
分段线性回归
4.99/5 (20投票s)
分段线性回归的两种算法
布局
线性回归
线性回归是数据分析中一种经典的数学方法,在教科书和文献中有详尽的介绍。有关介绍性说明,请参阅维基百科的文章[1]。大量的信息需要我们讨论并阐明我们解决此问题的方法。
在线性回归模型中,假设数据受到随机统计噪声的影响,其能为给定数据提供最优近似。在此模型中,每个值是独立变量空间中选定点处的线性近似以及由噪声引起的偏差的总和。在本文中,我们考虑一个独立变量 **x** 和一个因变量 **y** 的简单线性回归。
yi = **a** + **b** **x**i + **e**i
其中 **a** 和 **b** 是拟合参数。 **e**i 代表模型中的随机误差项。最佳拟合使用最小二乘法完成。这种线性回归方法用单条直线段取代了整个数据集。
作为一种基础的数学方法,线性回归在商业和科学的众多领域中都有应用。其流行原因之一是基于近似线斜率的计算能力。与直线偏差较大的情况被解释为系统行为改变的重要事件的迹象。在数据分析中,线性回归可以清晰地展示不受噪声影响的数据。它使我们能够为最初看起来混乱的数据集创建信息图表。此功能也有助于数据可视化,因为它使我们能够避免用肉眼手动绘制近似线的技巧。与其它方法相比,简单高效是线性回归的重要优势,也解释了为什么它在实践中是一个不错的选择。
线性回归的局限性在于,当噪声量相对较小时,其近似可能变得不准确(参见图1)。因此,该方法无法揭示给定数据集中的内在特征。

分段线性回归
分段线性回归 (SLR) 通过对给定数据集进行分段线性近似来解决此问题[2]。它将数据集分割成一系列具有相邻范围的子集,然后为每个范围找到线性回归,其精度通常比对整个数据集进行单线回归要高得多。它通过一系列线段来提供数据集的近似。在此上下文中,分段线性回归可以视为将一个给定的大型数据集分解成相对较小的简单对象集,这些对象在指定的精度内提供了对给定数据集的紧凑但近似的表示。
分段线性回归提供了一种相当稳健的近似。这种优势源于线性回归不对线段端点施加约束。因此,在分段线性回归中,两个连续的线段通常没有共同的端点。这个特性对于实际应用很重要,因为它使我们能够分析时间数据中的不连续性:信号幅度的急剧突然变化,以及准稳定状态之间的切换。该方法使我们能够理解系统或效应的动态。相比之下,高次多项式回归提供连续近似[3]。其插值和外插会受到过拟合振荡的影响[4]。多项式回归在前面提到的应用中不是可靠的预测器。
尽管想法简单,但分段线性回归在实现上并非易事。与线性回归不同,可接受近似的线段数量是未知的。指定线段数量并非一个实用的选项,因为盲目选择通常会产生一个很差地表示给定数据集的结果。同样,将给定数据集均匀地分割成大小相等的子集对于获得最优近似结果也无效。
除了这些选项,我们还限制了允许的偏差,并尝试构建一种能够以最少线段数保证所需精度的近似。算法检测到的线段揭示了给定数据集的基本特征。
指定 **x** 值时的偏差定义为原始 **y** 值与近似 **y** 值之间的绝对差值。范围内线性回归的精度和近似误差定义为范围内所有偏差值的最大值。最大允许偏差(容差)是模型重要的用户界面参数。它控制计算出的分段线性回归的总段数和长度。如果该参数的输入值非常大,则不会对给定数据集进行分割。结果只有一条线性回归线段。如果输入值非常小,则结果可能有很多短线段。
有趣的是,在此公式中,分段线性回归问题与折线简化问题相似。该问题的解决方案是 Ramer、Douglas 和 Peucker 算法[5]。尽管如此,折线简化不适合带噪声数据是有重要原因的。该算法优先考虑距离已构造的近似线段最远的数据点。在此算法的上下文中,这些数据点是最重要的。问题在于,在存在噪声的情况下,重要点通常来自高频波动。异常值会造成最大损害。因此,噪声可能对折线简化的精度产生重大影响。在分段线性回归中,每条线段都会与噪声的影响进行平衡。短时波动被去除,以显示原始数据中重要的长期特征和趋势。
算法
自适应细分
在此,我们讨论两种分段线性回归算法。在附带的代码中,这些算法的顶层函数是 SegmentedRegressionThorough() 和 SegmentedRegressionFast()。它们都基于自适应细分,这是我们从折线简化解决方案中借鉴来的。图2显示了该方法的自顶向下动态。
