(c.docid, c);
以上对视图的直接操作是完全可重建的,并且在内部由主存储文件中的“文档”支持,因此就像操作正常执行一样,您将拥有一个日志。
附录 v3.1.6 - 分割存储文件
继续在生产环境中的自我实践,在此版本中,您可以通过将 Global.SplitStorageFilesMegaBytes配置设置为某个值(默认值为 0,表示关闭)来分割文档存储文件。
此功能面向 DevOps/管理员,使他们能够进行更小的增量每日备份,例如,而不是对整个更改的.mgdat文件进行 100GB 的每日备份,备份将只包含每日更改的数量,这将允许在备份介质已满之前进行更多备份。
- 您可以随时设置和取消设置此值,
RaptorDB将正确处理。 - 设置后,
.mgdat文件将在大小限制附近分割成一个新文件(它可能会超过大小,因为它会将最后一个文档保留在同一个文件中,而不是将其分割成两个文件)。 - 最后一个文件始终是
.mgdat,第一个文件是.mgdat00000。 - 视图重建不受影响,并将正常工作。
附录 v3.2.0 - 高频存储文件
此版本进行了一些重大更改,其中一些是:
- 您现在可以使用
Global.CompressDocumentOverKiloBytes配置来压缩文档,默认为超过 100kb 的文档。 - 视图将在启动时检查完整性,并在需要时重建(例如,在非正常关闭后)。
- 添加了一个新的键/值存储文件,用于高频更新项,该文件将回收磁盘空间(即非追加式)。
引言
新的存储系统本质上定义为Dictionary<string,object>键/值存储,键为字符串,确保了最广泛的用例。您必须注意以下几点:
- 键目前限制为 255 字节的 UTF8 字符串。
- 保存到此存储不会影响视图(不会发生映射)。
- 您将没有以前的值,旧值将被覆盖。
- 存储文件实现为大小为
Global.HighFrequencyKVDiskBlockSize的磁盘块的链表,默认为 2048 字节(除非您知道自己在做什么,否则请勿使用小于 512 的值),请参阅下面的文件格式部分。 - 删除将立即释放键使用的所有块,并将旧值设置的起始块标记为已删除。
新的存储文件适用于快速和周期性地保存相同键的数据,例如状态信息,而您不关心数据的历史记录,只关心当前值。
数据完整性
由于新存储文件会回收可用空间(与追加式模型相反),因此数据损坏的可能性很大。为了确保数据完整性,RaptorDB执行以下操作:
- 新项目使用可用空间或追加到文件末尾,然后如果旧键存在,则将其所有块标记为空闲。这确保了在发生故障时,至少旧值不会被覆盖并且可以恢复。
- 如果发生非正常关闭,
RaptorDB将通过遍历每个块来自动重建键索引和空闲块列表。
文件格式
创建了一个新的文件格式,该格式实现为磁盘块的链表。每个块都有一个标题部分,其中包含有关数据如何在块中保存以及下一个块的信息,然后是键字节,限制为 255 字节,之后写入实际数据,直到达到块大小。
标题和键部分在列表中的每个块中重复,以确保数据完整性。
默认块大小为 2048 字节,除非您确切知道要保存的数据类型和要使用的最大键长度,否则不应低于 512 字节。

需要注意的一些事项:
- 无论每个块中剩余的可用字节多少,都会分配一个块,即如果数据小于块大小,块内的空间将丢失。
- 使用较小的块大小可能会提供更好/更小的文件大小,但如果数据大于每个块的空间,则需要更多的寻道。
- 由于标题为 15 字节,最大键大小为 255 字节,因此您不能低于 270 字节,除非您限制了键长度并且您的数据很短。
- 您可以随时调用
CompactStorageHF()来回收存储空间并减小存储文件大小。压缩后,原始文件将保存在old文件夹中。
用法
您可以通过以下接口访问新功能:
// when rdb is a RaptorDB.RaptorDB class or the RaptorDB.IRaptorDB interface
var kv = rdb.GetKVHF(); // returns the IKeyStoreHF interface
上述接口具有以下方法:
public interface IKeyStoreHF
{
object GetObjectHF(string key);
bool SetObjectHF(string key, object obj);
bool DeleteKeyHF(string key);
int CountHF();
bool ContainsHF(string key);
string[] GetKeysHF();
void CompactStorageHF();
}
上述接口本身就很容易理解。
高级主题
在所有写入操作中,都会创建一个名为temp.$的特殊文件,表示数据已更改的操作,因此在系统发生故障时,RaptorDB将知道重建索引。
您可以通过将上述文件添加到视图文件夹或新键/值存储的DataHF文件夹来触发重建过程。
另外一点:
继续在其他平台上进行测试,下面是一个动画 GIF,展示了RaptorDB在我之前安装了mono-complete的 Ubuntu 虚拟机上按原样运行。

附录 v3.2.5 - 新的字符串索引
一个长期存在的恼人问题是字符串索引的存储成本,因为字符串的大小是可变的,当您对其进行索引时,别无选择,只能采用可能的最大长度并为其分配存储空间,而不管其实际大小,因为您必须处理索引页的可变长度,这会变得非常混乱。
因此,在此版本中,并基于新的可回收存储文件格式,MGIndex<string>类型的索引将在外部MGHF文件中存储实际字符串,并在IDX文件中存储引用,这意味着这些类型的索引的存储大小大大减小。
您可以通过Global.EnableOptimizedStringIndex标志来控制此新文件的创建,该标志默认设置为 true。请注意:
- 以前的索引风格仍然有效,并且向后兼容。
- 新索引将在需要时在
View重建时构建,并且上述标志允许这样做。
附录 v3.2.14 - HFKV Increment() Decrement()
继续我对RaptorDB的实际使用,我为高频键值存储添加了原子Increment/Decrement(用于int、decimal值),RaptorDB确保更新是原子和一致的,可用于:
- 计数器
- 库存值
此外,全文搜索的边缘情况最终应该被涵盖,因此您可以执行:
- address = "-oak -*l" = 非 oak 且不以 l 结尾(非 hill、laurel 等)
附录 v3.2.15 - 全文搜索更改
从这个版本开始,全文搜索的处理方式发生了变化,因此使用 + 现在表示 OR(这是一个破坏性更改,但希望更有意义)。
所以
"15 franklin" = 15 and franklin "15 franklins" = 15 and franklins -> which will show no results since fanklins does not exist "15 +franklin" = 15 or franklin
附录 v3.3.0 - Web Studio

期待已久,RaptorDB终于有了 Web 界面。之所以等待,主要是因为我需要“理解”JavaScript 和 Web 开发,而这仍在进行中。此更新的部分内容来自 REST API 文章(https://codeproject.org.cn/Articles/678295/RaptorDB-REST),该文章已集成到主代码库中,并将继续在此处。
目前,此 Web 界面是只读的,并且执行非破坏性操作,出于安全原因,默认只允许本地计算机访问。将来,当我实现访问控制后,这可能会改变。
此 UI 使用纯 JavaScript,并且是从头开始编写的,没有任何依赖项,甚至“$”操作也是我编写的临时替代品。
