
通过克隆图学习广度优先搜索图遍历
5.00/5 (1投票)
图是技术面试中可能出现的最常见问题之一,尤其是在当今许多现实世界应用都可以用节点和边来表示的情况下,例如社交网络!
图是技术面试中可能出现的最常见问题之一,尤其是在当今许多现实世界应用都可以用节点和边来表示的情况下,例如社交网络!
编程面试中可能出现数百个图问题,幸运的是,我们只需要真正理解少数几个算法就能解决其中大部分问题。
在本文中,我们将讨论如何解决 LeetCode 上的 克隆图 问题,该问题要求我们使用图的广度优先搜索遍历来克隆它。
问题陈述
给定一个连通的无向图中的节点引用。返回图的深拷贝。
每个图节点包含一个值 (val) 和一个 GraphNode 列表 (neighbors)。
class Node {
public int val;
public List<Node> neighbors;
}
此问题的输入是一个与其它节点相连的单个节点,我们的目标是创建它的精确副本。
理解问题
为了解决这个问题,需要理解几个提到的术语。
在无向图中,假设节点 1 指向节点 2,这也意味着节点 2 也指向节点 1。

另一种图是有向图,如果节点 1 指向节点 2,并不一定意味着节点 2 也指向节点 1。

对于我们的输出,我们想要创建一个图的深拷贝。深拷贝意味着我们创建一个新的节点实例,它具有所有相同的值和也是深拷贝的邻居。这可以防止我们仅仅返回给定的节点。
高层算法
要对图进行深拷贝,我们首先必须访问图中的所有节点以创建它们的副本。探索图节点的常用算法是广度优先搜索 (BFS) 和深度优先搜索 (DFS)。
这两种算法都有各自的权衡,但它们的实现方式几乎相同。为了简化起见,我们将用 BFS 来解决这个问题。
在高层上,BFS 算法允许我们首先探索所有邻居节点,然后是所有邻居的邻居,依此类推,直到探索完所有节点。

BFS 算法需要 2 个东西
- 一个队列用于存放我们的节点。队列遵循“先进先出”的原则,我们稍后将看到这如何使我们能够通过优先处理邻居节点来创建 BFS 算法。这与使用栈不同,栈遵循“先进后出”的原则,用于 DFS。
- 一个已访问的集合,用于跟踪我们已访问的节点,以便我们不会再次探索它们,这尤其重要,因为图可能形成环,导致我们的算法无限运行。
BFS(或 DFS)算法通常涉及 3 个步骤。
- 将给定的起始节点放入队列和已访问集合中。
- 遍历队列直到清空。
- 从队列中弹出一个节点,遍历其子节点,如果之前未见过,则将它们添加到已访问集合和队列中。
使这一切生效的关键是队列数据结构。每当我们将其添加到树的所有子节点时,我们都会将它们添加到列表的末尾,从而保证我们首先探索遇到的第一个节点的所有子节点。
这里有一个例子。
给定一个包含 4 个节点的简单图:.

在此图中,这些节点都是单向的。我们将从将节点 1 放入我们的队列和已访问集合开始。

然后我们将开始处理我们的队列。
- 从队列中移除节点 1 并处理其邻居:节点 2 和节点 4。
- 由于我们之前未见过这两个节点,我们将它们添加到我们的队列和集合中。
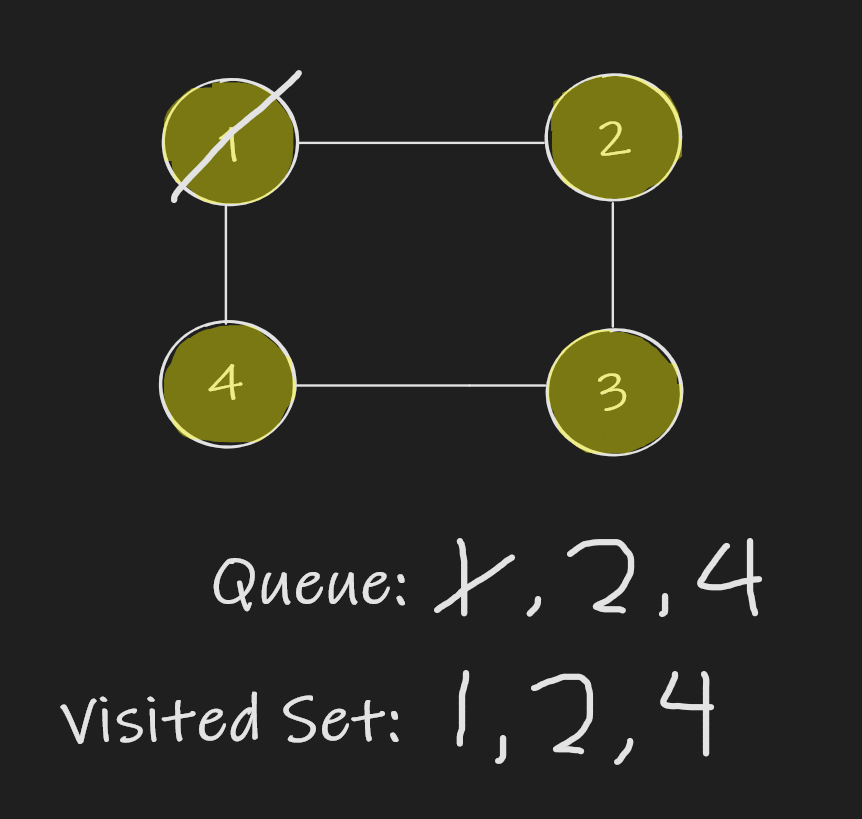
继续,我们开始处理队列中的下一个节点。
- 我们从队列中移除节点 2 并处理其邻居:节点 1 和节点 3。
- 由于节点 1 已经在我们的已访问集合中,我们不想再次访问它,但是我们会将节点 3 添加到我们的已访问集合和队列中。