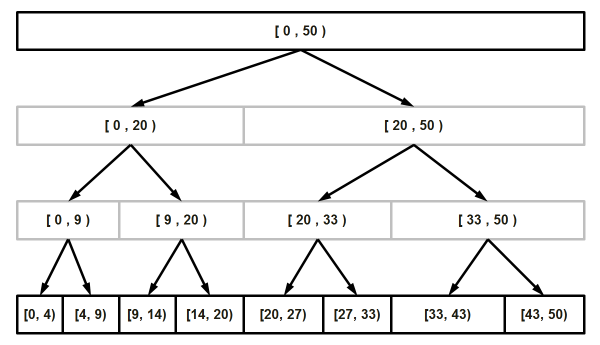
该细分方法的伪代码如下。
StackRanges stack_ranges ;
stack_ranges.push( range_top(0, n_values) ) ;
while ( !stack_ranges.empty() )
{
range_top = stack_ranges.top() ;
stack_ranges.pop() ;
if ( CanSplitRange( range_top, idx_split, ... ) )
{
stack_ranges.push( range_left (range_top.idx_a, idx_split ) ) ;
stack_ranges.push( range_right(idx_split , range_top.idx_b) ) ;
}
else
ranges_result.push_back( range_top ) ;
}
在两种算法中实现的分割范围的标准(参见函数 CanSplitRangeThorough() 和 CanSplitRangeFast())都基于将近似误差与用户提供的容差进行比较。一旦对范围内每个近似值实现了指定的精度,该范围就会被添加到近似结果中。否则,它将被分割成两个新范围,然后压入堆栈以供后续处理。
这两个函数还实现了对小且不可分割范围的测试。为避免由仅包含两个数据元素的数据集的细分引起的混淆是必要的。当前版本的算法不允许创建对应于单个数据点的退化线段。
这种细分方法属于分治算法家族。它速度快,并保证了结果的空间效率。在单次分割操作成本恒定的简化假设下,递归细分的运行时间在最坏情况下为 O(N),平均情况下为 O(log M),其中 N 是给定数据集中元素的数量,M 是近似结果中线段的数量。分割操作的成本特定于特定算法。这对整体性能的影响将在下文讨论。
现在显而易见的问题是如何为我们刚才讨论的递归细分找到最佳分割点?看来有不止一种方法可以回答这个问题。这些方法负责产生略有不同的近似结果,并导致 SLR 算法具有不同的性能。我们从更易于理解的简单方法开始讨论,然后是更高级的第二种方法。
顺序搜索最佳分割点
简单方法(参见函数 CanSplitRangeThorough())代表了对给定数据集范围内最佳分割点的顺序搜索。它涉及以下计算步骤:当前选定的数据点为我们提供了两个子范围。对于每个子范围,我们计算几个和、线性回归参数,然后计算近似精度,即原始值与近似值之间绝对差值的最大值。最佳分割点由两个子范围的最佳近似精度决定。

这种简单方法(参见图3)在紧凑性方面提供了良好的近似结果:对于指定的容差,线段数量很少。但遗憾的是,对于处理大型和特大型数据集来说,它太慢且不切实际。该算法的弱点在于,对给定范围内最佳分割点的顺序搜索(参见函数 CanSplitRangeThorough())的线性成本乘以子范围中线性回归计算的线性成本。因此,该算法的总运行时间至少为二次方。在递归细分线性性能的最坏情况下,该算法将变为三次。使用预先计算的和表也无法显著提高此速度。瓶颈在于计算范围内近似误差,这需要线性时间。
使用简单移动平均进行搜索
如果我们避免讨论第一种算法中对每个范围进行的昂贵顺序搜索,就可以提高构建分段线性回归的算法的效率。为此,我们需要一种快速的方法来检测最适合分割给定数据集范围内的数据点子集。
为了更好地理解更快算法的关键思想,让我们考虑没有噪声的完美输入数据。图4显示了具有多个明确定义的线段的样本数据的简单移动平均 (SMA) [6] 的计算。

重要事实是,当 SMA 窗口位于原始数据具有线性依赖性 y(x) 的范围内时,每个导出的 **y** 值都等于匹配的原始 **y** 值。换句话说,基于 SMA 的平滑操作不会影响原始数据具有线性依赖性 y(x) 的范围内的内点。当平滑窗口进入包含多条线段的范围时,原始 **y** 值与导出 **y** 值之间的偏差会变得明显并增加。在更普遍的上下文中,平滑曲线对原始数据集中所有类型的平滑和尖锐的非线性都很敏感,包括“拐角”和“跳跃”。非线性越大,平滑操作的效果越明显。
