
财务会计应用程序的数据库 III:完成基础设施
设计一个简单而功能齐全的财务会计应用程序数据库。
引言
在上一篇文章中,我们讨论并实现了核心会计基础设施设计:总账、会计科目表、(源)凭证和财务报表结构。
本文将专注于完成会计基础设施设计:公司档案、人员档案、成本中心以及所有在各类专业会计凭证中使用的其他实体。
会计应用程序中的本地化
本地化通常定义为针对特定文化或地区定制应用程序。本地化主要包括用户界面的翻译。然而,在财务会计领域,我们处理的不仅是数字和代码,还有一定数量的文本信息。幸运的是,文本信息的数量非常有限。此外,并非所有文本信息都需要本地化。例如,仅供内部使用的数据(如凭证描述、固定资产、内部注释等)进行本地化没有意义。只有(潜在)对外部可见的信息才需要本地化。
值得注意的是,财务会计有一项法律要求,所有会计记录和凭证都必须以本国语言保存。(我相信这适用于几乎所有司法管辖区)该规则的常见例外是外国人出具的(源)凭证,例如,您不需要翻译一家德国公司出具的发票。这就引出了一个要求,即所有文本数据都应始终以公司注册国的母语存在。财务会计领域的文本数据本地化意味着提供额外的文本数据,翻译成数据所针对人员的母语/可理解语言,即,您需要同时保留国家语言和相关人员所需的语言数据。
考虑到我们应用程序的范围,以下凭证将需要本地化
- 已开具发票
- 已开具形式发票
- 现金收款收据
凭证特有的文本数据及其区域化将由凭证本身处理,即,在扩展凭证表的特定凭证类型的表中。然而,所有凭证都有一个通用数据项——公司数据。因此,公司档案应该是可本地化的,即,应该有
- 一个通用的公司档案,其中包含与语言无关的数据(公司法定名称、各种代码、ID、电子邮件、默认值、策略等)
- 为公司使用的每种语言提供一个本地化的公司档案(地址、联系信息、CEO 职务等)
所有可本地化凭证的另一个通用数据项是人员(档案)。然而,正如您很快就会发现的那样,人员档案中没有可以合理要求本地化的文本数据。官方名称不能翻译。几乎没有人会要求翻译外国公司的原始地址。其余人员数据是关于各种代码、ID 和默认值,这些都不需要翻译。因此,无需为人员档案实现本地化。
实际上,大多数公司使用账单或 CRM 系统来开具发票和收款收据。来自这些系统的数据然后通常通过 REST 服务自动传输到会计系统。在这种情况下,会计系统的本地化根本不需要,因为国际数据由其他应用程序处理,会计人员只需要本国语言的文本数据。然而,我们也针对中小型企业,这些企业至少在一定程度上使用会计系统进行账单处理。因此——本地化。
会计应用程序中的版本控制
理论上,会计人员每次收到(或开出)(源)凭证时,都应该记录下来,并且永远不要更改或删除它。现实生活中,经常会发生拼写错误,会计人员不愿意以正确的方式进行更正,例如开具贷项通知单等调整凭证。这对于中小型企业尤其如此。因此,CRUD 的 U(更新)部分在技术上是非法的,但对于目标用户群来说是必需的。出于同样的原因,会计领域中不存在凭证版本。如果特定公司想要使用详细的审计跟踪,它可以使用额外的解决方案来实现,如本系列第一篇文章中所述(SQL Server 二进制日志、带有序列化凭证的自定义日志等)。我们目标的大多数公司不会想要或需要这样的功能。值得注意的是,法律很少要求详细的审计跟踪。由于我们不针对银行、保险公司和其他高度专业化的行业,因此具有完整 CRUD 功能且没有(广泛)审计跟踪的解决方案对目标群体(中小型公司及其会计)来说是完全可以接受的。
另一方面,会计领域确实需要某种形式的版本控制,尽管不是完全传统的。原因是所使用的关系模型。尽管凭证数据是自足的,提供了特定凭证的完整详细信息。它们确实引用了通用模型对象——人员和公司档案。例如,发票凭证模型不存储完整的公司档案数据和人员(买家)档案数据,只引用通用基础设施表中的数据。然而,任何打印或以其他方式导出的凭证都应包含截至凭证日期相关的原始数据。这可以通过两种方式实现:
- 通过以序列化方式将通用状态存储在凭证本身内(快照),或
- 为所有期间提供不同的通用状态版本
第一种方法在现实世界用例中存在问题。例如,会计人员开具了一张公司发票,后来得知该公司在发票日期时的名称已更改。如果他在通用模型中更改了相关人员数据,更改将不会反映在凭证中,因为它保留了旧的通用状态快照。因此,我们需要提供一种重置快照的方法,或者要求会计人员删除凭证然后重新录入。在这两种情况下,实现都会不直观或/和不方便,这是不好的。
第二种方法完全符合会计人员的期望。如果某些期间的数据发生更改,会计人员可以确信相关期间的所有凭证都会得到更新。因此,我们将使用它。(有关进一步讨论,请参阅如何最好地设计数据库和表来保存更改记录)。
所需版本控制方法是非传统的,因为任何版本都可以由会计人员随时修改(当会计人员得知某些更改时)。概念性的 Winforms GUI 可能看起来像这样(仅用于可视化,字段分布并非如进一步解释的那样合理!!!)

