
精简高效的文件 DIFF(FIFF)应用程序
4.89/5 (13投票s)
本文介绍了一个应用程序,该应用程序可以计算并显示两个文本文件之间的差异。
目录
引言
本文介绍了一个应用程序,该应用程序可以计算并显示两个文本文件之间的差异。它旨在满足 Code Lean and Mean[^] 编程竞赛的要求。此条目属于 .NET (C#) 类别。当 FIFFConsole 使用挑战中包含的 测试文件运行时,它在 109 毫秒(或更少)内完成,并在具有 2GB RAM 的 AMD 1.6 GHZ 笔记本电脑上占用约 952 KB 的内存。我声称它实现的算法在大多数实际应用中以线性时间和空间运行,即 O(m),其中 m 是两个文件之间差异的数量。
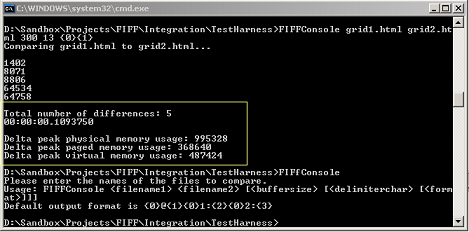
示例调用:FIFFConsole grid1.html grid2.html 250 13
在最初发布后,有人要求扩展该功能,以允许按非顺序方式比较文件。例如,如果第一个文件包含两行,而第二个文件包含相同的两行但顺序相反,则两个文件之间不应报告任何差异。换句话说,如果一个文件中的某个标记存在于另一个文件的正文中,那么该标记将从报告的任何差异中排除。此功能已添加到应用程序的0.2 版本中,作为范围更改,原始性能指标保持不变或略有提高。
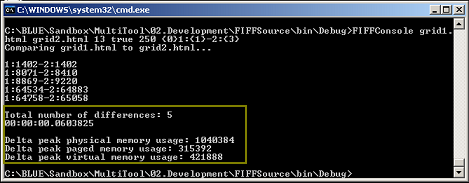
示例调用:FIFFConsole grid1.html grid2.html 13 true 250
本文的组织结构遵循了导致提出解决方案的迷你软件开发生命周期 (SDLC)。
分析
任何成功的软件项目都需要一组清晰理解的需求。IBM 在 Scott McEwen 编写的《需求:入门》[^] 中提供了极佳的资源。
在我们的案例中,问题领域由以下需求定义:
- 计算并显示两个文本文件之间的差异
- 0.2 版本:提供按非顺序比较文件的选项
- 提供小占用空间和高性能
- 报告执行时间
- 报告内存使用情况
- 为各种开发人员提供价值
这些需求引导我们得出以下功能:
- 提供文件名输入机制
- 支持各种文本文件格式
- 设计一种算法,该算法需要的读取文件和内存存储最少
- 0.2 版本:支持部分和全部文件读取
- 为性能调优留出空间
- 为未来优化留出空间
- 测量执行时间
- 测量内存使用情况
- 允许基本输出重新格式化
以下非功能未被优先考虑,并且可能已被完全省略:
- 安全和访问层
- 字符编码问题
- 线程安全
- 异步调用
- 异常处理
- 图形用户界面
这些功能和非功能转化为以下要求:
- 使用 .NET C# 控制台应用程序,需要两个参数来指定文件名
- 使用最多 3 个附加参数来指定缓冲区大小、标记分隔符和输出格式
- 0.2 版本:使用附加参数指定比较是否为顺序的
- 0.2 版本:使用内部标志指定比较是否区分大小写
- 仅存储哈希码和文件位置以节省空间
- 仅存储不同的哈希码,并在差异解决后立即清除它们
- 最多扫描文件两次
- 扫描的提前量不超过必要和充分的程度
- 0.2 版本:提供选项以优化顺序比较的扫描
- 使用 .NET 框架提供的有效哈希码生成函数 [^]
- 使用接口以允许对文件读取和临时存储对象进行不同的实现
- 使用
System.IO.FileStream[^] 作为文件读取接口实现,因为它已充分优化 - 使用
System.Collections.Generic.List(T)[^] 作为临时存储接口实现,因为它已充分优化 - 使用泛型类 [^] 作为算法类,为其提供接口实现信息
- 使用
System.DateTime.Now.Ticks[^] 记录执行时间- 0.2 版本:使用
System.Diagnostics.Stopwatch[^] 精确测量经过的时间
- 0.2 版本:使用
- 使用
System.Diagnostics.Process[^] 记录内存使用情况 - 使用
System.Text.UTF8Encoding[^] 支持 Unicode 和 ASCII 文本,UTF-8[^]
算法
