
使用 Intel® Advisor 消除内存瓶颈
了解程序如何访问内存有助于您更好地利用硬件。
您的应用程序访问内存的方式对性能有着决定性的影响。仅仅通过添加线程和向量化来并行化应用程序是远远不够的。有效利用内存带宽同样重要。但很多时候,软件开发者并不理解这一点。能够帮助减少内存延迟和提高带宽的工具可以帮助我们定位性能瓶颈并诊断其原因。Intel® Advisor 就是这样一款工具,它具有优化内存访问和消除内存瓶颈的功能。
- 使用新的集成 Roofline 功能进行 Roofline 分析
- 内存访问模式分析 (MAP)
- 内存占用分析
获得卓越性能
为了从您的应用程序中获得顶级性能,您需要了解您对所有系统资源的利用情况。您可以在 Intel Advisor 的“摘要”视图(图 1)中看到一些关于您的整个程序的有用指标,它能指示应用程序的向量化程度。

您还需要系统地检查程序中耗时最多的循环。一个关键的指标是向量化效率(图 2)。在这个例子中,Intel Advisor 显示向量化增益为 2.19 倍。但这仅意味着向量化效率得分为 55%。我们损失了 45% 的效率。导致向量化效率低下的因素有很多。

性能问题
不良的访问模式
间接内存访问是导致性能下降的常见原因。请注意下面的代码片段,在解码 B[i] 之前我们无法解码 A。
for (i = 0; i < N; i++)
A[B[i]] = C[i] * D[i];
这导致了不规则的访问模式。编译器通常可以通过一种称为“gather/scatter”的技术来向量化这种情况——这很好,因为它允许该循环进行向量化,但也不好,因为这些 gather/scatter 指令不如顺序访问快。为了获得快速的代码,尝试安排您的数据结构,以便数据以单位步长访问(稍后您将看到 Intel Advisor 如何显示此信息)是很重要的。
内存子系统延迟/吞吐量
让您的代码能够适应各种内存缓存,并优化数据重用,对于获得系统的最佳性能至关重要。在下面的示例中,我们使用 i 对一大块数据进行索引。这块数据太大,无法放入缓存,这是不好的——而 A 是一个多维数组,这使得情况更加糟糕。
for (i = 0; i < VERY_BIG; i++)
c[i] = z * A[i][j];
内存中 A[i][j] 和 A[i+1][j] 的引用并不相邻。因此,要获取每个新
引用,我们需要加载一个新的缓存行——并且可能需要驱逐一个缓存行。这种“缓存抖动”将
对性能产生负面影响。诸如缓存阻塞之类的技术,通过添加一个新的内部循环来
索引一个更小的范围,该范围设计为适合缓存,可以帮助优化这类应用程序。
分支代码
包含大量分支的应用程序(例如,下面带有 if(cond(i)) 的 for 循环)可以使用掩码寄存器进行向量化,以屏蔽条件不为真的 SIMD 通道。在这些迭代中,SIMD 通道不会执行有用的工作。Intel Advisor 使用掩码利用率指标(图 3)。有三个元素被抑制,使得掩码利用率为 5/8 = 62.5%。
for (i = 0; i < MAX; i++)
if (cond(i))
C[i] = A[i] + B[i];

您可能可以以单位步长的方式访问数据并获得出色的向量化效率,但由于掩码利用率低(图 4),您仍然无法获得所需的性能。表 1 显示了内存访问类型。

表 1. 内存访问类型
| 访问模式 | 小内存占用 | 大内存占用 |
| 单位步长 |
|
|
| 恒定步长 |
|
|
| 不规则访问, gather/scatter |
|
|
您的程序受 CPU/VPU 还是内存限制?
如果您的应用程序受内存限制,Intel Advisor 的一些功能可以帮助您优化。但首先,您需要确定您的程序是受内存限制还是受 CPU/VPU 限制。一种快速确定方法是查看您的指令。Intel Advisor 的代码分析窗口(图 5)可以以一种非常基本的方式显示您代码执行的指令组合。

一个经验法则是,执行大量内存指令的应用程序倾向于受内存限制,而执行大量计算指令的应用程序倾向于受计算限制。请注意图 5 中的细分。标量指令与向量指令的比例尤其重要。您应该尽量使用更多的向量指令。
另一种稍微复杂一点的技术是使用 Intel Advisor“调查”视图中的“特性”列(图 6)。

