
关于 U++ 框架的一些你可能不想知道的惊人事实……
……但我还是要告诉你。
目录
- 被认为有害
- 如果会痛,就别做
- 爱情、战争和 C++ 优化中一切公平
- 禁果
- 为 C++ 增添风味
- 明确
- 让我们索引它
- 人人皆可随机访问
- 语法糖果店++
- GUI 控件的生与死
- Lambda 时代
- 关于值的重要性
- 关于“无”
- 买一送一
- 共同利益
- 足智多谋的 C++
- 对话框模板就是……模板
- TheIDE
- BLITZ 构建
- 结局好一切都好
- 有用链接
- 历史
被认为有害
内存泄漏!悬空指针! 缓冲区溢出!
C++ 是一种可怕的语言,不是吗?
然而,大量现代顶级应用程序都用 C++ 编写,因为它的优点超过了所谓的缺点。
但这些问题确实存在,并影响着生产力和可靠性。如果你仔细思考,可以将其归结为
- 每个 new 语句都是发生内存泄漏的机会。
- 每个 delete 语句或指针赋值都是发生悬空指针的机会。
- 每次指针算术都是发生缓冲区溢出的机会。
那么让我们听听 U++ 对此有何看法
如果会痛,就别做
在 U++ 中,`new` 和 `delete` 语句被认为是不安全的。它们当然有时仍然需要,但通常只在实现层面。接口严格避免传递任何原始堆数据,堆应该只是实现细节。
在应用程序层面,几乎所有的堆管理都由析构函数和容器提供。
指针算术是一个更难解决的问题。U++ 的部分解决方案是为所有 U++ 容器提供 `operator[]`,这将指针算术问题转化为索引算术。尽管如此,索引算术通常更容易表达、检查和调试(至少我更喜欢知道我在索引 5 而不是在位置 0xac34bef)。此外,索引永不失效,不像 `std::vector` 的迭代器(这只是悬空指针问题的另一种变体)。
在实践中,这种编程风格不仅更安全,而且通过其他技巧可以产生更紧凑、更简单的代码。数千行的 U++ 应用程序代码完全干净,没有任何 `new`/`delete` 语句和指针算术,甚至通常连指针也没有,这非常常见。
爱情、战争和 C++ 优化中一切公平
C++ 在其核心性能方面是一门很棒的语言。然而,每次将其与例如 Java 进行比较时,结果都不太令人满意。对我们来说,这种羞辱是不可原谅的。
事实上,很快就能找到罪魁祸首:它就是所谓的“C++ 标准库”。
一个问题是大多数实现都缺乏优化,这也许可以解决。无法解决的是 C++ 标准库的定义方式,只能通过特定的实现来满足,而这种实现并非总是最佳的。
以 `std::map` 为例。如果你阅读文档,你会发现一些细则:“没有迭代器或引用失效”。如果使用节点二叉树实现 `std::map`,这看起来很合理。不幸的是,与例如 B 树相比,这种实现可能缺乏性能,因为 B 树无法满足此保证。现在问自己:上次不使 `std::map` 项的引用失效解决了你代码中任何重要问题是什么时候?真的值得为此牺牲性能吗?
禁果
很早以前,我们和一些非常聪明的人就发现,有一组重要的类型即使 C++ 标准不允许(它们不是 POD),也可以使用普通的 `memcpy` 在内存中移动。许多复杂而有用的值类型都可以通过这种方式轻松构建,包括一个非常重要的类型 `String`。
这为什么重要?嗯,对于大多数用途来说,最有效的数据结构是动态数组,例如 `std::vector`。事实上,它如此高效和多功能,以至于大多数 U++ 容器都以一种或另一种形式是动态数组。
动态数组在改变容量时需要移动其内容,即使 C++11 引入了移动构造函数,`memcpy` 也是完成此任务的更快方式。此外,虽然在中间插入/删除元素的复杂度为 O(n),但它仍然非常有用,并且使用 `memmove` 执行此任务可以轻松地将操作速度提高 5 倍。
我们认为这种速度提升确实值得付出努力。实际上,是相当多的努力。
我们创建了一个 `Vector` 类,它以要求的形式规定:它只能存储可以通过 `memcpy` 在内存中移动的元素,别无其他。但这意味我们不能使用 C++ 标准库的现有基础设施。例如,我们绝对不能将 `std::string` 存储到 `Upp::Vector` 中,因为我们无法保证其内部工作原理。但别担心,这并没有损失任何爱:我们借此机会优化了一切,例如 `Upp::String` 比 `std::string` 快得多。
细则:类型可以通过 memcpy 在内存中移动(并存储在 Vector 中)的要求是:它没有虚方法,其任何方法都不将其成员变量的任何引用存储到非局部变量中,并且其所有成员变量都满足相同的要求。
为 C++ 增添风味
那么,如果 `Upp::Vector` 在可以存储的元素类型上相当有限,我们应该如何处理那些不符合的类型呢?