实际版本数据仅在打印或以其他方式导出凭证时才需要。因此,实现需要版本控制的凭证的业务对象将需要一个名为PrepareForPrint或类似的方法来获取(更新)版本化数据。用于此目的的 SQL 查询将像
SELECT * FROM company_profile_versions v WHERE v. effective_date <= [document date]
ORDER BY v.effective_date DESC LIMIT 1.
公司档案版本数据可以缓存,因为数据量很小。人员档案版本数据更具问题。预期人员数量可能高达数万人。如果平均每人添加三个版本,可能会导致内存占用很大。尽管如此,在当前开发阶段,这些实现细节并不特别相关。目前,足以定义每个公司或人员档案都应包含一个版本化数据列表,并指定生效日期。
地址
关于地址有两个问题需要讨论
我们如何构建地址字段?
您可以在网上找到各种地址结构。大多数是特定于国家的,例如,美国邮政服务定义了这些地址字段:街道号码、前缀、街道名称、街道后缀、后缀、次要单元指示符、次要号码、邮箱号码、城市、州、邮政编码、ZIP+4 码。对于会计应用程序,使用特定于国家的地址结构并不是一个特别好的主意,因为很大一部分公司在国外拥有供应商和客户,而这些国家有自己的地址模式。地址结构没有国际标准。在这种情况下,依靠拥有最大数据集的专家来测试想法(即 Google)不是一个坏主意。 Google for Android 使用这些地址字段:标签、街道、邮箱、邻里、城市、地区、邮政编码和国家。这肯定比尝试为立陶宛调整美国地址模式要好。
然而,我们对数据的渴望不应超越我们用户的期望——会计人员。会计人员将无法也无意愿来构建外国地址(自己尝试一下如何构建这样的地址:“65 moo.7 T. Ao-nang, Muang, Krabi (Phi Phi Don), 81210 Phi Phi Don, Thailand”)。因此,我们不能将地址结构化的负担强加给会计人员。它只能作为应用程序母国地址的选项。总而言之,我们应该只提供可选的地址结构化,并且仅限于应用程序母国。就我而言——立陶宛。这就带来了需要一个非结构化地址字段、一个国家以及几个可选的国家特定字段(就我而言——为立陶宛)的需求:市政、城市、街道和房屋号码。如今,另一件可以增强分析的事情是地理坐标。将其集成到 gmaps 中很容易,让会计人员能够验证非结构化地址,或者从地图上选择地址。因此,为什么不添加两个十进制字段用于经度和纬度。
请记住,我们进行地址结构化并非无事可做。结构化地址的价值在于分析。我们肯定不会对公司自己的地址进行任何分析。因此,非结构化地址字段对于公司档案来说已经足够了。
每人需要多少地址?
会计人员感兴趣的地址有两种类型——账单地址和送货地址。实际上,后者通常由 CRM、仓库或账单应用程序处理,对会计而言并不经常感兴趣。
账单地址是发票上客户姓名旁显示的地址。它可以更改,但很少发生。正如我们在版本控制部分所讨论的,它可以方便地通过人员档案的版本来处理。如果账单地址在某个时候发生变化,它应该并且将影响晚于更改日期的发票。例如,如果会计人员开具了一张发票,然后发现账单地址已更改,他可以更新人员档案版本,这将也更新发票账单地址,这正是会计人员所期望的。账单地址是一个法律字段,可能具有一些与税收相关的含义。然而,账单地址上实际上并没有发生什么。因此,其更改(如果发生错误)仍然可以与现实世界的事实相协调。
送货地址是实际运送某些货物或设备的地址。只有当有实物运输时才有意义。它还描述了一个现实世界的事实,即它不仅仅是一个法律字段,如账单地址。因此,它始终是发票事实描述的一部分,并因此存储在发票模式中(有关进一步讨论,请参阅存储送货地址的最佳实践)。当然,会计人员能够从查找中选择送货地址而不是为每张发票手动输入,这很方便。然而,在这种情况下,查找值(地址)仅为默认值。一旦发票被保存,该值就会被复制到发票中,因为它成为一个现实世界的事实(而您不能通过更改档案来更改现实世界的事实)。因此,送货地址不需要版本控制。
公司本身(作为一个法人实体)始终只有一个账单地址。由于这是需要以多种语言呈现的事实,它属于公司区域档案的一个版本。
公司本身可以有多个送货地址,即它可以从不同地点发货。然而,这个概念与库存操作的仓库概念密切相关。因此,我们将在以后关于库存操作的文章中讨论它。
公司档案
为了总结本地化和版本控制的要求,我们将需要总共四张表(实体)来存储公司和人员档案
company_regional_profiles– 用于存储不需要版本控制的本地化公司数据,例如,仅用于预填充凭证字段的默认值。该表每种语言有一行(至少为基础语言有一行)。company_regional_profile_versions– 用于存储需要版本控制的本地化公司数据,例如公司地址company_profile– 用于存储不需要本地化或版本控制的公司数据,例如,仅用于预填充凭证字段的默认值。该表始终只有一行。(附注:作为非版本化字段的国家 ID 是一个糟糕的例子,它可能会改变,尽管非常罕见)company_profile_versions– 用于存储不需要本地化但需要版本控制的公司数据,例如,公司名称、电子邮件、电话号码、CEO 姓名等。