解决方案的核心是用于计算文本文件差异的算法。它从每个文件读取数据块,直到检测到差异。然后它逐个标记地重新读取相同的块。标记的定义是灵活的;在某些配置中,它可能是一个单词,在其他配置中,它可能是一行,等等。一旦达到第一个标记差异,标记的哈希码就会存储在临时存储中。临时存储可以是数组,也可以是哈希表、B 树等。文件的读取继续以这种方式进行,直到一个文件中的标记在另一个文件的临时存储中找到哈希。此时,差异就确定了,临时存储被清除,我们继续读取数据块。该算法是对称的。
- 0.2 版本:虽然这一原则得以保留,但算法已扩展为允许在不顺序或未优化比较的情况下,在处理之前完全读取文件并存储其标记。
或者,最长公共子序列问题 (LCS)[^] 为文件比较提供了一种经过验证的方法。然而,在我看来,由于我们处理的是具有细微差异的大文件(以行为单位),因此可以使用它的一个变体。
- 0.2 版本:LCS 方法完全不能应用于非顺序比较。
以下是伪代码:
open file A, B
if (hash A != hash B)
{
while not (EOF A or B)
{
if (read buffer A != read buffer B)
{
read and store token A, B (if optimized, read one token only)
while (store A or B is not empty)
{
matched = (token A or B exists in store B or A respectfully)
if (ordered and matched and (index token A in store B +
index token B in store A > 0)) or (not ordered and not matched)
{
report and clear store A, B to index token B, A in store A, B
}
if (ordered and matched and (index token A in store B =
index token B in store A)) or (not ordered and matched)
{
clear store A, B at index token B, A in store A, B
}
if (ordered and optimized)
{
if not matched
{
read and store token A, B (if optimized, read one token only)
}
else
{
clear store A, B
}
}
if (store A or B is empty)
{
report and clear store A, B
}
get next token A, B at index = (matched || not ordered) ? 0 : Min(
index token A, B in store B, A) + 1
}
}
}
}
close file A, B
由于对大 O 表示法[^] 和复杂的计算机科学理论了解有限,我无法提供算法时间和空间使用的上限。但是,以下是我的想法。空间消耗在于临时存储哈希码,时间消耗在于搜索它。令 n 为两个文件之间最长的单个差异(以标记数量衡量),令 m 为总差异数。那么算法在 O(n) 的线性空间内运行,并在 O(m*(1 + 2 + ... + n)) = O(m*n^2) 的多项式时间内完成。
最坏情况是两个文件完全不同。然后,如果按行分词,n = Min(k, l),其中 k 是第一个文件的行数,l 是第二个文件的行数,m = 1。因此,算法在 O(n^2) 时间内完成。例如,如果我们使用排序列表而不是数组,我们可以在 O(log n) 时间内对其进行二分查找,但需要 O(n) 的插入列表时间。由于插入和搜索的频率相同,因此这种方法没有优势。
最佳情况是两个文件相同,n = 0, m = 0。然后算法在 O(1) 的常数时间和空间内完成。
对于竞赛而言,由于我们比较的是具有细微差异的大文件,因此两个此类文件之间的差异的最大长度与其长度无关。换句话说,它是一个常数。因此,算法在 O(m) 的线性空间和时间内运行,n~1!
