
分布式系统设计入门 - 2. 微服务架构中的拆分实践
4.64/5 (3投票s)
分布式系统设计入门 - 2. 微服务架构中的拆分实践
引言
本文将从如何拆分一个开源项目开始,介绍AP&RP技术的使用。这是分布式系统设计入门系列文章的第二篇。您可以点击下面的链接找到第一篇文章。
在入门篇1中,我们简要介绍了AP&RP技术。为了充分展示这项技术的惊人效果,我随机选择了github.com上的一个项目。这是一个名为shop的开源电商项目,由Manphil编写,地址为https://github.com/Manphil/shop。在此感谢他和所有开源作者。没有他们的工作,我将需要花费更多时间来编写本章的示例。首先,我将对该项目进行整体技术介绍。这是一个用JAVA语言开发的电商项目。开发环境为IDEA和Tomcat 8.5。使用的数据库为MySql。它分为两部分:前端使用Bootstrap和JQuery,后端基于Spring MVC、Spring、MyBatis开发,使用Maven构建项目。由于我们只分析服务器系统的分布,我们将跳过项目的构建、调试和前端部分。虽然这个例子是JAVA语言,但本文介绍的技术也适用于nodejs、C++、C等语言开发的服务器端软件系统。
整体产品功能和系统架构
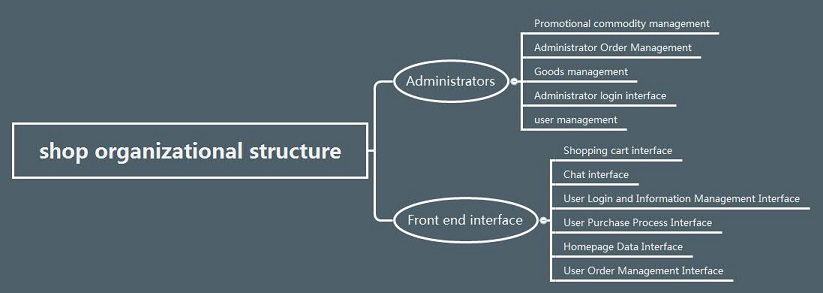
Shop并不是一个成熟的开源项目,许多功能都处于开发过程中。通过分析,我得出了一些令我惊讶的结论。我将在后面总结这些结论。Shop项目主要分为两部分,第一部分是系统管理,第二部分是前端调用接口。如图1所示,它有11个产品功能。
Shop系统架构也相对简单,分为后端服务和数据库。后端服务通过MyBatis中间件直接连接数据库,如图2所示。