我们还需要另外两个助手实体(表),它们在逻辑上属于公司档案
default_accounts– 正如在上一篇文章中所讨论的,一些业务功能,例如资产负债表展示,需要了解公司用于特定目的的(默认)账户,例如留存收益账户。此类默认账户列表在很大程度上取决于业务层实现,并且可能会发生变化。因此,为每种默认账户类型提供单独的字段不是一个好主意。此外,我们还需要支持应用程序扩展,这些扩展可能需要自己的默认账户。出于这些原因,默认账户类型被定义为枚举,并带有像我们之前为(源)凭证类型所做的那样的扩展点。由于我在本系列第一篇文章中没有预见到默认账户类型可扩展性的需求,我们将现在实现它。company_regional_templates– 本地化对象之一是公司用于其“外部”凭证(例如,发票模板)的模板。特定模板格式取决于应用程序使用的报告引擎。然而,从数据库的角度来看,这并不重要,因为模板始终是一个文件,即 BLOB。额外表的要求是由于数据类型和可扩展性。模板的 BLOB 字段可以添加到company_regional_profile_versions表中,但这种方法会使数据库复杂化。首先,模板的更改频率不如其他本地化数据频繁。每当我们添加一个本地化数据的新版本时,我们都会复制实际上未更改的字段。考虑到company_regional_profile_versions表中的条目不会太多,这对于小字段来说是可以的。但模板可能高达 100-500kB。当公司地址更改时,我们绝对不想复制如此多的数据。使用单独表作为另一个原因是为了可扩展性。很可能某些应用程序扩展会有自己的面向外部用户的凭证,例如特定类型发票,因此需要本地化。由于我在本系列第一篇文章中没有预见到模板类型可扩展性的需求,我们将现在也实现它。
现在,我们可以根据以下公司档案模式(相关部分)总结所有要求以及我对常用档案字段的个人经验

表 company_profile 详细信息
| 字段 | 描述 |
|---|---|
base_country | 公司所在地国家的 ISO 3166 代码。在公司创建后不应更改,因为公司不能自行迁往另一个司法管辖区。它是 country_codes 表的外键,并限制此国家代码的更新和删除。实际上,限制是此字段的主要目的,因为会计应用程序可能支持许多司法管辖区但对可用性有重大影响是不可行的。如果特定 RDBMS 不支持没有主键的表,该字段也可以用作主键。 |
base_currency | 用于会计核算的基础货币的 ISO 4217 代码。在公司创建后不应更改,因为此类更改会将我们带入单个数据库中有两种基础货币的情况。这在计算和支持方面极其困难。在此类罕见场合(例如,引入欧元)的推荐方法是创建一个新的公司数据库,并仅迁移转换后的余额。旧数据库保留用于历史参考。它是 currency_codes 表的外键,并限制此货币代码的更新和删除。 |
base_language | 会计核算所用基础语言的 ISO 639-2 代码。在公司创建后不应更改,因为这本身不会翻译旧的文本数据。在此类罕见场合(我甚至无法想象这种情况)的推荐方法是创建一个新的公司数据库并仅迁移余额。旧数据库保留用于历史参考。 |
establishment_date | 公司成立的日期。显然,不能更改(除非是拼写错误)。 |
default_description_invoice_made, default_description_invoice_received | 发票的默认描述。描述仅用于自动填充描述字段(作为默认值),仅供内部使用。因此,其更改对任何旧发票都没有影响。之所以使用它们而不是单独的默认描述表,是因为在实际用例中,它们是唯一不需要自定义描述的(至少根据我支持会计应用程序的经验)。 |
default_measure_unit_invoice_received | 收到的发票的默认计量单位。它仅用于自动填充计量单位字段(作为默认值),仅供内部使用。因此,其更改对任何旧发票都没有影响。 |
default_sales_vat_schema_id, default_purchases_vat_schema_id | 应用于新发票的默认增值税方案。它们仅作为默认值应用。因此,其更改对任何旧发票都没有影响。增值税方案将在本系列未来的文章中讨论。目前,它们只是供将来使用的参考字段。 |
inserted_at, inserted_by, updated_at, updated_by | 如本系列第一篇文章中所述的标准审计跟踪字段。显然,公司档案是一个根实体。 |
表 company_profile_versions 详细信息
| 字段 | 描述 |
id | 一个合成键。我更喜欢使用它以保持一致性。不过,在这种情况下,effective_date 字段也可以作为主键。 |
effective_date | 档案数据生效的日期。 |
