
Python 中的 KMeans 和 MeanShift 聚类。
4.00/5 (1投票)
使用 sklearn 和 scipy 进行 KMeans 和 MeanShift 聚类。

引言
本文介绍使用 Python 进行聚类。在本文中,我们将探讨两种不同的聚类方法。第一种是 KMeans 聚类,第二种是 MeanShift 聚类。KMeans 聚类是一种数据挖掘应用,它将 n 个观测值划分为 k 个集群。每个观测值都属于具有最近均值的集群。在 KMeans 聚类中,您可以指定要生成的集群数量,而在 MeanShift 聚类中,集群数量是根据数据中发现的密度中心数量自动检测的。MeanShift 算法将数据点迭代地移向模式,即数据点的最高密度。它也称为模式搜索算法。
背景
可以使用 sklearn.cluster 中的KMeans类实现 KMeans 聚类。KMeans 的一些参数如下所示
n_clusters:要生成聚类和质心的数量。默认为8。n_jobs:要并行运行的作业数量。-1 表示使用所有处理器。默认为None。n_init:算法应使用不同的质心种子运行的次数。默认为10。verbose:如果设置为1,则显示有关估计的信息。
可以使用sklearn.cluster中的MeanShift类实现 MeanShift 聚类。MeanShift 的一些参数如下所示
n_jobs:要并行运行的作业数量。-1表示使用所有处理器。默认为None。bandwidth:要使用的带宽。如果未指定,则使用sklearn.estimate_bandwidth进行估算。verbose:如果设置为1,则显示有关估计的信息。
为了演示聚类,我们可以使用sklearn.cluster包中 iris 数据集提供的样本数据。iris 数据集包含 150 个样本(每种 50 个),这 150 个样本属于 3 种鸢尾花(Setosa、Versicolor 和 Virginica),存储为 150x4 的numpy.ndarray。行表示样本,列表示萼片长度、萼片宽度、花瓣长度和花瓣宽度。
Using the Code
为了实现聚类,我们可以使用 iris 数据集提供的样本数据。
首先,我们将看到 KMeans 聚类的实现。
我们可以按如下方式加载iris数据集
from sklearn import datasets
iris=datasets.load_iris()
然后,我们需要按如下方式提取sepal和petal数据
sepal_data=iris.data[:,:2]
petal_data=iris.data[:,2:4]
然后,我们创建两个KMeans对象并拟合sepal和petal数据,如下所示
from sklearn.cluster import KMeans
km1=KMeans(n_clusters=3,n_jobs=-1)
km1.fit(sepal_data)
km2=KMeans(n_clusters=3,n_jobs=-1)
km2.fit(petal_data)
下一步是确定sepal和petal的质心和标签。
centroids_sepals=km1.cluster_centers_
labels_sepals=km1.labels_
centroids_petals=km2.cluster_centers_
labels_petals=km2.labels_
为了可视化聚类,我们可以创建散点图来表示sepal和petal聚类。
为此,我们首先创建一个figure对象,如下所示
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig=plt.figure()
我们可以创建四个子图来显示二维和三维的sepal数据。子图创建为 2x2 矩阵,第一行表示sepal信息,第二行表示petal信息。每一行的第一列显示二维散点图,第二列显示三维散点图。add_subplot()函数第一个参数的前两位数字表示行数和列数,第三位数字表示当前子图的序列号。第二个(可选)参数表示投影模式。