将“特性”视为编译器为了向量化您的循环所需要做的事情。在最新的向量指令集(如 Intel® AVX-512)中,有许多新的指令和习语,编译器可以使用它们来向量化您的代码。诸如寄存器掩码和压缩指令(图 6 中所示)之类的技术确实允许应用程序在以前不可能的情况下进行向量化——但有时会付出代价。编译器为了使您的数据结构适合向量(例如内存操作)所做的任何事情通常都会出现在“特性”列中。这些“特性”通常表明存在一个问题,您可以通过内存访问模式分析来深入研究。
有用的优化功能
Roofline 分析
Roofline 图是一种可视化表示应用程序性能相对于硬件限制(包括内存带宽和计算峰值)的方式。它最早由加州大学伯克利分校的研究人员在 2008 年的论文“Roofline: A Visual Performance Model for Multicore Architectures”中提出。2014 年,该模型由里斯本技术大学的研究人员在一篇题为“Cache-Aware Roofline Model: Upgrading the Loft”的论文中进行了扩展。传统上,Roofline 图是手动计算和绘制的。但 Intel Advisor 现在可以自动构建 Roofline 图。
Roofline 图提供了对以下方面的洞察:
- 性能瓶颈在哪里
- 由于它们,有多少性能被浪费了
- 哪些瓶颈是可以解决的,哪些是值得解决的
- 这些瓶颈最可能发生的原因是什么
- 下一步应该怎么做

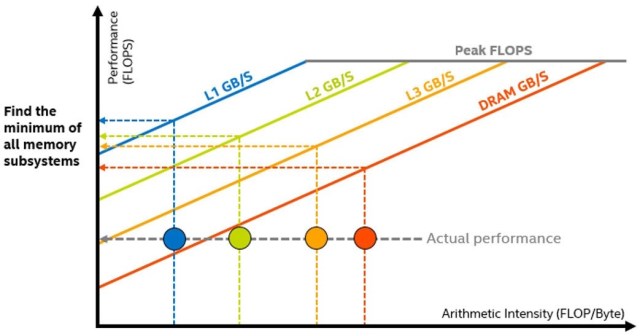
图 7 中的水平线表示您的硬件在给定时间内可以执行的给定类型的浮点或整数计算的数量。对角线表示给定内存子系统每秒可以传输多少数据。每个点代表程序中的一个循环或函数,其位置表示其性能,这受其优化和算术强度 (AI) 的影响。
Intel Advisor 集成 Roofline
集成 Roofline 模型提供了更详细的分析,直接显示瓶颈的来源。Intel Advisor 使用缓存模拟收集所有内存类型的数据(图 8)。

利用这些数据,Intel Advisor 计算给定缓存级别的所有数据传输次数,并计算每个循环和每个内存级别的特定 AI。通过观察此流量从一个级别到另一个级别的变化,然后将其与表示这些级别最佳可能带宽的相应上限进行比较,就可以确定内核的内存层次结构瓶颈并确定优化步骤(图 9)。
内存访问模式 (MAP) 分析
Intel Advisor MAP 分析让您最深入地了解您如何访问内存。您的内存访问模式会影响向量化的效率以及您最终能实现的内存带宽。MAP 收集在执行期间观察数据访问,并找出包含内存访问的指令。收集和分析的数据会出现在“优化报告”窗口的“内存访问模式”选项卡中。
要从 GUI 运行 MAP 分析(图 10),您需要使用“调查”报告中的复选框选择循环,然后运行 MAP 收集。

您也可以从命令行运行 MAP 收集。使用 -mark-up-list 选项选择
要分析的循环。
advixe-cl -collect map -mark-up- list=Multiply.c:78,Multiply.c:71,Multiply.c:50,Multiply.c:6 1 -project-dir C:/my_advisor_project -- my_application.exe
内存访问模式报告提供了关于循环执行期间内存访问操作中观察到的步长类型的信息。该工具报告单位/统一步长和恒定步长(图 11)。
单位/统一步长类型
- 单位步长(步长 1)指令在每次迭代中以一个元素为单位连续访问内存。
- 统一步长 0 指令在每次迭代中访问相同的内存。
- 恒定步长(步长 N)指令在每次迭代中以 N 个元素(N>1)为单位连续访问内存。
可变步长类型
- 不规则步长指令访问的内存地址在每次迭代中会以不可预测的数量变化。
- gather(不规则)步长在 AVX2 指令集架构上通过 v(p)gather* 指令检测。

