
C++ 反向反汇编
4.86/5 (68投票s)
2003年5月27日
32分钟阅读
535611
本文旨在为现代 C++ 应用程序的反编译提供材料
技术细节
本文旨在为用C++编写的应用程序的现代反编译提供资料。我们假设您对C++、X86汇编和Windows有扎实的理解。
概述和目录
- 为什么C++反编译是可能的?
- 引言
- 现代实例
- 编译器特定
- C++协议
- 引言
- 全局变量
- 表达式
- 返回值
- 函数调用和堆栈
- 局部变量
- C++关键字
- 引言
- If语句
- For
- 结构体
- 技术算法
- 实际反编译
- Windows应用程序反编译入门
- 反编译示例应用程序
特殊情况:编译器特定
编译器特定
每个编译器都不同,例如它们的 CrtlStartUp 例程、它们的语句汇编 (switch , if, while),以及许多其他方面,都会导致每个编译器生成不同的代码,即使您在两个编译器上编译相同的C++代码,最终结果也会不同。因此,我将只关注一个编译器,那就是Visual C++编译器。
Visual C++由微软生产,目前提供最快、最优化的代码。这并不是说本书提供的所有信息都仅适用于Visual C++,我只是说本书中呈现的某些信息可能仅在Visual C++上有效。
如果您没有Visual C++,也没关系,有许多其他编译器可用,而且本书中的大部分信息对它们也同样适用。
第一章:为什么C++反编译是可能的?
1.1 引言
我被问过很多次,C++反编译是否可行?这不仅是因为编译器的复杂性,还因为在编译过程中丢失了大量信息,例如注释、包含文件、宏等等。因此,人们常常想知道这是否值得追求。我想从程序编译时会完全丢失什么,以及会保留什么这个话题开始,请参考表1.1.1,看看我们丢失了什么,又保留了什么。
|
丢失内容 |
保留内容 |
|
模板 |
函数调用 |
|
类 |
动态链接调用 |
|
宏 |
Switch语句 |
|
包含文件 |
局部变量 |
|
注释 |
参数 |
这并不是说“保留内容”中的所有内容都100%存在,它只是意味着它们非常简单且实用,便于逆向工程。因此,我选择先处理“保留内容”部分,因为它更容易。
随着本书的进展,请记住逆向工程几乎从不简单,需要大量的实践。逆向工程一个已创建的事物比从头创建它要困难得多。
开始逆向工程的一个好方法是反编译您自己的程序,看看每个C++函数具体是如何工作的,然后将这些知识应用到其他领域,因为查看成千上万行的汇编代码并不是一件有趣的事情。
1.2 现代实例
现在,当您阅读本书时,您可能会开始认为,“任何翻译成另一种语言的东西都可以重新翻译回同一种语言”,对吗?嗯,反汇编并非如此,很多东西都会丢失,而且很多东西您必须在过程中自己推测(假设)。
因此,我想在书的开头提供一些实际的反编译示例,给您带来希望。
为了开始反编译,我决定从主要的C++语句入手
Int main(int argc, char * argv[])
现在,由于PE格式告诉我们可执行文件的开头,因此我们可以轻松地在任何可执行文件中找到此语句。因此,我们可以简单地读取特定可执行文件的PE格式并获取其起始地址。或者我们可以吗?
这就是通用运行时库(CRTL)发挥作用的地方。您知道,当您编译C++程序时,大多数编译器(因为这是编译器特定的东西)会按以下顺序执行:
CrtlStartUp();Int main(int argc, char * argv[])CrtlCleanUp();
这意味着我们无法查看PE文件并获取我们的代码起始地址,我们只能获取CrtlStartUp()代码的起始地址。我们有两个选择:要么反编译CrtStartup代码,要么跳过它。我更喜欢后者,我们稍后会处理通用运行时库。
第二章:C++协议
2.1 引言
C++之所以设计得如此出色,主要原因之一是它在汇编中有严格的协议。C++有一些非常静态的汇编,例如在返回值时,总是放在EAX寄存器中,而函数调用通常总是使用堆栈。因此,反汇编器可以利用这些静态汇编获得先机。
我们应该首先处理的是全局变量,因为如果您来自许多高级语言,您可能会有一些误解。
2.2 全局变量
您知道有多少本书说内存是随机存储在计算机上的,这在很大程度上是真的,但您的应用程序对全局变量的内存分配是相当静态的。没错,每次运行程序时,您的静态分配变量将始终位于同一位置。
另一个有趣的事实是,变量不存储数据,它们指向存储数据的位置。
这是一个C++示例
#include "stdafx.h" #include "windows.h" char * globalvar = "Whats Up"; int APIENTRY WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) { // TODO: Place code here. globalvar = (char *)0x400000; return 0; }
这是对反汇编的深入分析
00405030: global_var dd 405034h
00405034: global_var_value db 'Whats Up',0
mov global_var,400000h
好的,这证明了变量不存储数据。如您所见,编译器会自动将我们的global_var指针初始化为 global_var_value 的地址。
好的,到目前为止,我们知道变量只是值的指针,所以我们可以改变变量指向的位置,对吗?是的,我们可以,使用 mov global_var, 400000h 。因此,每当编译器访问 global_var 时,它将查看存储在 405030h 处的值,并得到 400000h。
如果您感到困惑,请记住 global_var 存储在 405030h,并参考图2。

这张图很直观,如果您仍然不清楚一切是如何工作的,我建议您找一本好的汇编书,学习什么是间接寻址。
我们刚刚处理了一个指针变量,现在来处理一个普通变量,因为这要简单得多。
