静态网站中的动态搜索
0/5 (0投票)
为静态 Hugo 网站添加动态搜索功能,通过自定义模板生成 JSON 和 JavaScript 来解析搜索结果。
最初,我将博客从 Medium 迁移到 Hugo 时,我使用了“一键式”解决方案,通过使用 Google 的动态脚本来实现搜索。这在过渡期内有效,但出于几个原因让我感到不舒服。搜索脚本需要动态内容生成,这迫使我通过允许 JavaScript 的 eval 在我的内容安全策略 (CSP - 如果您不熟悉该术语,我将在以后的博文中解释) 中进行一些安全妥协。它还依赖于 Google 对网站的快照,该快照可能已有几天,并且可能遗漏当前结果。最后,它在渐进式 Web 应用程序的离线模式下根本无法工作。
这让我非常困扰,于是我开始寻找其他解决方案。事实证明,这是 Hugo 网站的一个常见问题,并且已经以多种方式得到解决。
本文描述了我的解决方案。
创建搜索数据库
动态搜索静态网站的第一步是找到一种解析搜索数据的方法。这在 Hugo 中并不难。在我的 config.toml 中,我添加了 home 行,允许主页支持其他格式(JSON)。
[outputs] home = ["HTML", "RSS", "JSON"] page = ["HTML", "RSS"]
在 layouts/_default 下,我添加了一个 index.json 模板。此模板会生成包含所有站点内容的 JSON 文件。它使用动态变量(通过 Scratch 关键字)来构建代表页面的对象,然后以 JSON 格式输出结果。
{{- $.Scratch.Add "index" slice -}}
{{- range .Site.RegularPages -}}
{{- $.Scratch.Add "index" (dict "title" .Title "subtitle" .Params.subtitle "description" .Params.description "tags" .Params.tags "image" .Params.image "content" .Plain "permalink" .Permalink) -}}
{{- end -}}
{{- $.Scratch.Get "index" | jsonify -}}
这将生成一个数组,其中包含类似这样的条目
{
"content": "A ton of blah blah here...\n",
"description": "Learn about Jeremy Likness and his 'Developer for Life' blog.",
"image": "/images/jeremymicrosoft.jpg",
"permalink": "http://blog.jeremylikness.com/static/about/",
"subtitle": "Empowering developers to be their best.",
"tags": ["About"],
"title": "About Jeremy Likness and Developer for Life"
}
虽然它“有点大”(几兆字节),但其大小对于在慢速网络上下载或存储和处理内存来说是可以接受的。如果您有兴趣,可以在此处查看搜索 JSON。
新的简码
我通过简码实现了最初的 Google 集成搜索,因此我决定坚持这种方法,并创建另一个用于静态搜索的简码来替换旧的简码。模板在 shortcodes/staticsearch.html 中的样子如下:
{{ partial "_shared/banner.html" . }}
<p id="loading">Loading search data...</p>
<label for="searchBox">Enter your search below to find content on this blog:</label>
<input disabled placeholder="Enter search text" type="text" name="searchBox" id="searchBox" class="w-100"/>
<div id="results"></div>
<script src="{{"/js/search.js" | urlize | relURL }}"></script>
在 static/js 下,我创建了一个 search.js 脚本。这个脚本完成了大部分工作。
使用单独的页面布局进行搜索可能是一个更好的做法,因为它只在一个地方使用。这是我比较懒的做法。
准备索引
我做的第一件事是加载索引。我通过删除非字母数字字符并将所有内容转换为小写以实现标准化,从而提高一致性。正常化器完成了大部分工作。
var normalizer = document.createElement("textarea");
var normalize = function (input) {
normalizer.innerHTML = input;
var inputDecoded = normalizer.value;
return " " + inputDecoded.trim().toLowerCase()
.replace(/[^0-9a-z ]/gi, " ").replace(/\s+/g, " ") + " ";
}