JavaScript 需要现代浏览器,并且可以在 IE10+ 上运行(IE8、IE9 过于麻烦,而且鉴于我从头开始编写一切,不值得付出努力)。
您中间的 JavaScript 大师们可能会抱怨代码。
如何启用 Web Studio
默认情况下,Web Studio UI 是禁用的,您可以通过以下配置参数进行控制:
"EnableWebStudio" : true,
"WebStudioPort" : 91,
出于安全原因,Web UI 默认仅限于本地主机。您可以通过设置以下参数来启用来自任何地址的连接:
"LocalOnlyWebStudio" : false
您可以做什么
RaptorDB的大部分主要功能都可以通过 Web UI 访问,例如:
- 查询
- 视图模式
- 文档视图和历史记录
- 系统信息和日志
- 高频键/值浏览
查询
您可以通过查询选项卡访问您的数据,该选项卡支持分页、过滤、排序和导出到 Excel。
要过滤查询,您可以单击列名,它将添加到您的过滤器文本框中并添加您想要的过滤器,例如:
Address = "hill" and serial < 100 or Address = "hill -oak" and serial < 100
您可以单击列名来对列数据进行排序。如果您单击“docid”列下的链接,您将看到与该行关联的底层文档。
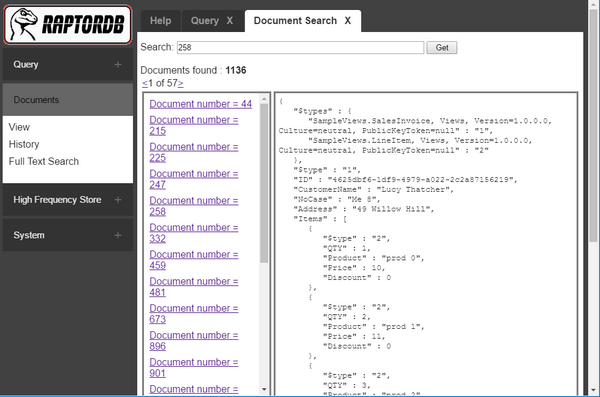
文档视图和历史记录
您可以在“Documents”菜单下查看实际文档的 JSON 并查看所做的任何修订。原始 JSON 文档的全文搜索也受支持。

系统信息
在系统信息菜单下,您可以看到最后 100 条日志项,以及服务器的调试信息和当前配置参数。
在此选项卡下,您还可以备份当前数据并优化高频数据存储。

高频键存储
在此菜单下,您可以浏览高频键/值存储,并查看您为每个键存储的内容的 JSON 表示。

入门
概念
RaptorDB 是一个基于 JSON 的键值存储,带有映射函数,将文档映射到视图以进行查询。因此,其核心是使用 Save() 保存文档实体,并使用 Fetch() 获取相同的实体。键值存储非常有用,但对于大多数应用程序,您需要查询和聚合文档的各个部分,因此您需要定义视图来从这些文档中提取信息。提取此类信息是为了性能。
一次只有一个 RaptorDB 实例可以访问数据文件夹(虽然文件以共享模式打开,因此您可以进行热备份,但两个实例不能共享相同的文件和文件夹)。
虽然 NoSQL 运动倡导“无模式”设计,但这并不意味着没有模式,而是减少了对模式的依赖或模式隔离,即在不破坏其他部分的情况下更改事物的能力,因为要以高性能完成任何事情,您都需要了解您的数据类型和结构,否则查询将仅限于全文搜索(在这种方式下,文本数据会丢失类型信息)。
安装
您可以通过 NuGet 安装 RaptorDB 到您的项目中,搜索 RaptorDB_doc,或手动添加 2 个 DLL 引用:- RaptorDB.dll:主服务器代码
- RaptorDB.Common.dll:嵌入式和客户端/服务器的通用库
您的第一个项目
完整源代码:无法解析文件宏,文件名或 ID 无效。为演示起见,我们将创建一个控制台应用程序项目(您可以使用 Visual Studio 创建任何类型的应用程序)。我们的第一个项目将在嵌入式模式下使用 RaptorDB,这意味着数据库将共享控制台进程的内存。
由于 RaptorDB 需要维护大量状态,因此我们应该为它创建一个全局变量,以便我们可以在代码的任何地方访问它并拥有一个实例。
class Program
{
static RaptorDB.RaptorDB rdb; // 1 instance
static void Main(string[] args)
{
rdb = RaptorDB.RaptorDB.Open("data"); // a "data" folder beside the executable
RaptorDB.Global.RequirePrimaryView = false;
DoWork();
Console.WriteLine("press any key...");
Console.ReadKey();
Console.WriteLine("\r\nShutting down...");
rdb.Shutdown(); // explicit shutdown
}
...
对于我们的第一个示例,我们将禁用文档必须定义主视图的需求,并将 RaptorDB 主要用作键值存储。
现在让我们保存一些数据:
static void DoWork()
{
Console.Write("Inserting 100,000 documents...");
int count = 100000;
for (int i = 0; i < count; i++)
{
var inv = CreateInvoice(i);
// save here
rdb.Save(inv.ID, inv);
}
Console.WriteLine("done.");
}
static SalesInvoice CreateInvoice(int counter)
{
// new invoice
var inv = new SalesInvoice()
{
Date = Faker.DateTimeFaker.BirthDay(),
Serial = counter % 10000,
CustomerName = Faker.NameFaker.Name(),
NoCase = "Me " + counter % 10,
Status = (byte)(counter % 4),
Address = Faker.LocationFaker.Street(),
Approved = counter % 100 == 0 ? true : false
};
// new line items
inv.Items = new List<LineItem>();
for (int k = 0; k < 5; k++)
inv.Items.Add(new LineItem() { Product = "prod " + k, Discount = 0, Price = 10 + k, QTY = 1 + k });
return inv;
}
var obj = rdb.Fetch(known_guid); // obj will be a SalesInvoice from the above data
public class SalesInvoiceViewRowSchema : RDBSchema
{
public string CustomerName;
public string NoCase;
public DateTime Date;
public string Address;
public int Serial;
}
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 1;
this.Schema = typeof(SalesInvoiceViewRowSchema);
this.Mapper = (api, docid, doc) =>
{
api.EmitObject(docid, doc);
};
}
}
static void Main(string[] args)
{
rdb = RaptorDB.RaptorDB.Open("data"); // a "data" folder beside the executable
RaptorDB.Global.RequirePrimaryView = false;
Console.WriteLine("Registering views..");
rdb.RegisterView(new SalesInvoiceView());
...