#include "stdafx.h" #include "windows.h" char globalvar[] = "Whats Up"; int APIENTRY WinMain(HINSTANCE hInstance, INSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) { globalvar[0] = 'A'; globalvar[5] = ‘U’; return 0; }
编译后变成
00405030 global_var db “Whats up”,0
mov global_var, ‘A’
mov global_var + 5 , ‘U’
我们立即可以看出,常规变量比全局变量简单得多。我们只需要引用内存中存储我们数据的地址。当然,在机器码中我们看不到像 global_var 这样的漂亮名称,所以这是一个纯反汇编。
00405030 “Whats Up”,0
mov 00405030,’A’
mov 00405035,’U’
如您所见,我们只是在修改存储在 00405030 和 00405035 处的值。
您应该已经掌握了变量和指针变量的知识,因为这些信息将不再解释。如果您有任何不明白的地方,请重读一遍。
2.3 表达式
好吧,我们都知道C++具有接近英语的语法,我们可以用它进行编程。但是X86汇编代码不是这样,例如,看看下面的语句
Int s = 3 + 4 + 1 + 5 + 9;
如何在汇编中计算这个?很简单,看看下面的C++示例
#include "stdafx.h" #include "windows.h" int s1 = 3; int s2 = 4; int s3 = 1; int s4 = 13; int APIENTRY WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine, int nCmdShow) { // TODO: Place code here. s1 = s2 + s3 –s4 + 34; return 0; }
编译后变成
00405030 s1 dd 3
00405034 s2 dd 4
00405038 s3 dd 1
0040503C s4 dd 1
mov eax, s2
00401008 add eax, s3
0040100E sub eax, s4
00401014 add eax, 34
00401017 mov s1, eax
好的,编译器对代码进行了一些优化,但仍然很容易理解。
- 编译器做的第一件事是加载
eax,将mov eax, s2的值赋给它。 - 现在
eax包含4。接下来我们把eax和s3相加, - 现在
eax包含5。之后,我们从s4中减去eax, - 现在
eax包含4。之后,我们将34加到eax上, - 现在
eax包含38。 - 然后,我们通过将
s1移动到eax中来完成,eax现在包含38。现在s1包含38。
您通常会看到编译器在表达式中使用寄存器而不是变量,因为寄存器速度更快。
由此我们可以得出结论,对于每个数学运算符,编译器都会将其映射到一个特定的X86指令。下面是一个表格
|
C++运算符 |
X86指令 |
|
* (乘法) |
Mul, (浮点数使用fmul) |
|
/ (除法) |
Div (浮点数使用fdiv) |
|
- (减法) |
Sub |
|
+ (加法) |
Add |
如您所见,我们可以使用上表轻松解析大多数C++语句。
作为测试,我们将查看一个示例反汇编转储,并手动将其反编译成C++。
0000000 2
0000001 3
0000002 4
0000003 0
0000004 1
0000005 mov al, [00000000]
add al, [00000001]
mov ch, [00000002]
mul ch
mov [000000003],ax
好的,我们首先要弄清楚他们使用的是什么类型的变量。
从我们看到的情况来看,他们使用了al和ch,它们是8位寄存器。因此,这意味着无论何时引用8位寄存器,都表示该变量是Char类型。
向下看,您会看到他们执行了“mov [000000003], ax”,由于ax是16位寄存器,变量类型是short int。
这里有一个小表,以便您可以将寄存器映射到变量类型
|
X86寄存器 |
C++类型变量 |
|
8位寄存器 ( |
Char |
|
16位寄存器 (AX) |
Short int |
|
32位寄存器 (EAX) |
Int |
到目前为止,我们看到对内存地址有4个引用,因此我们知道有4个变量。第一个[000000000]显然是char类型变量,因为我们看到,
mov al, [00000000]”
并且al是8位寄存器。
所以,我们给[0000000]命名为s1。我们还看到 [0000000] 到 [00000002] 都被8位变量引用,这意味着它们也是char类型。最后一个 [00000003] ,使用方式为“mov [000000003] , ax”,是short int类型,因为ax是16位的。
好的,让我们创建另一个表,其中将包含变量名或地址的别名。
虽然我们永远无法获得原始变量名,但我们也可以创建自己的。
|
地址 |
变量名/别名 |
变量大小 |
|
0000:0000 |
S1 |
Char |
|
0000:0001 |
S2 |
Char |
|
0000:0002 |
S3 |
Char |
|
0000:0003 |
S4 |
Short int |
您可能对为什么 00000004 存储1而 00000003 不存储感到困惑,这是因为Intel是小端序机器,它以反向字顺序存储值。
现在,接下来我们应该做的是使用我们创建的别名重写上面的代码。
s1 db 2
s2 db 3
s3 db 4
s4 dw 1
mov al, s1
add al, s2
mov ch, s3
mul ch
mov
s4,ax
现在,我们做的第一件事是 mov al, s1。
好的,al 现在包含值为2。接下来我们要做的是“add al, s2”。
现在 al 的值为5。因为 s2 中存储的值是3,接下来我们要做的就是 mov ch, s3?
