
快速圆坐标映射和色轮创建:第二部分 - 代码
4.68/5 (7投票s)
本文的第 1 部分讨论了一种精确处理圆内所有像素的算法,并可根据需要扩展到填充这些像素以创建色轮;这是第 2 部分,涵盖实际实现。
关于 HSL 的说明
HSL,即色相、饱和度和亮度,是一种指定颜色的系统,它与生成此色轮所使用的逻辑非常相似。主要区别在于颜色分布中的权重。HSL 仅在色轮周围使用 3 个“切片”来表示红色、绿色和蓝色,这可能使得指定彩虹中剩余的四种颜色更加困难,因为在那个系统中,它们在色轮上占据的空间要少得多。
“不要因为我美就恨我”
以下讨论的所有代码都是汇编语言代码。这可能会让许多读者厌恶地摇头。使用汇编语言的原因有两个:首先,它是我的母语。除了极少数特殊情况,我只用汇编编程。这是我所了解的,因此它能最大程度地确保所呈现的代码没有错误。其次,在当今世界,开发者使用的语言如此之多,以至于原生 Intel/AMD 汇编是通用演示的逻辑选择,几乎每个人都可以理解或解读。指令如此直接和简单,内存访问没有晦涩难懂的类型转换和声明,因此使用 ASM(在我看来)是创建每个人都可以接受的通用演示的最佳选择。
本文(第 2 部分)的材料技术含量极高,深入探讨了 SSE 指令的具体行为。如果您在阅读过程中开始感到“公路催眠”,那么建议您只在必要时参考这些材料;当您看到代码中无法立即理解的内容时。
最低要求
此代码所需的 SSE 最低版本是 SSE2。在接下来的代码中,许多时候整数会加载到 XMM 寄存器中,然后转换为 32 位单精度浮点数。任何 Intel 或 AMD 的 64 位处理器都支持 SSE2 指令集,这就是为什么没有使用更先进的 AVX 指令的原因:本文是一个学习工具,我希望所提供的代码具有最广泛的硬件兼容性。
嗯,这真奇怪……
危险,罗宾逊!如果您根据此处显示的示例代码构建实际代码,请为您的色轮使用一个奇数半径值! 否则,创建的色轮会出现许多问题。奇数半径允许在色轮中心有一个像素。此处显示的所有代码都假设半径是一个奇数。
初始数据
我的一个基本原则是尽可能避免内存访问。它们并非免费,在追求性能的编码中(这始终是我的首要任务),内存访问是首先要避免的。这在接下来的代码中得到了体现。尽管内存访问尚未降至绝对零,但它们仍然很少。在可能的情况下,主循环中保持不变的常用浮点值会存储在 XMM 寄存器中,以避免不断重新加载它们。我甚至将运行的 y 坐标存储在 XMM1 中,并且 XMM4 保留一个 1.0 的浮点值,仅用于每次循环递减 y。
除此之外,我一般性地查看哪些值被移动到哪里,并采取措施尽可能减少这种移动。尤其重要的是避免重新计算在每次循环迭代中总是产生相同或可预测结果的值。例如,( r ^ 2 ) 将应用于每个像素的计算。高级代码很可能会编译成每次循环计算该值,因为它不明显地出现冗余。在汇编中,这是显而易见的。
在接下来的代码中,我保留了 XMM0 寄存器来存储 ( r ^ 2 )。它在循环开始前计算一次,之后直到循环完成,该寄存器只会被读取。XMM1 存储当前的 y 坐标,XMM4 初始化为浮点值 1.0。在整个循环生命周期中,XMM4 专门用于递减 XMM1。因此,XMM1 始终存储当前 y 坐标的单精度浮点数(32 位)表示。这些值无需访问内存。变量 SliceSize 存储值 360 / 7,它再次保持不变。在我的代码中,SliceSize 初始化为 51.4285714285714285714285714286。这是另一个每次传递都需要且无需从内存重新加载的值。
