
使用 Apache Spark for .NET 进行大数据分析
4.82/5 (3投票s)
本文将为您提供一个关于使用 Apache Spark for .NET 进行大数据分析的初步介绍和快速入门指南。
引言
大数据并非一时潮流。事实上,我们正生活在一场影响地球上每个行业、每个企业和每个人生活的革命的边缘。随着每秒钟生成数百万条推文、iMessage、直播、Facebook 和 Instagram 帖子……产生 TB 甚至 PB 级别的数据,从这些数据中获得“有意义的洞察”是一项巨大的挑战,因为传统的数据库和数据仓库无法满足这些需要频繁更新或实时更新的大数据集的处理需求,例如股票、应用程序性能监控或用户在线活动等场景。为了应对大数据分析工具和技术日益增长的需求,许多组织转向了NoSQL 数据库和Hadoop,以及一些配套的分析工具,包括但不限于YARN、MapReduce、Spark、Hive、Kafka 等。
所有这些工具和框架构成了一个庞大的大数据生态系统,无法在一篇文章中全部涵盖。本文的重点是为您初步介绍 Apache Spark,最重要的是,介绍 .NET 库 for Apache Spark,它将 Apache Spark 工具带入了 .NET 生态系统。
我们将涵盖以下主题
- 什么是 Apache Spark?
- Apache Spark for .NET
- 架构
- 在 Windows 上配置和测试 Apache Spark
- 编写并执行您的第一个 Apache Spark 程序
什么是 Apache Spark?
Apache Spark 是一个通用的、快速的、可扩展的分析引擎,它以分布式方式处理大规模数据。它提供了一个通用的接口,支持多种语言,如 Python、Java、Scala、SQL、R,以及现在的 .NET,这意味着执行引擎不受您编写代码语言的影响。
为什么选择 Apache Spark?
除了易于使用之外,以下是一些使 Spark 在其他分析工具中脱颖而出的优势。
内存处理
Apache Spark 利用内存处理,这意味着不会花费时间将数据或进程移入或移出磁盘,从而提高速度。
高效
Apache Spark 非常高效,因为它通过弹性分布式数据集 (RDD) 在内存中缓存了大部分输入数据。RDD 是 Spark 的基本数据结构,负责管理数据的转换和分布式处理。RDD 中的每个数据集都经过逻辑分区,每个逻辑分区可能在不同的集群节点上进行计算。
实时处理
Apache Spark 不仅支持批处理,还支持流处理,这意味着数据可以实时输入和输出。
此外,Apache Spark 的 API 易于阅读和理解。它还利用惰性求值,这有助于提高其效率。而且,存在一个庞大且不断发展的开发者社区,他们不断地为技术做出贡献并进行评估。
Apache Spark for .NET
直到今年年初,由于缺乏 .NET 支持,.NET 开发人员一直无法进行大数据处理。 4 月 24 日,微软公布了一个名为 .NET for Apache Spark 的项目。
.NET for Apache Spark 使 .NET 开发人员能够使用 Apache Spark。它提供了高性能的 .NET API,您可以使用这些 API 访问 Apache Spark 的所有方面,并将 Spark 功能集成到您的应用程序中,而无需为了数据分析而将业务逻辑从 .NET 翻译成 Python/Scala/Java。
Apache Spark 生态系统
Spark 包含各种库、API 和数据库,并提供了一个完整的生态系统,可以满足团队或公司的各种数据处理和分析需求。您可以使用 Apache Spark 完成以下一些事情。
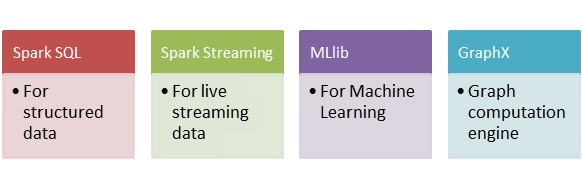
所有这些模块和库都构建在Apache Spark Core API之上。Spark Core 是 Spark 的构建块,负责内存操作、作业调度、构建和操作RDD中的数据等。
在对 Apache Spark 是什么以及它能为我们做什么有了一些了解之后,现在让我们来看看它的架构。
架构
Apache Spark 遵循驱动器-执行器概念。下图将使这个概念更加清晰。

