
使用 SIMD 优化 x86 汇编代码——数组求和示例
4.83/5 (5投票s)
讨论了在 x86 汇编语言编程中使用 MMX、SSE 和 AVX 等 SIMD 指令进行优化的内容。
目录
引言
SIMD(单指令多数据流)是一种计算单元,可以同时对多个数据项执行相同的操作。汇编语言中的指令可以利用并行计算来充分利用数据的并行性。典型的 SIMD 操作包括基本的算术运算(如加法、减法、乘法、除法)以及移位、比较和数据转换。处理器通过重新解释寄存器或内存位置中操作数的位模式来支持 SIMD 操作。例如,一个包含单个 32 位 DWORD 整数的 32 位寄存器,也可以容纳两个 16 位 WORD 或四个 8 位 BYTE。
大多数现代 CPU 架构都包含 SIMD 指令以提高软件性能。SIMD 特别适用于常见的任务,如图像处理中的像素处理或音频处理中的数字音量调整。此外,软件编译器在生成发布版本时,会严重依赖现代 SIMD 指令来优化代码执行。例如,Visual C++ 在发布模式下编译的项目,其运行速度比使用传统汇编语言编写的逻辑相似的代码要快得多。
SIMD 技术的发展经历了几个与现代 CPU 设计年份相对应的阶段。1996 年,Intel 推出了广泛应用的 MMX 扩展,这是对 x86 的扩展。随后,在 1999 年引入了 SSE(Streaming SIMD Extensions),并随后扩展到 SSE2、SSE3、SSSE3 和 SSE4。之后,在 2008 年推出了 AVX(Advanced Vector Extensions),并在 2013 年扩展到 AVX2 和 AVX-512。
在本文中,我将不详细介绍 MMX、SSE 和 AVX。我将重点关注一个数组求和的示例,展示如何使用一些现代指令进行优化。您需要熟悉传统的 x86 汇编语言,最好是在 Windows 系统上使用 MASM。学习 SIMD,我推荐阅读 Apress 出版的《Modern X86 Assembly Language Programming by Daniel Kusswurm》的第一版。通过 Visual Studio 的帮助,这可能是学习 SIMD 编程的一种良好且便捷的方法。这里引用的一些 MMX 材料也来自这本书。
关于数组求和示例
数组求和示例的代码逻辑可以在下面的 C/C++ 函数中看到,其中参数 x 是一个 BYTE 数组,n 是数组的长度。
// Code logic of array sum in C/C++
DWORD SumArrayCPP(const BYTE* x, unsigned int n)
{
DWORD sum = 0;
for (unsigned int i = 0; i < n; i++)
sum += x[i];
return sum;
}
我使用传统(原始)或现代(SIMD)指令,以及输入和输出,在 x86 汇编过程中实现了这样一个函数。为了测量执行时间,我通过多次重复运行每个过程,以进行效率比较。基准测试将允许您输入迭代次数,例如一百万次(1,000,000)。测试会生成一个包含 65536 个(64K)伪随机 BYTE 整数的大数组,其值范围从 1 到 255。运行后,结果可能会显示在下面的控制台输出中,这是我在 i7-8565U CPU、16.0 GB 内存和 64 位 Windows 10 上的结果。

如您所见,所有四种任务都得到了相同的求和结果。使用 x86 传统指令的原始方法需要超过 80 秒。对于 SIMD 技术,MMX 方法仅需要 10% 的时间,耗时 7 秒;SSE 方法耗时不到 4 秒;AVX 方法将时间缩短了一半,仅需 2 秒。x86 汇编执行过程中的激进变化带来了显著的改进。
现在,我们逐一看看每个实现。稍后,我还会展示基准测试的入口点,并提供 irvine32 库的支持。
传统方式的简单逻辑
下面的 SumArrayOriginal 过程易于理解。在本文中,我始终使用具有两个参数的原型:字节数组地址 arrayPtr 和数组长度 count,这与 SumArrayCPP 中的参数相同。我设置一个循环,将每个字节零扩展为双字(doubleword)后简单地相加,并将总和返回到 EAX。
;-------------------------------------------------------------
SumArrayOriginal PROC uses ECX, arrayPtr:PTR BYTE, count:DWORD
; Performs a summation for an 8-bit BYTE array
; Returns: sum in EAX
;-------------------------------------------------------------
mov eax,0 ; set the sum to zero
mov esi,arrayPtr
mov ecx,count
cmp ecx,0 ; array size <= 0?
jle L2 ; yes: quit
L1:
movzx EBX, BYTE PTR[esi] ; add each integer to sum
add EAX, EBX
add esi,TYPE BYTE ; point to next integer
loop L1 ; repeat for array size
L2:
ret
SumArrayOriginal ENDP
MMX 执行逻辑与实现
MMX 技术增加了八个 64 位寄存器,命名为 MM0 到 MM7,如下面调试时的 *Visual Studio Registers* 窗口所示。
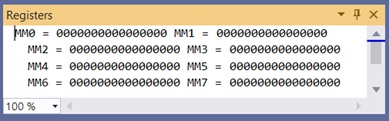
它们可以用于执行 SIMD 操作,使用八个 8 位整数作为打包的 BYTE,四个 16 位整数作为打包的 WORD,或两个 32 位整数作为打包的 DWORD。

