
代码现代化实战:线程、内存和向量优化
利用最新的 Intel® 软件开发工具更有效地利用硬件。
高性能计算(HPC)系统是硬件组件的复杂组合。硬件供应商正不断努力提高速度、降低延迟、增加核心数量并增加向量长度,以提高计算密集型应用程序的性能。但仅仅在具有更好组件的系统上运行应用程序并不能保证这些组件得到有效利用。要获得预期的性能提升,可能仍需要修改代码。
幸运的是,Intel® Parallel Studio XE 提供了涵盖 Intel® 硬件上代码调优各个方面的工具。有时很难知道从哪个工具开始,因此 Intel® VTune™ Amplifier Application Performance Snapshot (APS) 是快速了解应用程序性能特征的摘要——特别是限制性能的瓶颈。您可以使用快照选择合适的 Intel Parallel Studio XE 工具来调优集群、节点和/或核心级别的性能(图 1)。

Iso3DFD*:一种波传播内核及其性能测量
让我们看看这些工具如何帮助我们找到瓶颈并提高示例代码的性能。Iso3DFD 实现各向同性声波方程

其中 ∇2 是拉普拉斯算子,p 是压力场,c 是速度场。可以使用有限差分将 pt+1 表示为 pt 和 pt-1 的函数。实现有限差分传播内核可以使用模板(stencil)模式。在三维中,模板看起来像一个我们移动到压力场上的 3D 十字架。换句话说,要更新 pt+1[x,y,z],我们需要访问 pt[x,y,z] 在 3D 中的所有邻居。图 2 演示了 2D 中的模板模式。

在实际应用中,物理学家通常会为边界情况实现特定的传播方法。这些边界情况称为边界条件。为使本示例代码保持简单,我们不会在边界上传播波。图 3 中的直接实现计算模板的单次迭代。

由于本文将侧重于单节点性能,因此示例代码将不使用 MPI 来实现集群级别的并行。为了建立基线性能,我们使用了一个 512 x 400 x 400 的网格,在双路 **Intel® Xeon® Gold 6152 处理器**(2.1 GHz,每个插槽 22 核)系统(Red Hat Enterprise Linux Server* 7.4)上对初始实现进行了基准测试。使用此命令设置 Intel Parallel Studio XE 环境
> source <Parallel_Studio_install_dir>/psxevars.sh
让我们使用 Intel VTune Amplifier 的 Application Performance Snapshot 来快速查找初始 Iso3DFD 实现中的调优机会。此命令调用 APS
> aps ./Iso3DFD
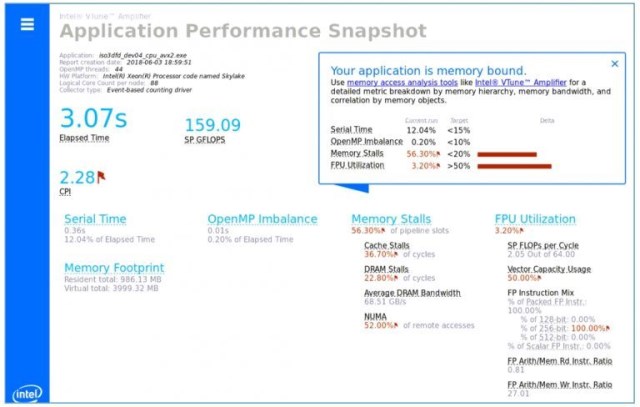
图 4 显示了在 Web 浏览器中显示的 APS 报告。当然,应用程序的初始单线程版本仅使用系统 44 个物理核心中的一个。APS 认为这是主要的性能机会,所以我们来并行化代码。

优化步骤 1:使用 OpenMP* 引入线程级并行
循环中没有依赖关系,所以让我们使用 OpenMP* 的“parallel for”指令在最外层循环上进行直接并行化,因为它每个迭代的工作量最大(图 5)。

通过 APS 快速检查,可以看到执行时间得到了显著改善(图 6)。快照报告了一些 OpenMP 的负载不平衡问题,但大约 38 倍的加速是一个不错的开始。更紧迫的性能问题是应用程序受内存限制。我们需要改进内存访问以消除此瓶颈。

优化步骤 2:使用循环交换改进内存访问
由于内存访问不佳导致的内存停顿是当前应用程序的主要瓶颈,因此,按照 APS 中的提示(图 6),我们运行 Intel VTune Amplifier 内存访问分析。
> amplxe-cl –collect memory-access ./Iso3DFD
分析结果如图 7 所示。应用程序受 DRAM 限制,但内存带宽消耗远未达到极限(即 DRAM 带宽受限值很小)。这对于访问内存步长很大的应用程序来说很常见。 **Intel® Advisor** 的检查内存访问模式分析可以帮助我们检测导致问题的代码行(图 8)。