每个 Spark 应用程序都包含一个驱动器和一个由集群管理器管理的工作节点或执行器集合。驱动器包含用户程序和Spark 会话。基本上,Spark 会话接收用户程序,并将其分解为小的任务块,然后分配给工作节点或执行器。每个执行器负责执行用户程序的一个小任务。集群管理器负责整体程序的执行,它帮助分解任务并将资源分配给驱动器和执行器。
在不深入探讨 Spark 工作原理的理论细节的情况下,让我们动手实践,在本地机器上配置和测试 Spark,看看它是如何工作的。
环境设置
.NET for Apache Spark 的 .NET 实现仍然使用 Java 虚拟机,所以没有一个独立的 .NET Spark 实现,它直接构建在 Java 运行时之上。以下是在 Windows 机器上运行 .NET for Apache Spark 所需的组件。
- Java 运行时环境
(建议您下载并安装 64 位 JRE 版本,因为 32 位版本对 Spark 的支持非常有限。)
- Apache Spark
(.NET 实现支持 Spark 2.3 和 2.4 版本。我将继续使用 Spark 2.4。一旦您从提供的链接中选择了 Spark 版本,请选择“Pre-Built for Apache Hadoop 2.7 or later”(预编译适用于 Apache Hadoop 2.7 或更高版本),然后下载 tgz 文件。下载完成后,将其解压到一个已知的位置。)
- Hadoop winutils.exe
下载完成后,将 `winutils.exe` 文件放在一个已知位置的另一个文件夹内的名为 `bin` 的文件夹中。
配置环境变量
在测试 Spark 之前,我们需要为 `SPARK_HOME`、`HADOOP_HOME` 和 `JAVA_HOME` 创建几个环境变量。您可以手动将这些环境变量添加到您的系统,也可以运行以下脚本来设置这些环境变量。
$ SET SPARK_HOME=c:\spark-2.4.1-bin-hadoop2.7
$ SET HADOOP_HOME=c:\hadoop
$ SET JAVA_HOME=C:\Program Files\Java\jre1.8.0_231
$ SET PATH=%SPARK_HOME%\bin;%HADOOP_HOME%\bin;%JAVA_HOME%\bin;%PATH%
请注意,您需要提供已解压的 *Spark* 目录、*winutils.exe* 和 **JRE** 安装的位置。上面的脚本将为您设置环境变量,并将每个目录的 `bin` 文件夹添加到 **PATH** 环境变量中。
要检查所有内容是否已成功设置,请检查 JRE 和 Spark shell 是否可用。运行以下命令。
$ Java –version
$ spark-shell
如果您已正确设置了所有环境变量,则应获得类似的输出。

Spark shell 允许您运行 **Scala** 命令来使用 Spark,并通过读取和处理文件来试验数据。
注意:您可以通过输入 **`:q`** 来退出 Spark-shell。
我们已成功为 .NET for Apache Spark 配置了环境。现在,我们可以创建我们的 .NET 应用程序 for Apache Spark 了。
让我们开始吧……
在本帖中,我将使用 Visual Studio 2019 创建一个 **.NET Core 控制台**应用程序。请注意,您也可以创建 .NET 运行时应用程序。

Visual Studio 完成模板创建后,我们需要添加 **.NET Spark Nuget** 包。

将 Nuget 包添加到项目后,您将在解决方案中看到 2 个 **jar** 文件。现在我们可以开始在程序中初始化 **Spark 会话**了。
using Microsoft.Spark.Sql;
namespace California_Housing
{
class Program
{
static void Main(string[] args)
{
// creating spark session
SparkSession Spark = SparkSession
.Builder()
.GetOrCreate();
// reading and loading data from CSV into DataFrame
DataFrame df = Spark
.Read()
.Option("inferSchema", true)
.Csv("housing.csv");
df = df.ToDF("longitude", "latitude", "housing_median_age",
"total_rooms", "total_bedrooms", "population", "households",
"median_income", "median_house_value", "ocean_proximity");
// printing schema and showing records
df.PrintSchema();
df.Show();
}
}
}
上面的代码会创建一个新的 `SparkSession`,或者在已创建的情况下获取一个。检索到的实例将提供一个单一的入口点和所有必要 API,用于与底层的 Spark 功能进行交互,并启用与 .NET 实现的通信。
下一步是加载应用程序将使用的数据。这里我使用的是加州住房数据 *housing.csv*。`Spark.Read()` 允许 Spark 会话从 CSV 文件读取。数据将被加载到 **DataFrame** 中,并自动推断列。文件读取后,将打印 schema 并显示前 20 条记录。
程序非常简单。构建并尝试运行您的解决方案,看看会发生什么。
您会注意到,您不能直接从 Visual Studio 中运行此程序。相反,我们需要先运行 **Spark**,以便它能够加载 **.NET 驱动程序**来执行程序。Apache Spark 提供 **`spark-submit`** 工具命令来提交和执行 .NET Core 代码。请看以下命令
spark-submit --class org.apache.spark.deploy.dotnet.DotnetRunner
--master local microsoft-spark-2.4.x-0.2.0.jar dotnet <compiled_dll_filename>
请注意,我们需要将编译后的 **DLL** 文件名作为参数来执行我们的程序。导航到项目解决方案目录,例如 *C:\Users\Mehreen\Desktop\California Housing*,然后运行以下命令来执行您的程序。
spark-submit --class org.apache.spark.deploy.DotnetRunner
--master local "bin\Debug\netcoreapp3.0\microsoft-spark-2.4.x-0.2.0.jar"
dotnet "bin\Debug\netcoreapp3.0\California Housing.dll"
您会收到很多 **Java IO** 异常,这些异常在此阶段可以成功忽略,也可以选择阻止它们。*Spark* 文件夹包含 `conf` 目录。在 `conf` 目录下的 `log4j.properties` 文件末尾添加以下行,以阻止这些异常。
log4j.logger.org.apache.spark.util.ShutdownHookManager=OFF
log4j.logger.org.apache.spark.SparkEnv=ERROR
让我们进入有趣的部分,看看 `PrintSchema()`,它显示我们 *CSV* 文件的列以及数据类型。