national_id_no, social_security_no, vat_no | 在国家注册机构中标识公司的代码。可能因司法管辖区而异,但在大多数司法管辖区应基本相同。如果您认为它们不会改变,请三思。国家注册改革正在发生。更不用说公司可能被(取消)注册为增值税纳税人多次。显然,这些代码是不可本地化的。 |
company_name | 公司的法定名称。显然,可以更改。不可本地化。 |
ceo_name, accountants_name | CEO 和会计的姓名。显然,可以更改。不可本地化。 |
vat_deduction_percentage | 适用的增值税抵扣百分比。将在未来的文章中详细讨论。目前,这只是一个为将来使用而保留的字段。 |
ceo_signature_facsimile, accountants_signature_facsimile | 在某些司法管辖区,发票可以“签署”CEO 的签名图文(扫描签名)。在立陶宛不再适用,据我所知,在欧盟其他地方也不适用。如果它适用于您的司法管辖区,这是一个放置字段的好地方。即使它们是 BLOB 类型,根据定义,它们的大小也很小(1-5 kB)。因此,复制不会产生显著影响。 |
表 extended_default_account_types 使用与其他类型扩展相同的方法实现(请参阅本系列第一篇文章了解详情)。唯一实质性区别是缺少回退类型。在这种情况下,如果不存在扩展,扩展的默认账户类型就没有意义。因此,如果卸载了扩展,则可以安全地删除扩展拥有的默认账户类型。表字段
| 字段 | 描述 |
id | 由扩展开发人员分配(生成)的扩展类型的 GUID。 |
extension_id | 扩展的 ID,扩展的默认账户类型属于该扩展(指向表 extensions 的外键)。 |
type_name | 扩展的默认账户类型的名称(简短描述)——用于(显而易见的)数据调试目的。 |
表 default_accounts 详细信息
| 字段 | 描述 |
id | 标准的合成键。default_account_type 和 extended_default_account_type_id 的组合也可以用作聚集主键。然而,extended_default_account_type_id 字段可能为 NULL(如果它不是由扩展定义的)。这可能会在某些 RDBMS 中引起问题。因此,我选择标准合成键。 |
default_account_type | 应用程序定义的默认账户类型枚举,由基本应用程序功能处理。它可能会改变。因此,不能使用 ENUM 类型。为了数据完整性(防止非法/不存在的类型),可以使用技术查找表。但我尚未决定。 |
extended_default_account_type_id | 由应用程序扩展定义的默认账户类型(如果默认账户类型属于应用程序扩展)。它是 extended_default_account_types 表的外键,带有 ON DELETE CASCADE 选项。这样,如果扩展被卸载,条目就会自动删除。 |
account_id | 被设置为特定类型默认值的账户。它是账户表的外键,带有 ON DELETE CASCADE 选项。这样,如果账户被删除,条目就会自动删除。 |
现在,我们可以根据以下公司区域档案模式(相关部分)总结所有要求以及我对常用本地化档案字段的个人经验

表 company_regional_profiles 详细信息
| 字段 | 描述 |
id | 区域档案所属语言的 ISO 639-2 代码。至少应有一个公司基础语言的区域档案。 |
default_extra_info_in_invoice | 添加到发票中的默认区域特定文本。该文本仅用于自动填充本地化凭证/发票注释字段(作为默认值)。因此,其更改对任何旧发票都没有影响。 |
default_invoice_measure_units | 已开具发票的默认计量单位。它仅用于自动填充本地化的计量单位字段(作为默认值)。因此,其更改对任何旧发票都没有影响。 |
inserted_at, inserted_by, updated_at, updated_by | 如本系列第一篇文章中所述的标准审计跟踪字段。显然,特定语言的公司区域档案是一个根实体。 |
表 company_regional_profile_versions 详细信息
| 字段 | 描述 |
id | 标准的合成键。我更喜欢使用它以保持一致性。不过,在这种情况下,effective_date 和 regional_profile_id 字段也可以用作聚集主键。 |
regional_profile_id | 版本条目所属区域档案的 ID。 |
effective_date | 档案数据生效的日期。 |
registered_address, office_address | 公司的注册地址和实际地址。注册地址是相关公司注册处的官方地址。实际地址与官方地址不同是很常见的。 |
phone_no, email, contact_details | 用于特定语言凭证的联系方式。虽然电话号码和电子邮件本质上不是本地化的(无法翻译),但通常会显示不同语言的不同联系方式。这些联系人背后有员工,并非所有员工都可能说相关语言。 |
