
在 Windows 中处理 UTF-8
4.87/5 (17投票s)
这是(又一篇!)关于如何在仍然鼓励使用 UTF-16 编码的平台上处理 UTF-8 编码的文章。
背景
让我重申一下上面提到的宣言中的一些观点
- UTF-16(也称为 Unicode、widechar 或 UCS-2)早在 20 世纪 90 年代初就已推出,当时人们认为其 65000 个字符足以满足所有字符的需求,
- 除特殊情况外,UTF-16 的效率或易用性并不比 UTF-8 高。事实上,在许多情况下,情况恰恰相反。
- 在 UTF-16 中,字符也具有可变宽度编码(两个或四个字节),并且计算字符数量与 UTF-8 一样困难。
如果您想在 Windows 中使用 UTF-8 编码(并且您应该这样做),并且不想发疯或让程序意外崩溃,您必须遵循以下规则
- 编译程序时定义
_UNICODE(或在 Visual Studio 中选择使用 Unicode 字符集)。 - 仅在 API 函数调用的参数中使用
wchar_t或std::wstring。其他地方请使用char或std::string。 - 使用
widen()和narrow()函数在 UTF-8 和 UTF-16 之间进行转换。
此程序包中提供的函数将使您的工作更加轻松。
调用库函数
所有函数都位于 utf8 命名空间中,我建议您不要为此命名空间使用 using 指令。这是因为许多/大多数函数与传统的 C 函数同名。例如,如果您有一个函数调用
mkdir (folder_name);
并且您想开始使用 UTF-8 字符,您只需将其更改为
utf8::mkdir (folder_name);
在函数前加上命名空间可以清楚地表明您正在使用哪个函数。
基本转换函数
遵循相同的宣言,基本转换函数是 narrow()(从 UTF-16 到 UTF-8)和 widen()(反之)。它们的签名如下:
std::string narrow (const wchar_t* s);
std::string narrow (const std::wstring& s);
std::wstring widen (const char* s);
std::wstring widen (const std::string& s);
此外,还有两个函数用于与 UTF-32 进行相互转换
std::string narrow (const std::u32string& s);
std::u32string runes (const std::string& s);
内部转换是通过 WideCharToMultiByte 和 MultiByteToWideChar 函数完成的。
还有用于计算 UTF-8 字符串中的字符数(length())、检查 string 是否有效(valid())以及将指针/迭代器移到字符字符串中的下一个字符(next())的函数。
包装器
几乎所有其他函数都是对传统 C/C++ 函数或结构的封装。
- 目录操作函数:
mkdir、rmdir、chdir、getcwd - 文件操作:
fopen、chmod、access、rename、remove - 流:
ifstream、ofstream、fstream - 路径操作函数:
splitpath和makepath - 环境变量访问函数
putenv和getenv - 字符分类函数
is...(isalnum、isdigit、isalpha等)
所有这些函数的参数都模仿了标准参数。但是,对于某些函数,例如 access、rename 等,返回类型是 bool,其中 true 表示成功,false 表示失败。这与返回 0 表示成功的标准 C 函数相反。请注意!
返回值
对于返回字符的 API 函数,您需要设置一个 wchar_t 缓冲区来接收值,使用 narrow 函数将其转换为 UTF-8,并最终释放缓冲区。以下是一个示例,说明这将如何显示。代码检索临时文件名。
wstring wpath (_MAX_PATH, L'\0');
wstring wfname (_MAX_PATH, L'\0');
GetTempPath (wpath.size (), const_cast<wchar_t*>(wpath.data ()));
GetTempFileName (wpath.c_str(), L"ABC", 1, const_cast<wchar_t*>(wfname.data ()));
string result = narrow(wfname);
这似乎过于繁琐且容易出错,所以我创建了一个用于保存返回值的对象。它具有转换为 wchar_t 缓冲区,然后转换为 UTF-8 字符串的运算符。由于缺乏更好的名称,我称之为 buffer。使用此对象,相同的代码片段变成:
utf8::buffer path (_MAX_PATH);
utf8::buffer fname (_MAX_PATH);
GetTempPath (path.size (), path);
GetTempFileName (path, L"ABC", 1, fname);
string result = fname;
内部,buffer 对象包含 UTF-16 字符,但 string 转换运算符会调用 utf8::narrow 函数将 string 转换为 UTF-8。
程序参数
有两个函数用于访问和转换 UTF-16 编码的程序参数:get_argv 函数返回一个类似 argv 的指向命令行参数的指针数组。
int argc;
char **argv = utf8::get_argv (&argc);
第二个函数直接提供一个 string 向量。
std::vector<std::string> argv = utf8::argv ();
使用第一个函数时,必须调用 utf8::free_argv 函数来释放为 argv 数组分配的内存。
意外转折 #
C++20 标准添加了一个额外的类型 char8_t,用于保存 UTF-8 编码的字符,以及一个 string 类型 std::u8string。通过将其与 char 和 unsigned char 区分开来,委员会也造成了许多不兼容性。例如,以下片段将产生错误:
std::string s {"English text"}; //this is ok
s = {u8"日本語テキスト"}; //"Japanese text" - error
您必须将其更改为类似以下内容:
std::u8string s {u8"English text"};
s = {u8"日本語テキスト"};
依我看,委员会引入 char8_t 类型违背了 UTF-8 编码的初衷。该编码的目的是将 char 类型的用法扩展到额外的 Unicode 代码点。它取得了巨大成功,已成为互联网上事实上的标准。即使是 UTF-16 编码的坚定支持者 Windows,现在也在缓慢转向 UTF-8。
在此背景下,char 数据类型除了用于保存 string 的编码之外,似乎不合适。特别是,使用 char 或 unsigned char 进行算术计算只是使用场景的一小部分。标准应该尝试简化最常见用例的使用,而将不常见的用例承担复杂性的负担。
遵循这一原则,您将希望编写
std::string s {"English text"};
s += " and ";
s += "日本語テキスト";
并隐含假设所有 char string 都是 UTF-8 编码的字符 string。
最近(2022 年 6 月),委员会似乎改变了立场,并引入了一个兼容性和可移植性修复 - DR2513R3,允许使用 UTF-8 字符串字面量初始化 char 或 unsigned char 的数组。在缺陷报告进入下一个标准版本之前,Visual C++ 用户在 C++20 标准规则下编译的解决方案是使用/Zc:char8_t- 编译器选项。
双重保险 #
从 Windows 版本 1903(2019 年 3 月更新)开始,Microsoft 允许您将 UTF-8 设置为系统 ANSI 代码页(ACP)。这允许您使用 API 函数的 -A 版本而不是 -W 版本。该设置深埋在三级对话框中。
转到设置 > 时间和语言 > 语言和区域,然后选择区域设置

