
用 AI 和 PyBullet 环境教机器人走路
5.00/5 (1投票)
在本文中,我们将研究PyBullet提供的两个较简单的运动环境,并训练智能体来解决这些环境。
引言
在上一篇文章中,我们使用Bullet物理模拟器作为进行连续控制环境强化学习的基础。最简单的入门方法是使用我们从之前一系列文章中已经熟悉的基石RL环境:Cartpole(倒立摆)。
然而,PyBullet 提供了更多环境。在这一系列的大部分内容中,我们将教一个类人机器人如何行走,但首先值得先了解其他两个环境:Hopper(跳跃者)和Ant(蚂蚁)。
Hopper(跳跃者)
Hopper环境非常有趣:它代表一条单独的脱离身体的腿。目标是训练一个策略,使腿尽可能快地跳跃。
让我们看看这个环境有多复杂。
>>> import gym
>>> import pybullet_envs
>>> env = gym.make('HopperBulletEnv-v0')
>>> env.observation_space
Box(15,)
>>> env.action_space
Box(3,)
我们再次处于连续空间,观察和动作都位于连续空间中。这一次,两者都更复杂。观察空间有15个维度,而CartPole只有四个;动作空间有三个维度,而CartPole只有一维。
代码
这是我用于在Hopper环境中用SAC进行训练的代码。
import pyvirtualdisplay
_display = pyvirtualdisplay.Display(visible=False, size=(1400, 900))
_ = _display.start()
import ray
from ray import tune
from ray.rllib.agents.sac import SACTrainer
import pybullet_envs
ray.shutdown()
ray.init(include_webui=False, ignore_reinit_error=True)
ENV = 'HopperBulletEnv-v0'
import gym
from ray.tune.registry import register_env
def make_env(env_config):
import pybullet_envs
return gym.make(ENV)
register_env(ENV, make_env)
TARGET_REWARD = 6000
TRAINER = SACTrainer
tune.run(
TRAINER,
stop={"episode_reward_mean": TARGET_REWARD},
config={
"env": ENV,
"num_workers": 7,
"num_gpus": 1,
"monitor": True,
"evaluation_num_episodes": 50,
}
)
图
我在22.6小时后终止了训练过程。学习进度如下所示

视频
最后一次进度快照的视频如下所示,显示智能体已经学会了很好地跳跃。

Ant(蚂蚁)
蜘蛛有八条腿,昆虫有六条腿,但PyBullet蚂蚁智能体只有四条腿。在Ant环境中,我们必须训练一个简单的四足生物以高速奔跑,而不会摔倒。
再次,让我们在开始训练之前检查一下环境。
>>> import gym
>>> import pybullet_envs
>>> env = gym.make(AntBulletEnv-v0')
>>> env.observation_space
Box(28,)
>>> env.action_space
Box(8,)
这代表着维度的另一个提升:观察空间从15个增加到28个,动作空间从三个增加到八个。一个四足蚂蚁比单条腿更复杂,这并不令人惊讶。
代码
因为这是另一个简单的环境,我们可以直接更改代码中指定的环境,而无需调整任何学习参数
ENV = 'AntBulletEnv-v0'
图
我又在25.8小时后终止了该过程。你可能更喜欢将TARGET_REWARD设置为3000。
学习进度如下所示
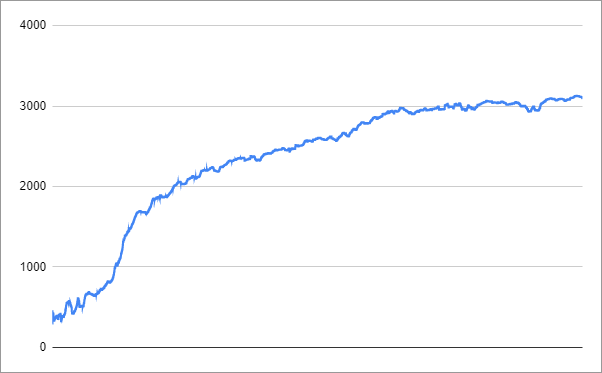
视频
这是最终快照的视频。智能体取得了快速的进展,似乎没有太多东西需要学习了。

下次
本系列文章的其余部分将重点关注PyBullet提供的另一个更复杂的环境:Humanoid(类人),我们需要训练一个类似人类的智能体用两条腿行走。我们从下一篇文章开始,使用近端策略优化(PPO)算法。