
Azure Cognitive Services 101
5.00/5 (2投票s)
Azure 认知服务入门,了解其功能并能在10分钟内开始识别图像
引言
在 4DotNet,我们有一个年度开发者日。这意味着,一年中的某一天,我们都会聚在一起,用最新的技术/功能挑战自己。当我们寻找一个好的挑战时,我记得微软的一个演示项目,它描述了一个游戏,玩家会收到一个指令,要求他们拍摄“某个物体”的照片。这里的物体是不断变化的。玩家现在可以拿起他们的移动设备,拍摄那个物体的照片。第一个这样做的玩家赢得该回合,然后会发出一个带有不同物体的新指令。这个游戏背后的技术(验证所拍摄的照片是否包含指令中的物体)是 Azure 认知服务 (ACS)。因为我从来没有遇到过使用 ACS 的项目,所以我认为这将是我们开发者日的一个很好的案例,因此我提议在开发者日期间,分成几个团队重新创建这个游戏。然后我们的首席执行官进来说,创建游戏会很有趣,但挑战性不够,因为“在 Azure 中调用 API 没那么难”。我同意他的看法,但由于我(再次)从未使用过 ACS,我仍然对这个系统感到好奇,所以我只是启动了一个小项目来看看它是如何工作的。那么,我们开始吧……
让 ACS 启动并运行
首先,我登录到 Azure 门户,看看启动认知服务需要什么。一旦你这样做,你就会看到各种已经存在的服务
- Bing 自动建议
- Bing 自定义搜索
- Bing 实体搜索
- Bing 搜索
- Bing 拼写检查
- 计算机视觉
- 内容审查
- 自定义视觉
- …
- 沉浸式阅读器(预览)
- 语言理解
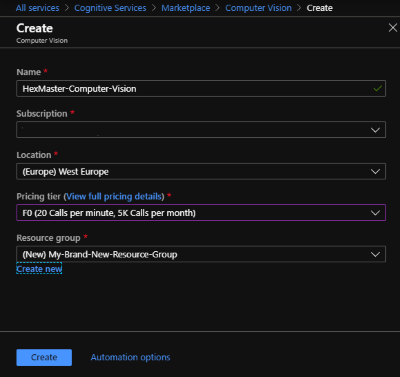 如今,有 20 种非常智能的功能可以在认知服务背后运行,所以你需要大致知道你要走向哪个方向。例如,当你想使用人脸识别时,你可以选择计算机视觉或自定义视觉来解释图片/图像,但 ACS 还包含一个名为“人脸”的服务,它更适合这种特定的解决方案。所以请注意,有很多服务可供你选择,请明智地选择。;)
如今,有 20 种非常智能的功能可以在认知服务背后运行,所以你需要大致知道你要走向哪个方向。例如,当你想使用人脸识别时,你可以选择计算机视觉或自定义视觉来解释图片/图像,但 ACS 还包含一个名为“人脸”的服务,它更适合这种特定的解决方案。所以请注意,有很多服务可供你选择,请明智地选择。;)
对于这个演示,我的目标是上传图片并调用服务告诉我图片上有什么。我选择了“计算机视觉”。如你所见,你可以创建一个免费的认知服务。是的!!它是免费的!!只要你每月调用次数少于 5K 次,每分钟少于 20 次。所以对于测试/玩耍,这个免费实例应该足够了。
开发酷炫的功能
好的,现在服务已经运行,一切都应该设置好了。现在,当你导航到 Azure 门户中的计算机视觉实例时,你会看到一个密钥(Key1)和一个端点。你需要这些来调用服务并获得有意义的响应。
我打开 Visual Studio (2019,已更新到最新版本,这样我就可以在 .NET Core 3.0 上运行 Azure Functions)。然后我启动了一个新的 Azure Functions 项目。我打开了 local.settings.json 文件并对其进行了编辑,使其看起来像这样
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet",
"COMPUTER_VISION_SUBSCRIPTION_KEY": "your-key",
"COMPUTER_VISION_ENDPOINT": "your-endpoint"
}
}
当然,请确保将 your-key 和 your-endpoint 更改为你在 Azure 门户中找到的值。现在我创建了一个带有 BLOB 触发器的新函数。计算机视觉服务接受最大 4 MB 的图像。所以如果你打算用你的全画幅单反拍摄一些图像并上传它们,请三思。所以我想象 某个 系统会使用 Valet Key Pattern 将图片上传到 BLOB 存储。一个 Azure Function 将调整该图像的大小,使其符合计算机视觉服务的要求,然后将该图像作为 BLOB 存储在名为“scaled-images”的容器中。我们即将创建的函数将在图像存储在“scaled-images”容器中时触发。
[FunctionName("CognitiveServicesFunction")]
public static async Task Run(
[BlobTrigger("scaled-images/{name}", Connection = "")] CloudBlockBlob blob,
string name,
ILogger log)
{
}
就是这样,一旦 BLOB 被写入我们的容器,函数就会触发。计算机视觉可以很容易地通过 HTTP 请求调用,我稍后会创建一个 HTTP 客户端,但首先,我们需要知道端点和我们的密钥,这样我们才能发出有效的 HTTP 请求。在你的函数类中,像这样创建三个静态字符串
private static string subscriptionKey =
Environment.GetEnvironmentVariable("COMPUTER_VISION_SUBSCRIPTION_KEY");
private static string endpoint =
Environment.GetEnvironmentVariable("COMPUTER_VISION_ENDPOINT");
private static string uriBase = endpoint + "vision/v2.1/analyze";
前两行从设置中读取你的密钥和端点,第三行追加到计算机视觉分析服务的路径。如你所见,我们将调用分析服务的 2.1 版本。现在回到你的函数中并创建 HTTP 客户端。
var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", subscriptionKey);