SMA 的这一特性提出了以下方法来找到用于计算局部线性回归和它们之间断点的线性依赖性 y(x) 的范围。如果我们计算原始值和光滑值之间的绝对差值数组,那么原始数据中所需的线性依赖性范围就对应于此数组中较小的(理想情况下为零)差值。这些近似范围之间的断点由差值数组中的局部最大值定义。
在附带代码中实现的算法(参见函数 SegmentedRegressionFast())中,我们检测了原始数据和光滑数据之间绝对差值数组中的所有局部最大值。分割近似范围的顺序(在函数 CanSplitRangeFast() 中)由局部最大值的大小决定。对于每个新的细分范围,我们计算线性回归的参数和近似误差。处理会一直进行,直到达到所需的精度。这意味着通常不是所有的局部最大值都被用来构建近似结果。
当处理受噪声影响的真实数据时(参见图5),平滑不仅有助于我们检测数据中的线段,而且还允许我们测量数据中的噪声量。此算法的当前版本使用对称窗口。窗口的长度可以控制线性近似的精度。为了获得平滑数据,我们对整个输入数据集应用一次平滑操作。之后不需要在由细分创建的近似范围内使用平滑。这种方法有助于我们避免与 SMA 的边界条件相关的问题。

从上面的讨论中可以清楚地看出,平滑方法的选择对于这种分段线性回归很重要。SMA 是一种低通滤波器。因此,其他类型的低通滤波器似乎也适用于平滑操作。理论上并非不可能,但实际上不太可能是个好主意。与其他低通滤波器相比,SMA 是最简单有效的滤波器之一。它的特性已得到深入研究。特别是,SMA 的一个著名问题是它会反转高频振荡。对于此处讨论的算法,这会导致局部最大值定位精度稍差。这个问题可以通过迭代 SMA 轻松解决,即所谓的 Kolmogorov-Zurbenko 滤波器[7]。此外,迭代 SMA 提供了更多的控制来去除高频波动。不仅可以调整平滑窗口的长度,还可以调整迭代次数,以减少导出数据中的噪声量并获得最佳可能的近似。重要的是,这种迭代滤波器还能保留给定数据的线段。
在性能方面,第二种 SLR 算法(函数 SegmentedRegressionFast())与第一种算法(函数 SegmentedRegressionThorough())相比具有重要优势。主要算法步骤的成本不是相乘而是相加。使用局部最大值在原始数据和光滑数据之间的绝对差值中搜索潜在分割点非常快,并在递归细分之前完成。此搜索涉及 SMA 的计算、差值数组和局部最大值数组。由于这些计算中的每一步都需要线性时间,因此算法的这一阶段也以线性时间完成。随后的递归细分在给定分割点上操作,并且只需要计算局部线性回归的参数,这需要线性时间。因此,此 SLR 算法的平均成本为 O(N log M),最坏情况成本为二次方,其中 N 是给定数据集中元素的数量,M** 是近似结果中线段的数量。此性能远优于第一种算法。这就是为什么基于平滑的算法是分析大型数据集的优选选择。
改进性能的代价是第二种算法可能找不到保证线性回归最高精度的精确分割点位置。这在实际应用中通常是可以接受的,因为噪声数据中局部最大值的精确位置是一个有些模糊的概念。这种情况类似于对平滑数据的分析。只要其平滑曲线在应用上下文中是有意义的,近似通常是可以接受的。用户容差严格时未能找到分段线性回归不一定是此算法的缺点。如果输入数据中有两条线段,算法不会期望找到十条近似线段。作为附加措施,可以通过仅在局部最大值区域进行狭窄的顺序搜索来提高寻找最佳分割点的精度。
对于大型和特大型数据集,可以通过结合两种算法来控制性能和精度:首先,我们运行基于 SMA 平滑的快速算法来检测重要的分割点。此结果用于给定数据集的初始分区,以构建一阶近似。然后,我们继续使用顺序搜索分割点的范围细分,以获得更好的精度。
结论
有趣的是,这两种算法的实现都需要很少的代码。附带代码中的注释侧重于适当的技术细节。在本节中,我们将讨论代码和算法的其他重要方面。
为了关注算法的主要思想,其实现优先考虑代码的可读性。出于同样的原因,我们不使用解决涉及浮点数的数值计算错误的方��。这种方法使代码更容易移植到其他语言。在此上下文中,我们注意到类 std::vector<T> 代表动态数组。此外,实现并未针对最佳性能进行优化。特别是,它没有使用预先计算的和表或高级数据结构。