嗯,请看 `Array`。它在实现上等同于 `std::vector
Array<Stream> input_files;
FileIn& f = input_files.Create<FileIn>(); // add a new FileIn Stream instance
上述代码演示了 U++ 设计的另一个基石:就地创建。与其在堆上创建对象实例并将其添加到容器中,更优选的方法是直接在容器中创建实例。这避免了对对象所有权的任何混淆——始终是容器拥有它。(是的,我很清楚 `std::emplace` 方法,而且它就是同一回事。区别在于强调,在 U++ 中,就地创建总是首先要考虑的。)
通过 `Array` / `Vector` 的二分法,U++ 实际上解决了两个重要问题:使用 `Vector` 获得性能,以及使用 `Array` 避免手动堆管理和大量指针。
这个想法并不仅限于 `Array` / `Vector`,所有相关的 U++ 容器都提供这两种风格,因此有类似队列的容器 `BiVector` 和 `BiArray`,映射 `VectorMap` 和 `ArrayMap` 等等。
明确
在某些情况下,容器的内容必须移动到其他地方。就像 C++ 11 以来标准库容器一样,U++ 中也有两种选择——你可以复制内容,或者移动它(`std::move`),移动后源容器为空。
然而,与 `std::` 容器不同,U++ 容器即使在可用的情况下也支持“默认”复制。你可以这样做
std::vector<int> x, y;
....
x = y;
但是,你可能会意外地执行耗时的复制操作,即使你实际需要的是移动数据。
这就是为什么 U++ 要求你在传输容器内容时必须清楚地声明自己
Vector<int> x, y;
....
x = clone(y); // y content is duplicated into x, original content is retained
x = pick(y); // y content is moved into x, y is now empty, synonym for std::move
x = y; // compile time error
实际上,你总是可以指望容器有 `pick` 操作,而 `clone` 只有在元素支持它时才可用。
让我们索引它
U++ 关联容器基于一个不寻常的概念:`Index` 容器。
你可以把 `Index` 看作是一个动态数组,类似于 `Upp::Vector` 或 `std::vector`,但有一个疯狂的特点。
它有一个 `Find` 方法,返回具有给定值的元素的索引。
Index<int> n;
n.Add(21); // n[0]
n.Add(31); // n[1]
n.Add(12); // n[2]
n.Add(31); // n[3]
int i = n.Find(31); // i is now 1
i = n.FindNext(i); // finds the next element with the same value, i is now 3
i = n.Find(5); // i is now -1 to signal 'not found'
Index 使用哈希来实现这一点,所以 Find 操作实际上非常快(比 std::map 快 5-10 倍)。
Index 可以提供与 std::set 或 std::multi_set 类似的服务,但返回索引的能力还有许多其他用途。主要的例子是 U++ 中键值映射的实现:VectorMap 和 ArrayMap 只是键的 Index 和值的 Vector 或 Array 之上的一层薄薄的接口。
人人皆可随机访问
通过使用 `Index` 方法来处理关联容器,另一个有趣的思路变得可能。
所有重要的容器现在都可以随机访问,这意味着它们总是具有 `operator[](int i)` 来访问带有索引的元素。
这很好,因为现实世界的问题通常也是“随机寻址”的:想想现实世界的例子,如表格(单元格有行/列坐标)或文本(文本中从开头算起的位置,行号)。
这也使得大多数时候可以避免使用迭代器。由于迭代器是指针的一种形式,而迭代是一种指针算术,这提高了可靠性。
语法糖果店++
C++ 有运算符重载。这是一件好事,这取决于你问谁。U++ 毫不犹豫地使用它。更糟糕的是:U++ 毫不犹豫地在有机会使代码更简单和/或更具可读性时,实际上滥用它。
你会喜欢它还是讨厌它,取决于你是更喜欢这样从 C++ 发出 SQL 语句
// This is not U++, but some other framework...