<span class="codeInline">DoWork()</span>变为: static void DoWork()
{
long c = rdb.DocumentCount();
if (c > 0) // not the first time running
{
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial < 100);
// show the rows
Console.WriteLine(fastJSON.JSON.ToNiceJSON(result.Rows, new fastJSON.JSONParameters { UseExtensions = false, UseFastGuid = false }));
// show the count
Console.WriteLine("Query result count = " + result.Count);
return;
}
Console.Write("Inserting 100,000 documents...");
int count = 100000;
for (int i = 0; i < count; i++)
{
var inv = CreateInvoice(i);
// save here
rdb.Save(inv.ID, inv);
}
Console.WriteLine("done.");
}
- 我们正在使用 fastJSON 的美化输出显示数据返回,fastJSON 内置于 RaptorDB 中。
- 在重新运行我们更改的代码时,视图已自动重建,并且包含我们已保存的数据,我们的查询有效(您需要再次运行一次才能看到查询结果,因为引擎将在后台重建视图,在查询执行时将不可用)。
- 我们没有做任何事情来定义索引,所有这些都为我们处理好了。
- 数据以类型化格式返回给我们,类似于类型化数据集(如果您熟悉的话)。
- 数据是从我们定义的视图返回的,而不是原始文档。
- 整个过程是类型安全的,并且编译器会帮助您纠正错误,而不是在运行时出错,这与字符串 SQL 查询类似(如果您需要动态查询,您也可以使用字符串过滤器,但显然编译器无法帮助您纠正错误)。
现在 Query() 有几个重载来控制基于条件的 Paging 和 Sorting:
// string based view names and object row returns
public Result<object> Query(string viewname);
public Result<object> Query(string viewname, string filter);
public Result<object> Query(string viewname, int start, int count);
public Result<object> Query(string viewname, string filter, int start, int count);
public Result<object> Query(string viewname, string filter, int start, int count, string orderby);
// string based filters and typed row returns (the view is determined by the schema you used)
public Result<TRowSchema> Query<TRowSchema>(string filter);
public Result<TRowSchema> Query<TRowSchema>(string filter, int start, int count);
public Result<TRowSchema> Query<TRowSchema>(string filter, int start, int count, string orderby);
// LINQ predicate filters and typed row returns (the view is determined by the schema you used)
public Result<TRowSchema> Query<TRowSchema>(Expression<Predicate<TRowSchema>> filter);
public Result<TRowSchema> Query<TRowSchema>(Expression<Predicate<TRowSchema>> filter, int start, int count);
public Result<TRowSchema> Query<TRowSchema>(Expression<Predicate<TRowSchema>> filter, int start, int count, string orderby);
哎呀!事情在变化。
现在假设我们低估了查询所需的内容,就像生活一样,需求在变化,那么我们该怎么办?好吧!对于 RaptorDB 来说很简单,我们只需要像下面这样更改我们的模式和视图:
public class SalesInvoiceViewRowSchema : RDBSchema
{
public string CustomerName;
public string NoCase;
public DateTime Date;
public string Address;
public int Serial;
public byte Status; // added to the view
public bool? Approved; // added to the view
}
[RegisterView]
public class SalesInvoiceView : View<SalesInvoice>
{
public SalesInvoiceView()
{
this.Name = "SalesInvoice";
this.Description = "A primary view for SalesInvoices";
this.isPrimaryList = true;
this.isActive = true;
this.BackgroundIndexing = true;
this.Version = 2; // <- increment when you make changes and want a rebuild
this.Schema = typeof(SalesInvoiceViewRowSchema);
this.Mapper = (api, docid, doc) =>
{
if (doc.Status == 0) // status = 0 means a draft and should not be saved
return;
api.EmitObject(docid, doc);
};
}
}
附注
- 上面的视图是主列表,我们可能不想不保存,因为没有引用可以检索 SalesInvoice,您可能根据状态(例如)在其他详细信息或汇总视图中执行此类过滤。上面的仅用于演示目的。
- 正如您所见,我们可以更改视图模式和/或文档的处理方式,我们只需要更改 Version 号即可让 RaptorDB 知道何时重建视图内容。
附录 v3.3.8 - nscript.exe
在此版本中,我添加了nscript.exe工具,该工具允许轻松运行和测试 C# 脚本文件,这些文件我已经使用很久了。该文件将编译并运行给定的脚本。此外,sample.cs文件现在是主 zip 文件的一部分,并已放入“test script”文件夹。
所以现在您可以轻松地像这样运行任何 C# 文件:
# run any cs file c:\rdb\test script> ..\tools\nscript.exe sample.cs # or just run the batch file c:\rdb\test script> run.cmd
sample.cs文件现在在顶部包含一个注释部分,用于指定使用的引用,这将告诉nscript.exe在哪里可以找到 DLL 文件。
// ref : ..\output\raptordb.dll
// ref : ..\output\raptordb.common.dll
// ref : ..\faker.dll
using System;
using System.Collections.Generic;
...