现在 ch 的值为4。之后我们进行乘法运算 mul ch,现在 ax 的值是 al * ch。
因为 al 的值为5,而 ch 的值为4,所以 ax 的值为20。
好的,我们可以开始解析C++语句,它是:
s1 + s2 * s3
之后,我们看到“mov s4, ax”,所以完整的C++语句是:
S4 = s1 + s2 * s3;
如您所见,我们经过了大量的混乱才得出一个简单的C++语句,而且这只适用于全局变量。不适用于局部变量或结构成员。所以事情只会变得更难。因此,我建议您仔细阅读,如果您不明白什么,就反复阅读,直到明白为止。
2.4. 返回值
C++的一个主要基本原理是从函数调用中返回值。这实际上是一个非常简单的过程,因为它只是涉及到将值放入eax寄存器。
所以,当您有像这样的语句时:
c = (char *) malloc (0xFF);
编译器首先调用 malloc,然后将c赋值给eax,就像“mov c, eax”一样。
例如,如果您有一个返回5的语句,您实际上是在说:
__asm
{
Mov eax, 5
Ret
}
让我们通过一个完整的反汇编转储进行一些练习。
Mov eax,5
Add eax,2
Sub eax,1
Ret
C++等效代码是:
return 5 + 2 – 1;
虽然这很简单,但它是C++反汇编器可以学习的最重要概念之一。
2.5 函数调用和堆栈
现在是时候深入C++的核心了,也就是函数调用。
总的来说,函数调用非常简单,因为它们只是汇编程序员的标签示例。
Int func () {return 1 ;}
Func();
将编译成:
Func:
Mov eax, 1
Ret
Call Func
由此我们可以得出两个结论:第一点是
函数名就像变量一样,它们只是指向某个地址的引用,这与标签相同。
这是一个用于练习的完整反汇编转储。
0000:0000 0
0000:0001 0
0000:0002 0
0000:0003 0
0000:0005 mov eax,1
0000:0009 ret
0000:0010 call 0000:0005 ‘code starts here
0000:0015 mov [0000:0000],eax
好的,我们首先看到在地址 0000:0015 ,我们将一个32位内存地址分配给一个32位寄存器的值,这意味着我们有一个32位变量,或者更确切地说,是一个int类型变量。
所以,让我们为地址 0000:0000 – 0000:0003 创建一个别名,它将是 s1。
现在让我们用这个附加信息创建一个新的反汇编。
S1 dw0
0000:0005 mov eax,1
0000:0009 ret
0000:0010 call 0000:0005 ‘code starts here
0000:0015 mov S1,eax
好的,第二点是代码从 0000:0010 开始,第一个指令是 call 0000:0005。
现在我们到了0000:0015,可以看到代码正在将一个值移入eax然后返回。现在我们位于地址 0000:0015 ,我们刚刚将s1移入了eax。
所以,我们现在可以反编译整个程序到C++。
Int s1 = 0; //dw 0 Int some_function() { return 1; //mov eax ,1 : ret } s1 = some_function(); //mov s1 , eax
那么,当函数有参数时我们该怎么办?嗯,情况变得相当复杂,因为编译器使用堆栈来处理参数。
它按从右到左的顺序推送参数,这意味着最后一个参数先入栈,第一个参数后入栈。
例如,C++函数
Func (1, 2);
将编译成:
Push 2 Push 1 Call func
现在让我们设想一个大小为32的堆栈帧。
第一个我们注意到的是 ESP = 32。考虑到这一点,请看下表。
|
X86指令 |
内存地址存储在 |
堆栈帧指针值 |
|
Push 2 |
[32] |
ESP = 28 |
|
Push 1 |
[28] |
ESP = 24 |
|
Call func |
[24] |
ESP = 20 |
|
Push ebp |
[20] |
ESP = 16 |
请记住,当您在X86机器上发出call指令时,处理器会将当前地址存储在堆栈上,以便知道应该返回到哪个位置。
现在参数已在堆栈上,让我们看看函数本身。
Int func (int a, int b) { return a + b; }
- 编译器做的第一件事是“
Mov eax, [ESP + 8]”,因为ESP等于20,并且第一个参数存储在[28]处。 - 编译器做的第二件事是“
add eax, [esp + 12]”,因为ESP等于20,并且第二个参数存储在32处。 - 编译器做的最后一件事是
ret。
所以完整的编译将是:
Func:
Mov eax, [ESP + 8]
Add eax, [ESP + 12]
Ret
一个非常实用的反汇编技巧是记住,由于堆栈是固定宽度(4字节),您可以轻松地确定他们正在访问哪个参数。
[EBP] = Stack [EBP +4] = Return address [EBP + 8] = First [EBP + 12] = Second [EBP + 16] = Third [EBP + 20] = Fourth
等等……。
2.6 局部变量
我们刚刚了解到参数存储在堆栈上,现在该学习局部变量了,它们也存储在堆栈上,但局部变量的存储方式却大相径庭。
这是一个例子。
Int func ()
{
int a = 5;
return a;
}
好的,要编译这段代码,编译器必须首先在堆栈上预留空间,方法是执行
Sub ESP, 4。因为4字节是 int 变量的大小。当然,编译器必须先备份esp寄存器,它通过“mov ebp,esp”来实现。但是等等,编译器必须先备份 ebp,它通过“push ebp”来实现。所以编译器做的第一件事是:
: Setting up the stack frame
Push ebp; back up ebp
Mov ebp, ESP; back up ESP in ebp
Sub ESP, 4; reverse some space on the stack
注意:C++总是以“设置堆栈帧”的方式编译代码,无论函数是否使用局部变量。编译器总是使用ebp来引用参数和局部变量。
在“函数调用和堆栈”部分,我使用了esp来引用参数,并跳过了设置堆栈帧的代码,以便清晰。
现在,编译器做的第二件事是:
Mov [ebp – 4], 5
Mov eax, [ebp -4]
如果我们还有第二个局部变量,我们可以简单地执行:
Mov [ebp – 8], 5, 当然,编译器会使用 sub ESP, 8 而不是 sub ESP, 4。
编译器做的最后一件事是恢复堆栈帧并返回。
; Cleaning up the stack frame
Mov ESP, ebp; restore stack pointer
Pop ebp; restore ebp
Ret
注意:编译器始终执行“清理堆栈帧”代码,在每个函数中。因此,我们可以通过查找类似的汇编代码来检测一个函数。为了清晰起见,我也在“函数调用和堆栈”部分跳过了这一点。
这是一个用于练习的完整反汇编转储。
0000:0000 0
0000:0004 push ebp
0000:0003 mov ebp,esp
0000:0005 sub esp, 8
0000:0010 mov [ebp -4], 5
0000:0015 add [ebp – 4] , [ebp + 8]
0000:0016 mov eax,[ebp – 4]
0000:0018 mov esp, ebp
0000:0020 pop ebp
0000:0021 ret
