
另一个并发表达式求值器
5.00/5 (3投票s)
高性能表达式求值器,
引言
当我最近开始实现一个日志查看器时,我找不到一个完整的、高性能的表达式求值器示例,该示例允许根据用户提供的表达式过滤大量的日志消息。因此,我决定自己编写一个表达式求值器,并将其源代码发布给大家。我选择了 Yacc/Bison 来解析用户表达式,因为我在学校(MIET)学过它。我还选择了 boost::thread,因为它具有可移植性并与 C++0x 标准兼容。
为了编译代码,我使用了
- Visual Studio 2005 Service Pack 1
- Boost 1.39。Windows 安装模块可以从 http://www.boostpro.com/download 下载。在安装过程中,我选择了
boost::thread和boost::regex选项。在 VS 中使用自定义构建规则来构建“.y”文件(请参阅 bison.rules)。
目标和定义
表达式求值器应能够接受用户输入的过滤表达式,并将其应用于可变长度的消息,以确定哪些消息满足过滤条件。每条消息包含相同数量的数字、日期、枚举和字符串类型的字段。我为本文的目的创建了一个自定义的 SQL 消息日志格式。下表解释了格式
| 字段号 | 1 | 2 | 3 | 4 | 5 | 6 |
| 名称 | 时间 | SQL 类型 | ClientSQL | 解析 | Execute | Rows |
| 类型 | 日期 | 枚举 | 字符串 | 字符串 | 数字 | 数字 |
| 大小 | 8 | 2 | (可变) | 8 | 8 | 4 |
用户表达式由一个或多个通过逻辑运算符连接的条件组成。每个条件可以包含字段名以及数字、枚举或字符串常量。
- 示例 1. 查找 Execute 字段大于 1.0 的消息:Execute > 1.0
- 示例 2. 查找类型为 ERROR 的消息:SQLType = ERROR
- 示例 3. 查找 SQL 字段以“
SELECT”开头的消息:SQL ilike '^SELECT(.)+' - 示例 4. 查找执行时间超过 1ms 的 SQL 架构更改:(ClientSQL ilike 'Alter(.)+' || ClientSQL ilike 'Create(.)+' || ClientSQL ilike 'Drop(.)+') && SQLType != ERROR && Execute > 1.0
注意:字符串常量可以包含正则表达式(请参阅 boost::regex 此处)。
演示控制台应用程序通过命令行接受用户表达式以及输入/输出文件名。它可以读取包含任意数量消息的文件,并将过滤后的消息写入输出文件。它还可以生成包含测试消息的二进制日志文件,并将二进制日志文件转换为文本表示。以下是命令行参数
F:\src\yacee>debug\yacee.exe -h
USAGE:
F:\src\yacee\debug\yacee.exe {-f <string>|-g <int>|-p <string>} [-e
<string>] -o <string> [--] [-v] [-h]
Where:
-f <string>, --filter <string>
(OR required) (value required) Filter the log file.
-- OR --
-g <int>, --generate <int>
(OR required) (value required) Generate test log file with the
specified number of messages.
-- OR --
-p <string>, --print <string>
(OR required) (value required) Print content of the log file.
-e <string>, --expression <string>
(value required) Expression to use for filtering the log. The option
should be used with -f option.
-o <string>, --output <string>
(required) (value required) Redirect output to the file.