Shop有62个可调用接口链接。也就是说,整个系统由62个任务组成。与拥有数百个接口的更成熟的电商项目相比,shop相对简单。
分析任务1
假设shop可以通过数据库集群实现AP操作,那么我们只需要对软件系统中数据的读写进行分类和RP分析,就可以知道项目shop是否可以进行分布式操作。在这里,我们选择shop中两个较复杂的任务来介绍具体的分析过程。其中之一是“/info/list”,它负责返回用户订单信息。它位于“shop/controller/front/CustomerController.java”文件中。
源代码如下:
@RequestMapping("/info/list")
public String list(HttpServletRequest request,Model orderModel){
HttpSession session=request.getSession();
User user;
user=(User)session.getAttribute("user");
if (user==null)
{
return "redirect:/login";
}
OrderExample orderExample=new OrderExample();
orderExample.or().andUseridEqualTo(user.getUserid());
List<Order> orderList=orderService.selectOrderByExample(orderExample);
orderModel.addAttribute("orderList",orderList);
Order order;
OrderItem orderItem;
List<OrderItem> orderItemList=new ArrayList<>();
Goods goods;
Address address;
for (Integer i=0;i<orderList.size();i++)
{
order=orderList.get(i);
OrderItemExample orderItemExample=new OrderItemExample();
orderItemExample.or().andOrderidEqualTo(order.getOrderid());
orderItemList=orderService.getOrderItemByExample(orderItemExample);
List<Goods> goodsList=new ArrayList<>();
List<Integer> goodsIdList=new ArrayList<>();
for (Integer j=0;j<orderItemList.size();j++)
{
orderItem=orderItemList.get(j);
goodsIdList.add(orderItem.getGoodsid());
}
GoodsExample goodsExample=new GoodsExample();
goodsExample.or().andGoodsidIn(goodsIdList);
goodsList=goodsService.selectByExample(goodsExample);
order.setGoodsInfo(goodsList);
address=addressService.selectByPrimaryKey(order.getAddressid());
order.setAddress(address);
orderList.set(i,order);
}
orderModel.addAttribute("orderList",orderList);
return "list";
}
- “
@RequestMapping (/info/list)”意味着URI“/info/list”的链接将触发函数“public String list”(HttpServletRequest request, Model orderModel)的调用。此调用不向函数传递参数。它可能以“https:///info/list”的形式触发。 - 在“
HttpSession session = request. getSession ();”中,首先读取session的数据。有关安全和权限的数据存储在session中。此代码验证只有登录用户才能使用此接口。请注意,session数据作为全局数据也是我们需要分析的数据之一。 - 在“
List<Order> orderList = orderService.selectOrderByExample(orderExample);”中读取指定用户的全部订单数据。“orderService.selectOrderByExample”最终会转化为MySQL数据库中的查询操作。 - 在获取了用户的所有订单信息后,通过语句“
orderItemList = orderService. getOrderItemByExample”查询特定订单中的商品信息。 - 在“
goodsList = goodsService.selectByExample(goodsExample);”中查询订单中的商品信息。 - 并在“
address = addressService.selectByPrimaryKey(order.getAddressid());”中查询相应订单的地址信息。
以上五种信息分别存储在`address'、`indent'、`orderitem'、`goods'和全局数据session中。这里是整个表的使用,用于读取数据。请注意这里使用的数据范围。以读取用户所有订单为例,使用的数据范围是整个`indent'表。获得的数据是用户的当前订单。这里使用的数据范围是边界,而不是获得的数据范围。通过以上分析,我们得到“/info/list”使用数据的范围,并将其记录在图3中。

分析任务2
我使用“/orderFinish”来分析数据写入的情况。“/orderFinish”的任务是将购物车数据提交到订单。代码如下:
@RequestMapping("/orderFinish")
@ResponseBody
public Msg orderFinish(Float oldPrice, Float newPrice,
Boolean isPay, Integer addressid,HttpSession session) {
User user = (User) session.getAttribute("user");
//Get order information
ShopCartExample shopCartExample = new ShopCartExample();
shopCartExample.or().andUseridEqualTo(user.getUserid());
List<ShopCart> shopCart = shopCartService.selectByExample(shopCartExample);
//Delete shopping carts
for (ShopCart cart : shopCart) {
shopCartService.deleteByKey(new ShopCartKey(cart.getUserid(),cart.getGoodsid()));
}
//Write order information to database
Order order = new Order(null, user.getUserid(), new Date(),
oldPrice, newPrice, isPay, false, false, false, addressid,null,null);
orderService.insertOrder(order);
//Inserted Order Number
Integer orderId = order.getOrderid();
//Write the order item into the "orderitem" table
for (ShopCart cart : shopCart) {
orderService.insertOrderItem(new OrderItem
(null, orderId, cart.getGoodsid(), cart.getGoodsnum()));
}
return Msg.success("Purchase success");
}
- 首先,“
@RequestMapping("/orderFinish")”将URI映射到orderFinish函数。引入了五个参数。当前端调用URI时,这五个参数会同时传递。 - 在第一句话中,“
User user = (User) session.getAttribute("user");”通过session获取当前用户信息。 - 在“
List<ShopCart> shopCart = shopCartService.selectByExample(shopCartExample);”中获取数据库中的用户购物车信息。 - 在“
shopCartService.deleteByKey(new ShopCartKey(cart.getUserid(),cart.getGoodsid()));”中删除了数据库中的购物车信息。 - 在“
orderService.insertOrder(order);”中,将购物车数据转换为order并提交到order数据库。 - 在“
orderService.insertOrderItem”中,将订单中的商品提交到数据库中的“orderitem”数据表中。
通过对上述读写数据范围的分析,我们可以看到。“/orderFinish”读取`shopcart'表和`session'中的数据。三个数据库中的表,`shopcart'、`indent'、`orderitem'被写入。写入数据的边界也是所有三个表。请注意,这是插入数据而不是更新。如果数据被更新,更新的范围会更小。我们将在后续章节中进一步讨论细微差别。我们的分析结果也如图4所示。