0000:0022 push ebp
0000:0023 mov ebp,esp
0000:0025 add [ebp + 8] , [0000:0000]
0000:0030 add [ebp + 8] , [ebp + 12]
0000:0031 mov eax,[ebp +8]
0000:0032 mov esp, ebp
0000:0035 pop ebp
0000:0036 ret
0000:0037 push ebp ;code start
0000:0038 mov esp, ebp
0000:0040 push 1
0000:0044 call 0000:0002
0000:0049 mov [0000:0000],eax
0000:0050 push 4
0000:0051 push 3
0000:0052 call 0000:0022
0000:0056 add [0000:0000],eax
0000:0058 mov esp, ebp
0000:0059 pop ebp
好的,我们首先看到内存地址 [0000:000] 被eax频繁引用,这意味着我们有一个32位变量,它是int类型。接下来我们注意到我们设置了3次堆栈帧并清理了3次,这意味着我们有3个函数(是的,int main(…) 也设置和清理堆栈帧)。
所以我们有:
Func1 () Func2 () Main ()
接下来我们看到 Func1 的地址是 0000:0004 ,并且接受一个32位参数。
因为我们在地址0000:0040处看到将1推送到堆栈,然后在地址 0000:0044 处调用 0000:0004,所以我们可以设置func1声明。
00000:00002 Func1 (int a)
现在,无论func1对[ebp + 8]做什么,我们都知道它正在处理其第一个参数。所以我们查看func1的代码,发现它有一个局部变量,因为它引用了[ebp – 4]。
现在让我们看看地址0000:0049,它是 mov [0000:000], eax 。所以我们知道原始C++代码是这样的:
[0000:0000] = func1 (1);
接下来,我们在地址 0000:0051 看到我们将4推送到堆栈,然后将3推送到堆栈,然后调用 0000:0022。
现在我们可以设置 Func2 的声明。
0000:0022 Func2(int a, int b)
在地址 0000:0056 ,我们看到 add [0000:0000],eax ,意味着原始C++代码是这样的:
[0000:0000] += Func2(3,4)
记住,我们先将4推送到堆栈,然后将3推送到堆栈,因为参数是从右到左传递的。
现在我们有了很多信息,让我们创建一个新的反汇编,其中包含Func1和Func2中所有局部变量和参数的别名。因为我们知道,无论何时他们使用像 [ebp +…] 这样的代码,它都是一个参数,而当他们使用像 [ebp -...] 这样的代码时,它是一个局部变量。
0000:0000 s1 dw 0
0000:0004 func1(int param_1): push ebp
{ local : local_var_1}
0000:0003 mov ebp,esp
0000:0005 sub esp, 8
0000:0010 mov local_var_1, 5
0000:0015 add local_var_1 , param_1
0000:0016 mov eax,local_var_1
0000:0018 mov esp, ebp
0000:0020 pop ebp
0000:0021 ret ;func1 exits here
0000:0022 func2 (int param_1 , int param_2) :
push ebp
0000:0023 mov ebp,esp
0000:0025 add param_1, s1
0000:0030 add param_1, param_2
0000:0031 mov eax,param_1
0000:0032 mov esp, ebp
0000:0035 pop ebp
0000:0036 ret ;func2 exits here
0000:0037 push ebp ;code start
0000:0038 mov esp, ebp
0000:0040 push 1
0000:0044 call func1
0000:0049 mov s1,eax ; s1 = func1(1);
0000:0050 push 4
0000:0051 push 3
0000:0052 call func2
0000:0056 add [0000:0000],eax ; s1 += func2(3,4);
0000:0058 mov esp, ebp
0000:0059 pop ebp
好的,我知道,我编造了一些汇编语法,比如 func1(int param_1) 和
{Local : local_var_1 }
这只是为了清晰起见。
现在让我们从地址 0000:0010 处的func1开始。我们看到它将 local_var_1 移到5,在C++中这意味着:
int local_var_1 = 5;
接下来我们看到 add local_var_1, param_1,在C++中这意味着:
local_var_1 +=param_1
在清理堆栈之前,我们看到的最后一件事是 mov eax,local_var_1,在C++中这意味着:
return local_var_1;
所以完全反编译的函数是:
Int func1(int param1) { int local_var_1 = 5; local_var_1 += param1; return local_var_1;
现在让我们转到地址 0000:0025 处的func2。我们看到 add param_1, s1,在C++中这意味着:
param_1 +=s1;
之后,我们看到 add param_1, param_2,在C++中这意味着:
param_1 += param_2;
在清理堆栈之前,我们看到的最后一件事是 mov eax, param_1,在C++中这意味着:
return param_1;
所以完全反编译的函数是:
Int func2(int param_1 int param_2) { param_1 += s1; param_1 += param_2; return param_1; }
现在我们能够反编译整个程序。
Int s1 = 0; Int func1(int param1) { int local_var_1 = 5; local_var_1 += param1; return local_var_1; } Int func2(int param_1 int param_2) { param_1 += s1; param_1 += param_2; return param_1; } int main() { s1 = func1(1); s1 += func2(3,4); }
本章可能一开始有点难理解,因为我提供了很多“直截了当”的信息。再次,如果您不理解任何内容,请重读。如果您仍然不理解,请发送邮件至 vbmew@hotmail.com 提问。
第三章:C++关键字
3.1 引言
到目前为止我们所做的都是简单的事情,现在是时候处理C++关键字、复杂表达式和一些实际的真实世界示例了。
3.2 If语句
人们使用的主要语句之一就是if语句,它逻辑上比较值。使用此函数,我们可以选择程序的执行路径。
If语句也可以非常、非常复杂,也可以非常简单。
看看下面的例子。
If(I ==0) //do function //continue
现在,如果我们有这样的东西怎么办?
