
有效利用您的整个集群
优化 Intel® 架构上的 SPECFEM3D_GLOBE 性能
英特尔是数据中心用户硬件和软件的领先提供商——例如最新的Intel® Xeon®和Intel® Xeon Phi™处理器。然而,许多高性能计算(HPC)应用程序未能充分利用处理器的先进功能。在本文中,我们将提供一种循序渐进的方法来提高SPECFEM3D_GLOBE*的性能,这是一个模拟三维全球和区域地震波传播并基于谱元法(SEM)执行全波形成像(FWI)或伴随层析成像的软件包。所有SPECFEM3D_GLOBE软件均使用Fortran* 2003编写,充分考虑了可移植性,并严格符合2003标准。该软件包使用消息传递接口(MPI)来表达分布式内存并行性。最近,OpenMP*共享内存并行结构已引入到求解器源代码中。
请遵循以下步骤,快速开始构建和运行此代码
$ cd specfem3d_globe $ ./configure FC=ifort MPIFC=mpiifort CC=icc CXX=icpc FCFLAGS="-O3 -xMIC-AVX512 -qopenmp" $ cp EXAMPLES/small_benchmark_run_to_test_more_complex_Earth/Par_file DATA $ make -j 8 xcreate_header_file xmeshfem3D xspecfem3D $ cd EXAMPLES/small_benchmark_run_to_test_more_complex_Earth $ ./run_this_example.sh
注释
- 从https://geodynamics.org/cig/software/specfem3d_globe/下载SPECFEM3D_GLOBE。
- 正在执行的测试基准是EXAMPLES目录中的
small_benchmark_run_to_test_more_complex_Earth。 - 此构建使用了Intel®编译器和MPI库。因此,配置选项为‘icc’、‘icpc’、‘ifort’和‘mpiifort’。
- 构建/运行机器包含Intel Xeon Phi(Knights Landing)处理器,因此使用了编译器标志‘-xMIC-AVX512’。
- ‘-qopenmp’标志将程序包构建为启用OpenMP线程。
- 求解器代码的性能是通过模拟给定网格体积的“n”个时间步所花费的时间来衡量的。
- 在SPECFEM3D_GLOBE文档中可以找到编辑模型分辨率、参数和MPI进程数量的步骤。
假设求解器已成功运行,我们需要知道它是否高效执行,充分利用了可用资源。运行时执行的剖析将让我们一窥求解器代码中各种子程序所花费的时间。我们可以跨多个集群节点收集此类剖析,以监控MPI行为以及每个节点的执行统计信息。像Intel® MPI Performance Snapshot和Intel® Trace Analyzer and Collector这样的工具具有收集MPI执行剖析的功能。此外,还可以使用Intel® VTune™ Amplifier和Intel® Advisor收集单节点剖析。SPECFEM3D_ GLOBE凭借其异步MPI通信/计算重叠,具有出色的MPI可伸缩性,因此我们的重点将放在节点内应用程序剖析和优化上。
使用Intel VTune Amplifier收集的通用探索剖析显示,此代码是后端绑定的,进一步的分类显示它存在内存(DRAM)延迟问题。通用探索的摘要视图显示在图1中。深入到热点再到源代码,会得到图2所示的剖析。在compute_element_iso子程序中访问的etax数组的维度为125 x N。INDEX_IJK从1递增到125,而索引ispec是任意的——因此是间接访问。Intel Advisor等工具可以提供有关此访问的随机性以及代码的向量化(编译器生成)的见解。图3显示了此类剖析。


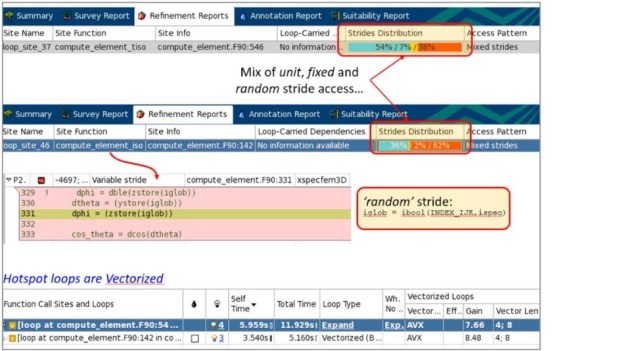
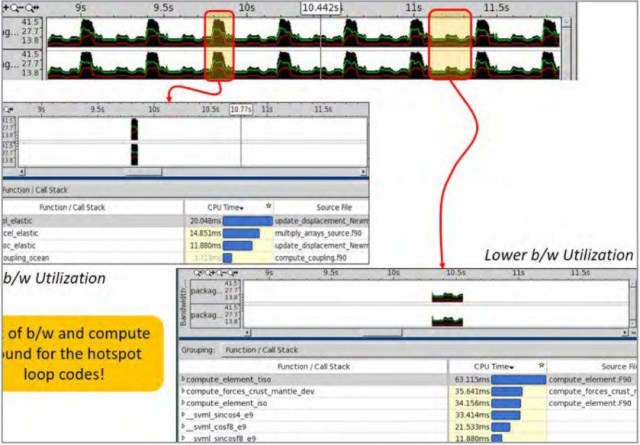
Intel Advisor显示内存访问步长信息——包括它们是单元步长、随机步长还是固定步长——以及它们的分布。此外,它还提供有关编译器代码生成、循环执行使用的向量长度、指令集和向量化增益的信息。此剖析有助于确定应用程序是否受益于处理器的向量功能和较新指令。有时,编译器可能会对循环进行向量化以利用处理器的完整向量宽度(例如,AVX-512*),但未观察到循环执行速度的相应提升。一个原因是它可能受限于带宽。Intel VTune Amplifier允许进行此类剖析(图4)。重要的是要理解,对带宽受限(高利用率)的循环进行优化以提高向量性能的效果将不那么显著。低带宽利用率的循环和代码区域可能正在执行非向量指令和/或遭受内存访问延迟问题。这需要修复。
在分析了SPECFEM3D_GLOBE的执行剖析后,我们尝试了一些代码更改,以提高在Intel®处理器上的性能。
缓解内存访问延迟问题
将间接(随机)访问转换为单元步长访问。SPECFEM3D_GLOBE求解器中的大部分网格数据在时间和求解器步长上是不变的。因此,复制数据并使其成为线性访问是有效的转换。
原始代码
subroutine compute_element_tiso(ispec,
...