如前所述,附带代码不支持用于范围最小长度(不可分割范围的限制)的用户界面参数。这些通用算法的实现应用了 2 个数据点构成线段的基本限制。因此,分段线性回归可能有很多小的线段,它们对应于细分过程产生元素数量较少的数据子集。这种效果通常是由用户指定的近似精度过高的高频噪声引起的。这样的结果在实践中很可能无用。如果出现这种情况,那么引入一个更大的不可分割范围限制以在处理早期阶段检测失败是有意义的。
此处讨论的算法假设输入数据是等间隔的。当偏差相对较小时,可以在特殊情况下使用这些算法。然而,在一般情况下,有必要正确准备输入数据。异常值问题超出了本文的范围,尽管它在实践中非常重要。当前实现假定所有输入值都具有重要性,并且没有任何值可以被删除。
当分段线性回归包含大量小段(紧凑性丢失)或其数据表示未达到指定精度时,它将变得无效。另一个复杂之处在于,分段线性回归允许一个以上可接受的结果。这一事实使得其解释不如线性回归那样简单。
在实际应用中,“什么是噪声?”和“什么是信号?”这两个朴素的问题往往难以回答。然而,如果不了解噪声的特性,我们就无法得出可靠的结论和有意义的预测。主要挑战是开发一个足够的数据分析数学模型。运行良好的模型会经过真实数据集的严格测试。
趣点
算法的性能测量始终备受关注,尽管运行时间可能因系统而异。对于下表中所示数据,测试系统是一台配备 AMD Ryzen 7 PRO 3700 处理器、16GB 内存和 Windows 10 Pro 操作系统的台式计算机。代码在 Visual Studio 2019 中以控制台应用程序类型生成。执行时间以毫秒为单位,在 C# 中使用 Stopwatch,在 C++ 中使用 std::chrono::high_resolution_clock 测量。第一张表显示了函数 SegmentedRegressionThorough() 中实现的 SLR 算法的结果。
| N | 10,000 | 20,000 | 30,000 | 50,000 | 70,000 |
| C++ | 215 | 860 | 1,930 | 5,370 | 10,500 |
| C# | 560 | 2,240 | 5,030 | 13,900 | 27,500 |
第二张表显示了函数 SegmentedRegressionFast() 中算法的结果。
| N | 10,000 | 20,000 | 30,000 | 50,000 | 70,000 | 100,000 |
| C++ | 1.2 | 2.5 | 3.1 | 3.5 | 3.9 | 5.0 |
| C# | 6.3 | 9.9 | 13.3 | 12.7 | 13.3 | 15.5 |
C++ 和 C# 变体的算法在运行时间对输入数据集大小的依赖性方面表现相似。第一个基于顺序搜索的算法在渐近上与计算成本模型一致。第二个使用简单移动平均的算法分析起来不那么简单,因为它的性能对近似结果中的段数更为敏感。
比较相同算法的运行时间值表明 C++ 比 C# 快约 3 倍。然而,更重要的是,使用简单移动平均的 C# 算法比基于顺序搜索最佳分割点的 C++ 算法明显更快。这些测量得出的 **实际教训** 是,选择正确的算法比选择编程语言更重要。C++ 无法帮助我们解决由蛮力算法引起的问题,而 C# 则可以通过智能实现提供超出可接受范围的性能。
参考文献
- https://en.wikipedia.org/wiki/Linear_regression
- https://en.wikipedia.org/wiki/Segmented_regression
- https://en.wikipedia.org/wiki/Polynomial_regression
- https://en.wikipedia.org/wiki/Overfitting
- https://en.wikipedia.org/wiki/Ramer-Douglas-Peucker_algorithm
- https://en.wikipedia.org/wiki/Moving_average
- https://en.wikipedia.org/wiki/Kolmogorov-Zurbenko_filter
历史
- 2020年10月7日:初始版本
- 2020年10月20日:添加了 C# 源代码
- 2020年11月2日:添加了“趣点”部分