
清理 Pandas DataFrame 中的数据
在本系列关于使用 Python 和 Pandas 进行数据清洗的第五部分中,我们将进行最后一次清理数据集的操作,然后进行重塑。

引言
本文是《使用 Python 和 Pandas 进行数据清洗》系列的一部分。其目标是帮助开发人员快速上手数据科学工具和技术。
如果您想查看该系列中的其他文章,可以在此处找到它们。
- 第一部分 - Jupyter 和 Pandas 入门
- 第二部分 - 将 CSV 和 SQL 数据加载到 Pandas 中
- 第三部分 - 在 Pandas 中更正缺失数据
- 第四部分 - 在 Pandas 中合并多个数据集
- 第五部分 - 在 Pandas DataFrame 中清理数据
- 第六部分 - 在 Pandas DataFrame 中重塑数据
- 第七部分 - 使用 Seaborn 和 Pandas 进行数据可视化
现在我们拥有一个包含所有合并的客户、产品和购买数据的大型 DataFrame,我们将最后一次清理数据集,然后进行重塑。
请注意,我们已经创建了一个完整的 Jupyter Notebook,其中包含本系列模块的源数据文件,您可以在本地下载并安装。
我们当前的数据集不包含任何缺失值,但它可能仍然包含没有意义或不是正确数据类型的值。让我们看看一些查找和清理这类数据的方法。
清理键
通过将三个数据集合并到我们的 DataFrame 中,我们在数据集本身周围存在一些不一致之处。为了纠正这一点,让我们删除一些重复的键并重命名其他一些键。
首先,让我们启动一个新的代码块,并通过使用以下内容删除重复的标识符
combinedData.drop(columns='customer_num', inplace=True)
combinedData.drop(columns='product_num', inplace=True)

这将删除 customer_num 和 product_num 列。
Pandas 也可以重命名列,所以让我们将三个“id”列重命名为更具代表性的名称
combinedData = combinedData.rename(columns={'id_x':'purchase_id', 'id_y':'customer_id','id':'product_id'})
这将把列 ID 重命名为其对应的源,并极大地清理我们的表格。
查找不一致的数据
数据不匹配的另一个主要原因是查找字段中包含与其键的意图不一致的数据。例如,您可能将字符串值与数字混合在一起。让我们检查我们的数据集,看看是否存在任何相关问题。
创建一个新的代码块,并使用我们在开始时看到的命令
print(combinedData.dtypes)
print(combinedData.head(2))
结果如下

正如您从结果中看到的那样,大部分数据已被泛化为对象,只有少数键被归类为数字 (int64)。
让我们尝试将我们的 purch_date 键转换为日期时间,看看是否会出现任何问题。
to_datetime方法尝试将值转换为日期时间类型to_to_numeric方法尝试将值转换为数字类型value_counts方法计算不同值的数量str.replace方法在字符串内应用替换字符
将上面的代码块更改为以下内容
print(pd.to_datetime(combinedData['purch_date'], errors='coerce').isnull().value_counts())

此代码块现在尝试转换 purch_date 列中的所有值,并计算发生了多少错误 (True) 或成功 (False)。幸运的是,这次我们没有错误(第一个和第二个数字匹配)。
让我们扩展此代码块以检查数字和货币键
print(pd.to_numeric(combinedData['amount'], errors='coerce').isnull().value_counts()) print(pd.to_numeric(combinedData['paid'], errors='coerce').isnull().value_counts()) print(pd.to_numeric(combinedData['cost'], errors='coerce').isnull().value_counts())
结果如下:

如果我们现在查看这些数字,在所有 paid 和 cost 错误中,还有两个 amount 值也是错误。 cost 和 paid 列应该很容易修复,因为 Pandas 不处理使用美元符号 ($) 编写的货币值。我们将通过从这两个 amount 键中删除所有美元符号来修复这个问题,使用以下方法
combinedData.paid = combinedData['paid'].str.replace('$','')
combinedData.cost = combinedData['cost'].str.replace('$','')
结果如下:

当我们运行此清理,然后进行检查时,cost 错误已修复,但 paid 键仍然有大量错误。
让我们通过将测试更改为引发错误来查找导致错误的值。我们将使用以下方法
print(pd.to_numeric(combinedData['paid'], errors='raise'))
结果如下:

看起来我们的值也包含千位标记的逗号分隔符,所以我们也将摆脱它们
combinedData.paid = combinedData['paid'].str.replace(',','')
combinedData.cost = combinedData['cost'].str.replace(',','')
这很容易

现在,当我们运行此清理阶段时,我们只剩下两个错误。
让我们将 amount 更改为引发错误,看看问题是什么。
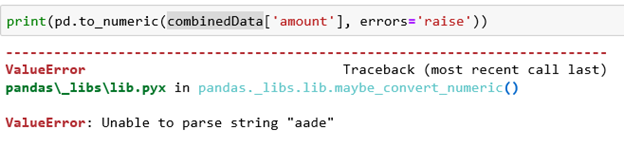
看起来一个字符串已经滑入了其中的两行。由于这个数字很小,我们只需将所有键转换为正确的类型,并删除所有具有空值的行,这些行应该只有两行。
让我们修改我们的代码,这样我们就有了下面的最终结果
combinedData.paid = combinedData['paid'].str.replace('$','')
combinedData.cost = combinedData['cost'].str.replace('$','')
combinedData.paid = combinedData['paid'].str.replace(',','')
combinedData.cost = combinedData['cost'].str.replace(',','')
combinedData.purch_date = pd.to_datetime(combinedData['purch_date'], errors='coerce')
combinedData.amount = pd.to_numeric(combinedData['amount'], errors='coerce')
combinedData.paid = pd.to_numeric(combinedData['paid'], errors='coerce')
combinedData.cost = pd.to_numeric(combinedData['cost'], errors='coerce')
combinedData.dropna(subset = ['amount'], inplace=True)
print(combinedData.isnull().sum())
print(combinedData.shape)
print(combinedData.dtypes)
结果如下:

现在我们有了最终结果:5,067 行已清理的数据,并具有正确分配的类型。
摘要
我们遍历了数据集的一些最终迭代,并从我们的值中清除了剩余的不一致之处。我们还确保我们的数据集具有正确分配的值类型,并形成了一个完整的画面。
接下来,我们将看到如何重塑我们的数据,以便为可视化做好准备。
标题图片来源:https://medium.com/cracking-the-data-science-interview/an-introduction-to-big-data-data-cleaning-a238725a9b2d