- 0.2 版本:在非顺序或未优化比较的情况下,两个文件在处理前被读入内存。因此,假设我们按行分词,p = Max(k, l),其中 k 是第一个文件的行数,l 是第二个文件的行数,算法在 O(p) 的多项式空间和 O(p + ... + 2 + 1) 的时间内运行。
注意:该实现不适用于比较大量更改的大文件。例如,虽然 3MB(或任何其他大小)的文件有 3 个不同的标记(更改),但可以在不到 100ms 的时间内进行比较,而 3MB 的文件有 15000 个不同的标记(更改)需要长达 2 分钟。
设计
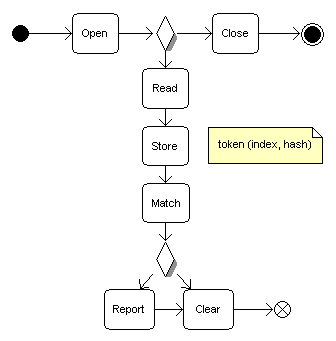
活动图
下面的活动图只是对上述算法原理的可视化表示。它在操作和决策点方面都非常简单。活动图有助于识别实现过程中所需的对象和操作。
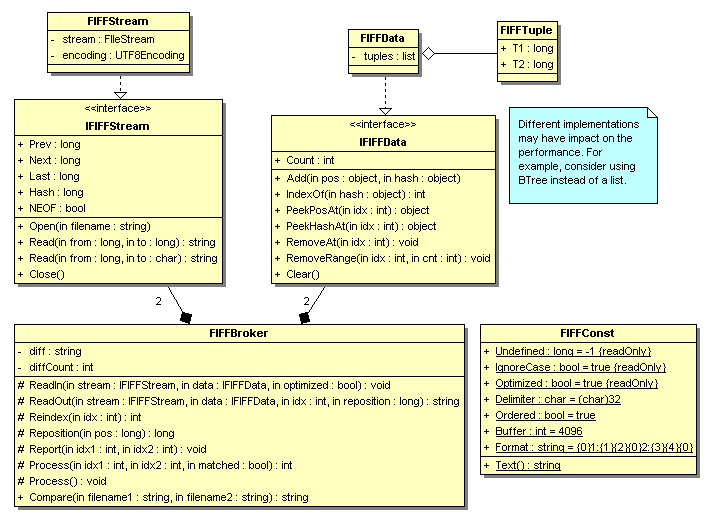
类图
下面的类图描述了用于实现该算法的对象。请注意,由于 FIFFBroker 不关心数据源和将使用的临时存储类型,只要它们提供某些可用操作,因此 IFIFFStream 和 IFIFFData 被定义为接口。这为未来的优化提供了便利。在累积差异时临时存储的 FIFFTuple 包含两个整数值,以节省空间。输出格式、读取缓冲区和标记分隔符是独立定义的,以便进行性能调优和基本自定义。
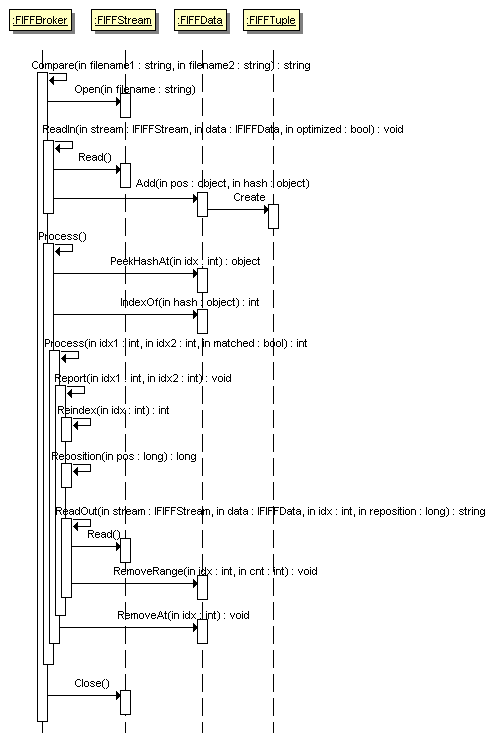
序列图
顺序图模仿了活动图,但它有助于确保正确识别完成任务所需的所有对象和操作。冗余的对象和/或操作也可以暴露出来。
实现
有关更多详细信息,请参阅上传的 源代码文件。
- 计算并显示两个文本文件之间的差异
try { FIFFBroker<FIFFStream, FIFFData> broker = new FIFFBroker<FIFFStream, FIFFData>(); Console.Write(broker.Compare(args[0], args[1])); } catch (Exception e) { Console.WriteLine("Exception: " + e.Message); } - 测量并报告执行时间
Stopwatch stopWatch = new Stopwatch(); // DateTime startTime = DateTime.Now; stopWatch.Start(); // ... stopWatch.Stop(); Console.WriteLine(stopWatch.Elapsed); //Console.WriteLine(new TimeSpan( DateTime.Now.Ticks - startTime.Ticks)); - 测量并报告内存使用情况
Process FIFFProcess = Process.GetCurrentProcess(); long startPeakWorkingSet64 = FIFFProcess.PeakWorkingSet64; // ... FIFFProcess.Refresh(); Console.WriteLine("Delta peak physical memory usage: {0}", FIFFProcess.PeakWorkingSet64 - startPeakWorkingSet64); // Note that because we did not create the process, we should not free it.另请参阅:GC.Collect 方法[^]。
// Put some objects in memory // ... Console.WriteLine("Memory used before collection: {0}", GC.GetTotalMemory(false)); // Collect all generations of memory. GC.Collect(); Console.WriteLine("Memory used after full collection: {0}", GC.GetTotalMemory(true));