ceo_title | CEO 的职务,例如,总监、总裁、董事长、CEO 等。 |
表 extended_regional_template_types 使用与其他类型扩展相同的方法实现(请参阅本系列第一篇文章了解详情)。唯一实质性区别是缺少回退类型。在这种情况下,如果不存在扩展,扩展的模板类型就没有意义。因此,如果卸载了扩展,其模板可以安全地删除。表字段
| 字段 | 描述 |
id | 由扩展开发人员分配(生成)的扩展类型的 GUID。 |
extension_id | 扩展的 ID,扩展的模板类型属于该扩展(指向表 extensions 的外键)。 |
type_name | 扩展的模板类型的名称(简短描述)——用于(显而易见的)数据调试目的。 |
表 company_regional_templates 详细信息
| 字段 | 描述 |
id | 标准的合成键。regional_profile_id、effective_date、regional_template_type 和 extended_regional_template_type_id 的组合也可以用作聚集主键。然而,如此大的聚集索引看起来并不太吸引人。因此,我选择标准合成键。 |
regional_profile_id | 模板版本条目所属区域档案的 ID。 |
effective_date | 模板生效的日期。 |
regional_template_type | 应用程序定义的模板类型枚举,由基本应用程序功能处理。它可能会改变。因此,不能使用 ENUM 类型。为了数据完整性(防止非法/不存在的类型),可以使用技术查找表。但我尚未决定。 |
extended_regional_template_type_id | 由应用程序扩展定义的模板类型。(如果模板类型属于应用程序扩展)它是 extended_regional_template_types 表的外键,带有 ON DELETE CASCADE 选项。这样,如果扩展被卸载,条目就会自动删除。 |
template_body | 模板文件。 |
现在我们有了完整的公司档案模式,我们可以定义初始化新公司数据库所需的动作序列
- 添加相关扩展的条目,如本系列第一篇文章中所述。
- 向
country_codes表添加公司基础状态的条目。 - 向
currency_codes表添加公司基础货币的条目。 - 向
company_profile表添加非本地化的公司档案条目。 - 向
company_profile_versions表添加非本地化的公司档案初始数据版本的条目。 - 向
company_regional_profiles表添加基础语言的本地化公司档案条目。 - 向
company_regional_profile_versions表添加基础语言本地化公司档案的初始数据版本的条目。
这是最少的必要初始化。当然,您还应考虑使用额外的向导来设置一些典型的财务报表和会计科目表。
人员档案
为了总结本地化、版本控制和地址的要求,我们将需要总共三个表(实体)来存储人员档案
person_profiles– 用于存储不需要版本控制的人员数据,例如,仅用于预填充凭证字段的默认值。person_profile_versions– 用于存储需要版本控制的人员数据,例如,人员姓名、地址等。shipping_addresses- 用于存储人员的送货地址
我们还需要另外两个助手实体(表),它们在逻辑上属于人员档案:person_groups 和 person_group_assignments。要求由典型用例决定——有时会计人员需要根据某些共同的业务特定标准对人员进行分组。人员组是简单的实体——只有一个名称(用于在查找控件中显示)和一个描述。一个人可以被分配到多个组,反之亦然。因此,我们还需要一个标准的许多对多关系表——person_group_assignments。由于这些表很简单,不需要进一步的详细信息。
现在,我们可以根据以下公司区域档案模式(相关部分)总结所有要求以及我对常用本地化档案字段的个人经验
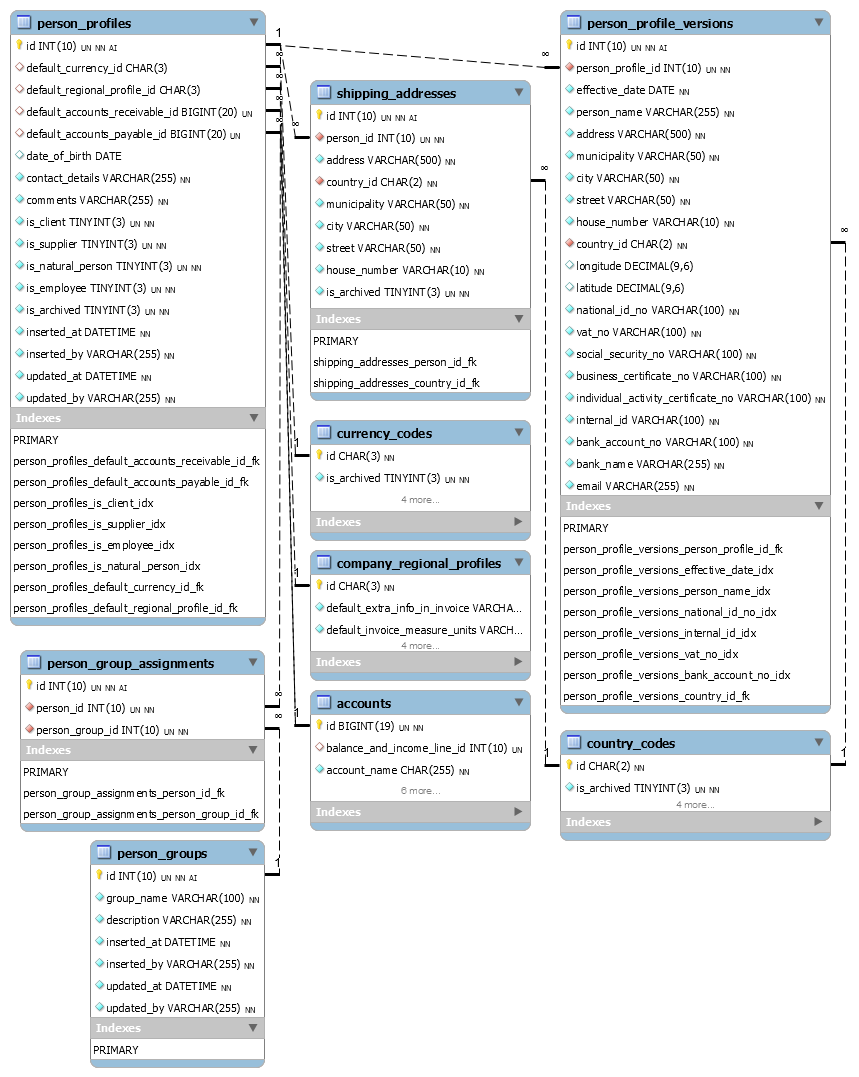
表 person_profiles 详细信息
| 字段 | 描述 |
id | 标准的合成主键。人员没有任何字段甚至字段组合可以作为自然键。 |
default_currency_id | 向该人员开具发票时用作默认值的货币的 ISO 4217 代码。作为默认值,它可以更改而不会对旧发票产生任何影响。它是 currency_codes 表的可空外键,带有 ON DELETE SET NULL 选项,因为 NULL 值可以安全地被视为公司的基本货币,并且在货币未用于凭证的情况下,没有理由阻止删除货币。 |