等等,什么?我为什么要创建一个 textarea 元素?既然您问了,答案如下:index.json 数据库包含 HTML 实体代码。例如 « 用于开头的引号, 用于空格。解码它们的最佳方法是将它们放入 textarea 的 innerHTML 中,然后读取其 value。您可以自己试试:它非常有效。之后,任何非字母数字字符都将被替换为空格,以创建可解析的“词云”。(顺便说一句,这种方法的绝妙附带好处是您也可以搜索代码片段……尝试将“showDescription”放入搜索框中)。
$("#searchBox").hide();
var searchHost = {};
$.getJSON("/index.json", function (results) {
searchHost.index = [];
var dup = {};
results.forEach(function (result) {
if (result.tags && !dup[result.permalink]) {
var res = {};
res.showTitle = result.title;
res.showDescription = result.description;
res.title = normalize(result.title);
res.subtitle = normalize(result.subtitle);
res.description = normalize(result.description);
res.content = normalize(result.content);
var newTags_1 = [];
result.tags.forEach(function (tag) {
return newTags_1.push(normalize(tag));
});
res.tags = newTags_1;
res.permalink = result.permalink;
res.image = result.image;
searchHost.index.push(res);
dup[result.permalink] = true;
}
});
$("#loading").hide();
$("#searchBox").show()
.removeAttr("disabled")
.focus();
initSearch();
});
dup 对象包含链接,以避免意外处理重复项。我还检查 tags 的存在,以确保它是我希望包含在搜索索引中的页面。我所有的有效博客文章和站点页面都有相关的标签。
为了显示目的,我保留了原始标题和描述。所有内容都前后填充了空格,以便我可以用空格填充搜索词,从而找到整个单词和短语而不是片段。
响应搜索文本
在加载并标准化索引后,我将搜索输入连接起来以响应按键事件。
var initSearch = function () {
$("#searchBox").keyup(function () {
runSearch();
});
};
runSearch 方法会标准化搜索输入,然后创建一个加权词集。
var runSearch = function () {
if (searching) {
return;
}
var term = normalize($("#searchBox").val()).trim();
if (term.length < minChars) {
$("#results").html('<p>No items found.</p>');
return;
}
searching = true;
$("#results").html('<p>Processing search...</p>');
var terms = term.split(" ");
var termsTree = [];
for (var i = 0; i < terms.length; i += 1) {
for (var j = i; j < terms.length; j += 1) {
var weight = Math.pow(2, j - i);
var str = "";
for (var k = i; k <= j; k += 1) {
str += (terms[k] + " ");
}
var newTerm = str.trim();
if (newTerm.length >= minChars && stopwords.indexOf(newTerm) < 0) {
termsTree.push({
weight: weight,
term: " " + str.trim() + " "
});
}
}
}
search(termsTree);
searching = false;
};
我设置了一个标志,以确保我不会在先前搜索运行时重新进入搜索,而不是“防抖”输入。在测试中,搜索速度比我打字还快,但这在较慢的设备上可能不适用。如果我收到反馈说在某些平台上不起作用,我会重新审视。
算法很简单。如果您输入 I am Borg,会生成一个加权短语集,如下所示:
1: i 1: am 1: borg 2: i am 2: am borg 4: i am borg
我丢弃短词和“停止词”列表中的任何内容(例如 the 这样的词,它们出现得太频繁以至于在搜索中没有意义)。我不介意短语中的停止词。最终的数组如下所示:
1: borg 2: i am 2: am borg 4: i am borg
每个词都用空格填充,因此 too 匹配 too 而不是 tool。然后使用生成的词来搜索索引。
搜索算法
搜索算法根据术语出现的位置分配相对权重。
var search = function (terms) {
