
基于层级调度的类队列数据结构
5.00/5 (1投票)
一种数据结构,允许根据定义项目层级的标签调度项目进行处理
引言
forque 结构的目的是以这样一种方式调度处理,即并发处理的项目不会相互影响。例如,当我们收到特定数据集的更新流时,如果该数据集中的实体具有父子关系,我们可能不希望对同一项目处理多个更新,或者同时对父项及其一个或多个子项进行更新。
为了实现这一点,用户为每个入队项目添加一个定义树状层级的标签。根据这些标签,forque 确保在层级中,特定子树一次只能处理一个项目。
例如,标签 `1/2` 和 `1/2/3` 具有父子关系,而标签 `1/2/1` 和 `1/2/3` 则不相关。
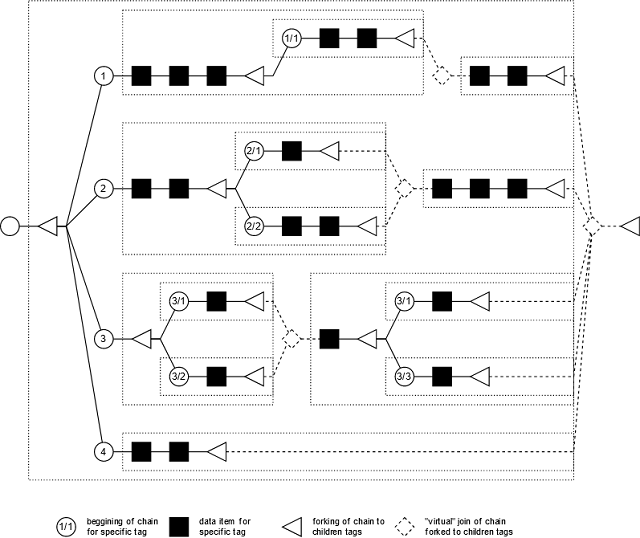
标签的结构可以是动态的或静态的。静态标签的深度和每个级别的类型在编译时定义。对于动态标签,深度不定义,而类型可以在运行时更改,即使是兄弟标签也可以是不同的类型。
| 信号强度 | 0 | 1 | 2 |
| 类型 | int | 字符串 | float |
| 静态标签 #1 | 77 | "x" | 12.3 |
| 静态标签 #2 | 8 | "y" | |
| 静态标签 #3 | 10 |
| 信号强度 | 0 | 1 | 2 |
| 动态标签 #1 | 8 | "x" | 12.3 |
| 动态标签 #2 | 8 | 7.9 | |
| 动态标签 #3 | "y" | 8 |
项目的生产分两个阶段完成
- 在队列中预留位置
- 用实际负载填充项目
预留位置确保相关项目的相对顺序将得到尊重,这样填充项目实际值所需的时间不会导致不必要的重新排序。
只有填充的项目才会提供给消费者。所有在该项目之后排序的相关项目将等待其被填充、提供和消费后才会被提供给消费者,即使它们已经填充。
这两个阶段可以合并,项目可以在预留时填充,但顺序仍将得到尊重,并且除非没有其他相关项目必须在其之前消费,否则不会提供新项目。
像生产一样,消费也分两个阶段进行
- 获取填充的项目
- 从队列中释放项目
两阶段过程确保消费者不会同时获得相关项目。在第一阶段,消费者请求一个可用时间。项目处理完成后,消费者必须通知队列处理已完成,以便下一个可用且具有相关标签的项目(如果有)可以提供。
虽然相关项目的顺序得到尊重,但对于不相关的项目则没有这样的保证,这正是这项工作的全部意义所在。:) 对于可用但不相关的项目,其提供给消费者的顺序仍然有一些控制
- 先进先出 (FIFO) - 第一个可用的项目首先被服务
- 后进先出 (LIFO) - 最后一个可用的项目首先被服务
- 优先级 - 具有最高用户定义优先级的可用项目首先被服务
要求
Forque 库要求编译器支持 C++20。具体来说,需要支持协程和概念。目前,它仅适用于 Microsoft Visual C++ 14 编译器。
使用 Forque
Forque 由 `frq::forque` 类模板实现,该模板由存储在队列中的项目类型、用于调度的标签类型、所需的运行队列类型和分配器进行参数化。
template<typename Ty,
runlike Runque,
taglike Tag,
typename Alloc = std::allocator<Ty>>
class forque;
`Runque` 和 `Tag` 模板参数受 `runlike` 和 `taglike` 概念的约束。
`frq::forque` 具有一个相当简单的接口,允许用户执行以下操作
- 为已生成且带有特定标签的项目在队列中预留位置
template<taglike Tag> task<> reserve(Tag const& tag, value_type const& value); // (a) template<taglike Tag> task<> reserve(Tag const& tag, value_type&& value); // (b)
- 为稍后将生成且带有特定标签的项目在队列中预留位置
template<taglike Tag> task<reservation_type> reserve(Tag const& tag); // (c)
- 访问运行队列中的下一个就绪项目
task<retainment_type> get() noexcept;
- 停止接受新预留和处理现有项目
task<> interrupt() noexcept;
生产项目
如果项目的值已知,则可以使用 `reserve` 重载 *(a)* 或 *(b)* 将其标记为所需标签并放入 forque。每当其依赖项被处理时,项目将被放入就绪队列。另一方面,如果项目的值未知,但必须预留位置以在处理项目的依赖项时保持所需的处理顺序,则可以使用重载 *(c)*。它返回一个 `reservation
消费项目
`get()` 仅在运行队列中有可用项目时,或者如果处理因抛出 `interrupted` 异常而中断时返回。调用 `get()` 后,项目不被视为已消费。相反,返回 `retainment
停止项目处理
调用 `interrupt()` 将立即唤醒任何等待项目的消费者,并在其上下文中抛出 `interrupted` 异常。任何后续对 `reserve()` 或 `get()` 的调用也将导致 `interrupted` 异常。