SqlQuery query;
query.prepare("INSERT INTO employee (id, name, salary) "
"VALUES (:id, :name, :salary)");
query.bindValue(":id", 1004);
query.bindValue(":name", "John Smith");
query.bindValue(":salary", 64000);
query.exec();
还是你会接受这样
// The same thing in U++
SQL * Insert(EMPLOYEE)(ID, 1004)(NAME, "John Smith")(SALARY, 64000);
如果您无法忍受大量的运算符重载,并且更喜欢第一个版本,那么很抱歉浪费了您的时间,这个疯狂的框架不适合您。
对我们其他人来说,这里的运算符重载增加了 SQL 语句的编译时检查,使代码更短更简洁,使 SQL 注入攻击成为不可能,甚至消除了不同 SQL 引擎之间的方言差异。我想这比对运算符重载的不安感觉更值得。
另外,我们也喜欢 `operator<<` 作为“追加”的含义,并且认为它没有理由只适用于流。
Vector<int> x;
String s;
x << 1 << 2 << 3;
s << "And the values in the container are: " << x;
除此之外,我们还为这里的一些运算符赋予了新的含义,例如
EditString edit; // this is GUI widget
edit <<= "Hello"; // <<= can be used to assign a value to widget
String s = ~edit; // operator~ can be used to read the actual value of widget
另一种常用的语法糖是方法链,其中方法返回 `*this` 而不是 `void`——这对于设置小部件非常有用。
EditString x;
TopWindow win;
win << x.SetFont(Serif(20))
.SetColor(LtCyan())
.SetFilter([](int c) { return ToUpper(c); })
.HSizePos().TopPos(10);
简洁紧凑,对吧?
GUI 控件的生与死
所有主要的 GUI 工具包的普遍智慧是,GUI 控件(例如,编辑器字段)必须在堆上分配,然后插入到其父级(例如,主窗口)中,然后父级成为所有者:当父级被销毁时,它会删除其子级。
在 U++ 中,控件完全由客户端代码拥有。它们通常以局部变量或成员变量的形式简单地创建,并在超出作用域时通过正常的析构函数销毁。
将控件添加到父级只是意味着父级知道该控件并开始在 GUI 中显示它。如果父级在控件之前被销毁,则不会发生任何严重的事情,控件再次成为无父级。如果控件在父级之前被销毁,则控件从父级中移除,如果父级当时显示在屏幕上,则控件简单地消失。
一个最小的 U++ 示例,演示带子控件的父窗口,代码如下:
GUI_APP_MAIN
{
TopWindow win; // top-level frame window
LineEdit x; // multiline editor widget
x.SizePos(); // fill the whole client area of the parent
win << x; // tell win a new widget considers it a parent
win.Run(); // window opens and runs until closed
}
除了父控件不拥有其子控件之外,GUI 也不拥有任何窗口。所有控件都独立于它们是否在 GUI 中处于活动状态而存在。
Lambda 时代
每一个 C/C++ GUI 框架似乎都在为一个相对简单的问题而苦恼:当用户按下按钮(或执行其他值得注意的操作)时,如何将此操作报告给客户端代码?