希望这能方便地测试和修改给定的示例,而无需经历创建项目文件的过程,这对一些人来说一直是一个障碍。
附录 v3.3.9 - Between() 和 Date Parts
在此版本中,您现在可以对DateTime, int, long, decimal类型执行Between(),如下所示:
// using strings for dates
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Between("2001-1-1", "2010-1-1") && x.Status == 2);
// using normal dates
var d1 = DateTime.Parse("2001-1-1");
var d2 = DateTime.Parse("2010-1-1");
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Between(d1, d2));
// string based
var result = rdb.Query("salesinvoice", "date.between(\"2001-1-1\",\"2010-1-1\"");
var result = rdb.Query("salesinvoice", "serial.between(20,30)");
在WebStudio界面上也有同样的效果。
此外,您还可以像这样查询任何日期列部分:
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Year == 2016 && x.Date.Month == 8);
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Hour < 10);
附录 v3.3.12 - In()
在此版本中,您现在可以在列和日期部分上使用In(),如下所示:
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial.In(1,3,5,7));
// or with array parameters
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial.In(new int[] { 1,3,5,7 }));
// or with array variables
var arr = new int[] {1,3,5,7};
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Serial.In(arr));
// or on date parts
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Year.In(2000, 2010));
// or as string
var result = rdb.Query("salesinvoice", "serial.in(1,3,5,7)");
此外,Between()已扩展到支持日期部分。
var result = rdb.Query<SalesInvoiceViewRowSchema>(x => x.Date.Hour.Between(12, 15);
附录 v4.0.0 - MGRB
在此版本中,我用我重写的MGRB位图结构替换了WAHBitarray数据结构,该结构基于Daniel Lemire的 roaring bitmap(https://roaringbitmap.org/),以实现更好的内存使用。我的版本具有以下附加优点(我可能会写一篇文章介绍):
- 能够在构造函数外设置位。
- 稀疏容器,即仅编码使用的位块。
- 反转容器,用于存储在一块 1 中存储 0。
- 基于设置的位优化容器块的选择。
在示例应用程序中,从空白数据库存储 100,000 个文档的初始内存使用量从 450MB 减少到 350MB,并且空闲内存工作得更好,并更好地优化了内存结构。
保存和索引的速度大致相同。
附录 v4.0.9 - Web Studio with Svelte
我最近遇到了Svelte,它与我使用并喜欢的Vue相似。我必须说,我真的很喜欢Svelte,因为它具有与Vue相同的概念和功能,但更简单,并且能产生非常小的输出,没有“框架”库的开销。
与Vue相比,所需的node_modules和rollup打包器也小得多。
我决定用Svelte重写我以前手动编写的jQuery风格的 Web Studio 代码(我第一次编写 JavaScript),结果要小得多,缩小后输出比我以前的代码小约 30%,但可维护性却无穷无尽(实际代码量减少了约 50%)。
我真正喜欢并且曾经非常麻烦且导致许多错误的方面是,您不需要像Vue那样引用this。
为了实现选项卡界面,我需要Svelte的一些高级功能,这些功能是:
- 在代码中运行时创建组件并设置它们的
target和props。 - 在运行时组件上使用
$on和$destroy。 - 使用
<svelte:options accessors={true} />来访问组件内部。
为了调试代码的运行,我需要将服务器 URL 更改为实际的RaptorDB服务器地址,而不是端口 5000 上的开发服务器。为此,我添加了debug.js文件:
import './main.js'
window.ServerURL = "https://:91/";
main.js文件包含:
...
window.ServerURL = document.location.protocol + "//" +
document.location.hostname + ":" +
document.location.port + "/";
...
默认的构建命令将代码构建到public文件夹,这并不理想。为了解决这个问题,我还更改了rollup.config.js文件,以区分调试和生产构建,并使用dist文件夹。
...
const production = !process.env.ROLLUP_WATCH;
const dir = production ? "dist" : "public";
export default {
input: production ? 'src/main.js' : 'src/debug.js',
...
我无法实现的是使用 JavaScript 的fetch()命令,在调试时它会产生 CORS 错误,所以我使用了我以前的XMLHttpRequest()代码,并将它们添加到window对象中,以便在整个应用程序中使用。
总而言之,我享受了这个过程,而且Visual Studio Code仍然是一个令人愉快的工具。
先前版本
您可以在此处下载以前的版本:
- RaptorDB_doc_v1.0.zip
- 下载 RaptorDB_doc_v1.1.zip
- 下载 RaptorDB_doc_v1.2.zip
- 下载 RaptorDB_doc_v1.3.zip
- 下载 RaptorDB_doc_v1.4.zip
- 下载 RaptorDB_doc_v1.5.zip
- 下载 RaptorDB_doc_v1.6.zip
- 下载 RaptorDB_doc_v1.7.zip
- 下载 RaptorDB_doc_v1.8.1.zip
- 下载 RaptorDB_doc_v1.8.2.zip
- 下载 RaptorDB_doc_v1.8.3.zip
- 下载 RaptorDB_doc_v1.9.0.zip
- 下载 RaptorDB_doc_v1.9.1.zip
- 下载 RaptorDB_doc_v1.9.2.zip
- 下载 RaptorDB_doc_v2.0.0.zip
- 下载 RaptorDB_doc_v2.0.5.zip
- 下载 RaptorDB_doc_v2.0.6.zip
- 下载 RaptorDB_doc_v2.0.6.1.zip
- 下载 RaptorDB_doc_v3.0.0.zip
- 下载 RaptorDB_doc_v3.0.1.zip
- 下载 RaptorDB_doc_v3.0.5.zip
- 下载 RaptorDB_doc_v3.0.6.zip
- 下载 RaptorDB_doc_v3.1.0.zip
- 下载 RaptorDB_doc_v3.1.2.zip
- 下载 RaptorDB_doc_v3.1.3.zip
- 下载 RaptorDB_doc_v3.1.4.zip
- 下载 RaptorDB_doc_v3.1.5.zip
- 下载 RaptorDB_doc_v3.1.6.zip
- 下载 RaptorDB_doc_v3.2.0.zip
- 下载 RaptorDB_doc_v3.2.5.zip
- 下载 RaptorDB_doc_v3.2.6.zip
- 下载 RaptorDB_doc_v3.2.7.zip
- 下载 RaptorDB_doc_v3.2.8.zip
- 下载 RaptorDB_doc_v3.2.9.zip
- 下载 RaptorDB_doc_v3.2.10.zip
- 下载 RaptorDB_doc_v3.2.11.zip
