
使用嵌套集提高层次结构性能
4.36/5 (19投票s)
2003 年 5 月 18 日
3分钟阅读
258697
1343
本文介绍了如何使用嵌套集来提高 SQL Server 和其他关系数据库中层次结构的性能
引言
本文和附带的代码演示了“嵌套集合”背后的理论和实践。该理论适用于任何数据库中的任何类型层级,但示例代码是使用 SQL Server 2000 编写的,并且已尽一切努力使其与大多数主要 SQL 提供程序兼容。
理论
嵌套集合依赖于层级的部分非规范化。它们可用于有效地使用层级,而无需依赖父/子链接。人们通常查看或表示层级的方式是使用父子关系,如下所示

上面的层级结构显示了一个虚构的公司组织结构,这些数据可以编译到数据库表中并很容易地表示出来,下面的 SQL 脚本显示了如何创建表并填充数据
-- Create the SQL Table
CREATE TABLE Employee
(
EmployeeID INT IDENTITY(1, 1) NOT NULL,
ParentID INT NULL,
JobTitle VARCHAR(50) NOT NULL,
FirstName VARCHAR(50) NOT NULL,
PRIMARY KEY(EmployeeID),
FOREIGN KEY ParentID REFERENCES Employee (EmployeeID)
)
GO
并填充数据
-- Set identity insert ON so we can insert the employee ID
SET IDENTITY_INSERT Employee ON
SET NOCOUNT ON
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (1, NULL, 'Managing Director', 'Bill')
-- Employees under Bill
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (2, 1, 'Customer Services', 'Angela')
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (3, 1, 'Development Manager', 'Ben')
-- Employess under angela
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (4, 2, 'Assistant 1', 'Henry')
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (5, 2, 'Assistant 2', 'Nicola')
-- Employees under ben
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (6, 3, 'Snr Developer', 'Kerry')
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (7, 3, 'Assistant', 'James')
-- Emplyees under kerry
INSERT INTO Employee (EmployeeID, ParentID, JobTitle, FirstName)
VALUES (8, 6, 'Jrn Developer', 'Tim')
SET NOCOUNT OFF
SET IDENTITY_INSERT Employee OFF
上面的 SQL 代码将创建代表上述层级所需的表。大多数层级是使用上面的 ParentID 方法开发的,通常足以应付,尤其是当层级具有固定数量的级别时。但是,如果应用程序的大部分基于层级,并且层级是动态的,那么上述方法的效率就会降低,并且使用成本非常高。各种常见的层级操作变得困难。例如,使用 ParentID 查找层级的叶节点变得非常困难,并且无法通过简单的 SELECT 语句轻松检索。要查找层级中任何级别的子级的任何父级,必须使用每个节点的 ParentID,这也很困难且效率低下,无法通过简单的 select 语句检索。
这就是嵌套集合变得非常有用的时候。如果我们稍微以不同的方式表示上面的层级,我们可以获得很多优势。下面是将相同层级表示为嵌套集合
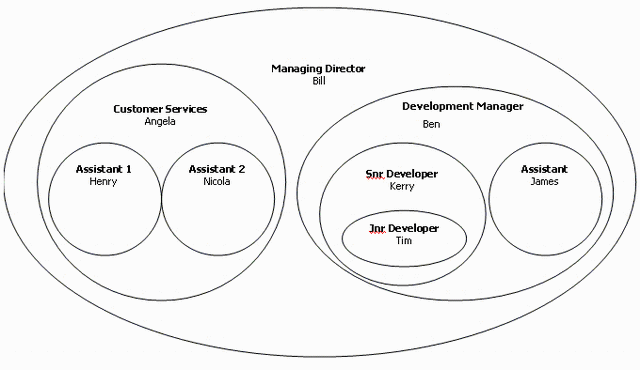
虽然乍一看这在视觉上有点令人困惑,但对于计算机系统来说,这很容易。上面的图表明每个节点都知道其所有后代,反之亦然。例如,我们可以很容易地从图中看到Ben 和 Angela 是 Bill 的孩子,因为它们包含在 Bill 中。我们还可以看到 Tim 和 James 是 Ben 的孩子,因为它们包含在 Ben 中。最终,这为我们提供了层级中每个成员之间的链接。
为了用数据表示这一点,我们需要为每个节点存储两个更多值,这些是集合的范围值。这些在下面的同一图中以蓝色和红色显示。