SumArrayMMX 过程返回与之前的 SumArrayOriginal 相同的結果,但执行时间显著减少了 90%。这种改进是基于打包加法实现的。这里提到的十个 MMX 指令是:pxor、movq、punpcklbw、punpckhbw、paddw、punpcklwd、punpckhwd、paddd、psrlq 和 movd。您可以在 x86 and amd64 instruction reference 中搜索以找到详细描述。在这里,我将逐步讲解 SumArrayMMX 的实现逻辑。
SumArrayMMX 保持与之前相同的双参数原型。在初始化时,我将循环计数器 ECX 设置为 count 除以 16,因为每次迭代处理 16 个字节的打包加法。为简单起见,这要求数组大小是 16 的倍数,例如这里的 64K(65536)。然后将数组地址设置为 EAX,并将 mm4、mm5 和 mm7 清零。
;-------------------------------------------------------------
SumArrayMMX PROC uses ECX, arrayPtr:PTR BYTE, count:DWORD
; Performs a summation for an 8-bit BYTE array
; Returns: sum in EAX
;-------------------------------------------------------------
; Initialize
mov ecx, count ;ecx = 'n'
shr ecx, 4 ;ecx = number of 16-byte blocks
mov eax,arrayPtr ;pointer to array 'x'
pxor mm4,mm4
pxor mm5,mm5 ;mm5:mm4 = packed sum (4 dwords)
pxor mm7,mm7 ;mm7 = packed zero for promotions
接下来,启动一个循环,将前 8 个字节保存在 mm0 和 mm2 中,同时将紧随其后的第二个 8 个字节保存在 mm1 和 mm3 中。
; Load the next block of 16 array values
@@:
movq mm0,[eax]
movq mm1,[eax+8] ;mm1:mm0 = 16 byte block
movq mm2,mm0
movq mm3,mm1
例如,mm1、mm3、mm0 和 mm2 可能看起来像这样:

现在,我必须在进行打包加法之前,将上述每个字节扩展为字(word)。简单地使用 punpcklbw(低位字节扩展为字)和 punpckhbw(高位字节扩展为字)。
; Promote array values from bytes to words
punpcklbw mm0,mm7 ;mm0 = 4 words
punpcklbw mm1,mm7 ;mm1 = 4 words
punpckhbw mm2,mm7 ;mm2 = 4 words
punpckhbw mm3,mm7 ;mm3 = 4 words
使用这个示例,mm1、mm3、mm0 和 mm2 可以是:

现在是并行执行打包字加法的时候了。
; Packed additions for words
paddw mm0,mm2
paddw mm1,mm3
这是结果:

另一个打包字加法是将上面的 mm0 和 mm1 相加,结果存入 mm0。
; Packed additions for words
paddw mm0,mm1 ;mm0 = pack sums (4 words)
现在有 4 个字了。

接下来,对 mm0 中的字执行类似的步骤。首先将 mm0 复制到 mm1,然后使用 punpcklwd(低位字扩展为双字)和 punpckhwd(高位字扩展为双字)将每个字扩展为双字。
; Promote packed sums to dwords, then update dword sums in mm5:mm4
movq mm1,mm0
punpcklwd mm0,mm7 ;mm0 = packed sums (2 dwords)
punpckhwd mm1,mm7 ;mm1 = packed sums (2 dwords)
然后我得到了:

最后,只需将两个双字打包加到 mm4 中,将另外两个双字打包加到 mm5 中。这些双字在循环的每次迭代中连续累积到 mm4 和 mm5 中,直到完成。
; Packed additions for doublewords
paddd mm4,mm0
paddd mm5,mm1 ;mm5:mm4 = packed sums (4 dwords)
add eax,16 ;eax = next 16 byte block
dec ecx
jnz @B ;repeat loop if not done
所有计算完成后,我以 mm4 包含两个双字,mm5 包含另外两个双字来退出循环。现在执行打包双字加法,将 mm5 与 mm4 相加,结果存入 mm5。为了计算最终总和,我将 mm5 复制到 mm6,并将 mm6 中的高位双字右移。因此,最后一次打包加法是将 mm5 与 mm6 相加。mm6 中的最终总和是低位双字,它被移入 EAX 作为返回值。
; Compute final sum_x
paddd mm5,mm4 ;mm5 = packed sums (2 dwords)
movq mm6,mm5
psrlq mm6,32 ;mm6 Shifted Right Logical 32 bits
paddd mm6,mm5 ;mm6[31:0] = final sum_x
movd eax,mm6 ;eax = sum_x
ret
SumArrayMMX ENDP
SSE 执行逻辑与实现
SSE 技术增加了八个 128 位寄存器,命名为 XMM0 到 XMM7,如下面调试时的 *Visual Studio Registers* 窗口所示。

它们可以用于执行 SIMD 操作,使用十六个 8 位整数作为打包的 BYTE,八个 16 位整数作为打包的 WORD,四个 32 位整数作为打包的 DWORD,或两个 64 位整数作为打包的 QWORD。

SumArraySSE 过程返回与之前相同的結果,但执行时间缩短了一半,与 SumArrayMMX 相比。这种改进是直观的,因为用于打包操作的寄存器大小翻倍了。这里使用的 SSE 指令与 MMX 的几乎相同,如以下章节所示。
SumArraySSE 保持与之前相同的双参数原型。现在我可以一次处理 32 个字节的打包加法,并将循环计数器 ECX 初始化为 count 除以 32。同样,为简单起见,这要求数组大小是 32 的倍数,例如这里的 64K(65536)。然后将数组地址 EAX 设置为 xmm4、xmm5 和 xmm7 已清零。
;-------------------------------------------------------------
SumArraySSE PROC uses ECX, arrayPtr:PTR BYTE, count:DWORD
; Performs a summation for an 8-bit BYTE array
; Returns: sum in EAX
;-------------------------------------------------------------
; Initialize
mov ecx, count ;ecx = 'n'
shr ecx, 5 ;ecx = number of 32-byte blocks
mov eax,arrayPtr ;pointer to array 'x'
pxor xmm4,xmm4
pxor xmm5,xmm5 ;xmm5:xmm4 = packed sum (4 dwords)
pxor xmm7,xmm7 ;xmm7 = packed zero for promotions
这次,我将直接从 *Visual Studio 调试* 环境中跟踪一个示例。内存中的第一个 32 字节块可能如下所示:

与 MMX 方法类似,我将前两个 16 字节块保存在 xmm0 和 xmm1 中。
; Load the next block of 16 array values
@@:
movdqa xmm0,xmmword ptr [eax]
movdqa xmm1,xmmword ptr [eax+16] ;xmm1:xmm0 = 32 byte block
请注意 Intel 规范中内存的**小端序(Little-Endian)**概念,xmm0 和 xmm1 变为:

接下来,使用四个寄存器将字节扩展为字。
; Promote array values from bytes to words, then sum the words
movdqa xmm2,xmm0
movdqa xmm3,xmm1
punpcklbw xmm0,xmm7 ;xmm0 = 8 words
punpcklbw xmm1,xmm7 ;xmm1 = 8 words
punpckhbw xmm2,xmm7 ;xmm2 = 8 words
punpckhbw xmm3,xmm7 ;xmm3 = 8 words
现在 xmm0、xmm1、xmm2 和 xmm3 都已通过 punpcklbw 和 punpckhbw 提升为打包字。

打包字加法之后:
; Packed additions for words
paddw xmm0,xmm2
paddw xmm1,xmm3
结果是 xmm0 中的八个打包字和 xmm1 中的另外八个字。

现在通过复制 xmm2 和 xmm3 并进行四次提升,将值从打包字扩展到双字。
; Promote array values from WORDs to DWORDs
movdqa xmm2,xmm0
movdqa xmm3,xmm1
punpcklwd xmm0,xmm7 ;xmm0 = 4 dwords
punpcklwd xmm1,xmm7 ;xmm1 = 4 dwords
punpckhwd xmm2,xmm7 ;xmm2 = 4 dwords
punpckhwd xmm3,xmm7 ;xmm3 = 4 dwords
我现在分别在 xmm0、xmm1、xmm2 和 xmm3 中有四个打包双字。