- 下载 RaptorDB_doc_v3.2.12.zip
- 下载 RaptorDB_doc_v3.2.13.zip
- 下载 RaptorDB_doc_v3.2.14.zip
- 下载 RaptorDB_doc_v3.2.15.zip
- 下载 RaptorDB_doc_v3.2.16.zip
- 下载 RaptorDB_doc_v3.2.17.zip
- 下载 RaptorDB_doc_v3.2.18.zip
- 下载 RaptorDB_doc_v3.3.0.zip
- 下载 RaptorDB_doc_v3.3.1.zip
- 下载 RaptorDB_doc_v3.3.2.zip
- 下载 RaptorDB_doc_v3.3.3.zip
- 下载 RaptorDB_doc_v3.3.4.zip
- 下载 RaptorDB_doc_v3.3.5.zip
- 下载 RaptorDB_doc_v3.3.6.zip
- 下载 RaptorDB_doc_v3.3.8.zip
- 下载 RaptorDB_doc_v3.3.9.zip
- 下载 RaptorDB_doc_v3.3.10.zip
- 下载 RaptorDB_doc_v3.3.11.zip
- 下载 RaptorDB_v3.3.12.zip
- 下载 RaptorDB_v3.3.13.zip
- 下载 RaptorDB_doc_v3.3.14.zip
- 下载 RaptorDB_doc_v3.3.15.zip
- 下载 RaptorDB_doc_v3.3.16.zip
- 下载 RaptorDB_doc_v3.3.17.zip
- 下载 RaptorDB_doc_v3.3.19.zip
- 下载 RaptorDB_doc_v3.3.19.1.zip
- 下载 RaptorDB_doc_v4.0.0.zip
- 下载 RaptorDB_doc_v4.0.2.zip
- 下载 RaptorDB_doc_v4.0.5.zip
- 下载 RaptorDB_doc_v4.0.6.zip
- 下载 RaptorDB_doc_v4.0.7.zip
- 下载 RaptorDB_doc_v4.0.8.zip
历史
- 首次发布 v1.0:2012 年 4 月 29 日
- 更新 v1.1:2012 年 5 月 4 日
- 通过属性进行全文索引
- 字符串查询解析器
- 修复关闭时刷新索引到磁盘
- 基础控制台应用程序
- 字符串查询的小写视图名称
- 如果查询中不存在 + - 字符,则全文搜索默认为 AND。
- 现在提供视图类型时,查询有效。
- 保存时暂停索引器以提高插入性能(约快 30%)
- 更新 v1.2:2012 年 5 月 11 日
- 视图版本控制和重建
- 代码清理
- 从 fastJSON 中移除缩进逻辑
- 将模式添加到 Result 中
- 更新 v1.3:2012 年 5 月 17 日
Results.Rows现在是可绑定的行模式对象(即使是字段)View.Schema现在必须派生自RaptorDB.RDBSchema- 从
Result中移除了列(不再需要) RegisterView引发异常而不是返回 Result- 添加了一个基础的查询查看器项目
- 索引时忽略 null 值
- 布尔索引文件名将以“.idx”结尾
- 示例应用程序将在主解决方案文件夹中创建数据文件,方便共享
- 现在可以在客户端对结果进行聚合查询
- 添加了
api.EmitObject以便于映射(需要更少的代码) - 升级到 fastJSON v1.9.8
- 修复 fastBinaryJSON 中的 datetime bug
- 更新 v1.4:2012 年 5 月 31 日
- 将源代码分解为多个项目
- 创建了客户端、服务器 DLL
- 升级到 fastBinaryJSON v1.1
- 改为使用
SafeSortedList以实现线程安全的索引 - 添加了自动安装程序 RaptorDBServer 服务
- 性能优化 TCP 网络层
- 为 Windows 应用程序添加了双模式用法(嵌入式、服务器)
- 代码清理
- 添加了
IRaptorDB接口,允许您无缝切换嵌入式和客户端 - 在服务器模式下从 Extensions 文件夹加载视图
- 更新 v1.5:2012 年 6 月 10 日
- 在
Param.CompressDataOver限制之上使用 MiniLZO 压缩网络流量 - 添加了
Delete(docid)和DeleteBytes(fileid) - 添加了以字符串形式查询 Guid 和 DateTime 的能力
- 修复了读取布尔索引的 bug
- 重建视图和后台索引器处理已删除的文档
- 在服务器模式下通过 users.config 文件添加了身份验证
- 备份和恢复数据
- 为用户添加了
AddUser()方法 - 在恢复数据和重建视图时处理
isDeleted - 服务器模式下自动备份(00:00 时间)
- 在
- 更新 v1.6:2012 年 6 月 30 日
- 查询 lambda 缓存
- 事务支持
- datetime 序列化中的 bug
- 在文章中添加了 Rules 部分
- 在文章中添加了 Transaction 部分
- 更新 v1.7:2012 年 7 月 14 日
- 服务器端聚合查询
- 修复了用于将视图 DLL 复制到 extensions 文件夹的视图构建脚本
- 服务器端查询可以带有过滤器
- 登录表单默认按钮修复
- 更新 v1.8.1:2012 年 8 月 11 日
- 修复了 hoot 索引 loadwords 在文件大小为零时的 bug
- 修复了 linq 绑定 ServerSide -> c.val == stringvariable 的 bug
- 修复了 linq 绑定 -> c.val == stringvariable 的 bug
- 修复了 serializers 中的反射代码 bug
- 提高了 WAH 位图 Set() 代码的速度
- 修复了并发保存位图索引到磁盘的 bug
- 升级到 fastBinaryJSON v1.3
- 升级到 fastJSON v2.0.1
- 更新 v1.8.2:2012 年 8 月 16 日
- 修复了 linq 绑定 -> c.val == obj.property 的 bug(感谢Joe Dluzen)
- 为位图索引添加了锁以实现并发
- 优化了 JSON 和 BJSON 中的 $types 输出
- 修复了 SafeSortedList.Remove 的 null 检查 bug
- 修复了服务器模式数据传输 bug
- 更新 v1.8.3:2012 年 9 月 23 日
- 升级到 fastJSON v2.0.6
- 升级到 fastBinaryJSON v1.3.4
- 修复了带有 date、guid 参数的 linq2string bug
- 将 double、float 类型添加到索引器的有效数据类型中
- 为 IndexFile 添加了锁以处理并发问题(感谢Antonello Oliveri)
- 修复了 logger 中 _que 的锁以处理并发(感谢Antonello Oliveri)
- 修复了反射绑定到 insert 方法的 bug(感谢Antonello Oliveri)
- 在视图上添加了 Count()
- 添加了结果分页支持
- 在事务模式下,映射器现在可以在自己的线程中看到它所做的更改,同时进行查询。
- 添加了新的 Logo 部分
- 更新 v1.9.0:2012 年 11 月 26 日
- 提高了将位图索引写入磁盘的速度
- 修复了带通配符的 hoot 搜索 bug
- 修复了 UTC 时间的 datetime 索引 bug(所有时间均为本地时间)
- 升级到 fastJSON v2.0.9
- 升级到 fastBinaryJSON v1.3.5
- 为了 MonoDroid 的兼容性,将 CodeDOM 更改为 Reflection.Emit
- 更优化的位图存储格式(如果小于 WAH 则保存偏移量)
- 修复了 monodroid 和 windows 兼容性的路径分隔符字符,已更改为
Path.DirectorySeparatorChar - 新的泛型 Query 接口,带有类型化结果(感谢seer_tenedos2)
- 更改为 Result<T>
- WAH 位计数速度提升
- 位图索引使用缓冲流以提高速度
- 添加了 between 查询(正在进行中)
- 存储文件和已删除项的 bug 修复
- 映射器 API 接口的新查询模型
- 现在您可以定义自己的行模式,但有一些注意事项。
- 修复了位图索引上的 NOT 查询,使其首先调整大小以适应总行数。
- 在定义自己的模式时,您可以在视图中定义全文列,而无需属性。
- 更新 v1.9.1:2012 年 12 月 30 日
- WAHBitarray 边缘情况 bug 修复
- 同步代码以适应 hOOt 中的更改
- 修复了服务器模式
SaveBytes()缺失的 bug - 修复了服务器模式下的服务器端查询 bug
- 修复了嵌入式 guid 在查询中的 bug:v => v.docid == new Guid("...")