解决方案从坏到更坏。旧的框架通常会将一些整数事件 ID 分配给操作,并将其传递给父级的一些虚方法。许多甚至发明了相对丑陋的消息映射概念。其他人则声称 C++ 不值得拥有如此复杂的概念,并引入了语言扩展和预处理器。
与此同时,至少自 C++98 兼容编译器出现以来,一个微不足道的解决方案就成为可能,它可以支持完整的可调用对象抽象(例如 `boost::function`,后来成为 `std::function`),因为这里真正需要的只是表示客户端操作的代码,别无他物。
当然,从 C++11 开始,有了 lambda,情况就更好了。从那时起,整个按钮问题就简化为
GUI_APP_MAIN
{
TopWindow win;
Button b;
b.SetLabel("Press me!");
b << [] { Exclamation("Ouch!"); };
win << b.VCenterPos().HCenterPos();
win.Run();
}
有了 lambda,你现在可以编写非常复杂的应用程序,甚至无需定义单个类、方法或函数。
GUI_APP_MAIN
{
ArrayCtrl list;
list.NoHeader().AddColumn();
list.WhenBar = [&](Bar& bar) { // assign the context menu to list, menu in U++ is callable
bar.Add("Add..", [&] { // menu entry and the code that should run if selected
String s;
if(EditText(s, "Add", "Text"))
list.Add(s);
});
};
TopWindow win;
win << list.SizePos();
win.SetRect(0, 0, 800, 400);
win.Title("A little demo of U++ events").Run();
}

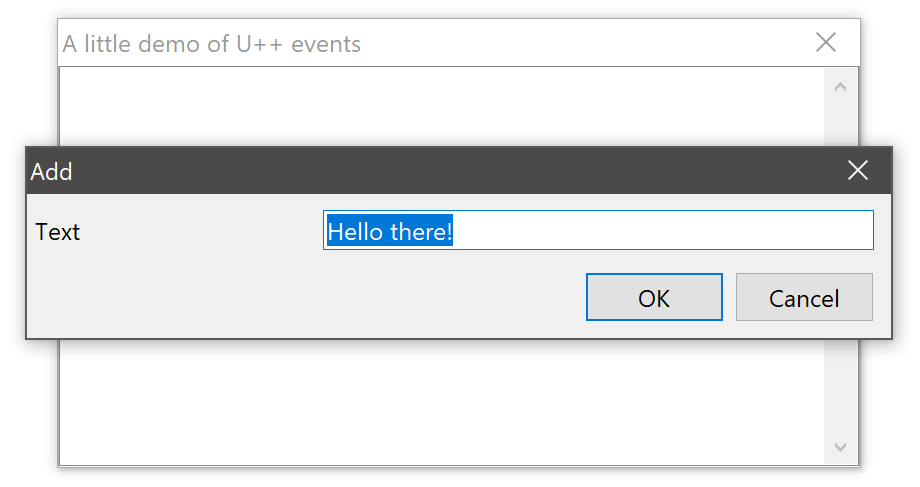

关于值的重要性
C++ 是静态类型语言,我们喜欢它。但看看这个对话框

这里有四个带有自然“值”的控件:第一个是 `String`,第二个是 `double`,第三个是 `Date`,那个选项是 `bool`。如果我们想在控件的基类接口中有一个单一的虚方法接口,允许我们以统一的方式处理控件值,该怎么办?是的,你猜对了,我们需要某种类型,可以存储 `String` 或 `double` 或……
现在你可能会说这是一个特殊情况,并引入一些有限的类型来处理一些 GUI 控件。
但我说:这很重要,这个问题随处可见!想想 JSON。想想 SQL。想想随处可见!
这就是为什么我们投入了大量精力来开发和优化 `Value` 类型。这种类型旨在能够存储任何类型的值,甚至是 `Value` 数组和 `Value` 到 `Value` 的映射。所有相关的 U++ 类型都被创建为“`Value`”兼容的,它们具有与 `Value` 之间的隐式转换。
我所说的“所有”是指:`int`、`double`、`int64`、`bool`、`String`、`Date`、`Time`、`Complex`、`Color`、`Uuid`、`Point`、`Size`、`Rect`、`Pointf`、`Sizef`、`Rectf`、`Font`、`Drawing`、`Painting`、`Image`。这几乎是 U++ 所有正常的 Value 类型,但 `Value` 也被设计为可扩展的:你可以非常容易地使你自己的类型与 `Value` 兼容。
并非偶然,Value 是 JSON 数据模型的超集,这使得
Value v = ParseJSON(R"--(
{ "items" : [ 1, 2, 3 ] }
)--");
int x = v["items"][1]; // x is now 2
为所有动态值拥有单一的 `Value` 类型,可以在 U++ 的各个部分之间产生良好的协同效应。例如,考虑像这样将 SQL 与 GUI 混合使用:
EditDate d;
d <<= SQL % Select(DATE_SOLD).From(SALES).Where(ID == id);
多年来,为了优化 `Value` 的内存消耗和速度,我们投入了巨大的努力。例如
Vector<Value> x;
x << String("Hello world!") << 1.23 << 123 << GetSysDate() << Point(12, 34) << Magenta();
只创建一个 96 字节的内存块。
+0 48 65 6C 6C 6F 20 77 6F 72 6C 64 21 00 00 00 0C Hello world!....