下面的代码显示了色轮生成代码中存储在内存中的所有值的数据声明。请注意,为了便于参考,我将常量等式与变量声明混合在一起。这并非我通常的做法,但 ML64.EXE 编译器(与大多数或所有其他 ASM 编译器一样)将接受任何位置(代码或数据)的等式,因此所有声明都集中在一个地方呈现。

上述声明或多或少都是不言自明的。EQU 是一个常量等式。数据类型 REAL4 是一个 4 字节或 32 位单精度浮点值。
FPU 用于通过 FPATAN 指令获取像素的角度,它只从内存中取值(除了少数特殊指令)。BCW_Value 变量用于此目的。
创建位图
以下代码处理保存色轮的位图的创建。

第 7 行显示了第 9 行和第 10 行的 C 等效代码。此部分创建了设备上下文 BCW_dc,这是 CreateDIBSection 函数调用所必需的。
WC 是我自己的 ASM 宏,用于使用 64 位调用约定调用 Windows 函数。传递给任何 Windows API 函数的前四个参数必须分别包含在 RCX、RDX、R8 和 R9 寄存器中。此宏接受可变数量的参数,并根据 64 位约定的要求设置调用。对于除了 ASM 之外的任何其他语言,开发人员无需关心此过程;只需像往常一样调用函数即可。
设备上下文创建后,第 24 行到第 27 行将 BCW_BMI 结构(必须初始化并传递给 CreateDIBSection 函数的 BitmapInfo 结构)清零。第 22 行显示了此函数的 C 等效代码。
第 31 行到第 35 行初始化 BitmapInfo 结构的相关字段。只填充调用所需的字段。常量 CWheel_Width 和 CWheel_Height 对于保存色轮的方形位图是相同的。使用单独的常量名称仅用于澄清,因为这样做对编译后的应用程序的成本为零。请注意,biHeight 字段设置为 -CWheel_Height。 指定负高度会在内存中创建一个自上而下的位图。 这对于处理实际像素写入的代码段至关重要。
第 41 行到第 45 行处理设置所需参数和调用 CreateDIBSection。第 39 行显示了此调用的 C 版本,如果没有错误,第 53 行将位图句柄保存到 CWheel_hBmp 中。
位图创建后,CWheel_pBits 可用于直接向位图写入像素数据。每个像素有一个 DWORD 值。对于整个位图的洪水填充,第 65 行到第 68 行将写入指针 RDI 设置为指向内存的第一个像素,存储计数设置为 CWheel_Width * CWheel_Height(位图中的像素数),寄存器 EAX(寄存器 RAX 的低 32 位)设置为 0xFF000000h,表示完全不透明的 Alpha 和黑色。第 68 行实际填充位图。
主处理循环
下面的代码是生成和处理像素位置“条带”的主循环。它从 (radius – 1) 递增到 1,每次设置 x 的值;x 被传递给处理所有像素(从 -x 到 x)的处理函数。