default_regional_profile_id | 创建某些本地化凭证(例如发票)时用作默认值的人员的公司区域档案(语言)的 ID。作为默认值,它可以更改而不会对旧凭证产生任何影响。它是 company_regional_profiles 表的可空外键,带有 ON DELETE SET NULL 选项,因为 NULL 值可以安全地被视为公司基础语言档案,并且在区域档案未用于凭证的情况下,没有理由阻止删除区域档案。 |
default_accounts_receivable_id, default_accounts_payable_id | 在人员凭证中使用时作为默认账户。作为默认值,它可以更改而不会对旧凭证产生任何影响。它是账户表的可空外键,带有 ON DELETE SET NULL 选项,因为这些值是可选的,并且在账户未用于凭证的情况下,没有理由阻止删除账户。 |
date_of_birth | 自然人的出生日期(如果该人员是自然人并选择使用出生日期而不是其他 ID)。显然,不能更改(除非是拼写错误)。 |
contact_details, comments | 这些字段仅供会计人员内部使用。保留其版本没有好处。 |
is_client, is_natural_person, is_employee, is_supplier | 最常见的人员类别。通常用于过滤查找列表。 |
is_archived | 一个标准字段,用于将人员标记为不再活跃使用,如本系列第一篇文章中所述。 |
inserted_at, inserted_by, updated_at, updated_by | 如本系列第一篇文章中所述的标准审计跟踪字段。显然,人员档案是一个根实体。 |
表 person_profile_versions 详细信息
| 字段 | 描述 |
id | 合成键。我更喜欢使用它以保持一致性。不过,在这种情况下,effective_date 和 person_id 字段也可以用作聚集主键。 |
person_id | 数据版本所属人员(档案)的 ID。 |
effective_date | 档案数据生效的日期。 |
person_name | 人员的姓名。显然,可以更改。 |
address, municipality, city, street, house_number, longitude, latitude | 人员的地址(非结构化和可选的结构化)。显然,可以更改。 |
country_id | 人员居住的国家。不那么明显,但仍然可以更改。例如,如果一家公司成为某个税务管辖区的居民,即使它在该国没有子公司,也被视为该居民。这可以更改。 |
national_id_no, vat_no, social_security_no, business_certificate_no, individual_activity_certificate_no | 在国家注册机构中标识人员(公司)的代码。可能因司法管辖区而异,但在大多数司法管辖区应基本相同。如果您认为它们不会改变,请三思。国家注册改革正在发生。更不用说公司可能被(取消)注册为增值税纳税人多次。显然,这些代码是不可本地化的。 |
internal_id | 公司内部使用的人员 ID,例如某个客户 ID。它通常会显示在发票上。因此,需要版本控制。 |
bank_account_no, bank_name | 人员的银行账户。显然,可以更改。也可以实现为人员银行账户的单独表,以支持每人多个银行账户。然而,我从未被任何会计人员要求过此类功能,并且倾向于保持简单。 |
email | 人员的电子邮件。它可能会显示在发票上。因此,需要版本控制(尽管在这种情况下值得怀疑)。 |
人员档案基础设施中的最后一个表 shipping_addresses 是一个简单的表——只有一个非结构化和可选的结构化地址,加上标准的位标志 is_archived。后者似乎是多余的,因为送货地址应被克隆到发票中。我将其保留只是为了让会计人员能够暂时在查找控件中隐藏它。
在人员档案模式到位后,我们可以通过查询获取有效的档案字段。
SELECT p.id, p.default_currency_id, p.default_regional_profile_id, _
p.default_accounts_receivable_id,
p.default_accounts_payable_id, p.date_of_birth, p.contact_details, p.comments, p.is_client,
p.is_supplier, p.is_natural_person, p.is_employee, p.is_archived,
v.person_name, v.address, v.state_of_residence_id, v.national_id_no, v.vat_no, _
v.social_security_no,
v.business_certificate_no, v.individual_activity_certificate_no, v.internal_id,
v.bank_account_no, v.bank_name, v.email
FROM person_profiles p