双击“内存访问模式”报告选项卡中的任何一行,即可查看所选操作的源代码(图 12)。
“源”和“详细信息”视图(图 13)都为您提供了对 Intel Advisor 另一项关键内存功能——内存占用的洞察。
内存占用分析
内存占用基本上是指给定循环访问的内存范围。这个占用范围是内存带宽的关键指标。如果范围很大,则可能无法放入缓存。像缓存阻塞这样的优化策略可以在这些情况下产生很大影响。Intel Advisor 有三种不同的内存占用指标(图 14)。



两个基本的占用指标代表了内存占用的一些方面。这些指标在内存访问模式 (MAP) 分析中是默认收集的。
- 最大指令地址范围表示此循环中的指令访问的内存地址值的最大值和最小值之间的最大距离。对于每个内存访问指令,都会记录其访问的最小和最大地址,并报告所有循环指令的最大地址范围。它覆盖了多个循环实例,并进行了一些过滤,因此 Intel Advisor 有时对该指标的信心较低,并以灰色显示。
- 首次实例站点占用是更准确的内存占用,因为它考虑了循环迭代中地址范围的重叠以及循环访问的地址范围之间的间隔,但仅计算该循环的第一个实例(调用)。
基于缓存模拟计算了一个更高级的占用指标,称为模拟内存占用。该指标显示了所有循环实例的汇总和重叠感知图,但仅限于一个线程。它是通过缓存模拟期间访问的唯一缓存行数乘以缓存行大小来计算的。要在 GUI 中启用它,请在“项目属性”的“内存访问模式”选项卡中选择“启用 CPU 缓存模拟”复选框,并在下拉列表中选择“模型缓存未命中”和“循环占用模拟模式”(图 15)。然后,在“调查”视图中使用复选框选择您感兴趣的循环,并运行 MAP 分析。

要在命令行中启用,您需要使用之前指定的 MAP 命令,并带有以下选项:-enable-cache-simulation 和 -cachesim-mode=footprint。
advixe-cl -collect map -mark-up- list=tiling_inter.cpp:56,output.c:1073 -enable-cache- simulation -cachesim-mode=footprint -project-dir C:\my_advisor_project -- my_application.exe
您可以在 Intel Advisor GUI 优化报告视图中看到分析结果(图 16)。更详细的缓存相关指标——如内存加载、存储、缓存未命中以及缓存模拟的内存占用总数——可以对循环相对于内存的行为进行更详细的研究。表 2 显示了 Intel Advisor 占用指标的适用性、局限性和对分析不同类型代码的相关性。

表 2. Intel Advisor 占用指标
| 最大指令 指令 地址范围 | 首次实例站点 占用 | 模拟 内存 占用 | |
| 为循环/站点分析的线程数 | 1 | 1 | 1 |
| 分析的循环实例数 | 所有实例, 但有一些 捷径 | 1,仅第一个 实例 | 取决于 循环调用计数 限制选项 |
| 是否考虑地址范围重叠? | 否 | 是 | 是 |
| 适用于具有随机 内存访问的代码 | 否 | 否 | 是 |
一个实际示例
计算科学中最常见的一些问题需要矩阵乘法。使用矩阵的领域几乎是无限的,但人工智能、仿真和建模只是其中的几个例子。下面的示例算法是一个三重嵌套循环,我们在每次迭代中执行一次乘法和一次加法。除了计算量大之外,它还访问大量内存。让我们使用 Intel Advisor 来看看有多少。
for(i=0; i<msize; i++) {
for(j=0; j<msize; j++) {
for(k=0; k<msize; k++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
创建基线
我们首次运行的经过时间为 53.94 秒。图 17 是一个缓存感知 Roofline 图。红点是我们主要的计算循环。它远低于 DRAM 带宽,甚至更远低于 L1 带宽,L1 带宽是我们试图达到的最大带宽。您可以通过该循环的代码分析选项卡(图 18)看到我们在内存层次结构的每个级别上实现的精确带宽。
为什么我们的性能如此差?我们如何能做得更好?这些是 Intel Advisor 设计来回答的问题。首先,我们需要检查“调查”视图(图 19)以了解情况,以及 Intel Advisor 是否有任何建议。Intel Advisor 已注意到我们存在“内存访问模式效率低下”的问题,并且该循环由于假定的依赖关系而未被向量化。为了检查内存访问模式,我们可以运行内存访问模式 (MAP) 分析(图 20)。