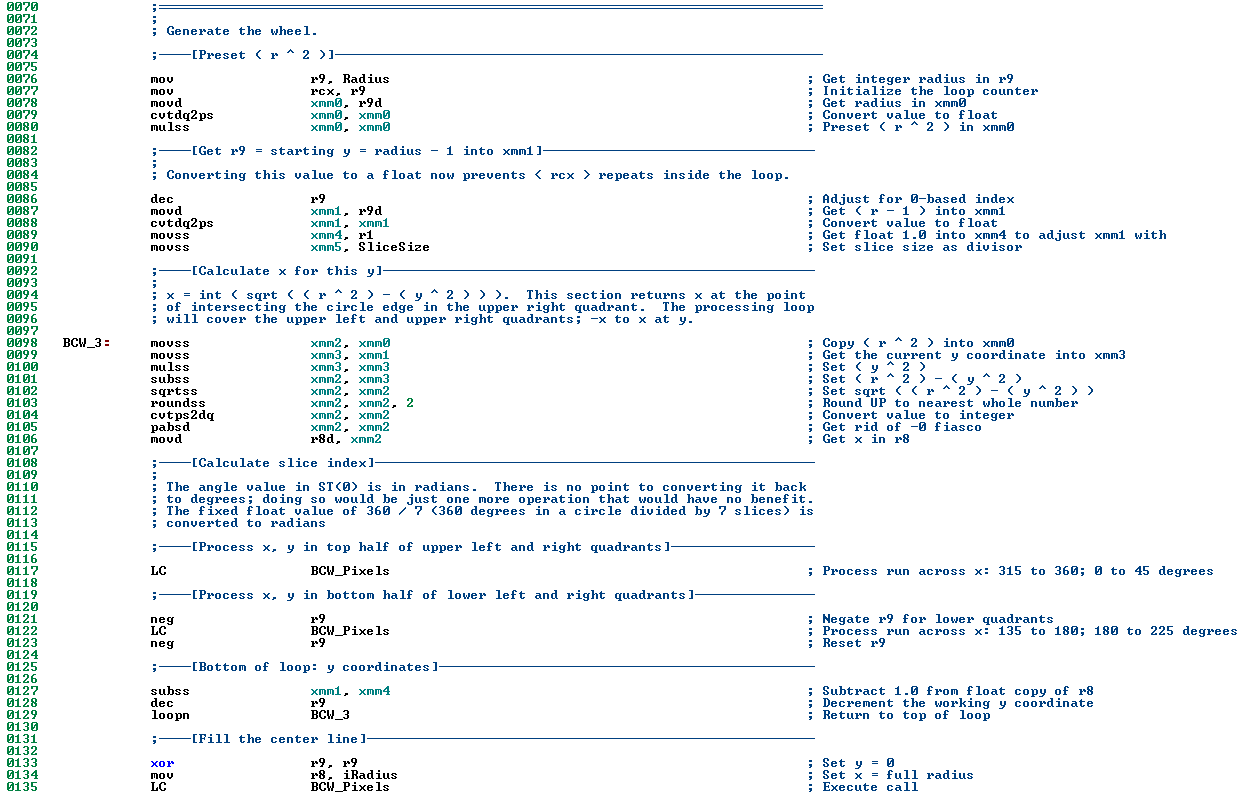
第 77 行初始化循环计数器,用于处理从 (radius – 1) 到 1(含)的 y 坐标。R9 是一个通用寄存器,可以直接或从内存中分配整数值。在这种情况下,已经初始化为圆半径的整数变量 Radius 被放入 R9 寄存器。然后将 R9 复制到 RCX 寄存器中;使循环计数器与 y 的起始值相同。请注意,RCX 是一个基于 1 的循环计数,而不是基于 0 的 y 坐标。ASM 的 LOOP 指令会递减 RCX(这是硬编码行为),如果 RCX > 0,则跳转到循环顶部。很快,R9 将递减(R9--)以作为基于 0 的 y 坐标进入主循环。
第 78 行将 Radius 值从 R9d 寄存器移动到 XMM0 寄存器。R9 是一个 64 位寄存器;R9d 表示 R9 的低 32 位。XMM 寄存器在逻辑上由四个每个 32 位的“插槽”或“部分”组成,因此在从通用寄存器移动时,需要将 32 位值移动到 XMM0 中。
由于 R9 中的值来自整数值 Radius,它仍然以整数形式存储在 XMM0 中,并且在加载到 XMM0 后需要转换为浮点值。这是在第 79 行使用 CVTDQ2PS 指令完成的。此指令中的第二个 XMM0 告诉 CPU 要转换什么;第一个参数(也是 XMM0)告诉它将结果存储在哪里。
第 80 行将 XMM0(第二个参数)与其自身(第一个参数)相乘,并将值存储在第一个参数(XMM0)中。这使得 ( radius ^ 2 ) 存储在 XMM0 中。此值将保留在 XMM0 中,并且在循环的整个生命周期中不会改变。这样做是为了避免在结果永远不会改变的情况下,每次传递都需要重新计算。
到目前为止,R9 一直等于 Radius。第 86 行将该值递减,使其成为基于 0 的 y 坐标。该值随后在第 87 行移入 XMM1,然后在第 88 行转换为单精度浮点值。
第 89 行将浮点值 r1(固定值 1.0)移动到 XMM4。这用于每次循环递减 XMM1。这通过 MOVSS 指令完成,该指令仅从内存中加载 XMM 寄存器的低 32 位(一个标量值)。之后,在第 90 行,值 SliceSize(一个浮点变量,存储 360/7)被加载到 XMM5 中。
所有这些预加载和预计算都只进行一次,在主循环开始之前。一旦进入循环,x 会为每个 y 值计算,并执行 BCW_Pixels 的回调过程。BCW_Pixels 处理程序负责在 -x 和 x 之间循环;它只需要将当前的 x 和 y 作为参数传递。
主循环
如果您想知道标签 BCW_1 和 BCW_2 发生了什么,它们是错误处理的跳转目标,已在此文章中替换为注释。
第 98 行到第 106 行从 XMM1 获取当前 y 坐标的浮点值,从 XMM0 获取 ( radius ^ 2 ) 的值,并使用当前 y 计算圆的右上象限中的 x 坐标。执行公式 x = int ( sqrt ( ( r ^ 2 ) - ( y ^ 2 ) ) ) 来确定当前 y 的 x。当 BCW_Pixels 处理程序接收到 x 和 y 时,它会遍历从 -x 到 x 的每个 x 值。
XMM2 和 XMM3 被用作工作寄存器,因为 XMM0 和 XMM1 在此循环中受到保护——它们的值保持完整和未改变。