var results = [];
searchHost.index.forEach(function (item) {
if (item.tags) {
var weight_1 = 0;
terms.forEach(function (term) {
if (item.title.startsWith(term.term)) {
weight_1 += term.weight * 32;
}
});
weight_1 += checkTerms(terms, 1, item.content);
weight_1 += checkTerms(terms, 2, item.description);
weight_1 += checkTerms(terms, 2, item.subtitle);
item.tags.forEach(function (tag) {
weight_1 += checkTerms(terms, 4, tag);
});
weight_1 += checkTerms(terms, 16, item.title);
if (weight_1) {
results.push({
weight: weight_1,
item: item
});
}
}
});
}
总的来说,每次“命中”大约是
1: content 2: description or subtitle 4: tag 16: title 32: title starts with
每次命中的权重乘以短语权重。该算法高度倾向于标题中的命中,因为如果匹配了短语,则也会加上片段(例如,“I am Borg” = “I am” 和 “am Borg”)的分数。更复杂的算法可以以树状结构存储术语,并在顶点处停止匹配,但此方法在我的测试中似乎能给出我期望的结果,所以我认为没有必要进一步复杂化或调整它。
这是计算目标中命中数的逻辑:
var checkTerms = function (terms, weight, target) {
var weightResult = 0;
terms.forEach(function (term) {
if (~target.indexOf(term.term)) {
var idx = target.indexOf(term.term);
while (~idx) {
weightResult += term.weight * weight;
idx = target.indexOf(term.term, idx + 1);
}
}
});
return weightResult;
};
使用
~是一个简单的技巧。indexOf返回-1表示“未找到”,如果找到则返回一个零基索引。-1的补数是0或falsy,任何0或更高的数都变成负数或truthy。
通过删除符号,我失去了搜索 C# 的能力,但在其他情况下它工作得很好(例如,node.js 变成短语 node js)。如果存在返回无效结果的测试用例,我会重新审视算法,但目前它似乎有效。如果您遇到问题,请随时使用本文末尾的评论表单提供反馈。
返回结果
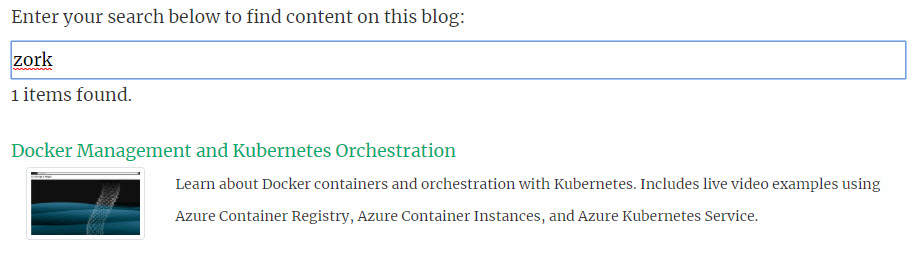
困难的部分(搜索)已经完成。现在我只需按降序权重对数组进行排序并渲染各个部分。我在每个页面的 front matter 元数据中存储图像,因此很容易提取 URL 以在结果中显示缩略图。
var render = function (results) {
results.sort(function (a, b) { return b.weight - a.weight; });
for (var i = 0; i < results.length && i < limit; i += 1) {
var result = results[i].item;
var resultPane = "<div class=\"container\">" +
("<div class=\"row\"><a href=\"" + result.permalink + "\" ") +
("alt=\"" + result.showTitle + "\">" + result.showTitle + "</a>" +
"</div>") +
"<div class=\"row\"><div class=\"float-left col-2\">" +
("<img src=\"" + result.image + "\" alt=\"" + result.showTitle + "\" class=\"rounded img-thumbnail\">") +
"</div>" +
("<div class=\"col-10\"><small>" + result.showDescription + "</small></div>") +
"</div></div>";
$("#results").append(resultPane);
}
};
摘要
搜索完全包含在几个文件中,特别是 /static/search URL、/index.json 数据库和 /js/search.js 逻辑。这些文件都可以缓存,因此搜索完全可以在离线模式下使用(我很快就会发布有关创建渐进式 Web 应用程序的步骤的博文)。您可以在此处查看最新源代码。
数据库在每次重新发布网站时都会更新,因此它始终是最新的(略有延迟,取决于网站本身的缓存)。
您对算法和/或代码有任何反馈或改进吗?您是否以不同的方式解决了这个问题?在下面的评论中分享您的想法!
此致,