If(I==0) { int i2 = 0; } i2 = 3; //error can’t access i2 because it’s not in your scope // it’s in the if statements scope
因此,我们知道编译器为每个带括号的If语句生成堆栈帧,对吗?错了!。
实际上,I2对main是可访问的,但编译器将其隐藏起来。我之所以告诉您这一点,是因为要反编译if语句,您必须完全理解它们。
第二个例子是:
If( (I ==0) || ( ( I2 == 1) && (i3 ==2) ) )
这里的逻辑是:如果 I = 0 ,或者如果 i2 = 1 并且 i3 = 2。
另一个例子是:
If( (c = (char *) malloc(0xFF) ) == NULL)
这表示 c = malloc(0xFF),并且如果 malloc 返回 NULL,则此条件为真。
再举一个例子:
If(malloc(0xFF)) //this is saying call malloc(0xFF) and if it returns //anything not equal to 0 then This condition is true
最后一个但并非最不重要的例子是:
If(!malloc(0xFF)) //this is saying call malloc(0xFF) and if it returns // value is equal to zero then this condition is true
值得庆幸的是,所有这些if语句都可以反编译回原来的样子(几乎)。
现在,if语句直接映射到X86指令cmp。考虑到这一点,请看看下面的C++程序:
int main() { int I = 0; if(I == 34) i+= 23; return 1; }
它编译成以下内容:
push ebp
mov ebp,esp ;setup the stack frame
sub esp, 4
mov [ebp – 4],0
cmp [ebp – 4], 34 ;
jnz continue_program
add [ebp – 4],23
continue_program:
mov eax,1
mov esp, ebp ;restore the stack frame
pop ebp
ret
是的,我知道我决定给您一个完整的二进制反汇编,看看您是否还记得堆栈帧和[ebp -4],这表示创建的第一个局部变量,而且int main也必须像所有其他函数一样设置堆栈帧。
现在,让我们学习如何将此程序反编译回C++。
我们做的第一件事是查看compare mov [ebp – 4],0,它告诉我们程序正在将变量初始化为0。
接下来,我们看到一个cmp指令,它正在比较[ebp -4]和34。因此,我们知道程序正在使用if语句,您知道“如果[ebp -4] = 34”,我们现在应该做什么?让我们为[ebp -4]创建一些别名,我们将使用local_var_1。然后我们看到指令jnz,它与jne相同,表示如果[ebp -4]或local_var_1不是34,则跳过此if语句并跳转到continue_program。
Add [ebp -4], 34 或 add local_var_1, 34 表示 local_var_1 += 34; 之后,我们“mov eax,1”,清理堆栈帧,然后返回。
现在,让我们寻找多个逻辑if语句。
If( (i==0) || (i2 == 23) &;& (i3 ==21) )
If_block_check1:
Cmp I,0
Jne if_block_check2:
Jmp do_if
If_block_check2:
Cmp i2,23
Jne skip_if
Cmp i3,21
Jne skip_if
Do_if:
; actions here
skip_if:
好的,我们首先看到,在多逻辑if语句中,当一个条件失败时,它会跳转到下一个逻辑表达式,看看它是否为真,如图3.2.1所示。

因此,如果我们有一个多逻辑if语句,并且表达式的一部分成功,我们将继续评估表达式,直到出现一个错误。
当然,这只适用于 &;& 运算符。对于 || 运算符,如果表达式的一部分为真,我们将退出整个表达式,if语句将评估为真。
3.3 For循环
for循环
for循环的有趣之处在于它能够评估3个表达式。
For( <expression 1>; <expression 2>; <expression 3>)
表达式通常是:
For( <assignment>; <conditional>; <increment| decrement>)
反编译for语句并不难,因为它在大多数情况下实际上是一个if语句。
If(I < 4) { i++; //do actions }
现在是for循环的等效代码。
for(int I =0;i<4;i++) { //do actions }
好的,让我们来看一个简单的for循环反汇编。
Mov [ebp – 4],0 ;initilize the local variable
Jmp condition
Increment:
Add [ebp -4],1
Condition:
Cmp [ebp -4],4
Jge done
Loop:
;do actions
Jmp increment
Done:
如您所见,for循环不过是一个高级if语句。我们首先在堆栈上初始化局部变量,然后检查条件语句。然后我们转到循环,最后我们跳回到增量,然后再次跳到条件标签,如此反复,直到条件为真。
3.4 结构
结构在C++中非常有用,因为它们能够包含成员。结构允许您定义任何大小的变量,例如:
Struct test1
{
int member1;
int member2;
};
这将在内存中创建一个64位、8字节的变量。所以,在某种意义上,结构就是常规变量,但允许我们独立地访问该变量的某些部分。
这使得它非常有用。
因为如果您使用char test1[8];,您将在内存中创建与Struct test1完全相同的东西,只是在char test[8];中单独访问4字节成员要困难得多。
这是一个将test1用作局部变量的示例。
Sub ESP, 8 ;reverse 8 bytes on the local stack
Mov [ESP -4], 45 ;move member2 to 45
Mov [ebp -8], 12 ;move member1 to 1
如您所见,结构在内存中是反向存储的,因为您会认为:
成员一应该是堆栈上的最后一个,但事实是它在堆栈上的第一个。
对于全局变量,编译器将简单地在可执行文件中反向查找8个字节,并根据您选择的成员单独引用它们。
3.6 技术算法
