
Python 嵌入式 XML 和测试自动化
4.59/5 (6投票s)
Python 代码嵌入 XML 中,并在运行时进行解析以生成数据值。
介绍
通过 Python-Embedded XML(简称 PeXml),用户可以将 Python 脚本嵌入 XML。Python 脚本将在运行时进行解析以生成数据值。例如,PeXml 可以将以下 XML
<!-- Python-Embedded XML -->
<Data>
<StudentID>'SID0000' + str(dg.random.randrange(100)).zfill(3)</StudentID>
<Class>dg.round_robin(['Mon 7am', 'Tue 2pm', 'Thur 9am', 'Fri 1pm'])</Class>
<ExtraCredit>dg.extra_credit(0.2)</ExtraCredit>
</Data> 转换为
<!-- After Evaluation -->
<Data>
<StudentID>SID0000023</StudentID>
<Class>Tue 2pm</Class>
<ExtraCredit>No</ExtraCredit>
</Data> 其中 Python 函数实现在用户定义的 Python 模块中。
#dg.py
import random
index = 0
def round_robin(l):
global index
index = index + 1
return l[index % len(l)]
def extra_credit(probability):
if random.random() < probability:
return 'Yes'
else:
return 'No' XML 广泛用作 Web 服务或其他中间层事务的输入(或输出)。在测试这些事务时,测试工程师需要传入不同的值来验证不同的业务逻辑。通常,业务逻辑可能非常复杂,此时随机生成的假数据不足以满足需求。PeXml 的设计旨在解决此问题,它允许测试工程师
- 在输入 XML 中实现复杂的业务逻辑来生成数据值,
- 灵活地更改业务逻辑,以及
- 保留一个事务内或事务之间参数的数据依赖关系。
背景 - 测试自动化
测试自动化总是概念上高谈阔论,实践中却鲜有成效。主要挑战在于
- 复杂性
- 灵活性
- 数据依赖
复杂性: 一位聪明开发者的几行源代码就可以实现非常复杂的业务逻辑,而这些逻辑需要数十甚至数百种输入参数组合才能穷尽。传统上,测试人员必须手动枚举所有组合。这是一项 直接 的任务,但耗费的时间远远超出通常紧张的测试计划所允许的范围。
测试自动化引入了另一个复杂层。假设我们已经记录了所有测试用例。手动执行测试用例可以容忍测试用例中的缺陷,而自动执行则不能。人类测试人员在执行测试用例时可以检测和修复错误,但测试程序会直接崩溃。想到要测试测试程序本身?所需的时间是爆炸性的。
负载测试是一种特殊的自动化测试。通常在负载测试期间会执行数百万甚至更多的事务。所有这些事务都必须完全自动化,并且不能容忍任何错误。如果出现任何错误,测试人员将非常挠头,难以确定是测试程序错误,还是系统无法承受负载。例如,一个事务发出了“未找到数据”的错误,乍一看是合法的函数错误。但根本原因可能是, 重载 下数据加载器未能将数据上传到数据库。
灵活性: 假设测试人员经历了无数个不眠之夜,终于修复了测试程序中的所有错误。通常此时测试周期已接近尾声。他会希望在下一个版本中重用该测试程序,这样所有不眠之夜才算有所 值 。 悲剧 的是, 新版本中业务逻辑发生了变化 ,他不得不重新做大部分工作。
业务逻辑的变化是新版本的主要驱动因素,特别是对于 企业 客户而言,他们对用户界面的外观和感觉优先级较低,而对业务流程优先级较高。在一个快节奏的世界里,当每个人都想降低成本并提高生产力时,对业务流程的微调就变得更加频繁。举几个例子:供应链经理想为新产品削减几个步骤, 制造商 想在生产路线中增加几个工具,或者在线零售商想收集新型顾客数据。
具体到测试自动化,灵活性也意味着能够快速切换不同场景的能力。在负载测试中,通常客户需要两种场景:正常 vs. 压力。负载的混合也很重要。数据库管理员可能想了解当大多数事务是读取事务与大多数是写入事务时的系统性能。