+16 AE 47 E1 7A 14 AE F3 3F 00 00 00 00 00 02 00 00 .G.z...?........
+32 7B 00 00 00 00 00 00 00 C0 81 0B 00 00 01 00 00 {...............
+48 09 0A E4 07 01 00 00 00 A8 58 14 40 00 04 00 00 .........X.@....
+64 0C 00 00 00 22 00 00 00 00 00 00 00 00 49 00 00 ...."........I..
+80 80 00 FF 00 00 00 00 00 00 00 00 00 00 27 00 00 .............'..
关于“无”
让我们再回顾一下上一节中的对话框。

现在数字字段是空的。这可能被视为用户错误,对话框可能不允许此类值(是的,U++ 中你也可以做到),但通常,这只是意味着“我不知道”或“我不在乎”,控件需要以某种方式向客户端代码发出空值信号。
再一次,我们可以通过对控件接口进行一些有限的扩展来处理这种情况,或者我们可以一劳永逸地处理这种情况。受 SQL 启发,我们引入了 `Null` 值的概念——这些是空值。
现在来说一些“脏”技巧:虽然为 `Date` 或 `Point` 等更复杂的类型引入 `Null` 相对简单,但问题在于基本类型,即 `int`、`double` 和 `int64`。这里有两种选择——创建一些新的 `Int` / `Double` / `Int64` 封装类型,并带有一个“`Null`”布尔选项,或者你可以做一些疯狂的事情。
正如你所预料的,我们选择了疯狂:我们取了这些类型的最小值,例如 `int` 的 `-2147483648`,并将其声明为 `Null`。这会将相关上下文中 `int` 值的范围缩小到 `-2147483647 .. 2147483647`,但另一方面,我们避免了为整数值使用两种不同类型。选择最小可能值在排序时具有优势,因为它最终会将 `Null` 值放在前面。
再一次,在 U++ 核心库中定义 `Null` 改善了各个模块之间的互操作性,例如
EditDate d; ... SQL * Update(SALES)(DATE_SOLD, ~d).Where(ID == id); // if d is empty, sets DATE_SOLD to null
买一送一
U++ 的另一个“搞怪”之处在于它处理二进制序列化方式。
// This is not U++, but some other framework...
struct SensorRecord {
String name;
double altitude;
double temperature;
}
DataStream& operator<<(DataStream& in, SensorRecord& m)
{
in >> m.name >> m.altitude >> m.temperature;
return out;
}
DataStream& operator<<(DataStream& out, const SensorRecord& m)
{
out << m.name << m.altitude << m.temperature;
return out;
}
如果你仔细观察,可能会发现一些东西……是的,这些函数体实际上是完全相同的!唯一的区别是其中一个有“<<”,另一个有“>>”。
我们 U++ 团队的穷苦小伙子们只思考了 20 秒,就宣布:既然可以只用一个函数,为什么要用两个呢?