标签
库提供以下标签类型选择
- 静态标签 - `frq::stag` 类模板,接受标签包含的元素数量、其大小和它们的类型
- 动态标签 - `frq::dtag` 类模板,仅接受分配器类型
所有标签类型都必须满足 `taglike` 概念,其定义如下
template<typename Ty>
concept taglike = requires(Ty t) {
typename Ty::size_type;
typename Ty::storage_type;
{std::size_t{typename Ty::size_type{}}};
{ t.values() } noexcept -> std::convertible_to<typename Ty::storage_type>;
{ t.size() } noexcept -> std::same_as<typename Ty::size_type>;
};
其中
- `size_type` 是一种可以存储标签中值数量的类型,并且可以在不缩小的情况下转换为 `std::size_t`,
- `storage_type` 是一种可以存储标签中所有值的类型,
- `size` 是一个成员函数,返回标签中值的数量,并且
- `values` 是一个成员函数,返回当前存储在标签中的所有值。
静态标签
静态标签的结构、大小和每个级别的值类型在编译时定义。静态标签拥有其中存储的值,这意味着复制/销毁标签也将复制/销毁存储的值。
`frq::stag` 类模板表示静态标签。
template<std::uint8_t Size, typename... Tys>
class stag;
`Size` 模板参数指定将填充 `Tys` 类型列表中的多少个值,从而定义标签的“级别”。对于同一队列使用的所有标签,无论标签级别如何,类型列表都必须相同
| 信号强度 | 0 | 1 | 2 |
stag<3, int, string, float> | 77 | "x" | 12.3 |
stag<2, int, string, float> | 8 | "y" | |
stag<1, int, string, float> | 10 |
`frq::stag` 可以从包含定义类型且大小合适的 `tuple` 构造,或者向构造函数提供参数列表,这些参数将用于初始化标签中相应的值
template<typename... Txs>
constexpr inline stag(construct_tag_default_t, Txs&&... args);
constexpr inline stag(storage_type const& values);
constexpr inline stag(storage_type&& values);
标签的大小可以通过调用 `size()` 获取;包含标签中所有值的 `tuple` 由 `values()` 返回;最高可用级别的值由 `key()` 返回。
storage_type const& values() const noexcept;
size_type size() const noexcept;
auto key() const noexcept;
`frq::stag_t` 类型别名提供了一种为指定类型列表在最高级别定义 `stag` 类型的方法
template<typename... Tys>
using stag_t = /* ... */;
动态标签
动态标签在每个级别的值的大小或类型上没有限制。标签大小可以在运行时增加,并且每个级别的值类型可以不同,甚至对于同一父级的子项也可以不同
| 信号强度 | 0 | 1 | 1 |
| 动态标签 #1 | 8 | "x" | 12.3 |
| 动态标签 #2 | 8 | 7.9 | |
| 动态标签 #3 | "y" | 8 |
这是通过类型擦除实现的。存储在动态标签中的类型必须支持哈希和相等比较。动态标签共享值,因此标签只存储值的引用,不像静态标签。
`frq::dtag` 类模板仅由用于类型擦除目的的分配器进行参数化
template<typename Alloc = std::allocator<dtag_node>>
class dtag;
存储在动态标签中的值由 `frq::dtag_node` 抽象类型包装,该类型执行类型擦除。`frq::dtag_node` 提供了用于哈希、相等比较和存储值的字符串格式化的接口。
class dtag_node {
public:
virtual ~dtag_node() {
}
virtual std::size_t hash() const noexcept = 0;
virtual bool equal(dtag_node const& other) const noexcept = 0;
virtual std::string get_string() const = 0;
};
用户可以通过 `frq::dtag_value` 类型与值交互,这是一种 *常规* 类型,提供对存储实际值的底层节点的访问。