集成
要运行 FIFFConsole 0.2 版本,请打开命令提示符,导航到包含可执行文件的目录,然后使用以下参数调用它:
- <filename1> - 第一个文本文件的路径和名称,必需,默认值:N/A
- <filename2> - 第二个文本文件的路径和名称,必需,默认值:N/A
- <delimiterchar> - 标记分隔符的字节表示,可选,默认值:32 (即空格)
- <ordered> - 指示是否执行非顺序比较的标志,可选,默认值:false
- <buffer> - 扫描差异时读取的块的大小,可选,默认值:4096(即 4K)
- <format> - 输出格式,可选,默认值:{0}1:{1}{2}{0}2:{3}{4}{0}(其中 {0} = 新行,{1} = 差异在文件 1 中开始的位置,{2} = 此位置在文件 1 中存在的文本,{3} = 差异在文件 2 中开始的位置,{4} = 此位置在文件 2 中存在的文本)

如果您想自动化该过程和/或一次比较多个文件,您可以编写一个脚本来选择这些文件,调用 FIFFConsole,并按需存储结果。下面是一个这样的脚本,它接收一个位于修改文件夹中的文件,在原始文件夹中查找同名文件,并将文件差异存储在另一个文件夹中。此脚本由 Natasha Guigova 编写。它的一个版本已用于质量保证 (QA) 回归测试。
' To run this script, use the command prompt and type: cscript /nologo
' <scriptfilename />.vbs
strBaseFolder = "C:\Sandbox\Test\Original"
strCurrentFolder = "C:\Sandbox\Test\Modified"
strResultFolder = "C:\Sandbox\Test"
strExeFile = "%comspec% /c C:\Sandbox\Test\FIFFConsole.exe"
Set objShell = CreateObject("WScript.Shell")
Set objFSO = CreateObject("Scripting.FileSystemObject")
Call runCompare
Function runCompare
On Error Resume Next
If objFSO.FolderExists(strResultFolder) = False Then
objFSO.CreateFolder(strResultFolder)
End If
Set objCurrentFolder = objFSO.GetFolder(strCurrentFolder)
Set colFiles = objCurrentFolder.Files
For Each objFile in colFiles
strFileBase = strBaseFolder & "\" & objFile.Name
strFileCurrent = strCurrentFolder & "\" & objFile.Name
strFileResult = strResultFolder & "\" & Replace(objFile.Name,
".html" , ".txt")
strCMD = strExeFile & " " & strFileBase & " " & strFileCurrent &
" 13 true 250 > " & strFileResult
objShell.Run strCmd,0,TRUE
Next
End Function
If Err = 0 Then
MsgBox "Task Completed"
Else
MsgBox "Error Source: " & Err.Source & vbCrLf & _
" Error Description: " & Err.Description
End If
Set objShell = Nothing
Set objFSO = Nothing