分布式工程
当我们整理完任务的所有读写数据后,我们将其放入表格文件(见附件)。我们发现,该项目中的只有少数操作使用了数据库字段。大多数数据使用了表中的所有数据字段。该项目中有6个任务无效。有28个任务读取数据。有30个任务写入数据。有一个写入数据的任务没有原子关系。29个原子相关任务被分为8组。去除无效任务后,剩余37组任务可以分布到37个服务器容器中。分布式任务组与有效任务的比例为69.3%,如图5所示。

其中,任务的原子关系是指读取的数据如果与其他数据存在写冲突,则只能放置在原子服务器容器中。在30个有写入数据的任务中,有29个任务具有原子关系,并被分为8组。例如,“/addCategoryResult, /saveCate, /deleteCate”都写入`category'表。因此,这三个任务具有原子关系,并被分为一组。这八组写入任务最多只能放置在八个具有原子属性的服务器容器中。也就是说,八个单线程服务器容器。
对于剩余的28个只读任务,我们已经假设使用了分布式数据库集群来模拟AP技术。这种数据库集群可以使用Oracle、HP vertica、SAP HANA或Ocean Base。这些都是世界知名公司的产品,我不需要做广告。虽然数据库集群模拟的AP操作效率较低,但为了让初学者更容易理解,我们用数据库集群代替AP操作。在接下来的章节中,我们将学习如何手动进行AP操作。假设数据库集群可以为每个任务提供额外的服务器节点来处理AP操作。该项目总体上可以分布到74个服务器集群。
通用分布式技术
令我惊讶的是,一个电商网站的工程离散性如此之高。在没有任何其他特殊技术的情况下,引入了数据库集群。它将服务器扩展了74倍,而无需修改任何代码。如果传统的按功能划分方法最多只能分为11个部分。此外,软件工程和数据库的划分耗时耗力。在这里,我将这种分布式技术的普遍应用称为通用分布式技术。通用分布式技术是一种基于最小修改工程的系统分布式方法。相比之下,AP&RP技术远不止于此。对于通过通用分布式方法处理的项目,我们将获得一个任务URI的映射表。以本项目为例,可以将37个服务器端软件副本简单地复制并放入37个服务器容器中。URI被映射到不同的服务器容器,使用nginx反向代理。请注意,您不需要在这里分割软件工程。只需让不同的服务器容器处理不同的请求。例如,我们配置其中一个服务器容器192.168.1.1来处理写入`category'表的操作。正如我们之前学到的,“/addCategoryResult”、“/saveCate”、“/deleteCate”都会写入`category',所以将配置添加到nginx中,如下所示:
location /addCategoryResult {
proxy_pass http:// 192.168.1.1:8080;
}
location /saveCate {
proxy_pass http:// 192.168.1.1:8080;
}
location /deleteCate {
proxy_pass http:// 192.168.1.1:8080;
}
通过将反向代理与数据库集群和37个服务器的副本结合起来,我们得到了如图6所示的分布式shop项目。

顺序依赖和数据依赖。
GOOGLE开发了GRPC协议,方便微服务之间的调用,但我建议您不要使用GRPC来建立内部服务之间的链接。我之前提到,实现AP&RP技术的主要目标是消除服务之间的顺序依赖。所谓的对服务的顺序依赖性表现为服务的相互调用。调用服务最先遇到的问题是数据映射的复杂性。例如,有服务A1、A2。如果没有调用关系,它们就是独立的A1和A2。如果A1在业务中调用A2,这相当于A1和A2在特定条件下共同执行一个任务。项目关系变成了三种A1、A2和A1&A2。这种复合时序关系实际上是一种条件服务合并。也就是说,原本相互独立A1和A2在特定条件下会被同时阻塞。这种阻塞导致整个系统性能的间歇性下降。如图7所示。