// This how we do it in U++
struct SensorRecord {
String name;
double altitude;
double temperature;
void Serialize(Stream& s) { s % name % altitude % temperature; }
};
U++ 中的单个 `Serialize` 方法提供了加载和存储的配方。由于 `operator<<` 和 `operator>>` 都不适合这里,所以我们劫持了 `operator%`,它以 C++ 运算符滥用(由标准 C++ 流引入)的最佳视觉传统,某种程度上调用了操作的双向特性。
另请注意,U++ 中没有专门的 `DataStream` 类。原因在于,此类相对于 `stream` 类提供的唯一真正信息是过程的方向(加载或存储),这是一个可以在 `Stream` 基抽象类中轻松存储的单个位。除了减少一个需要担心的类之外,其优点还在于更好的优化机会,因为基本类型的 `operator%` 方法现在可以直接在 `Stream` 中定义。
然后,operator% 的通用模板将此序列化运算符提供给具有 Serialize 方法的每种类型。提供 Serialize 方法是 U++ 类(包括容器)的常见做法,这使得整个序列化业务变得微不足道。
struct SensorRecords {
Array<SensorRecord> records;
void Serialize(Stream& s) { s % records; } // Array::Serialize uses SensorRecord::Serialize
};
共同利益
Serialize 是“U++ 通用方法”的一个例子,它将类型与常见的 U++ 机制集成。还有更多这样的常见特性
class Foo : public ValueType<Foo, 323, Moveable<Foo> > {
// ValueType sets the numeric id for Value serialization of this type
// Moveable marks the type as Vector compatible
......
public:
String ToString() const; // support for operator<<
hash_t GetHashValue() const; // support for hash tables (Index)
bool IsNullInstance() const; // support for IsNull function
void Serialize(Stream& s); // binary serialization
void Jsonize(JsonIO& jio); // JSON serialization
void Xmlize(XmlIO& xio); // XML serialization
Foo(const Nuller&); // assigning Null
operator Value() const; // implicit conversion to Value
Foo(const Value& q); // implicit conversion from value
};
请注意,这与基类或虚方法(通常……)无关,这些通用方法通过各种模板使用。将这些功能作为方法提供比 C++ 标准库要求我们做的更方便。
足智多谋的 C++
有些事情最好通过键入代码来完成。但是,任何尝试在文本编辑器中创建栅格图像的人都可以告诉你,这通常是一个相当乏味的过程。因此,我们倾向于使用一些可视化设计工具来完成。

现在,当漂亮的图片设计好后,我们需要以某种方式将它们导入到应用程序中。这里,方法各不相同。
有人说最好将它们放入文件(通常是 .png),然后将这些文件放入随应用程序一起提供的文件夹中,然后添加(大量)代码将文件加载到一些内部对象中。如果你的应用程序需要超过 100 个图标,祝你好运。
其他人则使用某种形式的“资源”文件,该文件为图像分配一些 ID,然后你使用这些 ID 来识别图像。
在 U++ 中,我们所做的是实际上将包含图像的文件 `#include` 到 C++ 中,其主要结果是存在一个带有 `static` 方法的类,这些方法返回图像。换句话说,我们没有文件名或一些 ID,而是有静态的 C++ 方法。
#include <CtrlLib/CtrlLib.h>
// This 'imports' .iml images as C++ static methods
#define IMAGECLASS DemoImg
#define IMAGEFILE <Demo/Demo.iml>
#include <Draw/iml.h>
using namespace Upp;
struct MyApp : TopWindow {
virtual void Paint(Draw& w) {
w.DrawRect(GetSize(), White());
w.DrawImage(10, 10, DemoImg::MyImage());
}
};
GUI_APP_MAIN
{
MyApp().Run();
}

对话框模板就是……模板
另一个通常被设计而不是在代码中创建的资源是对话框的布局。
现在有些框架用网格和分组等方式以逻辑方式描述代码中的元素布局,这没问题,也运行良好,尽管它可能有点限制性和乏味。
然而,使用可视化设计器设计对话框是另一种常见的做法,并且可以非常高效,U++ 也采用了这种方法。
一旦对话框使用某个可视化工具设计好

与图形相同的问题再次出现:如何将此设计与应用程序一起存储并与代码连接?