LEFT JOIN person_profile_versions v ON v.person_profile_id = p.id AND v.effective_date =
(SELECT MAX(q.effective_date) FROM person_profile_versions q WHERE q.person_profile_id=p.id)
成本中心
成本中心通常定义为企业内部可以将成本分配到的部门。它是管理会计的一部分。(参见维基)我们将以一种更通用、更简单的方式实现成本中心——作为分析的一个额外维度,它并不严格与成本相关。简单地定义一组松散的简单成本中心实体,并提供分组选项,这些选项可以分配给凭证和总账条目,从而能够过滤报表。这种直接的实现将允许会计人员不仅将其用作经典的成本中心,还可以用作项目跟踪器或预算行。
成本中心的模式很简单,几乎不需要进一步的评论。

将人员和成本中心绑定到凭证
正如在系列第二篇文章中已经讨论过的,首先将人员和成本中心添加到总账。我们已经为此目的留下了两个字段。因此,现在完整的模式看起来像这样(相关部分)。

然而,这并不是唯一应该添加人员和成本中心外键的地方。再次,如第二篇文章所讨论的,并非所有凭证都有总账交易(例如,工时表或劳动合同就没有)。此外,一些凭证可能同时通过总账条目相关和不相关的人员(例如,带担保的发票)。因此,我们也应该在凭证级别添加外键引用。即使相关人员可能重叠(并且在大多数情况下会重叠),它也不会破坏规范化,因为引用具有不同的上下文。对凭证的链接肯定比对总账条目的链接更广泛。另一方面,我们无法将与凭证的关系简化为与特定总账条目的关系。这就得出了两个引用都由该领域业务逻辑要求的结论。
显然,一个(源)凭证可能同时具有多个相关的人员和成本中心。这就带来了标准多对多表的需求。因此,凭证与人员和成本中心关系的最终模式看起来像这样(相关部分)。

还应该注意的是,使用该模式的应用程序不应忽略已分配给总账条目的人员和成本中心。这些也应归入凭证关系。否则,按人员(或成本中心)过滤的简单选择也会命中“繁重”的总账条目表。这只是最务实的原因。还有一个理论原因。如上所述,凭证-人员关系与总账条目-人员关系根据领域业务逻辑是不同的。因此,根据领域,通过总账条目和凭证对人员的引用具有不同的业务含义,并且两者都应保留,以便正确描述这两个方面。约定(因为您不能在数据库级别保证它)也对扩展有好处。由于每个扩展凭证都应使用凭证基础设施,因此所有凭证(基础功能和扩展功能)都将通过单个“接口”可用,即,我们可以有一个统一的可过滤的注册表来管理所有凭证。
通用凭证编号模式
在通用凭证接口中实现的最后一个但并非最不重要的有用功能是编号模式。会计人员收到的凭证有它们自己的编号。也就是说,会计人员只是记录了一个事实。然而,公司本身会开出一些凭证。至少对于小型公司来说,这些都是使用会计软件(即我们的应用程序)生成的。因此,应用程序应该能够处理此类凭证的编号。这可能是文化特定的,但据我所知,凭证编号的生成方式如下:
- 存在一个文档序列号,主要由一些字母组成,有时也包含其他字符和数字;也可能是一个空字符串;
- 存在一个基础(运行)编号(整数),根据公司政策重置:从不、每年一次、每月一次或每天一次。
- 存在一个格式化的完整凭证编号,它由:序列号(作为前缀)、凭证日期(或日期的部分,例如仅年份,或者根本不考虑日期)和基础编号组成。
总而言之,使用 .NET 格式字符串(仅用于演示,也可以使用任何其他格式)的凭证编号模板可以通过以下字段进行描述:
- Serial – 用户提供的几乎任何字符串;为了确保合理性,假定最多 20 个字符;
- 编号策略枚举,即重置运行编号:从不、每年一次、每月一次或每天一次;
- 完整编号格式字符串,例如“{0:yyyyMMdd}-{1:D6}”,这对于 2019-12-31 日期且运行编号为 1 的凭证将生成“20191231-000001”,或者“{1}”,对于同一凭证将生成“1”(序列号始终作为前缀,无需包含在格式字符串中)。
- 一个位标志,表示完整编号由外部系统提供,即是否应使用运行编号和格式字符串“计算”完整编号,或者是否允许用户(例如 CRM)手动输入完整编号。
如果您知道不适合该模板的真实用例,请告知。
显然,模板的更改(公司某些类型凭证的编号策略)不能影响已开出的凭证的编号。这就带来了以下选项:
- 如果模板已被凭证使用,则使其变为只读。
- 将模板字段复制到(复杂)凭证编号字段。
- 介于以上选项之间的任何内容。
实际上,我认为所有选项都没有严重的缺点。我的选择基于大多数会计人员如何看待/理解凭证编号概念。他们倾向于将编号模式与序列部分相关联,即,当他们从查找中选择一个序列号时,会计人员(大多数)期望为凭证分配一个有效的(下一个)编号。否则,会计人员不习惯“编号策略”字段,也不习惯看到具有相同序列号的多个“编号策略”,这使得它不直观。为了使编号功能尽可能直观,我选择了以下混合解决方案:
- 模板的序列部分对每种凭证类型都是唯一的,并标识模板(至少从会计人员的角度来看)。
- 模板的序列部分在凭证使用模板后变为只读。