顺序过滤实现
Yacc/Bison 表达式文法非常简单
exp: NUM { $$ = $1; }
| VAR { $$ = $1->value.var; }
| VAR like STRING { $$ = driver.IsLike($1, $2, $3->c_str()); }
/* note: = and == are the same, i.e. "is equal" operator */
| VAR '=' NUM { $$ = ($1->value.var == $3); }
| VAR "==" NUM { $$ = ($1->value.var == $3); }
| VAR '=' STRING { $$ = 0 == strcmp($1->value.pstr, $3->c_str()); }
| VAR "==" STRING { $$ = 0 == strcmp($1->value.pstr, $3->c_str()); }
| VAR "!=" NUM { $$ = ($1->value.var != $3); }
| VAR "<>" NUM { $$ = ($1->value.var != $3); }
| VAR "!=" STRING { $$ = 0 != strcmp($1->value.pstr, $3->c_str()); }
| VAR "<>" STRING { $$ = 0 != strcmp($1->value.pstr, $3->c_str()); }
| exp "||" exp { $$ = ($1 != 0.0) || ($3 != 0); }
| exp "&&" exp { $$ = ($1 != 0.0) && ($3 != 0); }
| VAR '>' exp { $$ = $1->value.var > $3; }
| VAR '<' exp { $$ = $1->value.var < $3; }
| VAR ">=" exp { $$ = $1->value.var >= $3; }
| VAR "<=" exp { $$ = $1->value.var <= $3; }
| exp '+' exp { $$ = $1 + $3; }
| exp '-' exp { $$ = $1 - $3; }
| exp '*' exp { $$ = $1 * $3; }
| exp '/' exp { $$ = $1 / $3; }
| '(' exp ')' { $$ = $2; }
| '-' exp %prec NEG { $$ = -$2; }
| '!' exp %prec NOT { $$ = !($2); }
;
like: "like" { $$ = 0; } | "ilike" { $$ = 1; } | "not" "like" { $$ = 2; }
| "not" "ilike" { $$ = 3; }
词法扫描器
起初我考虑编写一个词法扫描器并使用 Cygwin 包中的 lexer.exe。但是,由于表达式只能包含少数简单的词法单元,如数字、标识符、算术和逻辑运算符,因此编写一个 C 过程将表达式文本转换为词法单元列表甚至更容易。
词法扫描器的实现可以在 Driver 类的 BuildLexemes() 方法中找到。词法单元存储在 CLexeme 对象的 _lexemes 数组中,声明如下
std::vector<CLexeme> _lexemes;
class CLexeme
{
public:
Parser::token::yytokentype _type;
LexemeVal _val;
CLexeme() : _type(BISLEX_EOF)
{}
CLexeme(Parser::token::yytokentype type, LexemeVal val) : _type(type), _val(val)
{}
CLexeme(Parser::token::yytokentype type) : _type(type)
{
_val.sVal = 0;
}
};
union LexemeVal
{
std::string* sVal;
double dVal;
CVariable* vVal;
};
LexemeVal 存储词法单元的值。sVal 用于字符串字面量;dVal – 用于整数和浮点数;CVariable – 当识别出现有字段名时分配。
过滤循环
顺序过滤器处理 rgMessageOffsets 数组中的输入消息,并将满足表达式的消息存储在 rgFilteredMessages 数组中。以下是 FilterLog 过程中的主要过滤循环
Driver driver;
vector<LONG> rgFilteredMessages;
if (driver.Prepare(filter, "input")) // parse expression
{
for (size_t i=0; i < rgMessageOffsets.size(); i++)
{
SetVariables(logStart + rgMessageOffsets[i]);
if (driver.Evaluate())
{
err = 3; // failed to apply filter
goto Cleanup;
}
if (driver.bisrez != 0.0)
{
rgFilteredMessages.push_back(rgMessageOffsets[i]);
}
}
}
else
{
err = 4; // invalid expression
goto Cleanup;
}
主循环一次获取一条消息,调用 SetVariables 过程将消息中的值复制到过滤器驱动程序缓冲区,调用 Evaluate 方法,如果驱动程序状态‘bisrez’不等于零,则存储消息。下图演示了控制流程
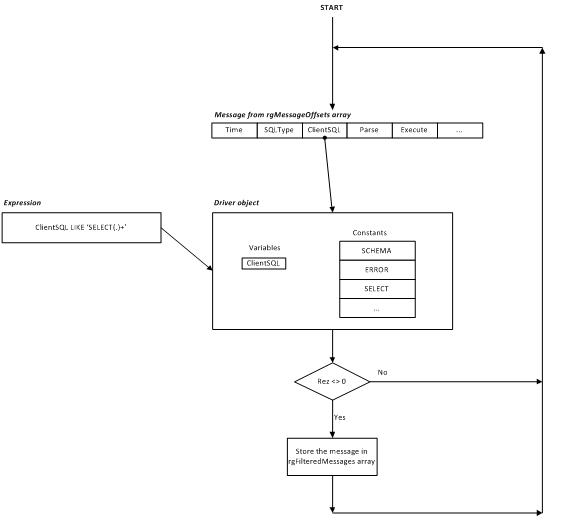
表达式求值由 Driver::Evaluate 中调用的 Parser::parse 方法执行。对于我的应用程序来说,它的性能已经足够好了(请参阅文章末尾的基准测试)。可以通过引入高效的执行计划来优化表达式求值。然而,这超出了本文的范围。
并发过滤实现
我选择了一种简单的并发过滤器设计方法。我使用了每处理器一个线程,并让主线程也参与工作
SYSTEM_INFO systemInfo;
GetSystemInfo(&systemInfo);
if (systemInfo.dwNumberOfProcessors > 1)
{
CDriverThread** threads = (CDriverThread**)_alloca
((systemInfo.dwNumberOfProcessors-1) * sizeof(CDriverThread*));
for (unsigned i=0; i < systemInfo.dwNumberOfProcessors-1; i++)
{
threads[i] = new CDriverThread(logStart, rgMessageOffsets, GetNext, filter);
threads[i]->Go();
}
driverThread.DoWork();
// At this point the main thread had finished filtering,
// but some threads may not have finished yet.