在下一个对话框中,选择更改系统区域设置
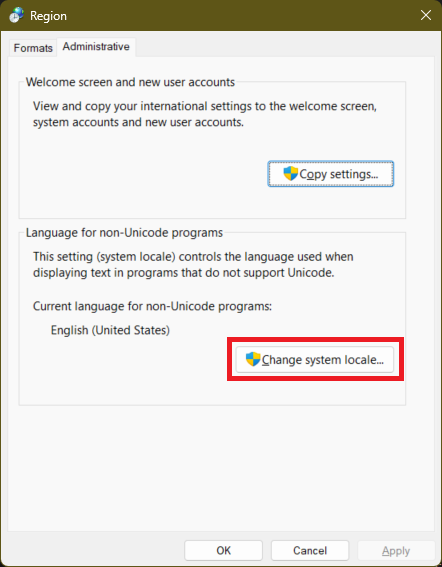
最后,勾选Beta 版:对全球语言支持使用 Unicode UTF-8复选框。

更多信息可以在这里找到:在 Windows 应用中使用 UTF-8 代码页
“有什么好处?”您可能会问。“您之前说过我应该定义 _UNICODE 来确保只调用 -W API 函数。”是的,这对于 Windows API 函数是正确的,但对于 C 函数,没有 -A 和 -W 变体。如果您像下面的程序一样调用 fopen:
int main()
{
const char* greeting = u8"Γειά σου Κόσμε!\n"; //Hello world
const char* filename = u8"όνομααρχείου.txt";
FILE* f = fopen(filename, "w");
fprintf(f, greeting);
fclose(f);
return 0;
}
您可能不会注意到您调用了 fopen 函数而不是 utf8::fopen。在默认 ANSI 代码页(通常是 1252)的 Windows 机器上运行此程序将产生以下结果:

但是,如果 Windows 设置为使用 UTF-8 ACP,即使调用标准 fopen 也能生成正确的文件名:

此外,所有输出到 std::cout 的内容都将正确格式化为 UTF-8 文本。
明智之举:您应该使用 GetACP 函数检查 Windows 是否设置为使用 UTF-8 代码页。
if (GetACP() != 65001)
std::cout << "Warning! not using UTF-8 ANSI code page\n";
否则,如果您的开发机器设置为使用 UTF-8 ANSI 代码页,您将面临应用程序被认证为 “在我机器上可用” 的风险。
结论
我希望这篇文章以及随附的代码能表明,在 Windows 程序中使用 UTF-8 编码并不一定非常痛苦。
本系列的下一章是:
- Tolower or not to Lower(转小写还是不转小写)展示了如何在 UTF-8 中解决大小写转换问题。
- INI 文件展示了在 Windows INI 文件中使用 UTF-8 的 Windows API 实现。
历史
- 2023 年 10 月 9 日 - 添加了关于 C++20 和设置 ACP 的部分。
- 2020 年 8 月 2 日 - 链接到系列中的其他文章,代码已更新。
- 2019 年 11 月 22 日 - 初始版本。