我提供了一些算法来证明和帮助您理解本书中提出的一些理论。
下面的示例证明了if块内的变量确实可以被整个函数访问。
#include "stdafx.h" #include "iostream.h" int main(int argc, char* argv[]) { __asm mov dword ptr [ebp -4], 23 if(true) { int i; cout << i << endl; } return 1; }
输出应该是23,即使我们从未初始化I。如果您不清楚,请记住,由于I是第一个也是唯一一个变量,所以它的位置是[ebp -4]。
下一个示例证明了结构只是普通的变量,只是能够被分成部分而不是整体来访问。
#include "stdafx.h" #include "iostream.h" struct test1 { int member1; int member2; int member3; }; int main(int argc, char* argv[]) { test1 local_struct; local_struct.member1 = 1; local_struct.member2 = 1; local_struct.member3 = 1; __asm { add dword ptr [ ebp - 12],55 ; structure 1 add dword ptr [ ebp - 8] , 100 ; structure 2 add dword ptr [ ebp - 4] , 23 ; structure 3 } cout << "member 1: " << local_struct.member1 << endl; cout << "member 2: " << local_struct.member2 << endl; cout << "member 3: " << local_struct.member3 << endl; return 1; }
输出应该是:
member 1: 56 member 2: 101 member 3: 24
第四章:实际反编译
本章旨在提供实际反编译的知识。在本章中,我们将学习如何使用反汇编器,并学习如何反编译真实世界的应用程序。
4.1 Windows反编译入门
Windows反编译并不难,因为所有Windows程序员都遵循严格的编程方法,例如 CreateWindowEx 或 CreateDialog。所有Windows都有消息循环,您可以轻松找到它们。在我们真正开始深入反编译之前,让我们先回顾一下基础知识。在浩瀚的Windows世界中,有许多类型的应用程序,以及更多的技术类型。
因此,所有这些都太多了,无法在一个教程中涵盖。此外,这些信息仅适用于使用基本窗口函数的应用程序,例如 CreateWindowEx 和 CreateDialog。用Visual Basic制作的应用程序或
1. 创建窗口类
从这里我们可以得到窗口过程方法,其中处理所有消息。
lpfnWndProc 的 WNDCLASSEX 结构包含窗口过程方法的地址。
2. 创建窗口本身。
我们可以通过名称检索所有常量,而且大多数时候是精确的C/C++等效代码。
3. 消息
我们所要做的就是寻找对 GetMessage(…) 的引用。
我们先从基本骨架开始,然后处理更复杂的内容。学习基础知识很重要,因为
它们为您提供了应用程序设计理念。我们将使用PVdasm,您可以从我的网站获取 -
这是一个非常好的免费反汇编器,我们将使用它。
4.2 反编译示例应用程序
首先加载PvDasm,您的屏幕应该类似于图4.2.1。

(图4.2.1)
抓取CreateWindow2(我们要手动反编译的程序)并在反汇编器中打开它,您的屏幕应该类似于图4.2.2。

(图4.2.2)
我们看到了入口点,但这是CRTL代码(通用运行时库)。我们如何找到 WinMain 函数?通过引用。我们知道WinMain函数中有 CreateWindowEx 或 RegisterClassEx。如果我们能找到程序调用这些函数的地方,我们就可以开始绘制程序的轮廓。您知道,当您编译程序时,链接器会将其与库或DLL(动态链接库)链接。您从这些
DLL中获得的函数称为导入。PVdasm可以列出程序的所有导入,并显示它们被调用的地址。要使用此功能,请按Ctrl+N或按导入按钮。您的屏幕应该类似于图4.2.3。
- 步骤1. 单击导入按钮或按Ctrl+N
- 步骤2. 您应该看到一个带有导入列表的窗口;向下滚动直到看到
CreateWindowEx。
现在我们必须找到函数的开头。这很容易,如果我们遵循以下规则。
1. 由一个push ebp
mov esp,ebp
sub esp, <;X>
紧随一个
mov esp,ebp
pop ebp
ret <;X>
如果我们向上滚动到地址0040104C,您应该会看到:
0040104C push ebp
0040104D mov ebp, esp
0040104F sub esp, 50h
之后,我们看到:
mov dword ptr ss:[ebp- 30],0000030
mov dword ptr ss:[ebp-2c],0000000003
好的,所以我们知道我们有局部变量,并且它主要看起来像一个结构。要找到 WNDCLASSEX 结构,我们需要一个参照点。一个好的参照点是 LoadCursor。几乎所有应用程序都会调用此函数,因此只需按导入按钮或Ctrl+N,然后选择 LoadCursor。
选择 LoadCursor 后,您应该会看到类似以下内容:
00401092 call ds:LoadCursorA
00401098 mov [ebp-14], eax
好的,我们都知道函数的返回值存储在eax寄存器中,并且我们知道正在使用 WNDCLASSEX 的 hCursor 成员(因为我们正在加载一个光标)。现在 hCursor 在内存中的位置是什么?是ebp-14h(是的,这是14的十六进制,不是十进制),有了这个信息,我们可以找出所有其他成员的位置。如果我们快速看一下 WNDCLASSEX 结构:
typedef struct WNDCLASSEX { UINT cbSize; //30h UINT style; // 2ch WNDPROC lpfnWndProc; //28h int cbClsExtra; //24h int cbWndExtra; //20h HINSTANCE hInstance; //1ch/ HICON hIcon; //18h HCURSOR hCursor; // ebp -14h ß--Start calculation here -> HBRUSH hbrBackground; //ebp -10h LPCSTR lpszMenuName; //ebp – 0ch LPCSTR lpszClassName; //ebp - 8 HICON hIconSm; //ebp -4 };