- 更新 v1.9.2:2013 年 4 月 6 日
- SafeDictionary.Add() 如果项已存在则会更新
- BitmapIndex 使用新的锁定机制
- CaseInsensitive 属性
- 修复了小写 hoot 索引 bug
- 不区分大小写的字符串索引和搜索
- nocase 示例
- 修复了 LINQ 查询中 !=(不等于)的处理 bug
- 更新 v2.0.0:2013 年 4 月 28 日
- 添加了更多方法文档
- * doc 存储文件中的破坏性更改,从哈希 guid 更改为 guid 键 *
- 为文档和文件添加了
FetchHistory()和FetchVersion()以获取修订版本 - 升级到 fastJSON v2.0.14
- 升级到 fastBinaryJSON v1.3.7
- 对整个原始文档进行全文索引和搜索
- 修复了带有布尔参数的 LINQ 查询 bug
- 更新 v2.0.5:2013 年 5 月 18 日
- 向类添加了 FreeMemory
- 添加了内存限制和空闲内存计时器
- 视图后台按时将索引保存到磁盘
- 修复了 RaptorDBServer.csproj 以进行 AnyCPU 构建
- 更新 v2.0.6:2013 年 6 月 15 日
- WAHBitArray bug 修复
- 升级到 fastJSON v2.0.15
- 修复了 hoot 全文索引最后一个单词的 bug
- 保存已删除项的位图在保存计时器上
- 更新 v2.0.6.1:2013 年 6 月 22 日
- WAHBitArray bug 修复
- 更新 v3.0.0:2013 年 8 月 23 日
- 索引文件以共享模式打开,以便在线复制
- 添加了 cron 守护程序(感谢Kevin Coylar)
- 备份现在按 cron 计划进行
- 重构存储文件以实现未来兼容和复制支持
- 存储文件现在存储有关存储对象的元数据
- * 存储文件不向后兼容 *
- 脏索引页在保存时排序以提高读取性能
- 恢复现在在关机后可以继续
- 您可以通过
Global.RequirePrimaryView禁用在保存时定义主视图(K/V 模式) - 视图重建现在在后台进行(重启时非阻塞)
- 您可以在“datafolder\views”中以 C# 脚本格式(*.view)定义视图,以便在运行时进行编译。
- 如果在脚本视图中定义了行模式,则在客户端不存在时,脚本 DLL 文件将被传输到客户端。
- fastJSON 现在序列化静态属性
- 升级到 fastJSON v2.0.18
- 升级到 fastBinaryJSON v1.3.8
- 添加了 HQ-Branch 复制功能
- 如果配置文件不存在,将自动生成带有“-”前缀的配置文件。
- 解决方案文件夹根目录中的“output”是项目的新的构建目标,方便访问。
- 更新 v3.0.1:2013 年 10 月 6 日
- 升级到 fastJSON v2.0.22
- 升级到 fastBinaryJSON v1.3.10
- 检测进程退出并干净关闭,因此您可以省略显式的
Shutdown()。 - WAH 位图数组 bug 修复
- 更新 v3.0.5:2013 年 10 月 11 日
- 修复了将页列表保存到磁盘的 bug,用于计数 > 5000 万项
- 更新 v3.0.6:2013 年 11 月 2 日
Result.TotalCount反映原始行数,并且在分页时与Result.Count不同。- 内部将
FireOnType更改为处理 Type 而不是字符串 Query()现在可以正确处理空过滤器字符串。- 升级到 fastJSON v2.0.24
- 升级到 fastBinaryJSON v1.3.11
- 更新 v3.1.0:2013 年 12 月 5 日
- 为查询添加了排序
- 删除了额外的查询重载,以支持新模型
- 更新 v3.1.2:2014 年 5 月 17 日
- 添加了签名程序集,程序集版本将保持为 3.0.0.0,文件版本将递增。
- 添加了 nuget 构建
- 升级到 fastJSON v2.1.1
- 升级到 fastBinaryJSON v1.4.1
- 来自Richard Hauer的 WAH 和 Query2 的 bug 修复
- 更改了所有单例实现
- 修复了 String.Empty 索引 bug
- *破坏性更改*:从视图定义中移除了 FireOnType
- 视图现在可以正确处理 T 的子类(例如 SpecialInvoice : Invoice)
- 修复了 index bitmap.Not(size) 的 bug
- 更新 v3.1.3:2014 年 5 月 27 日
- 添加了
FetchHistoryInfo()和FetchBytesHistoryInfo(),并包含日期更改信息。 - 添加了
api.NextRowNumber()。 - 将所有配置文件移至数据文件夹,您应该对该文件夹具有写访问权限(感谢Detlef Kroll)。
- 修复了在没有行的情况下删除前插入的 bug。
- 添加了
- 更新 v3.1.4:2014 年 6 月 21 日
- 添加了
StringIndexLength属性,用于视图模式,以控制索引文件中字符串索引的大小。 - 添加了
ViewDelete()以直接从视图中删除。 - 添加了
ViewInsert()以直接插入到视图中。 - 添加了 Faker.dll(http://faker.codeplex.com)以生成更漂亮的数据。
FreeMemory()还将索引保存到磁盘。- 将服务器模式文件移至 output\server,以免加载 views.dll 时产生冲突。
- 分页列表也在
SaveIndex()时保存到磁盘。 - 修复了视图模式在未继承自
RDBSchema时的 bug。 - 将 T 替换为代码智能感知中更有意义的
TRowSchema。
- 添加了
- 更新 v3.1.5:2015 年 1 月 3 日
- 添加了
View.NoIndexingColumns定义,以覆盖选定列的索引。 - 升级到 fastJSON v2.1.7
- 升级到 fastBinaryJSON v1.4.5
- 添加了
DocumentCount()以获取存储文件中的项目数量。 Shutdown()现在等待视图重建完成。- 更多智能感知帮助。
- 添加了
- 更新 v3.1.6:2015 年 1 月 9 日
- 文档存储文件现在可以通过
Global.SplitStorageFilesMegaBytes配置进行分割。 - 重构 StorageFile.cs
- 升级到 fastJSON v2.1.8
- 升级到 fastBinaryJSON v1.4.6
- 修复了.config 文件未正确保存的 bug。
- 文档存储文件现在可以通过