请注意第 105 行将 XMM2 的最终值设置为其绝对值。不要在您的代码中跳过此行。SSE 似乎特别喜欢创建 -0 结果。当这个怪异的值转换为通用寄存器中的整数时,它最终存储为 0x80000000,这会破坏正确的计算。
不使用 x 的浮点值。整数值被移动到寄存器 R8d 中。BCW_Pixels 回调要求 x 在 R8 中,y 在 R9 中。只要两个寄存器中的高 32 位都清零,R8 和 R9 中的 64 位值将与它们在 R8d 和 R9d 中的 32 位对应值相同。
将角度放入 XMM2,x 放入 R8d,y 放入 R9d 后,在第 117 行调用 BCW_Pixels 处理从 -x 到 x 的 y 处的像素行。
汇编语言允许调用应用程序中的任何代码。与 WC 宏一样,我的 LC(本地调用)宏只是 CALL 的别名。无需将被调用者格式化为函数。唯一需要记住的注意事项是,如果一段代码要从其所在的同一函数中调用,它不能以 RET 语句返回。编译器会看到这一点并崩溃,试图关闭托管被调用者的函数。它会尝试销毁函数使用的堆栈帧,丢失 RBP(所有局部变量的基指针),如果它编译,应用程序要么崩溃,要么进入高度奇怪的模式。我使用一个名为 LocalRet 的单行宏,它只是一个字节声明 0xC3。这是近程 RET 语句的操作码。
第 121 行到第 123 行对 R9 中的 y 取反,再次调用 BCW_Pixels,然后第二次对 R9 取反以撤消第一次取反。
记住 XMM4 存储浮点值 1.0。第 127 行从 XMM1(运行中的 y 坐标)减去此值,以递减该坐标。R9 中对应的整数 y 坐标也递减。
最初的 8088 将 LOOP 指令目标的距离限制在 255 字节以内(一个短跳转)。如果指定了比这更远的跳转目标,编译器会发出错误,因为它只能在指令中编码 8 位的目标数据作为相对偏移量。由于某种原因,在 Intel 架构最初设计 40 多年后,此限制仍然存在。从未创建合适的替换指令来扩展跳转范围。(这很可能是因为在图坦卡蒙王逝世前后,汇编的使用失宠了。)为了弥补这一点,我使用了名为 LOOPN 的两行宏,它递减 RCX 并在 RCX > 0 时跳转到循环顶部。此宏在第 129 行调用。
该过程以圆的中心线 y = 0 结束,该中心线在循环外部“手动”处理,因为如果半径是奇数,则没有匹配的下象限要处理。
BCW_Pixel 回调
在介绍 BCW_Pixel 回调时,将引用代码段而不是单行。此时应该已经建立了足够多的知识基础,只有以前未见过的指令才需要单独介绍。
图 4 显示了用于处理每次迭代 y 的像素行的 BCW_Pixels 回调。

第 512 行将 RCX 寄存器保存到堆栈中,因为它作为调用者的主循环计数器正在使用。RCX 将在从回调返回之前立即恢复。
RAX 是一个 64 位寄存器;EAX 是 RAX 的低 32 位。Intel 64 位架构在将 32 位值移动到其低 32 位时会自动清除通用寄存器的高 32 位。这种行为有利有弊,但由于它已硬编码到 CPU 中,因此必须加以利用。