继续,我们将
- 处理节点 4 及其邻居节点 1 和节点 3。
- 两个邻居都在已访问集合中,所以我们不会将它们放入队列。

注意:我还想指出我们遍历图的顺序,我们从 1 开始,然后到它的邻居 2,然后之后我们到它的另一个邻居 4。这就是队列如何让我们运行 BFS 算法。如果我们想做 DFS,我们会使用栈。
最后完成此示例
- 从队列中移除节点 3,然后查看其邻居:节点 2 和节点 4。
- 两个都在已访问集合中,所以我们不做任何操作。

此时,我们的队列已清空,BFS 算法已完成。
将算法应用于问题
在此问题中,我们将遵循相同的算法,但是我们需要进行额外的修改。
当我们遍历图时,我们需要克隆我们遇到的每个节点,以便我们能够重新创建图。
我们需要跟踪所有我们创建的节点,以便我们不会重新创建它们。为了实现这一点,我们可以将它们放入一个映射中,其中使用节点的 value 作为键,深拷贝作为值。
我们可以用这 3 种数据结构来完成我们的算法:我们的克隆节点到引用的映射、我们的队列和我们的已访问集合。然而,我们可以使用的一个优化是使用这个映射作为我们的已访问集合!
每当我们创建节点的克隆时,这将是我们第一次看到它。在这些情况下,当我们处理一个邻居节点时,我们会将该节点同时添加到映射和集合中。为什么不直接去掉集合呢?
时间和空间复杂度
运行时
此算法的运行时是O(V + E),V 代表我们正在访问的所有节点,E 代表节点之间存在的所有边。
注意:边是连接两个节点的链接。
空间复杂度
此算法的最坏情况空间复杂度为O(N)。虽然我们的队列可能不会存储图中的所有节点,但我们的已访问集合将存储所有节点以防止我们处理同一个节点两次。
实现
class Solution {
public Node cloneGraph(Node node) {
if (node == null) {
return null;
}
Queue<Node> queue = new LinkedList();
Map<Integer, Node> cloneMap = new HashMap();
queue.add(node);
cloneMap.put(node.val, new Node(node.val));
while (!queue.isEmpty()) {
Node cur = queue.remove();
Node clone = cloneMap.getOrDefault(cur.val, new Node(cur.val));
cloneMap.put(cur.val, clone);
for (Node child : cur.neighbors) {
Node childClone = cloneMap.getOrDefault(child.val, new Node(child.val));
clone.neighbors.add(childClone);
if (!cloneMap.containsKey(child.val)) {
queue.add(child);
}
cloneMap.put(child.val, childClone);
}
}
return cloneMap.get(node.val);
}
}
结论
解决克隆图问题的关键教训是了解如何应用 BFS 算法。
图算法非常重要,因为它们在面试中很常见。它们可能看起来令人生畏,迫使你找出多个数据点之间的联系。
有时问题本身可能甚至不提及图关系。但是,一旦你确定面试问题是一个图问题,你就会发现只需要掌握少数几个关键算法就能解决大多数编码问题!
帖子 使用克隆图学习广度优先搜索图遍历 最先出现在 Leet Dev。