ax1=fig.add_subplot(221)
ax2=fig.add_subplot(222,projection="3d")
ax3=fig.add_subplot(223)
ax4=fig.add_subplot(224,projection="3d")
要绘制散点图(数据和质心),我们可以使用以下代码
ax1.scatter(sepal_data[:,0],sepal_data[:,1],c=labels_sepals,s=50)
ax1.scatter(centroids_sepals[:,0],centroids_sepals[:,1],c="red",s=100)
ax2.scatter(sepal_data[:,0],sepal_data[:,1],c=labels_sepals,s=50)
ax2.scatter(centroids_sepals[:,0],centroids_sepals[:,1],c="red",s=100)
ax3.scatter(petal_data[:,0],petal_data[:,1],c=labels_petals,s=50)
ax3.scatter(centroids_petals[:,0],centroids_petals[:,1],c="red",s=100)
ax4.scatter(petal_data[:,0],petal_data[:,1],c=labels_petals,s=50)
ax4.scatter(centroids_petals[:,0],centroids_petals[:,1],c="red",s=100)
可以使用iris数据集的feature_names属性设置子图的 x 轴和 y 轴标签,如下所示
ax1.set(xlabel=iris.feature_names[0],ylabel=iris.feature_names[1])
ax2.set(xlabel=iris.feature_names[0],ylabel=iris.feature_names[1])
ax3.set(xlabel=iris.feature_names[2],ylabel=iris.feature_names[3])
ax4.set(xlabel=iris.feature_names[2],ylabel=iris.feature_names[3])
可以使用以下代码将子图的背景颜色设置为绿色
ax1.set_facecolor("green")
ax2.set_facecolor("green")
ax3.set_facecolor("green")
ax4.set_facecolor("green")
最后,我们可以显示图表,如下所示
plt.show()
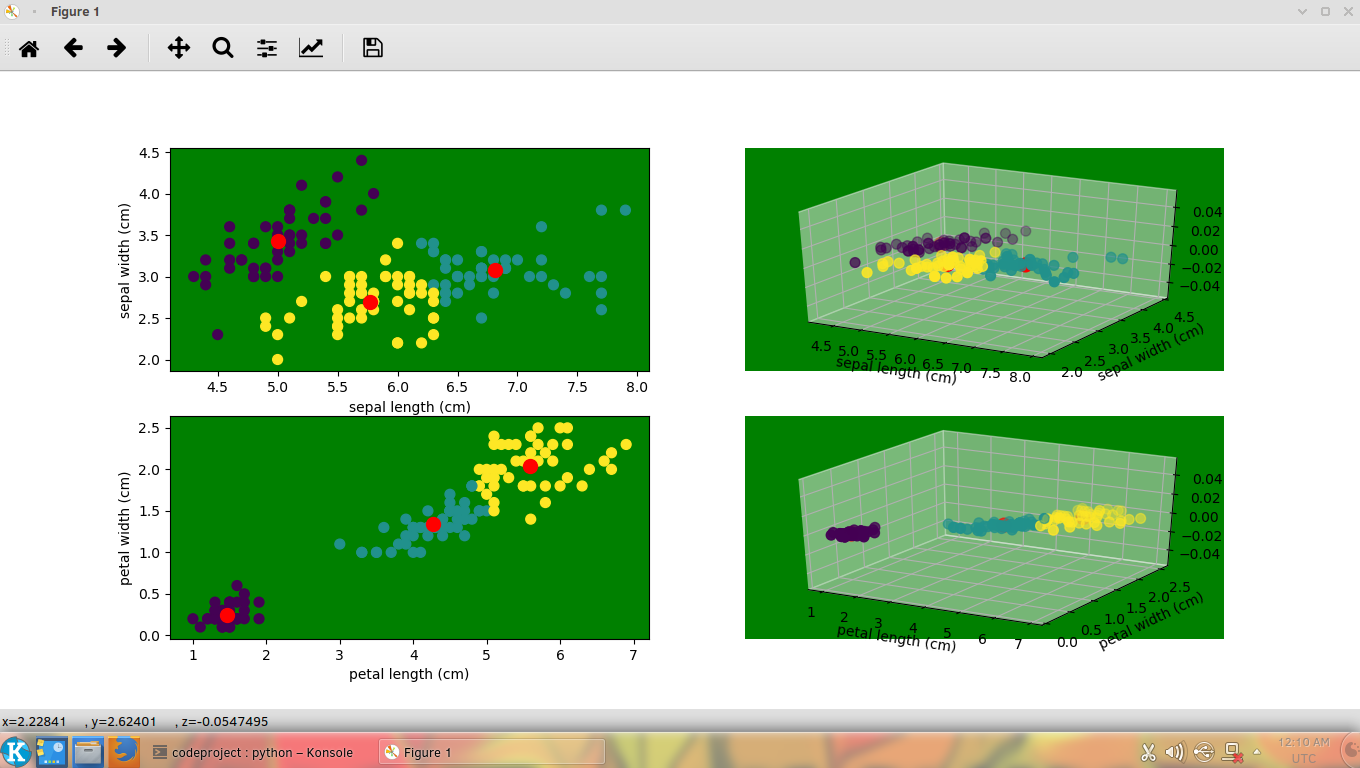
运行以上代码将显示以下输出
以下是MeanShift聚类的实现。
我们创建两个MeanShift对象并拟合sepal和petal数据,如下所示
from sklearn.cluster import MeanShift
ms1=MeanShift(n_jobs=-1).fit(sepal_data)
centroids_sepals=ms1.cluster_centers_
labels_sepals=ms1.labels_
ms2=MeanShift(n_jobs=-1).fit(petal_data)
centroids_petals=ms2.cluster_centers_
labels_petals=ms2.labels_
其他步骤与KMeans聚类相同。以下是MeanShift聚类的输出

请注意,在 MeanShift 聚类中,聚类数量由 MeanShift 算法自动确定。