如您所见,计算结构成员地址很容易。只需将上方每个成员的大小相加,然后减去下方每个成员的大小。现在我们知道了每个结构的内存位置,我们就可以开始真正理解程序是如何创建的了。我们首先要做的是获取结构中所有成员的值,从cbSize成员开始。
1. cbSize
我们看到的第一个是 mov dword ptr ss:[ebp- 30],0000030,我们都知道ebp-30h是 cbSize 的位置。所以我们实际上是在说 mov dword ptr ss:[cbSize],30h。当然,我们可以更进一步,因为我们知道30h是 WNDCLASSEX 的大小,而 cbSize 应该保存 WNDCLASSEX 的大小,所以我们可以将此行完全反编译为:
wc.cbSize = sizeof(WNDCLASSEX);
2. style
mov dword ptr ss:[ebp-2c],0000000003
好的,程序使用了什么样式?嗯,要找出这一点,我们需要查看windows.h并获取所有样式值。现在我们可以手动进行逐位比较,但我们没有时间了,所以我做了一个小型程序WinDasmRef。我们只需要选择我们想查找的部分类型,在我们的例子中是 WNDCLASSEX 的样式,然后输入一个值,然后它就会返回用户输入的精确值。
有关更多信息,请参阅屏幕截图4.2.5。

您可以从 http://www.crackingislife.com/modules.php?name=Downloads&d_op=getit&lid=1 获取此程序。
- 步骤1. 选择一个部分
- 步骤2. 输入一个值
- 步骤3. 它将为您进行逐位比较并找到所有值。
这个程序远未完成,但对于本书来说已经足够了。
3. lpfnWndProc
mov dword ptr ss:[ebp-28],00401000
这是最重要也是最有趣的部分,因为它保存了消息循环的地址。从这里我们可以看出消息循环位于地址00401000(当然是十六进制)。
4. cbClsExtra
mov dword ptr ss:[ebp -24],0
我们只是将 wc.cbClsExtra 设置为0000000。
5. cbWndExtra
mov dword ptr ss:[ebp-20],0000000
我们只是将 wc.cbWndExtra 设置为0。
6. hInstance
mov eax,dword ptr ss:[ebp+8] //局部变量 hInstance
mov dword ptr ss:[ebp-1C],eax //Hinstance
请记住,main函数的声明是:
WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR lpCmdLine , int nCmdShow)
第一个参数(hInstance)存储在 ebp + 8,第二个参数(hPrevInstance)存储在 ebp + 12。
现在eax保存了hinstance的值,我们只是将该值传输到[ebp-1C]或hinstance。所以,换句话说,我们说的是wc.hInstance = hInstance。
7. hIcon
mov dword ptr ss:[ebp-18],00000000
我们只是将 wc.hIcon 设置为0。
8. hCursor
push 00007F00
mov ecx,DWORD ptr SS:[ebp+08]
push ecx
call USER32!LoadCursorA
mov dword ptr ss:[ebp-14],eax
好的,我们首先查看 LoadCursorA 的声明,发现它是:
LoadCursor (HINSTANCE hInstance, LPSTR cursorname);
最后一个参数是先推送的,所以cursorname是第一个被推送的参数,其值为7F00。
如果用户没有使用自定义光标(大多数用户都不使用),我们可以从WinDasmRef中检索其值。是的,您可以在WinDasmRef中输入十六进制值,只需确保输入0x7F00而不是7F00。
参考图4.2.6。

(图4.2.6)
注意:如果您想知道为什么 LoadCursor.cursorname 没有出现在第一张图中,那是因为我写这本书时正在编写这个程序。
mov ecx,DWORD ptr SS:[ebp+08]
push ecx
接下来,我们将ecx移动到SS:[ebp+8],它是 hInstance,然后我们将ecx推送到堆栈。
当前堆栈包含:
- IDC_ARROW
- hInstance
然后我们看到 call USER32!LoadCursorA。我们可以将此还原为完整的原始源代码行:
LoadCursor(hInstance,IDC_ARROW);
现在我们都知道 LoadCursor 在eax寄存器中返回光标的句柄,所以:
mov dword ptr ss:[ebp-14],eax,ebp-14 是hCursor的位置。现在让我们反编译整个语句:
wc.hCursor = LoadCursor(hInstance,IDC_ARROW);
9. hbrBackground
push 01
CALL GDI32!GetStockObject
mov dword ptr ss:[ebp-10],eax
好的,我们首先将01推送到堆栈并调用 GetStockObject。现在,如果我们查看 GetStockObject 的声明,即 GetStockObject(int brush),我们知道01指定了一个画刷,所以我们打开WinDasmRef,输入1,参考图4.2.7获取更多信息。

所以我们知道调用是 GetStockObject(LTGRAY_BRUSH)。之后,我们看到 mov dword ptr ss:[ebp-10],eax,eax保存了 GetStockObject 返回的画刷句柄,而ebp-10是 hbrBackground 的内存位置,所以完整的反编译语句是:
wc.hbrBackground = GetStockObject(LTGRAY_BRUSH);
10. lpszMenuName
mov dword ptr ss:[ebp-0C],0000000
我们只是将 lpszMenuName 设置为0。
11. lpszClassName
mov edx,dword ptr ds:[0040603C]
mov dword ptr ss:[ebp-08],edx
在地址0040603C处,有一个指向类名的指针。我怎么知道?很容易,因为它被方括号包围着,所以它正在从0040603C获取值。我们可以很容易地使用任何十六进制编辑器来查看地址0040603C,只要我们知道映像基址。