- 模板的其余字段保持可编辑,但其值会被复制到凭证中,即更改不会影响之前的凭证。
有两种方法可以实现此解决方案:直接复制编号策略、外部系统标志和格式字符串到凭证,或者保留一个单独的“编号策略版本”表,其中包含相同的字段,并在策略更改时添加新行。第一个选项将为一百万凭证的数据库增加约 60MB 的额外成本。第二个选项将节省空间,并且(也许?)会更规范化,但会更复杂。由于磁盘空间成本微乎其微,我选择更简单的解决方案——三个字段复制。由此产生的模式将是以下(相关部分)。

表 complex_numbers 的详细信息
| 字段 | 描述 |
document_id | 凭证的 ID。由于我们这里是 0..1 关系,它既是主键也是外键。 |
template_id | 定义编号规则的模板的 ID。 |
reset_policy | 编号策略,即运行编号应重置的期间。从模板复制。 |
format_string | 用于通过凭证日期和运行编号生成完整编号的格式字符串。从模板复制。 |
has_external_provider | 一个位标志,指示完整编号由第三方(例如 CRM)创建和格式化,即不应使用 format_string 和 running_no。从模板复制。 |
running_no | 在重置期间内凭证的运行(序列)编号。 |
full_no | 凭证的完整(格式化)编号。 |
表 complex_number_templates 的详细信息
| 字段 | 描述 |
id | 复杂编号模板的 ID。标准的代理主键。 |
document_type | 模板适用的基础(源)凭证类型。 |
extended_document_type_id | 模板适用的扩展(源)凭证类型。 |
serial | 凭证的序列号,即用户提供的任意字符串(包括空字符串),用于为凭证的完整编号添加前缀。应在 document_type 和 extended_document_type_id 之间唯一。模板用于凭证后不得更改。 |
reset_policy | 编号策略,即运行编号应重置的期间。 |
format_string | 用于通过凭证日期和运行编号生成完整编号的格式字符串。 |
has_external_provider | 一个位标志,指示完整编号由第三方(例如 CRM)创建和格式化,即不应使用 format_string。 |
is_archived | 一个标准位标志,指示模板不再使用,仅作为历史记录保留。(因为用于凭证的模板不能被删除) |
注释 | 会计人员关于模板的注释。仅供内部使用。 |
inserted_at, inserted_by, updated_at, updated_by | 如本系列第一篇文章中所述的标准审计跟踪字段。显然,复杂编号模板是一个根实体。 |
有了架构后,我们可以通过一个 ID 为 123 的任意复杂编号架构,并在 2019-05-26 日期的一个凭证的通用方法中获取下一个编号。
SELECT MAX(c.running_no) + 1 AS NextRunningNo
FROM documents d
LEFT JOIN complex_numbers c ON c.document_id = d.id
WHERE c.template_id = 123 AND (c.reset_policy = 'never' OR
(c.reset_policy = 'day' AND d.document_date = '2019-05-26')
OR
(c.reset_policy = 'month' AND YEAR(d.document_date) = YEAR('2019-05-26')
AND MONTH(d.document_date) = MONTH('2019-05-26'))
OR
(c.reset_policy = 'quarter' AND YEAR(d.document_date) = YEAR('2019-05-26')
AND QUARTER(d.document_date) = QUARTER('2019-05-26'))
OR
(c.reset_policy = 'halfyear' AND YEAR(d.document_date) = YEAR('2019-05-26')
AND ((MONTH(d.document_date) < 7 AND MONTH('2019-05-26') < 7) OR
(MONTH(d.document_date) > 6 AND MONTH('2019-05-26') > 6)))
OR
(c.reset_policy = 'year' AND YEAR(d.document_date) = YEAR('2019-05-26')));
结论
在本文中,我们完成了核心会计基础设施数据库模式的开发:公司档案、人员档案、通用凭证编号策略。
未来的文章将专门介绍(源)凭证的具体类型和会计操作。目前,我还没有决定从哪里开始。
历史
- 2019 年 8 月 18 日:初始版本