步长 204,800 正好是我们前两个维度的大小(512 x 400)。这意味着在最内层循环中按数组元素进行迭代不会有效利用处理器缓存。我们可以通过更改循环顺序来解决此问题(图 9)。

通过此更改,最内层循环中对数组元素的访问将在内存中连续,这应该会增加缓存重用。让我们重新编译并使用 APS 再次获取性能快照(图 10)。根据报告,通过优化内存访问,我们获得了大约 4.7 倍的加速。内存停顿的百分比显著降低,应用程序不再受 DRAM 限制。然而,之前在图 6 中报告的 OpenMP 不平衡问题,在图 10 中再次出现,现在是主要的性能问题。

优化步骤 3:使用 OpenMP 动态调度改进负载均衡
尽管我们仍然存在内存停顿,但 APS 将我们的注意力引向了 OpenMP 不平衡问题,该问题占用了 30% 的执行时间。OpenMP 默认使用静态调度。这通常是一种有效、开销低的调度协议。但是,它有时会导致负载不平衡,所以让我们尝试动态调度(图 11)来替代。

这显著缓解了负载不平衡问题(图 12)。

优化步骤 4:使用缓存块(Cache Blocking)改进内存访问
由于缓存停顿仍然很显著(图 12),我们可以尝试通过实现一种众所周知的优化技术——缓存块(cache blocking)——来优化缓存中的数据重用(图 13)。

请注意,为了向 OpenMP 线程提供并行工作,我们在 `omp parallel` for 指令中添加了 `collapse(3)` 子句,以便为块状化安排的三个循环能够折叠成一个大的迭代空间。新的 APS 显示了 1.3 倍的性能提升,并且由于缓存块,内存停顿更少,OpenMP 负载均衡也得到了改善(图 14)。

优化步骤 5:引入向量化
从 APS 报告中,我们可以看到我们的计算内核只包含标量浮点指令(“标量 FP 指令百分比”值为 100%)。这意味着编译器没有自动进行向量化。让我们使用 Intel Advisor 来探索向量化代码的机会。
> advixe-cl –collect survey ./Iso3DFD
打开 GUI 中的报告并查看“Survey”和“Roofline”选项卡,我们可以看到该工具建议我们应用 SIMD 指令来帮助编译器向量化突出显示的循环(图 15)。

OpenMP 标准最近添加了 `omp simd` 指令,以帮助编译器在无法确定循环迭代是否独立时进行自动向量化。所以,让我们插入该指令看看是否有帮助(图 16)。

使用 `-xHost` 编译器选项重新编译应用程序以使用正确的向量指令集。APS 报告现在显示了 2 倍的性能提升(图 17)。此外,我们看到向量容量使用率为 50%。然而,随着向量化效率的提高,我们发现现在内存的压力很大。我们需要引入比以前更多的数据来喂饱向量单元,这就是为什么我们再次看到内存停顿。
线程、内存和向量化优化
我们可以尝试进一步的优化(例如,使用 `-qopt-zmm-usage=high` 编译器选项),但通过一些基本的代码修改和有效使用 Intel Parallel Studio XE,特别是 APS,我们已经从 1,767 秒的基线性能缩短到了 3 秒。APS 在快速检查优化进度和识别调优机会方面非常有用。Intel VTune Amplifier 的内存访问分析和 Intel Advisor 的 Survey 和内存访问模式分析在对特定性能方面进行更深入的分析时提供了帮助。
了解更多
- Intel Parallel Studio XE
- Intel Advisor
- Intel VTune Amplifier
- Intel VTune Amplifier Application Performance Snapshot
性能测试中使用的软件和工作负载可能仅在 Intel 微处理器上针对性能进行了优化。性能测试,例如 SYSmark 和 MobileMark,是使用特定的计算机系统、组件、软件、操作和功能来测量的。任何这些因素的更改都可能导致结果有所不同。您应该参考其他信息和性能测试,以帮助您全面评估您正在考虑购买的产品,包括该产品与其他产品结合使用时的性能。有关更完整的信息,请访问 http://www.intel.com/performance。
Intel 的编译器对于非 Intel 微处理器上的优化(这些优化不特定于 Intel 微处理器)可能或可能不会达到相同的优化程度。这些优化包括 SSE2、SSE3 和 SSSE3 指令集以及其他优化。Intel 不保证在非 Intel 制造的微处理器上进行任何优化的可用性、功能或有效性。本产品中特定于微处理器的优化仅供 Intel 微处理器使用。某些非特定于 Intel 微体系结构的优化保留给 Intel 微处理器使用。有关本通知涵盖的具体指令集的信息,请参阅适用的产品用户和参考指南。