Intel Advisor 已检测到我们的读取访问为恒定步长,写入为统一步长 0。我们访问的内存范围为 32MB,远大于我们任何缓存的大小(图 21)。我们还可以使用 MAP 报告(图 22)来查看缓存的性能。我们有超过 2300 次缓存未命中,所以性能差不足为奇。但有几种方法可以解决这个问题。


步骤 1
进行循环交换,这样我们就不需要恒定步长,也不需要访问这么大的内存范围。我们还可以通过包含一个 pragma ivdep 来向量化循环,该 pragma 告知编译器我们没有阻止向量化的依赖关系。
for(i=tidx; i<msize; i=i+numt) {
for(k=0; k<msize; k++) {
#pragma ivdep
for(j=0; j<msize; j++) {
c[i][j] = c[i][j] + a[i][k] * b[k][j];
}
}
}
我们新运行的经过时间为 4.12 秒,提高了 12 倍以上。为什么我们的新性能好这么多?首先,让我们看看我们的集成 Roofline 图(图 23)。每个红圈代表相应内存层次结构(L1、L2、L3 和 DRAM)的带宽。我们可以看到我们的计算循环的 L1 内存带宽(由最左边的红圈表示)现在是 95 GB/秒。我们还可以使用“调查”视图(图 24)来查看我们现在使用 AVX2 指令实现了 100% 的向量化效率。

我们的 MAP 报告(图 25)告诉我们,我们所有的访问现在都是单位步长,并且最大地址
范围是 16KB,完全在我们的缓存大小范围内。我们的缓存性能也得到了显著提升(图 26)。
我们的缓存未命中数从 2,302 次下降到 512 次。所以我们的性能有所提升,但我们仍然
没有达到峰值。

第二步
实现缓存阻塞,以便我们的计算在较小的内存范围内进行。
for (i0 = ibeg; i0 < ibound; i0 +=mblock) {
for (k0 = 0; k0 < msize; k0 += mblock) {
for (j0 =0; j0 < msize; j0 += mblock) {
for (i = i0; i < i0 + mblock; i++) {
for (k = k0; k < k0 + mblock; k++) {
#pragma ivdep
#ifdef ALIGNED
#pragma vector aligned
#endif //ALIGNED
#pragma nounroll
for (j = j0; j < 10 + mblock; j++) {
c[i] [j] = c[i] [j] + a[i] [k] * b[k] [j];
}
}
}
}
}
}
在上面的代码中,我们添加了三个额外的嵌套循环,以便我们在分块(或块)中进行计算。完成一个块后,我们移动到下一个。我们的缓存阻塞情况的经过时间为 2.60 秒,比之前的运行提高了 1.58 倍(图 27)。我们的循环的 L1 内存带宽现在是 182 GB/秒,非常接近 L1 上限。我们的向量化和步长没有改变,但现在我们的内部循环只有 15 次缓存未命中,并且地址范围已缩小到 480 字节(表 3)。

表 3. 结果摘要
| Run | 时间 经过时间, 秒 | 总 GFlops | 内存 地址 Range | 缓存 未命中次数 | 改进 (时间) |
| 基线 | 53.94 | 0.32 | 32 MB | 2,302 | N/A (基线) |
| 循环 交换 | 4.19 | 4.17 | 16 KB | 511 | 12.87x |
| 阻塞 | 2.6 | 6.61 | 480 B | 15 | 20.74x |
优化内存访问
优化程序的内存访问至关重要。了解您的程序如何访问内存,并使用 Intel Advisor 这样的工具,可以帮助您充分利用硬件。通过使用 Intel Advisor 的 Roofline 和新的集成 Roofline 功能,您可以可视化您的内存瓶颈。当您将 Roofline 功能与内存访问模式分析相结合时,您可以获得更深入的内存洞察。
相关资源
特别感谢
本文来自《并行宇宙》,这是 Intel 的季度杂志,通过最新的工具、技巧和培训帮助您将软件开发带入未来,扩展您的专业知识。 在此处获取。