数据依赖: 数据依赖有两种级别。一种是同一事务内的参数之间,我们称之为 局部依赖 。 两个或多个数据值的特定组合触发特定业务流程是一种常见的做法。例如,过程控制系统可能会记录烘烤过程开始和结束时的烤箱温度,并在温差大于阈值时触发警报。测试程序必须能够为“happy path”测试用例生成在阈值内的温度,为“unhappy path”测试用例生成超出阈值的温度。
另一种是 全局依赖 。可以通过连接多个 Web 服务或其他类型的事务来构建复杂的业务流程。在验证此类业务流程时,需要跨所有事务维护数据 完整性 。例如,在线 零售商 可能会为客户调用多个事务。客户 ID,作为所有事务的关键参数,必须在所有事务中保持一致。
一个 优雅 的解决方案是将测试程序分成两部分:一部分用于建模流程,另一部分用于建模数据。好处是流程模型的更改不会影响数据模型,反之亦然。通过为流程模型和数据模型引入配置文件来实现灵活性。流程模型通常就是一系列事务。通过配置文件,可以轻松地添加、删除或交换序列中的步骤,以模拟业务流程的更改 或在测试场景之间切换。
然而,配置文件本身在表达所涉及的逻辑方面存在不足,尤其是在数据依赖方面。对于数据模型,通常配置文件可以指定常量值、随机数、数字范围或字符串列表。任何更复杂的情况都需要某种编程语言。
像 Python 这样的脚本语言是一种轻量级的 编程 语言,它需要的编程技能更少,并且不需要 编译 成二进制代码。将 Python 脚本等脚本文本嵌入到配置文件中将 自动 解决问题。如今,XML 是事务输入和输出的 事实标准 。因此,我们提出了 Python-Embedded XML 的概念,它可以灵活地编码复杂的数据模型并保持局部和全局依赖。
使用代码
PeXml 包含两部分:一个 C++ DLL 和一个 C# DLL。相应地,附带的源代码包包含两个 Visual Studio 2008 项目,一个 C++ 项目:PythonInterpreter(用于 C++ DLL)和一个 C# 项目:PythonXML(用于 C# DLL)。
C++ DLL 使用 Boost.Python 来调用 Python 解释器并解析 Python 脚本。C# DLL 使用 XML DOM 遍历 XML 树并调用 C++ DLL 进行 Python 解析。我们选择这种两层架构是因为 Boost.Python“能够实现 C++ 和 Python 编程语言之间的 无缝 互操作性”;而我们的测试程序是用 C# 编写的,无论如何都需要在某个点从 C++ 切换到 C#。
原则上,用 C++ 实现所有功能并非难事。这可能更 受欢迎 ,因为 Python 和 Boost.Python 都是平台无关的。如果所有东西都用 C++ 实现,PeXml 也将是平台无关的。有兴趣的读者可以将其作为一项练习来完成。
先决条件
由于 PeXml 同时使用了 Python 和 Boost.Python,读者在使用 PeXml 之前需要同时安装它们。对于初学者来说,最好的方法是下载预编译的 Windows 安装包。存在多个包。我们使用的是 ActivePython 2.7.2 和 BoostPro 1.47.0。
读者还需要确保 Python DLL 和 Boost.Python DLL 都在系统路径中。否则,PeXml 会抱怨找不到 DLL。
python27.dll - Usually located at C:\Python27 or C:\Windows\system32
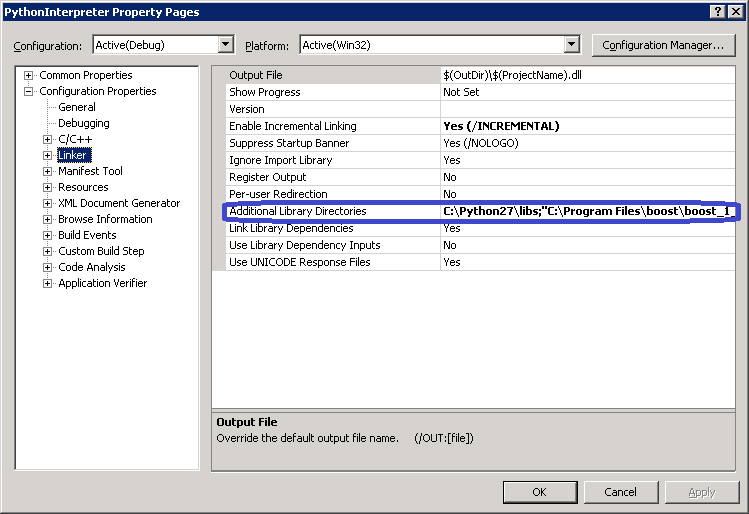
boost_python-vcnn-xx-yy-1_47.dll - Usually located at C:\Program Files\boost\boost_1_47\lib 如果读者想编译源代码,在 C++ 项目:PythonInterpreter 中,需要将“附加包含目录”和“附加库目录”设置为 Python 和 Boost.Python 的正确包含和库路径。

构建 PeXml 解决方案将生成两个 DLL,使用 PeXml 时需要两者。
PythonInterpreter.dll
PythonXML.dll
一个工作示例
要使用 PeXml,读者可以创建一个新的 C# 项目(使用 Visual Studio 2008)并添加对 PythonXML.dll 的引用。读者还需要将两个 DLL 复制到当前路径,否则会 抱怨 找不到 DLL。

我们需要添加以下命名空间