再一次,使用了各种方法,通常最终会使用一些动态对话框加载器以及小部件的整数或文本 ID 来识别它们。
正如你可能预料到的,U++ 做了完全不同的事情。就像图形一样,一旦你设计了布局,你就可以使用一些讨厌的预处理器技巧直接将其导入到 C++ 中。
然而,与栅格图像不同,这里最终的产品是一个模板类定义,它将控件添加到任何基类,并提供一个函数来放置和设置它们。
#include <CtrlLib/CtrlLib.h>
using namespace Upp;
// imports layout class templates
#define LAYOUTFILE <Demo/Demo.lay>
#include <CtrlCore/lay.h>
GUI_APP_MAIN
{
WithDemoLayout<TopWindow> dlg; // WithDemoLayout adds dialog widgets as member variables
CtrlLayoutOKCancel(dlg, "My Dialog");// initializes widgets, assigns ok and cancel actions
if(dlg.Execute() == IDOK)
PromptOK(String() << "Text is: " << ~dlg.text);
}


这使得设计与 C++ 紧密结合:没有外部表示,没有 ID,没有从资源加载对话框。设计中的控件名称就是 C++ 中的成员变量名称,一切都是直接而简单的。
注意:之所以这是模板而不仅仅是一个类,是因为您并非总是将布局用于整个对话框,也用于对话框的一部分,例如选项卡式对话框窗格。因此,需要定义基类,即模板参数。
TheIDE
TheIDE 是 U++ 框架的标准开发环境。
现在让我说清楚
我明白为 U++ 提供标准 IDE 可能会被许多人认为是尝试 U++ 的一个重大挫折。是的,有很多其他的 IDE 环境,有些甚至更精美,而且人们喜欢在这里做出选择。
那么为什么要费心呢?
你可能会猜到原因是它集成了对话框和图像的可视化设计器,但还有一个更重要的问题。
我们希望 U++ 和基于 U++ 的代码模块化并真正实现平台独立。
U++ 拒绝了经典的“库”概念(你需要构建它们,然后将它们添加到你的包含/库路径中,并通过类似 -l 选项添加到你的命令行中)。
相反,U++ 模块被组织成“包”。包是一个包含源文件以及一些描述与其他包关系和可选其他构建相关信息的单一文件夹。在 TheIDE 中,你可以在包组织器对话框中设置此元信息。

在上面的对话框中,你可以看到 `CtrlCore` 包的定义(这是一个提供基本 GUI 封装的包)作为示例。首先查看最大的窗格,并注意“Uses”部分。这定义了 `CtrlCore` 依赖于哪些其他包(它们是 `Draw`、`plugin`\bmp、`RichText` 和 `Painter`)。
在这种情况下,其他部分(库、链接选项、pkg-config)定义了哪些主机平台库将与应用程序链接。还要注意带有激活行条件的“when”列。
现在需要注意的是,包定义中没有包含路径或库路径。这是有充分理由的:包应该是平台无关的,应该可以在任何计算机和(理想情况下)任何受支持的主机平台上编译,而无需更改任何内容。
因此,拼图的另一部分是所谓的“构建方法”。这基本上是对您本地设置的描述,也是您添加各种路径和额外编译器选项的地方。

需要注意的是,只有“外部”头文件路径必须列在构建方法中;对于包头文件,一种简单的机制和标准化的 `#include` 方式确保它们始终可用。
话虽如此,U++ 也提供了命令行构建器 umk,所以如果你真的坚持,你可以直接编辑包元信息,只使用 TheIDE 编辑对话框模板和图像,并像所有真正的程序员一样继续使用 emacs。
BLITZ 构建
TheIDE 提供的另一个很棒的功能是自动化的单一编译单元技术:BLITZ。
它尝试将整个包合并到一个文件中供编译器编译,以加快编译速度——速度提升的原因是头文件只处理一次。
这个过程是自动化的:U++ 可以决定哪些文件可以成为这个单一编译单元的一部分,甚至尝试解决可能阻碍该过程的一些问题(例如,未定义在 .cpp 文件中定义的宏)。
所有这些都与另一个,这次是众所周知的功能结合起来:C++ 编译器在多核 CPU 上并行调用(想想 `gmake` 的 `-j` 选项)。最终的速度提升总结在我 Ryzen 2700x 机器的这个截图中。

11 秒就能完全重建一个 C++ GUI 框架?我敢打赌你已经开始想念你的 makefile 了。
结局好一切都好
这篇冗长的抱怨现在接近 30KB,这可能是一个该停止的信号。
如果您读到这里,感谢您的关注!
我希望您喜欢这次旅程,并且现在对“U++ 围绕一些相当极端的原则设计,以最大限度地提高开发人员生产力和性能”这句话有了更清晰的理解。
有用链接
历史
- 2020 年 11 月 9 日:初始版本