兴趣点
buffer 参数会影响性能,但不会影响内存使用。它允许对数据块进行预扫描以查找差异,并将算法仅应用于有差异的块,而不是整个文件内容。我预计差异越多,缓冲区就越小。如果它大于文件大小,则没有影响。例如,当 FIFFConsole 0.1 版本在 AMD 1.6 GHZ 笔记本电脑(2GB RAM)上使用以下 buffer 大小运行挑战中包含的 测试文件时:
- 4096 - 完成耗时接近 300 毫秒
- 1000 - 完成耗时接近 150 毫秒
- 500 - 完成耗时接近 125 毫秒
- 250 - 完成耗时接近 109 毫秒
- 100 - 完成耗时接近 140 毫秒
- 10 - 完成耗时接近 500 毫秒
- 0.2 版本:
buffer参数仅在顺序比较且optimized标志设置为 true 的情况下才有意义。在所有其他情况下,文件将被完全读取,算法将应用于文件的整个内容。

- 0.2 版本:
optimized标志适用于顺序比较,并指示文件是按块读取还是整体读取。在前一种情况下,算法仅应用于部分(必要且充分)数据,并且过程花费的时间明显更少。结果差异是等效的,尽管它们可能具有略微不同的表示。例如,当两个文件之间存在重复标记(如测试文件中的 <TR vAlign=top>)时,删除可能会报告为编辑后删除。
delimiterchar 参数是一个用于调优的占位符。它用于定义标记。标记用于计算差异。当 delimiterchar 为空格时,我们处理的是单词。需要注意的是,它不能很好地处理标点符号。“Text”和“Text,”将被视为不同的标记。在 HTML 或 XML 文件的情况下,不建议使用空格作为标记分隔符,因为“<h3>Revision </h3>”将被分词为“<h3>Revision”和“</h3>”。尽管与 delimiterchar 相关联的是字符,但标记的最大长度永远不会超过一行。可以定义更智能的分词逻辑,但这超出了本次挑战的范围。
根据输出,可以恢复文件内容。输出包含文件 1 中的位置、文件 1 中的差异以及文件 2 中的差异的信息。因此,
- 添加 (+) 等同于文件 1 中的差异为空
- 删除 (-) 等同于文件 2 中的差异为空
- 修改 (.) 等同于文件 1 和文件 2 中都存在差异
测试用例
考虑以下文本示例及其比较方式:
- This is a text
- This is a text simple
- This is a simple text
- This is a simple text, right?
- This is a complex text
- This is a complex convoluted text.
- This is convoluted text that my sister wrote.
- This text is in red
- I like ice-cream! :D
结论
所提出的实现可以通过几种简单的方式进行扩展:
- 在差异确定时生成事件,以便通知任何订阅者
- 实现
IFIFFStream接口以处理文件以外的对象 - 实现分隔符查找表,以支持更灵活的标记集
- 仅处理字节数组(而不是
string),以支持二进制文件和其他通用输入
本文所述的算法和实现旨在做到精简、高效、可扩展和可扩展。我很乐意收到您的评论。
资源
修订历史
- 2011-07-02:应用了错误修复
- 2011-07-02:添加了性能说明(感谢 Qwertie)
- 2011-04-25:修改了文章中部分图片的尺寸
- 2010-01-13:添加了用于流程自动化的 VB 脚本(感谢 Natasha Guigova)
- 2010-01-10:添加了0.2 版本,支持非顺序文件比较
- 2009-08-27:在算法部分添加了声明线性空间和时间执行的说明
- 2009-08-27:添加了测试机器规格
- 2009-08-27:添加了对
GC.Collect()的引用(感谢 Luc Pattyn) - 2009-08-24:添加了结论
- 2009-08-24:添加了时间和空间上限估算
- 2009-08-22:在 CodeProject 上发布