第 513 行到第 518 行执行将 R8d 中传入的 x 坐标设置为负值的任务。32 位值的第 31 位移入第 0 位,清除除该位之外的所有位。如果 R8d 为负,则值为 1,否则为 0。然后将该位左移一位,使负的 R8d 为 2,正的为 0。最后,该值递减,使负值为 1,正值为 -1。将 R8d 乘以这个值,负值保持不变,正值变为负值。请记住,32 位值以补码形式存储,因此翻转值的符号不仅仅是简单地切换符号位。
位操作指令是执行周期数最低的指令之一;简单的比较/跳转指令对会清空 CPU 的预取队列并强制其重新填充。
在 R8d 中的 x 坐标强制为负值后,第 525 行将该值符号扩展为 64 位。这对于将 RCX 用作循环计数器至关重要;如果没有此步骤,RCX 最终将存储一个非常大的 64 位值:高 32 位为垃圾,低 32 位为实际计数器。第 526 行将该值取反,使 RCX 成为 R8d 传入值的正计数。在第 527 行将此值左移 1 位,使其值加倍,因为该过程将从 -x 到 x 运行 ( 2x ) 次。
第 534 行是实际处理循环从 -x 到 x 的起点。
第 534 行到第 547 行使用 FPU 获取 0, 0 中心点和当前 x, y 位置之间的角度。第 534 行发出 FINIT 指令仅仅是因为 Intel 文档说应该这样做。FPU 只有 8 个寄存器(ST(0) 到 ST(7)),它们以堆栈形式工作。每次 FLD 或任何其他 FPU 指令将值放入 ST(0) 时,ST(6) 会下推到 ST(7),ST(5) 会下推到 ST(6),依此类推。当其堆栈溢出时,FPU 会开始生成异常,因此如果不对堆栈顶部的值进行特定清除,它就不能无限期地使用。发出 FINIT 是按照规范进行的,而且它比实现对 FPU 堆栈进行持续跟踪以清除垃圾要简单得多。
FPU 只会从其他 FPU 寄存器或内存中加载值。
在第 535 行,x 坐标从 R8d 移到变量 BCW_Value 中,以便 FPU 可以加载它。FILD(在第 536 行)告诉 FPU 加载一个整数值;当 FPU 加载整数值时,转换为浮点值是自动的。然后 y 坐标从 R9d 移到第 537 行的 BCW_Value 中,第 538 行将其加载到 ST(0) 中,将先前加载的 x 坐标从 ST(0) 下移到 ST(1)。
根据 Intel 文档,FPATAN 指令将 ST(1) 除以 ST(0),将结果存储在 ST(1) 中,然后弹出寄存器堆栈,将结果移动到 ST(0)。在第 539 行的 FPATAN 指令之后,第 540 行从 ST(0) 弹出当前像素的角度并将其放入 BCW_Angle。由于该值是通过 FSTP 而不是 FISTP 移动的,它在内存中存储为 32 位浮点数。然后,第 541 行可以将角度作为浮点数加载到 XMM2 中,无需进行转换。
第 542 行必须将 FPU 以弧度返回的角度除以每度弧度计数,将其转换为度数。
第 543 行和第 544 行执行代码中仅有的两对比较/跳转指令之一。在 XMM 寄存器中进行位测试是可能的,但它以一种非常奇怪的方式实现,如果比较为真,则设置 XMM 寄存器中的所有位,否则清除它们。在这种设置下,必须检索和检查值,而且无论如何都别无选择,只能执行条件跳转。第 543 行到第 547 行的目的是将负角度设置为 (360 – angle)。
