
在没有 Microsoft Word 的情况下填充 .docx 文档中的合并域
4.92/5 (41投票s)
用于在 Microsoft Word (docx) 模板文档中填充合并域(单个域和表格数据)的实用工具类,无需 Microsoft Word 本身
引言
此应用程序使用 Open XML SDK 来查找 Microsoft Word 文档中的 MERGEFIELD 并将其替换为提供的数据。此外,它还支持添加带数据的表格。这是一种在服务器端生成 Microsoft Word 文档的非常快速和稳定的方法。
主要代码仅包含1个类和几个完成所有工作的方法。我提供了一个前端来测试该类的功能。
为了能够运行该应用程序,您必须下载并安装前面提到的 SDK。由于该 SDK 是用 .NET 3.5 编写的,整个库只能在 .NET 3.5 及更高版本中工作。
背景
在一个客户项目中,我需要能够将 XML 文件中的数据注入到标准化的文档格式中。该客户仍在使用 Microsoft Office 2000,但在他所有的电脑上都安装了兼容包。
我不想通过 OLE 自动化来使用 Microsoft Word,因为它是一个在无人值守情况下运行的服务器端进程。由于微软不推荐在这种场景下使用 Microsoft Office,所以这不是一个可选项。但我记得新的 docx 格式只是一个包含可编辑的零散 XML 文件的压缩包。在网上搜索了一番后,我找到了 Open XML SDK,它在解析 Microsoft Word 文档结构方面提供了很大帮助。最终,我编写了一段代码,用 XML 文件中的数据填充 Microsoft Word docx 文件。这生成了所需的数据文档。
使用这种机制还给我带来了额外的好处,即客户可以自己编辑模板的布局。虽然这不是一个必要条件,但它在之后为我节省了很多时间。
使用前端
随源代码一起提供了一个前端应用程序,让您可以测试其功能。
这个应用程序是使用 WPF 编写的,并使用了 WPF 工具包中的 datagrid。为了能够运行这个测试应用程序,您需要从 CodePlex 下载并安装 WPF 工具包。
当然,在测试任何东西之前,您需要一个 docx 模板。我在 zip 文件中添加了一个示例模板,但您也可以提供自己的模板(有关模板的详细信息,请参见下一章)。
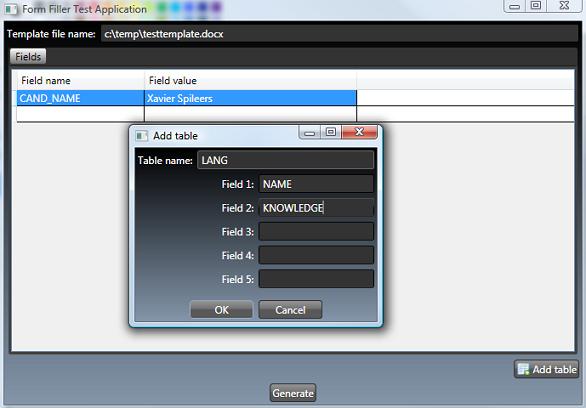
在主窗口中,您必须首先在上面的文本框中提供模板的完整路径(只要此字段为空,“生成”按钮将处于禁用状态)。
在窗口中央的网格中添加您的字段和数据。要添加表格数据,请单击“添加表格”按钮,并定义表名和列名(最多5个)。单击“确定”并为表格提供数据。对每个表格重复此操作。
最后,单击“生成”。您的报告应该会自动出现。
docx 模板
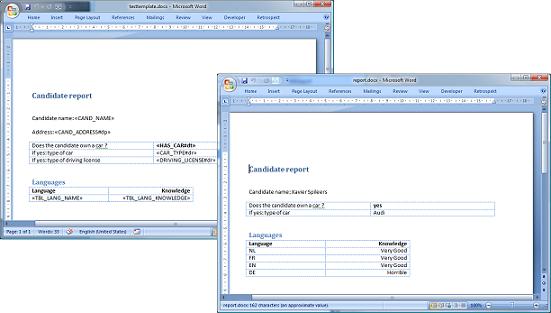
首先,您需要一个包含多个 MERGEFIELD 的 Microsoft Word docx 文档,这些合并域作为您数据的占位符。mergefield 包含了您要添加的数据的名称(代码),例如
{MERGEFIELD CAND_NAME \* MERGEFORMAT}
此外还有3个可以使用的后缀
dp: 如果数据字段为空或未提供,则删除该段落dr: (仅在表格中)如果数据字段为空或未提供,则删除该行dt: (仅在表格中)如果数据字段为空或未提供,则删除整个表格
后缀被添加到字段名称后,并以“#”开头。例如
{MERGEFIELD CAND_NAME#dp \* MERGEFORMAT}
如果您想向 Word 文档中添加表格数据,您必须在 docx 文档中添加一个表格。表格的单元格包含合并域,用于指示必须放置在此处的数据字段。这些 Mergefield 的格式为:TBL_表格名_字段名。例如
{MERGEFIELD TBL_LANG_NAME \* MERGEFORMAT}
上面的 mergefield 告诉应用程序,此单元格包含 Lang 数据表中选定记录的 Name 列的值。应用程序将为数据表中找到的每条记录向表格中添加一行。(后缀不支持表格数据。每个表格单元格只能包含1个合并域。)
注意:应用程序会填充放置在文档页眉/页脚中的单个 mergefield,但不支持页眉/页脚中的表格数据。