class dtag_value {
public:
dtag_node_ptr::element_type const& node() const;
std::size_t hash() const noexcept;
std::string get_string();
bool operator==(dtag_value const& rhs) const noexcept;
bool operator!=(dtag_value const& rhs) const noexcept;
};
`frq::dtag` 可以从 `dtag_value` 序列构造,或者通过向构造函数提供参数列表,这些参数将初始化标签中相应的值。可以提供哈希操作和相等比较,这将由构造的 `dtag_node` 使用。
template<tag_iterator Iter>
dtag(allocator_type const& alloc, Iter first, Iter last);
template<tag_iterator Iter>
dtag(Iter first, Iter last);
template<typename HashCmp, typename... Tys>
dtag(allocator_type const& alloc, HashCmp const& hash_cmp, Tys&&... args);
template<typename... Tys>
dtag(construct_tag_alloc_t, allocator_type const& alloc, Tys&&... args);
template<typename HashCmp, typename... Tys>
dtag(construct_tag_hash_cmp_t, HashCmp const& hash_cmp, Tys&&... args);
template<typename... Tys>
dtag(construct_tag_default_t /*unused*/, Tys&&... args);
动态标签提供与静态标签类似的接口。它们可以提供:`size()`;包含标签中值引用的 `tag_value` 向量:`values()`;以及最高可用级别处的 `tag_value`:`key()`。还提供了一个附加访问器,允许用户获取存储在标签中的值的元组:`pack()`。提供给 `pack` 函数模板的模板参数的数量和类型必须与存储在标签中的值的数量和类型匹配,否则行为未定义。
storage_type const& values() const noexcept;
size_type size() const noexcept;
template<typename... Tys>
auto pack() const;
auto key() const noexcept;
`frq::default_hash_compare` 类型,在用户类型未在标签构造期间提供的情况下使用,将哈希计算转发给 `std::hash
struct default_hash_compare {
template<typename Ty>
std::size_t hash(Ty const& value) const noexcept;
template<typename Ty>
bool equal_to(Ty const& left, Ty const& right) const noexcept;
};
运行队列
运行队列表示准备好提供给消费者进行处理的项目队列。准备就绪的项目被消费的顺序可以由用户配置。有三种选项可用
- 先进先出 (FIFO) - 第一个可用的项目首先被服务
- 后进先出 (LIFO) - 最后一个可用的项目首先被服务
- 优先级 - 具有最高用户定义优先级的可用项目首先被服务
`frq::make_runque_t` 元函数提供了一种配置所需运行队列的方法
template<typename Order,
typename Mtm,
typename Ty,
typename Alloc,
typename... Rest>
using make_runque_t = /* ... */;
- `Order` 定义了就绪项目被消费的顺序。以下选项之一可用
fifo_order (先进先出)lifo_order (后进先出)priority_order (优先级顺序)
- `Mtm` 定义了多线程模型。目前只实现了 `coro_thread_model`。
- `Ty` 是存储在运行队列中的项目类型。
- `Alloc` 显然是队列本身使用的分配器。
- `Rest` 可用于向所需运行队列类型传递附加参数。对于 `priority_order`,它定义了传递给底层优先级队列的 `LessThen` 操作。
`Ty` 参数与 forque 操作的用户类型不同。它是一种包装类型,允许消费者控制项目的生命周期。该类型还提供了一种通知 forque 项目已处理的方法,以便它可以准备下一个相关项目(如果可用)。
`make_runque_t` 元函数返回的类型将满足 `runlike` 概念,其定义如下