using System.Xml;
using PythonXml; 以下代码片段将加载并解析一个 Python-Embedded XML。
static void Main(string[] args)
{
Interpreter interp = new Interpreter();
interp.InitPython(@"D:\\Python", "dg");
string xml = "<!-- Python-Embedded XML -->" +
"<Data><StudentID>'SID0000'+ str(dg.random.randrange(100)).zfill(3)</StudentID>" +
"<Class>dg.round_robin(['Mon 7am', 'Tue 2pm', 'Thur 9am', 'Fri 1pm'])</Class>" +
"<ExtraCredit>dg.extra_credit(0.2)</ExtraCredit></Data>";
XmlNode node = interp.Interp(xml);
System.Console.WriteLine(node.OuterXml);
}
首先,初始化 `class Interpreter` 的新实例,然后调用
InitPython(string path, string package)来初始化 Python 解释器(或虚拟机),并从路径 `path` 加载名为 `package.py` 的用户定义的 Python 模块。用户定义的模块定义了将嵌入 XML 中的函数。它可以导入其他 Python 模块。可以定义全局变量来存储值。在运行时,不同的函数可以引用全局变量来实现数据依赖。
然后调用
XmlNode Interp(string xml) 来解析 Python-Embedded XML 并返回 `XmlNode` 的一个实例。返回节点对象是为了通常需要对该节点进行一些后续处理。有些人可能想检查几个参数的值;有些人可能想操作其中一些值。这些类型的任务可以轻松地在节点对象上执行。
PeXml 还提供了一组方法来设置和获取 Python 模块中定义的全局变量的标量值。
public void SetString(string key, string value)
public void SetInt(string key, int value)
public void SetDouble(string key, double value)
public string GetString(string key)
public int GetInt(string key)
public double GetDouble(string key) 以本文开头的 dg.py 为例,测试程序可以通过以下方式设置全局变量 `index` 的值:
interp.SetInt("index", 5) 或者通过以下方式获取 `index` 的当前值:
int index = interp.GetInt("index") 更多关于 Python
嵌入 XML 中的 Python 脚本必须是一个求值为字符串的表达式,或者是一个返回字符串的函数。这减轻了 PeXml 处理不同类型返回值的负担。由于 XML 中的所有数据值都是字符串,因此此限制是 合适的 。
对于数值,Python 有一个内置函数 `str()` 来将它们转换为字符串。 例如,
str(5)
str(6.0) 会将整数和浮点数转换为相应的字符串。
如果用户想将常量值嵌入 XML,他们需要将其放入 Python 字符串格式,即用单引号或双引号括起来的字符串,并转义特殊字符。例如,
'a Python string'
'C:\\Program Files\\boost\\boost_1_47' # a path where character \ is escaped
'It\'s a Python string' # character ' is escaped Python 解释器会将它们视为字符串表达式并返回它们对应的值。
全局变量定义在用户定义的 Python 模块的顶部。在 Python 函数中,必须通过 `global` 语句来指示全局变量。否则,Python 会将其视为局部变量。
例如,以下代码片段 声明 了一个全局变量 `index`,该变量在函数 `round_robin()` 中被引用。