Using the Code
在 FormFiller 类上只有一个(public)方法可以调用:GetWordReport。
此方法接受3个参数
filename: 模板 docx 文件的完整路径dataset: 一个包含必须添加到模板中的表格数据的DataSet。dataset中的每个datatable都必须根据模板中使用的名称进行命名(见上文)。如果模板包含一个字段TBL_LANG_NAME,那么datatable必须被命名为“LANG”并且必须包含一个名为“NAME”的列。如果没有表格数据,此参数可以为null。values: 这是一个string类型的Dictionary,其中键是字段名,值是必须放置在 Microsoft Word 文档中的数据。
如果一切顺利,填充好的模板将以字节数组的形式返回。
代码中的一些亮点
打开模板
使用 SDK 打开 docx 文件非常容易。只需要以下代码
using (MemoryStream stream = new MemoryStream(filebytes))
{
// Create a Wordprocessing document object.
using (WordprocessingDocument docx = WordprocessingDocument.Open(stream, true))
{
...
}
}
(filebytes 变量是读入的 docx 模板。)
为数据提供一个 Run 对象
在 OpenXML 文档中,您不能只添加包含普通硬回车或制表符的文本。这些必须被替换为正确的 XML 标签,才能在 Microsoft Word 中正确显示。

OpenXML 中的 mergefield 表示为 SIMPLEFIELD (<fldsimple>) 元素,并且可以包含子 RUN (<r>) 元素。字段的文本表示为 RUN 元素内的子 TEXT (<t>) 元素。一个 RUN 元素还可以有一个 RUNPROPERTIES (<rpr>) 元素,其中包含有关显示文本的附加布局信息,我们不希望丢失这些信息,因为我们希望我们的数据保持与模板中合并域相同的布局。
所以,如果我们想用我们的文本替换一个合并域,我们必须确保
- 我们数据中的制表符和回车符能正确呈现,并且
- 保留合并域的格式
FormFiller.GetRunElementForText 中的代码正是做了这件事
internal static Run GetRunElementForText(string text, SimpleField placeHolder)
{
string rpr = null;
if (placeHolder != null)
{
foreach (RunProperties placeholderrpr in placeHolder.Descendants<RunProperties>())
{
rpr = placeholderrpr.OuterXml;
break; // break at first
}
}
Run r = new Run();
if (!string.IsNullOrEmpty(rpr))
r.Append(new RunProperties(rpr));
if (string.IsNullOrEmpty(text)) return r;
// first process line breaks
string[] split = text.Split(new string[] { "\n" }, StringSplitOptions.None);
bool first = true;
foreach (string s in split)
{
if (!first) r.Append(new Break());
first = false;
// then process tabs
bool firsttab = true;
string[] tabsplit = s.Split(new string[] { "\t" }, StringSplitOptions.None);
foreach (string tabtext in tabsplit)
{
if (!firsttab) r.Append(new TabChar());