第 553 行到第 555 行将 SliceIndex 的值设置为 ( 7 * angle ) / 360;这是对计算 angle / ( 360 / 7 ) 的重构。回想一下 XMM5 存储了 360/7 的浮点结果,角度被这个值除。这个过程迂回地计算 angle / ( 360 / 7 ) 的余数。这是必要的,因为 SSE 不会给出余数。第 555 行 ROUNDSS 指令的第三个操作数指定截断;无论其值如何,都丢弃所有小数,并将结果向下舍入到下一个较低的整数。这与 360 % ( 360 / 7 ) 相同。
第 559 行到第 563 行将这个整数(切片索引)乘以某个度数,然后从原始角度中减去该结果,只留下余数。余数用于确定进入目标切片的距离;这将给出最终的颜色。
第 567 行到第 569 行根据 SliceIndex 值定位表格条目。为每个颜色分量(红色、绿色和蓝色)确定从 Table [ index + 1 ] 到 Table [ index ] 的范围。
第 571 行执行一个无价的 SSE 指令:它从表中加载一个整数 DWORD 值,将其分成四个字节,每个字节都放入 XMM7 寄存器的一个“槽”中。这为我们分离了颜色分量,从一个单一的 DWORD(高 8 位是 alpha 通道;它们在计算过程中一并处理)。然后将 XMM7 转换为 float 值。对另一个表格条目(低值)重复此过程,将其移入 XMM6 并转换为浮点值。
使用起始颜色和结束颜色之间的范围;切片百分比乘以这个范围。结果必须加到起始(低)颜色上,才能得到最终的基础颜色。因此,XMM3 在 XMM7 中的起始颜色被修改之前,会得到一份副本。
第 576 行从 XMM6 中的结束值减去 XMM7 中的起始颜色。这给出了目标颜色切片所跨越的红色、绿色和蓝色颜色范围。红色在 XMM6 的第 2 部分,绿色在第 1 部分,蓝色在第 0 部分。
第 577 行:这是我从一个我已经不记得是谁那里学到的一个小技巧。它只在 SHUFPS 指令的源操作数和目标操作数相同时有效,因为寄存器在指令执行时是自修改的。最终效果是将 XMM 寄存器第 0 部分中的标量值复制到该寄存器的所有四个部分。可以将其视为“填充”指令。在第 577 行,最初只存在于 XMM2 第 0 部分的切片百分比被复制到该寄存器的所有四个部分。它需要同时对红色、绿色和蓝色颜色分量进行操作。
完成后,XMM2 中的切片百分比在第 579 行乘以 XMM7 中每个分量的起始到结束范围。结果加到起始颜色上,根据切片上的距离生成红色、绿色和蓝色的最终基础值。
第 587 行到第 594 行计算从当前 x, y 到 0, 0 中心点的距离。
已知基准(距离 0, 0 中心点 [ radius – 1 ])颜色后,第 587 行到第 594 行将颜色向白色偏移。这是通过从中心点到 ( radius – 1 ) 的距离百分比来完成的。此过程遵循与第 567 行到第 579 行相同的方法,只是所有分量的高颜色值始终为 0xFF,无需从表中读取。除此之外,遵循相同的过程。从 0, 0 中心点到 x, y 像素的距离除以 ( radius – 1 ),以给出沿该线的距离百分比。( 1 – 此百分比 ) 是每个分量从基准颜色移动到 0xFF 的量(所有分量都处于纯白色的最大值)。此过程中实现的舍入偶尔会为 ( 1 - % ) 产生负距离;比较/跳转指令对会对此进行调整——如果不存在,应用程序会崩溃,因为它最终会引用输出位图中不存在的位置。