如你所见,我们将把你的个人密钥添加到 HTTP 请求的请求头中。现在是时候定义我们希望服务分析的信息了。你可以使用 VisualFeature enum 来设置这些。这个 enum 在认知服务 NuGet 库中可用(更多信息请点击此处)。最终,使用它们只会添加一个带有字符串值的查询字符串参数。对于我们的纯 HTTP 请求,我们只需将该查询字符串参数添加到我们的 HTTP 请求中。可用选项有
- 类别 - 根据文档中定义的分类法对图像内容进行分类
- 标签 - 使用与图像内容相关的详细词语列表标记图像
- 描述 - 用一个完整的英语句子描述图像内容
- 人脸 - 检测是否存在人脸。如果存在,则生成坐标、性别和年龄
- 图片类型 - 检测图片是剪贴画还是线条画
- 颜色 - 确定强调色、主导色以及图像是否为黑白
- 成人内容 - 检测图像是否具有色情性质(描绘裸体或性行为)。还会检测具有性暗示的内容
- 名人 - 如果图像中检测到名人,则识别名人
- 地标 - 如果图像中检测到地标,则识别地标
我将选择类别、描述和颜色。所以最终,我将调用的端点是
https://instance-name.cognitiveservices.azure.com/vision/v2.1/
analyze?visualFeatures=Categories,Description,Color
发布请求
现在几乎一切都已设置好,我们只需要再添加一个标头,当然还有图像,所以我们开始吧!首先,我将把 BLOB 内容下载到一个字节数组中
await blob.FetchAttributesAsync();
long fileByteLength = blob.Properties.Length;
byte[] fileContent = new byte[fileByteLength];
var downloaded = await blob.DownloadToByteArrayAsync(fileContent, 0);
因为我将在 HTTP 请求中使用这个字节数组,所以我正在创建一个 ByteArrayContent 对象,这样当我在发布它时,我的客户端可以将字节数组作为 HttpContent 接受。所以要完成请求
using (ByteArrayContent content = new ByteArrayContent(fileContent))
{
content.Headers.ContentType =
new MediaTypeHeaderValue("application/octet-stream");
response = await httpClient.PostAsync(uri, content);
}
你看到我添加了 MediaTypeHeaderValue,因此在 Content-Type 标头中发送了“application/octet-steam”值。然后我发送 POST 请求并等待响应。
响应
认知服务会响应一个 JSON 消息,其中包含使用视觉功能所需的所有信息,并应用于上传的图像。下面是返回的 JSON 示例
{
"categories": [
{
"name": "abstract_",
"score": 0.00390625
},
{
"name": "others_",
"score": 0.0703125
},
{
"name": "outdoor_",
"score": 0.00390625,
"detail": {
"landmarks": []
}
}
],
"color": {
"dominantColorForeground": "White",
"dominantColorBackground": "White",
"dominantColors": [
"White"
],
"accentColor": "B98412",
"isBwImg": false,
"isBWImg": false
},
"description": {
"tags": [
"person",
"riding",
"outdoor",
"feet",
"board",
"road",
"standing",
"skateboard",
"little",
"trick",
"...",
"this was a long list, I removed some values"
],
"captions": [
{
"text": "a person riding a skate board",
"confidence": 0.691531186126425
}
]
},
"requestId": "56320ec6-a008-48fe-a69a-e2ad3b374804",
"metadata": {
"width": 1024,
"height": 682,
"format": "Jpeg"
}
}
 我发送的图片是这里显示的图像的放大版,如你所见,计算机视觉给出的描述非常准确,“一个人在滑滑板”确实是图片上的内容。此外,一些标签也非常巧妙。服务返回的强调色 #B98412 也匹配(它是一种较深的黄褐色,与图片匹配)。只有类别不太令人印象深刻。它没有提出一个明确的想法,所有三个值的置信度得分都是“令人反感的”。为了方便你,我在 GitHub Gist 中分享了我的 Azure Function。请确保你的存储账户中有一个名为“
我发送的图片是这里显示的图像的放大版,如你所见,计算机视觉给出的描述非常准确,“一个人在滑滑板”确实是图片上的内容。此外,一些标签也非常巧妙。服务返回的强调色 #B98412 也匹配(它是一种较深的黄褐色,与图片匹配)。只有类别不太令人印象深刻。它没有提出一个明确的想法,所有三个值的置信度得分都是“令人反感的”。为了方便你,我在 GitHub Gist 中分享了我的 Azure Function。请确保你的存储账户中有一个名为“scaled-images”的容器。现在你可以运行该函数并开始将图像上传到“scaled-images”容器。该函数将获取它们并开始分析它们。输出的 JSON 消息将显示在 Azure Functions 控制台窗口中。
就是这样,你现在也知道如何使用 Azure 认知服务了……祝你圣诞快乐!
历史
- 2019年12月31日:初始版本