r.Append(new Text(tabtext));
firsttab = false;
}
}
return r;
}
此方法检查给定的合并域中是否存在 RUNPROPERTIES 元素。如果存在,则保留其内容 (.OuterXml) 并将其添加到新实例化的 RUN 元素中。然后检查数据中是否有制表符/回车符,并向数据中添加正确的元素(BREAK 和 TABCHAR 元素)。
保存模板
一旦所有字段都已填充完毕,必须将更改显式保存回文档中(它不会自动发生)。
docx.MainDocumentPart.Document.Save(); // save main document back in package
处理页眉和页脚
页眉和页脚不与主文档放在同一个 XML 文件中(它们是包中不同的“文档部分”)。上面讨论的代码将找不到放置在页眉或页脚中的 MERGEFIELD。为此,需要对页眉和页脚部分进行循环。下面是一个遍历文档页眉的循环示例
foreach (HeaderPart hpart in docx.MainDocumentPart.HeaderParts)
{
... // process fields
hpart.Header.Save(); // save header back in package
}
关注点
后缀(见上文)允许删除段落、行和表格。如果在遍历元素时执行此操作,循环会突然停止(而不会抛出任何错误)。例如:如果文档中有10个合并域,您正在使用以下语句遍历它们
foreach (var field in docx.MainDocumentPart.Document.Descendants<SimpleField>())
{
...
}
假设您决定删除元素5。例如,以下代码搜索 mergefield 的父 PARAGRAPH (<p>) 元素,并删除它(同时也删除了字段本身)
Paragraph p = GetFirstParent<Paragraph>(field);
if (p != null)
p.Remove();
您将永远无法到达元素6到10。循环将在没有任何迹象表明您错过了4个元素的情况下退出。
为了解决这个问题,您会注意到代码中有两个循环:第一个循环用数据填充 mergefield。这个循环会维护一个空 mergefield 的列表,第二个循环将删除所有这些空的 mergefield。
由 M. Chale 提供的更新
该库现在支持 UPPER、LOWER、FirstCap 和 Caps 标签。UPPER 和 LOWER 将整个 string 分别转换为大写或小写,FirstCap 将首字母大写,而其他所有字母都变为小写;Caps 则将单词标题化,即每个单词的首字母大写。请注意,Caps 例程有点简单,只将紧跟在空格后的字母大写。该库还支持应出现在数据之前或之后的文本。如果字段不为空且未标记为 #dp,它们将以与 MergeField 其余部分相同的格式插入。
带格式的示例字段:MERGEFIELD MYFIELD \ UPPER \b before \f after
感谢 Michael Chale 的这次更新。
针对 Microsoft Word 2010 的更新
自 Microsoft Word 2010 起,不再使用 SimpleField 元素。它已被多个 Run 元素所取代,其中一个(或多个)包含带有字段指令的 FieldCode 元素。该库的代码已被修改,以将这些新格式替换为旧式的 SimpleField,从而保持与 Microsoft Word 2007 文档的向后兼容性。
历史
- 2009-07-29: 提交到 CodeProject
- 2009-08-12: 现在页眉和页脚中的
Mergefield也会被处理 - 2009-08-14: 源代码小更新:表格中的
mergefield格式现在也会被复制(粗体、斜体等) - 2009-09-15: 更新源代码:
MemoryStream不可扩展以及表格行属性未被复制。修复了这两个问题。 - 2010-06-14: Michael Chale 添加了对字段格式化的支持。我已将解决方案更新至 VS2010。
- 2010-08-02: 更新库以支持 Microsoft Word 2010 生成的文档
- 2011-05-30: 向库中添加了几个错误修复