顺序依赖最常见的问题是建立服务之间原本不相关的合并关系,从而导致服务的间歇性阻塞。间歇性阻塞不一定会发生,但会以特定概率发生。这种特定概率随着顺序依赖的增加而增加。通常,当两个服务需要共享数据或发生数据冲突时,我们习惯于创建分布式锁、新服务或数据库事务来处理此类冲突。分布式锁、服务容器和数据库事务都是新的原子容器,但在不同情况下调用方式不同。也就是说,我们不知不觉地创建了大量的顺序依赖。如图8所示。

由于任务函数的修改会导致原子关系的增加,正确的做法是重新规划任务的分配。原子关系的那些任务一起调整。继续保持任务的数据依赖而不是顺序依赖。如图9所示。

一些知识点和问题
- AP&RP安全可靠吗?
首先,AP&RP技术不修改任何业务逻辑。没有添加额外的业务层和硬件层。因此,不存在AP&RP技术故障导致系统宕机的问题。在通用分布式技术中,从直观上看,它是从单服务器扩展到多服务器。这些服务器中的任何一个故障都不会导致整个集群业务停止。所以这种扩展是集群安全性的改进。旧的分布式技术更安全吗?我建议您阅读FLP定理的相关论文。分布式系统不会比硬件带来更多的可靠性。在这里,我们向辛勤工作的硬件工程师致敬,他们为我们提供了更高的可靠性。
- 谬论1. 不同功能分类中不存在原子任务。
因为功能的分类是主观和任意的。原子任务经常被分为不同的功能。例如,在活动商品管理中,“
/update”任务需要设置“goods (activityId)”与商品管理功能具有原子关系。将此任务与其余原子任务放在一起会更自然。在这里,我们应该将“/update”放在商品管理中,但这从产品设计的角度来看似乎很奇怪。 - 谬论2. 不能按功能分类,但这并不意味着是对的。
目前,大多数分布式系统都是按功能分类的。然后工程师根据是否有问题来纠正系统。虽然按功能划分的大多数系统都能正常工作。但我认为这只是工作得好。因为没有触发RP冲突,也就是说,原子关系的冲突。认为只要在一定概率下工作良好,就没有问题,这种想法非常危险且不精确。
- 系统的叠加给出了沉重的精神负担。
过多的软件功能层和过多的硬件系统层给开发人员带来了严重的精神负担。分层只是为了让阅读看起来更具层次感。软件的实际过程与触发点严重分离。这导致软件阅读的巨大障碍。例如,在这个例子中,从触发数据库操作到实际调用数据库,需要跳过三个文件。此外,作者还开发了大量最终未使用的数据库调用方法。所有这些都导致开发效率下降和开发成本增加。
- 灵活的自动化分布式系统。
随着软件系统访问量的增加,系统需要越来越精细地拆分,但随着拆分的越来越精细,项目的复杂性也会越来越高。当复杂性超出人脑在有限时间内能够理解的范围时,就需要计算机系统根据规则自动分解系统的能力。显然,在处理极其复杂的系统时,我们不能再仅仅依赖人力资源。因为人力资源管理本身极其不可靠和复杂。我们需要更灵活的自动化分布式系统。在未来的章节中,我们将讨论更多的技术细节,并最终完成一个灵活的自动化分布式系统。
- 从面向计算到异步网络扩展。
分布式科学的建立之初,主要是为了解决数学计算是否可以分解的问题。例如,我们是否可以使用分布式方法来反转哈希算法?当时,计算机只是计算的工具。此时,计算机系统更像是人类社会中工具的延伸。您可以将其视为商店、停车场收费员、外卖呼叫者。人际网络本身就是一个庞大的异步系统。当这个异步系统扩展到计算机系统时,计算机系统只是扩展了人类异步系统的高度离散性。这种离散性是分布和边界划分的基础。我们还将花更多时间讨论分布式技术的学术意义。
谢谢
首先,我想感谢我的妻子在我学术年期间的支持。我也感谢Code Project网站和编辑发布我的论文和教学文章。感谢您的阅读。我希望我的文章能帮助您了解分布式技术,并将AP&RP技术应用于您的网站设计。现在您可以开始分析您的网站是否可以分布式了。
历史
- 2019年5月7日:初始版本