// We have to wait for those threads to finish.
for (unsigned i=0; i < systemInfo.dwNumberOfProcessors-1; i++)
{
threads[i]->Join();
delete threads[i];
}
}
else
{
// This is a single CPU system. Filtering is performed in the current thread.
driverThread.DoWork();
}
所有消息的过滤可以平均分配给线程。但是,一些 CPU 核心可能被其他应用程序使用,这可能导致那些首先完成过滤的线程不必要地等待。为了防止等待,每个线程一次处理少量消息(128 条消息)。回调函数 GetNext 用于获取下一块工作
typedef void (*GetNextFunc)(vector<LONG>** pprgFilteredMessages,
int& startIndex, int& count);
typedef vector<LONG> MessagesArray;
static MessagesArray rgMessageOffsets; // storage for all messages
static boost::mutex mymutex;
static int workStart; // index of next available work
static map<int, MessagesArray*> mapFilteredMessages;
// Callback function a thread uses to obtain next piece of work
void GetNext(vector<LONG>** pprgFilteredMessages, int& startIndex, int& count)
{
MessagesArray* prgFilteredMessages = new MessagesArray();
{
boost::mutex::scoped_lock l(mymutex);
if (workStart < (int)rgMessageOffsets.size())
{
mapFilteredMessages[startIndex = workStart] =
(*pprgFilteredMessages = prgFilteredMessages);
workStart += (count = min(WORK_SIZE,
(int)rgMessageOffsets.size()-startIndex));
return;
}
}
// no work is left
*pprgFilteredMessages = 0;
startIndex = count = 0;
delete prgFilteredMessages;
}
第一个参数 pprgFilteredMessages 用于返回过滤后的消息并组装最终结果。我们希望保留过滤消息的时间顺序。一种可能的选择是将过滤后的消息存储在一个全局数组中并按时间字段排序。这种方法通常用于具有分布式内存体系结构的超级计算机和集群计算机。另一种方法是利用 PC 共享内存体系结构,并填充结果,使其自动排序。这种方法在 GetNext 函数和以下(负责将结果存储在输出文件中)行中实现
// assemble filtered messages from pieceses and write them to the output file
for (int start=0; start < (int)rgMessageOffsets.size(); start += WORK_SIZE)
{
MessagesArray* prgFilteredMessages = mapFilteredMessages[start];
n = (*prgFilteredMessages).size();
for (unsigned i=0; i < n; i++)
{
const BYTE* baseAddr = logStart + (*prgFilteredMessages)[i];
...
WriteFile(hOutFile, baseAddr, msgLen, &numBytes, 0);
}
}

其他
测试日志文件生成和日志文件到文本表示的转换分别在 GenerateLog.cpp 和 PrintLog.cpp 文件中实现。代码相当简单明了。请参阅生成、过滤和打印日志文件的批处理文件。
基准测试和结论
开发和基准测试在以下配置的 PC 上进行
- CPU:Intel Core i7 950 @ 3.07GHz,启用超线程
- 内存:DDR3 6144MB 2138MHz 4-7-7-20
- 主板:ASUS P6T
- 硬盘:Disk_C WD 500GB Black RAID1;Disk_D WD 640GB Black RAID1
下表显示了单线程和多线程表达式求值的性能
| 测试 | 单线程,毫秒 | 多线程,毫秒 | 消息计数 |
| 10p3 | 34 | 8 | 1000 |
| 10p4 | 212 | 42 | 10000 |
| 10p5 | 1400 | 353 | 100000 |
| 10p6 | 13720 | 3305 | 1000000 |
| 10p7 | 失败 | 失败 | 10000000 |
我运行了启用和禁用 Intel 超线程 (HT) 的测试,发现性能相同(这是预料之中的)。
本文描述了一个表达式求值器,可用于过滤日志中的大量消息。该求值器可以轻松扩展以支持更复杂或不同的表达式。附带的源代码可以在 Visual Studio 2005 或更高版本中编译。并行表达式求值可以显著加快过滤速度。性能与系统中 CPU 核心的数量成线性增长。
历史
- 2009 年 12 月。初稿完成