index = 0
def round_robin(l):
global index
index = index + 1
return l[index % len(l)] 每次调用函数 `round_robin()` 时,全局变量 `index` 都会加 1。因此,下一次调用将返回列表中的下一个值。
全局变量用于实现局部和全局数据依赖。
如果 `round_robin()` 在 XML 中被多次调用,它将按顺序返回列表中的值。这可用于生成互斥值。
例如,根据 `index` 的初始值,以下 XML
<Data>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
</Data>
将被转换为
<Data>
<Number>1</Number>
<Number>2</Number>
<Number>3</Number>
<Number>4</Number>
</Data> 无论 `index` 的初始值是什么,我们都能保证 XML 中的 `Number` 参数必须具有不同的值。
Boost.Python 为进程初始化一个单例虚拟机。因此,Python 全局变量也可以用于在进程内实现全局数据依赖。例如,假设我们有四个事务,`Step1`,`Step2`,`Step3`,和 `Step4`。它们各自的 XML 是
<!-- Input XML for Step1 -->
<Data>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
</Data>
<!-- Input XML for Step2 -->
<Data>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
</Data>
<!-- Input XML for Step3 -->
<Data>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
</Data>
<!-- Input XML for Step4 -->
<Data>
<Number>str(dg.round_robin([1, 2, 3, 4])</Number>
</Data> 如果测试程序按顺序调用这四个事务,无论顺序如何,我们都可以保证每个步骤的 `Number` 必须有一个不同的值。
兴趣点
设计考量
为什么选择 Python? 我们选择 Python 是因为它在与其他编程语言的 互操作性 方面表现出色。有 Boost.Python 可以实现与 C++ 的无缝互操作,也有 IronPython 可以实现与 C# 的互操作。
为什么选择 Boost.Python? 一方面,我们更喜欢它无缝的互操作性。另一方面,Boost.Python 巧妙地使用对象来维护引用计数,程序员无需担心内存泄漏或垃圾回收。
为什么不将用户定义 Python 包的路径和名称作为 XML 声明中的属性? 可以将它们作为 XML 声明中的属性,例如
<?xml version="1.0" encoding="UTF-8" PythonPath="D:\\Python" PythonPackage="dg" ?>但这样的话,在逻辑上 Python 包是 XML 的一个属性,这与使用全局 Python 变量实现多个 XML 之间的全局数据依赖的概念相冲突。
已知问题
PeXml 未处理所有 Boost.Python 异常。 未处理的 Boost.Python 异常将终止进程。 这对我们来说是可以接受的,因为我们主要在测试程序中使用 PeXml。用户应具备处理这些异常的知识。如果这对任何用户都无法容忍,可以按照 PythonInterpreter.cpp 中的 `PythonEval()` 示例来实现适当的异常处理。
从 PythonInterpreter.dll 返回的字符串值的长度限制为 1K 字节。 这是因为我们选择在 C++ 和 C# 之间使用显式封送来处理字符串。C# 端将初始化一个 1K 字节的 StringBuilder,并将其传递给 C++ 端以接收返回的字符串值。优点是安全。缺点是灵活性。在我们的实践中,我们没有遇到任何长度超过 1K 字节的 XML 值。无论如何,限制可以轻松扩大。
历史
2012 年 7 月 7 日 - 第一个版本。