让我们称这些为左(红色值)和右(蓝色值). 这些值应与 ParentID 一起存储在 Employee 表中,这就是我们需要完全表示嵌套集合层级所需的一切。
-- Alter the employee table to include the left and right extent values
ALTER TABLE Employee ADD [LeftExtent] INT NULL
ALTER TABLE Employee ADD [RightExtent] INT NULL
GO
通过使用数据库的左值和右值,您可以挑选出一些简单的规则和简单的查询
-- If Left is between parent left and parent right then the node is a child
SELECT * FROM Employee
CROSS JOIN (
SELECT [LeftExtent], [RightExtent]
FROM Employee WHERE Firstname = 'Ben'
) AS Parent
WHERE Employee.[LeftExtent]
BETWEEN Parent.[LeftExtent] and Parent.[RightExtent]
-- All Leaf nodes (an item with any children) can be
-- identified by Left = Right - 1
SELECT * FROM Employee WHERE [LeftExtent] = [RightExtent] - 1
可以使用更高级的查询,但在解释这些查询之前,必须填充左值和右值。下面是用于填充左值和右值的 SQL 代码,有关其工作原理的解释包含在注释中
-- Create the stack table
DECLARE @tmpStack TABLE
(
ID INT IDENTITY(1, 1),
EmployeeID INT NOT NULL,
LeftExtent INT NULL,
RightExtent INT NULL
)
-- what we do is start from a parent, in this instance
-- we want to start from the very top which is the NULL parent
DECLARE @parentid AS INTEGER
SET @parentid = NULL
-- our counter is the variable used to set the left and right extent
DECLARE @counter AS INTEGER
SET @counter = 1
-- what we do is go check the parentid for children, if it
-- has children we push
-- it into the stack and move on to the next child
DECLARE @id AS INTEGER
DECLARE @oldid AS INTEGER
SET NOCOUNT ON
WHILE 1 = 1
BEGIN
SET @id = NULL
-- get the first row which is a child of @partentid, which has not already
-- been pushed onto the stack
INSERT INTO @tmpStack
(
EmployeeID,
LeftExtent
)
SELECT TOP 1 EmployeeID, @counter
FROM Employee
WHERE ISNULL(ParentID, 0) = ISNULL(@parentid,0)
AND EmployeeID NOT IN (SELECT EmployeeID FROM @tmpStack)
-- just check we are getting the right identity value
-- this value does not get reset once its reas so we
-- need to see if its the same as the older one
SET @id = SCOPE_IDENTITY()
IF ISNULL(@id, 0) = ISNULL(@oldid, 0)
SET @id = NULL
ELSE
BEGIN
SET @oldid = @id
SET @counter = @counter + 1
END
-- if we have children (i.e if this operation inserted a row,
-- then we carry on
IF @id IS NULL
BEGIN
-- no rows left, which means we want to pop the last item
SELECT TOP 1 @id = ID FROM @tmpStack
WHERE RightExtent IS NULL ORDER BY ID DESC
-- there are no items left to pop, so exit the procedure
IF @id IS NULL
BREAK
UPDATE @tmpStack
SET RightExtent = @counter
WHERE ID = @id
SET @counter = @counter + 1
SELECT @parentid = ParentID
FROM Employee WHERE EmployeeID =
(SELECT EmployeeID FROM @tmpStack WHERE ID = @id)
END
ELSE
BEGIN
-- this is easy enough, move on to the next level
-- we want the parent id of the item just inserted
SELECT @parentid = EmployeeID FROM @tmpStack WHERE ID = @id
END
END
-- And update all the Items in Hier_Dept
-- in the original hierarchy table
UPDATE e
SET LeftExtent = ts.LeftExtent,
RightExtent = ts.RightExtent
FROM Employee e
INNER JOIN @tmpStack ts
ON ts.EmployeeID = e.EmployeeID
GO
上面代码的逻辑非常简单,如果您将层级想象为其原始结构,则需要对左右值进行编号,就像您在树的外部绘制一条线一样,例如

下面是一些使用左右值查询数据的更多示例
-- Which level of the hierarchy are the employees on
SELECT COUNT(P2.EmployeeID) AS level,
P1.FirstName,
P1.LeftExtent ,
P1.RightExtent
FROM Employee AS P1
INNER JOIN Employee AS P2
ON (P1.LeftExtent BETWEEN P2.LeftExtent AND P2.RightExtent)
GROUP BY P1.FirstName, P1.LeftExtent, P1.RightExtent
ORDER BY Level ASC
-- counting the employees of a manager (children of a node)
SELECT p1.FirstName,
COUNT(p2.EmployeeID) Employees
FROM Employee p1
INNER JOIN Employee p2
ON (p2.LeftExtent BETWEEN p1.LeftExtent AND p1.RightExtent
AND p2.LeftExtent <> p1.LeftExtent)
GROUP BY p1.FirstName
ORDER BY Employees DESC
就是这样了。简而言之的嵌套集合。我希望您发现这些代码有用且有趣。如果您需要有关该理论的更多详细信息,则有很多 SQL 网站可以提供有关此主题的一些信息。如有任何更正,请随时给我发电子邮件!