- 更新 v3.2.0 : 2015年1月25日
- 您可以使用
Global.CompressDocumentOverKiloBytes配置来压缩存储文件中的文档 - 升级到 fastJSON v2.1.9
- 为视图添加了完整性检查,如果未正常关闭,则自动重建
- bug 修复:在
Shutdown()之前禁用计时器 - 添加了高频更新键/值存储文件
- 您可以使用
- 更新 v3.2.5 : 2015年2月6日
- 为存储字符串
MGIndex文件进行了新的优化 - 添加了
Global.EnableOptimizedStringIndex标志来控制新索引的使用
- 为存储字符串
- 更新 v3.2.6 : 2015年2月27日
- 由 Stainslav Lukeš 完成的优化
- 升级到 fastJSON v2.1.10
- 升级到 fastBinaryJSON v1.4.7
- bug 修复:位图索引
- bug 修复:删除的位图索引的文件名冲突
- 为视图和 RaptorDB 引擎添加了版本检查,并在引擎升级时自动重建
- 将已删除的位图索引更改为
.deleted扩展名 - 将版本号文件更改为文本模式,使用
.version扩展名
- 更新 v3.2.7 : 2015年2月27日
- bug 修复:在
Shutdown()过程中视图重建时等待,该过程在2秒内被切断(ProcessExit)
- bug 修复:在
- 更新 v3.2.8 : 2015年3月3日
- bug 修复:在与已删除的位图索引相关的查询中出现重复项
- 更新 v3.2.9 : 2015年3月8日
- 升级到 fastJSON v2.1.11
- 升级到 fastBinaryJSON v1.4.8
- 添加了对 vb.net 字符串 linq 查询的支持
- 添加了 vb 测试项目
- 更新 v3.2.10 : 2015年4月24日
- 将
Form1重命名为frmMain - 添加了可排序的全文索引
- 修复了 Linux 系统的路径名
- 将默认保存和释放内存计时器从 60 秒更改为 30 分钟
- 优化了查询排序,使用内部缓存,速度提升约 100 倍
- 将
- 更新 v3.2.11 : 2015年4月25日
- bug 修复:排序缓存
- 更新 v3.2.12 : 2015年5月17日
- 代码清理
- bug 修复:全文搜索时的 + - 前缀
- 升级到 fastJSON v2.1.13
- 升级到 fastBinaryJSON v1.4.10
- 更新 v3.2.13 : 2015年5月31日
- 代码重构
- bug 修复:全文索引搜索时开头的 not "-oak hill"
- 修复了日志中的时间输出
- 升级到 fastJSON v2.1.14
- 升级到 fastBinaryJSON v1.4.11
- 更新 v3.2.14 : 2015年8月6日
- 服务器跟踪连接的客户端数量,每 30 秒自动清除一次
- 为 HFKV 的
int,decimal值添加了原子Increment()Decrement()操作 - bug 修复:全文索引中的通配符搜索
- 添加了全文搜索的 not 通配符 -> "-oak -*l"
- 全文索引在空格和
char.IsPunctuation()处断开文本 api.NextRowNumber()会阻塞直到重建完成- 视图映射函数可以通过
api接口访问高频 KV
- 更新 v3.2.15 : 2015年9月13日
- *重大更改* : 全文搜索中的 + 现在表示 OR
- 全文搜索 bug 修复:边缘情况
- 更新 v3.2.16 : 2016年1月26日
- 为视图添加了对
ushort的支持(感谢 dragosc) - bug 修复:服务器模式下的
FetchHistory()返回值(感谢 DrDeadCrash) - bug 修复:边缘情况位图索引提交(感谢 dragosc)
- bug 修复:hOOt 全文索引关闭
- bug 修复:
FullTextSerach()在索引前过滤掉 JSON 字符
- 为视图添加了对
- 更新 v3.2.17 : 2016年2月19日
- bug 修复:客户端/服务器模式下的
GenericResult()中的空行 - bug 修复:如果模式中定义了属性/字段但在实体中未定义,则在获取行时出现 null 错误
- bug 修复:客户端/服务器模式下的
- 更新 v3.2.18 : 2016年3月15日
- 清理 usings
- 索引中的
FreeMemory(),先保存数据 - 为 hOOt 索引添加了索引词列表
- hOOt 优化索引会先保存数据
- hOOt 优化索引会阻塞直到完成
- hOOt
FindDocuments()现在是通用的 - 添加了带
object[]参数的服务器端函数 - 添加了自动构建号递增器
- bug 修复:不等于
!=在查询中转换为字符串 - 升级到 fastJSON v2.1.15
- 升级到 fastBJSON v1.4.12
- 更新 v3.3.0 : 2016年4月7日
- 添加了 WEB Studio 界面
- 日志保留最近 100 条日志以供回忆
- bug 修复:HF 存储文件寻道位置溢出(感谢 ozzel)
- 更新 v3.3.1 : 2016年4月14日
- bug 修复:视图模式定义中混合了属性和字段(查询时发生无效转换异常)
- 更新 v3.3.2 : 2016年4月25日
- bug 修复:查询中边缘情况重复项显示
- 更新 v3.3.3 : 2016年5月6日
- bug 修复:
SafeSortedList.Add() - bug 修复:
WAHBitArray.FreeMemory()
- bug 修复:
- 更新 v3.3.4 : 2016年5月20日
- 简化了关闭过程(无额外的索引保存)
- Web UI 内容高度设置为浏览器高度
BimapIndex中的内存使用量减少(移除记录缓存)WAHBitArray中的内存使用量减少(偏移量 Dictionary -> SortedList)MGIndex中的内存使用量减少(缓存 Dictionary -> SortedList)Hoot中的内存使用量减少(词典 Dictionary -> SortedList)- 如果 Web 服务器在未以管理员身份运行时启动,则记录错误
- frmMain 窗体关闭正确处理了关闭
- 将默认
Globals.FreeMemoryTimerSeconds从 30 分钟更改为 5 分钟
- 更新 v3.3.5 : 2016年5月31日
- bug 修复:查询中的
!=在找不到 RH 表达式时返回所有行(感谢 Lutz Wellhausen) - linq
(x => true)谓词返回所有行 - linq
(x => false)谓词返回 no rows
- bug 修复:查询中的