以及 `Show()` 方法显示的行。

幕后发生了什么?
在创建应用程序时,我提到 **.NET Core** 和 **.NET Runtime** 都可以用来创建 Spark 程序。这是为什么?我们 .NET Spark 代码到底发生了什么?为了回答这个问题,请看下图并尝试理解它。

您是否还记得添加 `Microsoft.Spark` Nuget 包时添加到解决方案中的 *jar* 文件?Nuget 包将 **.NET 驱动程序**添加到 .NET 程序中,并打包了 **.NET 库**以及您看到的两个 **jar** 文件。**.NET 驱动程序**被编译为 **.NET Standard**,因此无论您使用 **.NET Core** 还是 **.NET Runtime**,差异都不大。而这两个 *jar* 文件则用于与 Apache Spark 底层的原生 **Scala** API 进行通信。
还能做什么……
现在我们了解了幕后发生了什么,让我们对代码做一些调整,看看还能做什么。
删除不必要的列
由于我们处理的是大量数据,可能会有一些不必要的列。我们可以使用 **Drop()** 函数轻松删除这些列。
var CleanedDF = df.Drop("longitude", "latitude");
CleanedDF.Show();

数据转换
Apache Spark 允许您使用列来过滤数据。例如,我们可能只对湾区附近的房产感兴趣。我们可以使用以下代码过滤给定区域的房产数据。
var FilteredDF = CleanedDF.Where("ocean_proximity = 'NEAR BAY'");
FilteredDF.Show();
Console.WriteLine($"There are {FilteredDF.Count()} properties near Bay Area");

// There are 2290 properties near Bay Area
我们也可以使用 `Select()` 方法迭代一列,例如,获取该区域的总人口。
var sumDF = CleanedDF.Select(Functions.Sum(CleanedDF.Col("population")));
var sum = sumDF.Collect().FirstOrDefault().GetAs<int>(0);
Console.WriteLine($"Total population is: {sum}");
上面的代码将迭代 `population` 列并返回 `sum`。
// Total population is: 29421840
让我们看另一个使用 `Select()` 和 `Filter()` 方法的例子,我们对获取特定范围内的值感兴趣。
var SelectedDF = CleanedDF.Select("median_income", "median_house_value")
.Filter(CleanedDF["median_income"].Between(6.5000, 6.6000) &
CleanedDF["median_house_value"].Between(250000, 300000));
SelectedDF.Show();
上面的代码将只输出 `median_income` 在 6.5 - 6.6 之间且 `median_house_value` 在 250000 - 300000 之间的条目。

下一步是什么?
本文旨在为您提供 .NET for Apache Spark 的快速介绍和入门指南。显而易见,.NET 实现为 .NET 开发人员带来了 Apache Spark 的全部强大功能。此外,您还可以使用 .NET for Apache Spark 编写跨平台程序。微软正在 .NET 框架上大力投入。Apache Spark 的 .NET 实现也可以与 ML.NET 一起使用,并且可以执行许多复杂的机器学习任务。欢迎您随意尝试。
历史
- 2019 年 12 月 1 日:初始版本