c13 = 0.125_CUSTOM_REAL*cosphisq*(rhovphsq + six_eta_aniso*rhovphsq
...
初始化/启动代码
prepare_timerun (...)
...
do ispec_p = 1,num_elements
ele_num = ele_num + 1
...
ia_c1store(idx6+3,tiso_ele_num) = c13
---------------------------------------------------------------
优化代码
subroutine compute_element_tiso(ispec, ele_num, &
...
c13 = ia_c1store(idx7+3,tiso_ele_num)
...
此代码修改将所有九个数组——‘xix’、‘xiy ... gammzl’——复制到一个数组‘ia_arr’中。这将有助于缓解这些访问的带宽压力(因为只需要进行一次数组访问,而不是九次),但向量化友好性会降低(因为每个数组的元素不是连续的)。在带宽压力不是主要问题的 cases 中,用户可以创建九个对应于原始代码的数组,以获得向量化优势。最佳选项必须通过实验确定。
编译器向量化/循环分解
计算循环‘iso’和‘tiso’非常大。编译器无法对这些循环进行向量化。因此,进行了手动循环分解。通过使用Intel®编译器支持的‘!DIR$ DISTRIBUTE POINT’语法进行循环分配/分解,可以实现类似的效果。
数据对齐/填充
计算循环‘iso’和‘tiso’为网格中的每个元素调用,并从MPI区域或线程区域调用。这些循环的迭代次数为125。由于循环中访问的数组的维度为125 x N,因此应用于此代码的另一项优化是将其对齐到2n边界。应用了三个元素的填充,使其成为一个128 x N的数组。
原始代码
subroutine compute_element_tiso(ispec, ... c13 = 0.125_CUSTOM_REAL*cosphisq*(rhovphsq + six_eta_aniso*rhovphsq ...
优化代码
prepare_timerun (...)
...
do ispec_p = 1,num_elements
ele_num = ele_num + 1
...
ia_c1store(idx6+3,tiso_ele_num) = c13
---------------------------------------------------------------
subroutine compute_element_tiso(ispec, ele_num, &
...
c13 = ia_c1store(idx7+3,tiso_ele_num)
...
用查找表替换冗余计算
‘tiso’循环中的一些计算会调用超越函数。这些计算对于求解器执行时间步来说是不变的。可以使用查找表替换它们。
IVDEP或SIMD指令
SPECFEM3D_GLOBE求解器中的一些热点是具有迭代次数5 x 5和5 x 25的嵌套循环。这些是‘m x m’矩阵-矩阵乘法。编译器优化报告(使用-qopt-report标志)表明并非所有这些循环都已向量化。使用IVDEP或SIMD指令帮助编译器为这些循环生成向量代码。总之,一些简单的代码更改(和数据转换)使SPECFEM3D_GLOBE求解器在基于Intel Xeon Phi处理器的系统上的性能提高了约2.1倍。仍有进一步优化的空间——并且正在探索中。
使用的配置和工具
- Intel Parallel Studio XE 2017
- 配备Intel Xeon Phi 7250处理器、96GB DDR内存的自启动系统
- Intel Xeon Phi处理器上的MCDRAM配置为FLAT模式。QUAD模式下的网格互连
- 操作系统版本:CentOS* Linux* release 7.3.1611 (kernel 3.10.0-514.10.2.el7.x86_64, glibc 2.17-157.el7_3.1.x86_64)
参考文献
- SPECFEM3D_GLOBE: Komatitsch and Tromp 1999; Komatitsch and Vilotte (1998): https://geodynamics.org/cig/software/specfem3d_globe/
- Intel软件工具/手册:https://software.intel.com/en-us/intel-parallel-studio-xe
- Intel® 64 和 IA-32 架构软件开发人员手册:https://software.intel.com/en-us/articles/intel-sdm
- Ahmad Yasin。“A Top-Down Method for Performance Analysis and Counters Architecture." IEEE Xplore: 2014年6月26日。电子ISBN:978-1-4799-3606-9。