scipy.cluster.vq模块提供kmeans2函数来实现 kmeans 聚类。但是它要求在聚类之前对数据进行归一化。我们可以使用whiten函数对数据进行归一化。我们可以使用scipy.cluster.vq模块按如下方式实现kmeans聚类
# Clustering using KMeans and Scipy
from sklearn import datasets
from scipy.cluster.vq import kmeans2,whiten
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
iris=datasets.load_iris()
sepal_data=iris.data[:,0:2]
petal_data=iris.data[:,2:4]
sepal_data_w=whiten(sepal_data)
petal_data_w=whiten(petal_data)
centroids_sepals,labels_sepals=kmeans2(k=3,data=sepal_data_w)
centroids_petals,labels_petals=kmeans2(k=3,data=petal_data_w)
fig=plt.figure()
ax1=fig.add_subplot(221)
ax2=fig.add_subplot(222,projection="3d")
ax3=fig.add_subplot(223)
ax4=fig.add_subplot(224,projection="3d")
ax1.scatter(sepal_data_w[:,0],sepal_data_w[:,1],c=labels_sepals,s=50)
ax1.scatter(centroids_sepals[:,0],centroids_sepals[:,1],c="red",s=100)
ax2.scatter(sepal_data_w[:,0],sepal_data_w[:,1],c=labels_sepals,s=50)
ax2.scatter(centroids_sepals[:,0],centroids_sepals[:,1],c="red",s=100)
ax3.scatter(petal_data_w[:,0],petal_data_w[:,1],c=labels_petals,s=50)
ax3.scatter(centroids_petals[:,0],centroids_petals[:,1],c="red",s=100)
ax4.scatter(petal_data_w[:,0],petal_data_w[:,1],c=labels_petals,s=50)
ax4.scatter(centroids_petals[:,0],centroids_petals[:,1],c="red",s=100)
ax1.set(xlabel=iris.feature_names[0],ylabel=iris.feature_names[1])
ax2.set(xlabel=iris.feature_names[0],ylabel=iris.feature_names[1])
ax3.set(xlabel=iris.feature_names[2],ylabel=iris.feature_names[3])
ax4.set(xlabel=iris.feature_names[2],ylabel=iris.feature_names[3])
ax1.set_facecolor("green")
ax2.set_facecolor("green")
ax3.set_facecolor("green")
ax4.set_facecolor("green")
plt.show()
上面的代码产生以下输出

关注点
数据聚类是数据挖掘的一个非常有用的功能,它在数据分类和图像处理领域有很多实际用途。我希望读者能通过本文更好地理解数据聚类的概念。
历史
- 2019年10月28日:初始版本