template<typename Ty>
concept runlike = requires(Ty s) {
typename Ty::value_type;
requires runnable<typename Ty::value_type>;
typename Ty::get_type;
{ s.get() } ->std::same_as<typename Ty::get_type>;
{ s.put(std::declval<typename Ty::value_type&&>()) };
};
其中
- `value_type` 是存储在队列中的项目类型,需要满足 `runnable` 概念,
- `get_type` 是 `get()` 成员函数的返回类型,它返回下一个可用项目,
- `get` 是一个返回下一个可用项目的函数,并且
- `put` 是一个将项目添加到队列的函数。
`runnable` 概念相当简单。它只需要一个非抛出移动构造函数
template<typename Ty>
concept runnable =
std::is_nothrow_move_constructible_v<Ty> && !std::is_reference_v<Ty>;
用户的唯一职责是配置所需的运行队列类型并将其提供给 forque。用户不会直接与运行队列交互。
示例
Forque 应用程序使用示例可以在 *./src/app/* 目录中找到。它使用动态标签,包含多个生产者和简单的消费者,这些消费者仅将已消费的项目输出到控制台。
该示例具有一个相当简单的线程池实现,它为消费者和生产者的协程执行提供了上下文,但这超出了本文的范围。
我们做的第一件事是选择标签类型并配置运行队列和 forque 类型
using tag_type = frq::dtag<>; // dynamic tag
// type returned by 'reserve' call
using reservation_type = frq::reservation<item>;
// type returned by 'get' call
using retainment_type = frq::retainment<item>;
using runque_type = frq::make_runque_t<frq::fifo_order,
frq::coro_thread_model,
retainment_type,
std::allocator<retainment_type>>;
using queue_type = frq::forque<item, runque_type, tag_type>;
`generate_tag` 函数给出了如何生成任意大小的动态标签的示例
auto tag_size = tag_size_dist(rng);
while (tag_size-- > 0) {
auto node = frq::make_dtag_node<int>(std::allocator<frq::dtag_node>{},
frq::default_hash_compare{},
tag_value_dist(rng));
tag_values.push_back(std::move(node));
}
return tag_type{begin(tag_values), end(tag_values)};
`produce` 函数是一个分两个阶段生产项目的协程
auto tag = generate_tag(rng);
// phase 1
auto item = co_await queue.reserve(tag);
// ...
co_await p.yield();
// ...
// phase 2
co_await item.release({tag, value});
在第一阶段,我们在队列中为项目预留位置。在第二阶段,我们用实际值填充项目,这将使项目可供消费。
调用 `yield` 实际上将协程的其余部分放回线程池队列的末尾。由于生产是在循环中完成的,没有任何等待,这使得消费者有机会在我们结束循环之前开始消费项目。
每个生产者生成一定数量的项目,在最后一个生产者完成生产后,它会启动 forque 的关闭
if (--producers == 0) {
co_await queue.interrupt();
}
`consume` 函数是一个从 forque 中消费就绪项目的协程
try {
// phase 1
auto item = co_await queue.get();
// ...
co_await p.yield();
// ...
// phase 2
co_await item.finalize();
}
catch (frq::interrupted&) {
break;
}
与生产者一样,也有两个阶段。在第一阶段,我们等待并从队列中获取项目;在第二阶段,处理完成后,项目被释放。
中间的 `yield` 调用通过将协程的其余部分放到线程池队列的末尾来模拟异步处理。
处理被包装在 `try`/`catch` 块中,以便在 forque 关闭后可以中止消费协程。