映像基址是程序加载到内存中的位置。要查看映像基址,请在PvDasm中按CRTL+P。一个类似于图4.2.8的窗口应该会弹出。
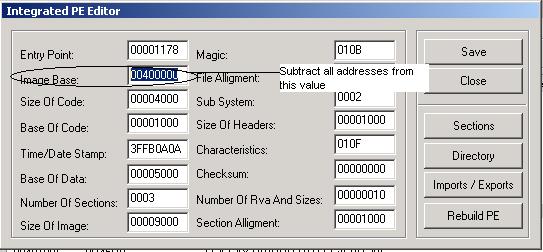
(图4.2.8)
我们从映像基址400000(十六进制)中减去0040603C,得到603C。现在,如果我们到文件偏移量603C处,我们会看到30。我们必须再读3个字节,因为Intel使用32位地址,所以完整地址是30604000。
现在30604000是以小端序存储的,这是X86使用的。我们必须通过反转每个十六进制字节将其转换为大端序,如下所示:00406030。现在,如果我们从中减去映像基址,我们就得到6030。我们在地址6030处看到一个'D'。如果我们继续读取直到遇到空终止符,就像其他人一样,我们会看到DECOMPILE。
现在我们知道了类名,我们可以将该语句完全反编译为:
static char * szClass = “DECOMPILE”;
wc.lpszClassName = szClass; 因为我们正在执行 mov dword ptr ss:[ebp-08],edx,而edx
保存了 szClass 的地址,而ebp-8是 lpszClassName 的内存位置。
12. hIcon
mov dword ptr ss:[ebp-4],0000000
这只是将hIcon设置为0。
现在我们完成了整个窗口类,让我们来概述一下所有值。
WNDCLASSEX wc; //we don’t know the exact name but it has to be something wc.cbSize = sizeof(WNDCLASSEX); wc.style = CS_HREDRAW | CS_VREDRAW; wc.lpfnWndProc = WndProc; wc.cbClsExtra = 0; wc.cbWndExtra =0; wc.hInstance = hInstance; wc.hIcon =0; wc.hCursor = LoadCursor(hInstance,IDC_ARROW); wc.hbrBackground = (HBRUSH) GetStockObject(LTGRAY_BRUSH); wc.lpszMenuName = NULL; wc.lpszClassName = szClass; wc.hIconSm = NULL;
您可以看到我们几乎将它精确地反编译回了源代码。
现在我们看到以下代码:
lea eax,dword ptr ss:[ebp-30]
push eax
call USER32!RegisterClassExA
and eax,0000FFFF
test eax,eax
jnz 004010E4
push 0
push 00406054 ; ASCIIZ Crap
push 0040605C ; ASCIIZ Can’t register class
push 0
Call USER32!MessageBoxA
xor eax,eax
jmp 00401172
让我们先从:
lea eax,dword ptr ss:[ebp-30]
push eax
call USER32!RegisterClassExA
现在ss:[ebp-30]保存了 WNDCLASSEX 结构 的地址,因为[ebp-30]是结构的第一个成员,即cbSize。现在eax保存了结构的地址,我们将其推送到堆栈并调用 USER32!RegisterClassExA; 如果我们查看 RegisterClassEx 的声明,
ATOM WINAPI RegisterClassExA(CONST WNDCLASSEX *);
我们看到它返回ATOM类型,它是16位的。因此,我们看到eax,0000FFFF,它屏蔽掉了高16位,所以我们读到的不是32位值。之后,我们看到:
test eax,eax
jnz 004010E4
这只是说如果eax不为零,则跳转到004010E4。精确的C++代码是:
if(!RegisterClassEx(&;wc))
{
//错误的代码在这里
}
//否则继续 (004010E4
请记住,‘!’表示如果 RegisterClassEx 返回0,则执行错误的代码。现在,当我们继续时,我们看到如果失败,它将显示一个消息框:
push 0
push 00406054 ; ASCIIZ Crap
push 0040605C ; ASCIIZ Can’t register class
push 0
Call USER32!MessageBoxA
如果我们查看 MessageBox 的声明:
MessageBoxA(HWND hWnd , LPCSTR lpText, LPCSTR lpCaption, UINT uType);
- push 0 是为hWnd 参数准备的,它指定我们没有句柄。
- push 00406054; 是ASCII字符串“crap”的地址。
- push 0040605C; 是ASCII字符串“Can’t register class”的地址。
- push 0; 是消息框类型,要查看0的类型,
让我们打开WinDasmRef。
有关更多信息,请参阅图4.2.9。

所以,我们可以将整行反编译为:
MessageBox(NULL,”Can’t register class”,”crap”,MB_OK);
之后,我们看到:
xor eax,eax
jmp 00401172
xor eax,eax 将eax清零为0,如果我们查看地址00401172处的内容,我们会发现:
mov esp,ebp
pop ebp
ret 10
这是退出代码,所以我们可以将此行反编译为 return 0。完整的原始代码是:
if(!RegisterClassEx(&;wc))
{
MessageBox(NULL,"Can't register class","Crap",MB_OK);
return 0;
}
正如您所见,对于这些基本的Windows内容,反编译非常简单,所以我不会再啰嗦了。如果您有任何问题,请查看我们在 http://www.eliteproxy.com/modules.php?name=Forums 的论坛。
更多内容即将推出
Visual basic 6.0 是下一个
贷方
本文由您的捐赠资助。如果您想继续支持Opcodevoid,请捐赠。
免责声明
本书按“原样”提供;不应用或授予任何保证。本书中的内容受Opcodevoid版权保护,所有权利均受尊重。未经Opcodevoid或Opcodevoid Inc.书面许可,不得以任何方式复制、重制或分发本书中的所有信息和算法。