
使用 Create ML 和 Core ML 构建用于 iOS 的 AI 图像分类应用
5.00/5 (5投票s)
在本文中,我们将使用 Apple 的 Create ML 来训练我们自定义的热狗检测模型。
引言
深度神经网络在图像分类等任务中表现出色。过去需要花费数百万美元和一支研究团队十年的成果,现在任何人只要有一台还不错的 GPU 就能轻松获得。然而,深度神经网络也有缺点。它们可能非常庞大且运行缓慢,因此并不总能在移动设备上良好运行。幸运的是,Core ML 提供了一个解决方案:它使您能够创建能在 iOS 设备上运行的精简模型。
在本系列文章中,我们将向您展示两种使用 Core ML 的方法。首先,您将学习如何将预训练的图像分类器模型转换为 Core ML 模型,并在 iOS 应用中使用它。然后,您将训练自己的机器学习 (ML) 模型,并使用它来制作一个 Not Hotdog 应用——就像您在 HBO 的《硅谷》中可能看到的那样。
有了上一篇文章中下载的图像,我们就可以使用 Apple 的 Create ML 来训练我们自定义的热狗检测模型。
创建您的 ML 项目
要开始一个新的 Create ML 项目,请选择 Xcode > 打开开发者工具 > Create ML。

选择一个项目文件夹,然后单击 新建文稿。

选择 图像分类器,然后单击 下一步。
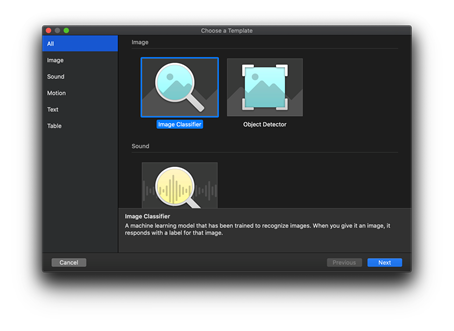
输入您模型的项目描述,然后单击 下一步。

确认您的项目位置,然后单击 创建。

您的项目已准备就绪。

配置训练数据
现在是时候配置训练数据了。对于图像分类模型,Create ML 要求将图像分组到与它们的标签对应的文件夹中。
● dataset_root:
● class_1_label:
● image_1
● image_2
● (…)
● image_n
● class_2_label:
● image_n + 1
● image_n + 2
● (…)
● image_n + m
● (…)
由于这正是我们在上一篇文章中下载图像的方式,因此无需额外准备。
在 训练数据 部分,选择 选择 > 选择文件。

找到包含您图像的数据集。

确保选中了数据集的根文件夹,然后单击 打开。
Create ML 应能正确检测到 157 张图像,分为 2 个类别。
增强训练图像
训练前的最后一个要配置的参数是最大迭代次数(默认为 25)和数据增强。
增强过程会引入图像的随机变化,从而增加训练数据集的大小和多样性。在训练模型进行图像分类时,我们希望模型能够正常工作,而不管图像质量、方向、对象的确切位置等。虽然增强通常有帮助,但我们不应过度使用它。请注意,每个选定的选项都会使训练数据集的大小呈指数级增长,但只有有限的新信息可以改进模型。
即使我们的数据集很小,选择多个增强选项也可能大大增加训练时间(从不到两分钟到数小时),并且对模型性能的影响不确定。让我们谨慎使用增强。

训练您的模型
设置好所有选项后,您可以单击窗口顶部的 训练 按钮……然后休息一下。根据图像数量、选定的增强选项以及您使用的硬件,该过程可能需要几分钟到几个小时。
过程的第一步是 *特征提取*。从技术上讲,这是一个预测会话,其中每张图像都由现有的、预先训练的 VisionFeaturePrint 模型处理,以生成一个 2048 元素输出向量。该向量代表描述基本和复杂元素的抽象特征。
只有在为所有图像生成特征后,实际训练才会开始。
使用选定的配置,在我们机器上的过程持续了一分钟多一点。

结果看起来不错吧?训练数据集的准确率和召回率都远高于 90%,验证数据集的准确率和召回率都远高于 80%。考虑到图像数量很少且训练时间很短,没有什么可抱怨的。图像数量很少是否意味着验证数据集不够具代表性?
与其猜测和担忧,不如让我们看看我们的模型在实际生活中是如何工作的。
运行预测
单击右上角的 输出 单元格。使用左下角的 + 按钮,或将图像拖放到左列。

模型会生成预测。以下是一些对未包含在训练数据集中的 Google Open Images Dataset 图像的预测。

到目前为止一切顺利。现在让我们尝试一些棘手的。

嗯,我们的模型毕竟不是完美的——我们用一个汉堡把它骗了。
解决这个问题最明显的方法是将一些汉堡图片添加到“其他”类别中并重复训练。但这可能还不够,尤其是在数据集不平衡的情况下——我们的“其他”对象比“热狗”多得多。无论如何,如果模型性能不可接受,则需要进行更多的数据处理。(请记住,100% 的预测准确率几乎是不可能达到的目标!)
Create ML 模型内部是什么?
我们使用 Create ML 训练的分类模型一个有趣之处在于它的尺寸。它非常非常小(17 KB,而我们之前讨论过的模型的尺寸为 20-200 MB)。
让我们一窥模型的内部,找出它是如何保持如此紧凑,同时又产生合理的结果的。一个很好的工具是 Netron。

乍一看,它看起来不像 CNN 或任何其他神经网络。
秘密在于 visionFeaturePrint 块。这不仅仅是一个简单的“层”。这个块代表了 Apple 提供的一个完整的 CNN 模型。正是这个模型在我们 Create ML 训练的第一步中用于特征提取。
接下来的块是 glmClassifier(一个广义线性模型),它由 Create ML 训练来为固定向量分配标签。从技术上讲,这意味着我们训练的模型部分根本不是神经网络!
热狗或非热狗 1.0
现在我们有了一个自定义 ML 模型,可以在我们的 iOS 应用程序中使用。要做到这一点,只需将模型的输出从 Create ML 拖到 Xcode,这与我们之前使用 ResNet 模型所做的非常相似。

有了这个模型以及对本系列 之前使用的示例 iOS 应用 进行的一些 косметические 更改,我们终于可以交付“热狗或非热狗”iOS 应用了。看看它是如何处理来自 Google Open Image Dataset 的图像的。
欢迎您查看下载附件中的应用代码。

摘要
就这样吗?远未结束——第一个迭代永远不是最后一个。凭借新获得的知识,您可以回到训练数据集的选择和准备。然后您可能需要获取反映您应用“真实世界”使用场景的新图像……然后您可能会调整训练参数……等等。
但这将是下一篇文章的主题。
现在,让我们为构建一个功能齐全的“热狗或非热狗”iOS 应用程序以及一个自定义图像分类模型而为自己鼓掌。我们使用的工具帮助我们构建了一个像 HBO《硅谷》系列中的 Jian Yang 那样的应用程序。
近十年来,ML 的进步是惊人的。现在,您可以在口袋里装下那些“昨天”还需要强大工作站才能运行的模型。您不仅可以使用这些模型,还可以训练它们,有时只需要一台简单的笔记本电脑。并且可以轻松访问云(包括免费的 Google Colab 资源),您可以走得更远。
希望您喜欢这个系列。如果您有任何问题,请在评论区留言——我们将尽力回答。