- 更新 v3.3.6 : 2016年7月25日
- 升级到 fastJSON v2.1.18
- 升级到 fastBinaryJSON v1.4.15
- 将默认
view.ConsistentSaveToThisView = true - 将默认
view.isPrimaryList = true - 重构了 Web 服务器
- 重构了
nav.js
- 更新 v3.3.8 : 2016年8月12日
- 与
hOOt同步 - 添加了
nscript.exe工具 - 添加了带命令行运行的
sample.cs测试脚本 - 更改了日志消息类型
- bug 修复:全文搜索
- 全文
tokenizer会断开 a.b.c 单词和数字
- 与
- 更新 v3.3.9 : 2016年8月14日
- 查询日期部分,例如
x => x.Date.Year == 2016或"date.year = 2016" - 日期
Between(),例如x => x.Date.Between("2000-1-1","2002-6-16") - 优化了内部查询引擎的范围查询
- 内部查询实现 from to
Between()用于int, long, decimal
- 查询日期部分,例如
- 更新 v3.3.10 : 2016年8月21日
- 代码清理
- 泛型
Between<T>() - bug 修复:
BitmapIndex.FreeMemory() - bug 修复:
MGIndex.FreeMemory() - 添加了泛型
Fetch<T>()(感谢 Norbert Haberl) - 添加了来自 [https://github.com/jaime-olivares/zipstorer] 的
ZipStorer(感谢 Jaime Olivares) - 添加了自动压缩旧日志文件
- 更新 v3.3.11 : 2016年8月25日
- 添加了查询位图缓存以提高查询速度
- 更新 v3.3.12 : 2016年8月28日
- 添加了
In<T>(),例如x => x.Serial.In(1,3,5,7)或"serial.in(1,3,5,7)" Count()和所有其他重载的查询缓存- 在 ViewHandler.cs 中重构/清理代码
- 日期部分与 In() 一起使用,例如
x => x.Date.Year.In(2000,2001) - 日期部分与 Between() 一起使用,例如
x => x.Date.Year.Between(2000,2010)
- 添加了
- 更新 v3.3.13 : 2016年9月3日
- bug 修复:
x=>true谓词情况 - 升级到 fastJSON v2.1.19
- 升级到 fastBinaryJSON v1.4.16
- bug 修复:字符串键索引与
Global.EnableOptimizedStringIndex = true - ** 增加了 RaptorDBVersion ** 如果存在旧索引数据,则会重建
- bug 修复:
WAHBitArray.Fill()
- bug 修复:
- 更新 v3.3.14 : 2016年11月12日
- 升级到 fastJSON v2.1.21
- 升级到 fastBinaryJSON v1.4.18
- bug 修复:文档全文搜索结果 < 分页计数
- 更新 v3.3.15 : 2017年6月6日
- 升级到 fastBinaryJSON v1.4.19
- bug 修复:日志 zip 文件名
- bug 修复:
FastDateTime中的本地/UTC 时间 - 更改为 public
WAHBitArray - 更改为 public Hoot
- 更改为 public CronDaemon
- Zipstorer 默认使用 UTF8 文件名
- bug 修复:
ViewInsert()和重建索引 *旧数据无法恢复,请重建您的数据库* - 移除查询位图缓存,因为结果不正确
- 升级到 fastJSON v2.1.25
- bug 修复:HFKV 存储在失败关闭时重建
- 更新 v3.3.16 : 2017年6月7日
- bug 修复:HFKV 重建
- 更新 v3.3.17 : 2017年6月9日
- 在
RaptorDB.Open()中添加了ITokenizer全文搜索重载 - 重写了 tokenizer
- bug 修复:HFKV 重建
- 在
- 更新 v3.3.19 : 2018年1月25日
- 升级到 fastJSON v2.1.28
- 升级到 fastBinaryJSON v1.4.21
- 支持 .netcore 2.0 和 netstandard 2.0
- 更新 v3.3.19.1 : 2018年1月26日
- bug 修复:在 .net core 的 Ubuntu 上关闭
- 更新 v4.0.0 : 2018年10月5日
- 升级到 fastJSON v2.2.0
- 升级到 fastBinaryJSON v1.5.1
- 更改为更快的 Unicode <-> 字节转换
- 优化了视图数据字节大小,移除了 bjson 类型数组
- 新的稀疏位图索引,内存占用更少(
MGRB基于 roaring bitmap) - * 如果您正在使用高频键存储,可能存在重大更改 *
- bug 修复:列中的全文搜索,支持不区分大小写的单词
- 并行关闭索引以提高性能
- 修复了
.strings文件不断增大的问题
- 更新 v4.0.2 : 2018年10月8日
- bug 修复:数据文件夹中缺少 raptordb.version 文件
- bug 修复:
MGRB.Fill()
- 更新 v4.0.5 : 2018年10月11日
- bug 修复:
MGRB.Fill(length)遵守 length 值 - bug 修复:
MGRB.CountOnes()在 length = 0 时 MGRB添加了锁以保证完整性MGRB添加了InvertedContainer以提高内存使用效率MGRB在计算中遵守长度- 截断
StorageFileHF末尾的空闲列表数据在读取时
- bug 修复:
- 更新 v4.0.6 : 2018年12月17日
- 升级到 fastBinaryJSON v1.5.2
- bug 修复:加载空的 hOOt 词汇文件
- bug 修复:查询少于 64 行的 MGRB 索引
- 更新 v4.0.7 : 2019年2月25日
- bug 修复:
StorageFileHF从之前的失败关闭中重新加载空闲列表
- bug 修复:
- 更新 v4.0.8 : 2019年6月23日
- bug 修复:.string 索引文件随时间增长
- 升级到
fastJSONv2.2.5 - 升级到
fastBinaryJSONv1.5.3
- 更新 v4.0.9 : 2019年7月24日
- 使用
Svelte重写了 Web Studio
- 使用