第 624 行到第 630 行设置最终颜色,即向白色移动后的颜色。这是存储在位图中的颜色。颜色分量仍需要组合成一个 DWORD 值;这在设置写入位置之后完成。
不使用 Windows 的 SetPixel 函数,而是直接将像素存储到 x, y 处的位图数据中,速度要快得多。位图中的位置是距离位图数据 ( ( y * bitmap_width * 4 ) + x * 4 ) 字节。
第 634 行到第 643 行计算此位置。但是,由于色轮的 0, 0 中心实际上在位图的中心,需要将位图高度的 ½ 添加到 y,并将位图宽度的 ½ 添加到 x。这些是适用于所有像素的固定偏移值。
第 635 行使用 MOVSXD 指令将 R9d 中的 32 位 y 值移动到 64 位 RAX 寄存器中,同时进行符号扩展。必须假设 R9 的高 32 位包含垃圾;不能假定它们是清除的。这就是为什么使用 MOVSXD 指令而不是直接将 R9 移动到 RAX 的原因。
y 的值从圆坐标系转换为位图相对行索引,然后乘以 <位图宽度> 像素再乘以每像素四个字节。这给出了位图数据到包含目标像素的位图行起点的距离。此值加到 RDI,将其从指向位图中的像素 0 调整到目标行的开头。接下来,将 R8d 移动(再次使用 MOVSXD)到 RAX 中,左移两位,以实现乘以每像素四个字节的效果,然后写入指针再次按此量进行调整。RDI 现在指向实际写入位置。
第 647 行到第 657 行构建最终颜色值并存储在 EAX 中。第 648、650 和 654 行中的 SHUFPS 指令逐步旋转 XMM3,以便每个颜色分量都移入 XMM3 的槽 0。这允许使用 MOVD 指令一次只将一个分量值移动到通用寄存器中。EBX 最初是接收分量值的累加器,然后左移 8 位以接收下一个分量值。由于 EAX 用于最终的 STOSD 指令,因此最后一个颜色分量执行 EAX(其中加载了分量)与 EBX(到那时用作累加器)的逻辑 OR。
此时 RDI 指向写入位置,EAX 包含最终颜色值。最后一步,在第 661 行,设置 EAX 的高 8 位以确保存在完整的 Alpha。第 662 行存储实际像素。
第 666 行递增运行的 x 坐标,然后 LOOPN 宏(前面介绍过)执行跳转到循环顶部,直到 RCX 循环计数器达到零。
第 671 行恢复进入 RCX 的值,该值作为回调的第一要务保存,然后返回给调用者。请记住,LocalRet 只是 <byte 0C3h> 的别名,它是一个 RET 语句。
结论
现在可能已经很明显,使用汇编语言时,开发人员需要承担比其他语言更多的思考和责任,但它在执行速度和可执行文件大小方面会带来巨大的回报。这在游戏编程中尤为如此。您想深入到何种程度是您的选择。如果您的色轮在应用程序执行期间只构建一次,那么如果您使用语言的内置数学处理整个过程,您可能不会注意到性能上的任何显着差异。但是,在经常使用大量数学运算的情况下,额外的时间和精力会带来额外的性能结果。当您认为有必要时,选项始终存在。