然后进行打包双字加法求和。
; Then sum the DWORDs
paddd xmm0,xmm2
paddd xmm1,xmm3
结果是 xmm0 中的四个打包双字和 xmm1 中的四个打包双字。

最后,与 MMX 代码逻辑类似,我将四个双字打包加到 xmm4 中,将另外四个双字打包加到 xmm5 中。寄存器 xmm4 和 xmm5 在每次迭代中不断累积 xmm0 和 xmm1 的结果,直到循环完成。
; Already packed sums to dwords, just update dword sums in xmm5:xmm4
paddd xmm4,xmm0
paddd xmm5,xmm1 ;xmm5:xmm4 = packed sums (4 dwords)
add eax,32 ;eax = next 32 byte block
dec ecx
jnz @B ;repeat loop if not done
循环结束后,xmm4 和 xmm5 分别包含四个双字作为打包总和。

现在执行打包双字加法,将 xmm4 的内容加到 xmm5 中。为了计算最终总和,还需要更多步骤。我将 xmm5 复制到 xmm6,并将 mm6 的高位四字(quadword)右移 64 位(使用 PSRLDQ,以字节为单位),这与 MMX 的 psrlq(以位为单位移位)不同。我必须使用 PSRLDQ(Packed Shift Double Quadword Right Logical)来进行字节移位,而不是位的移位。有关详细信息,请参阅 x86 and amd64 instruction reference。然后我进行打包加法,在 xmm5 中得到总和。
; Compute final sum_x
paddd xmm5,xmm4 ;xmm5 = packed sums (4 dwords)
movdqa xmm6,xmm5
PSRLDQ xmm6, 8 ;xmm6 Shifted Right Logical 8 bytes
paddd xmm5,xmm6
实际上,总和现在包含在低位四字中,作为 xmm5 中的两个双字,而无需关心 xmm5 的高位四字。

最后一步是将 xmm5 中的两个低位双字相加。我将其复制到 xmm6,并将 xmm6 的高位双字右移 32 位(使用 PSRLDQ,以字节为单位)。在最后一次打包双字加法后,xmm6 中低位双字里的最终总和被传递到 EAX 作为返回值。
movdqa xmm6,xmm5
PSRLDQ xmm6, 4 ;xmm6 Shifted Right Logical 4 bytes
paddd xmm6,xmm5 ;xmm6[31:0] = final sum_x
movd eax,xmm6 ;eax = sum_x
ret
SumArraySSE ENDP
AVX 执行逻辑与实现
AVX 技术增加了额外的 128 位,将 SSE 的 XMM0 到 XMM7 扩展为八个 256 位寄存器,命名为 YMM0 到 YMM7,如下面调试时所示。

它们可以用于执行 SIMD 操作,使用三十二个 8 位整数作为打包的 BYTE,十六个 16 位整数作为打包的 WORD,八个 32 位整数作为打包的 DWORD,或四个 64 位整数作为打包的 QWORD。

SumArrayAVX 过程返回与前三个相同的結果,但执行时间进一步缩短。这是合理的,因为寄存器大小再次翻倍,从 128 位增加到 256 位。这里使用的 AVX 指令也类似,只是增加了 'v' 前缀,并且有三个操作数。
由于 YMM 寄存器非常大(256 位),我希望简化 SumArrayAVX 的逻辑,而不是像 MMX 和 SSE 那样的模式。在循环中,我一次处理 32 个字节,而不是分成两个分支处理 64 个字节。为此,我仍然将循环计数器 ECX 初始化为 count 除以 32。当循环开始时,我只将 32 个字节加载到 ymm1 中。
;-------------------------------------------------------------
SumArrayAVX PROC uses ECX, arrayPtr:PTR BYTE, count:DWORD
; Performs a summation for an 8-bit BYTE array
; Returns: sum in EAX
;-------------------------------------------------------------
; Initialize
mov ecx, count ;ecx = 'n'
shr ecx, 5 ;ecx = number of 32-byte blocks
mov eax,arrayPtr ;pointer to array 'x'
vpxor ymm0, ymm0, ymm0
vpxor ymm5, ymm5, ymm5
@@:
; Load the next block of 32 bytes from array
vmovdqa ymm1,ymmword ptr [eax]
让我们仍然使用与之前相同的数组示例,内存中的前 32 个字节如下:

在加载时,ymm1 根据**小端序(Little-Endian)**概念,将内存中的所有 32 个字节存储为:

接下来,将字节扩展为字,并执行打包字加法。
; Packed additions for words
VPUNPCKLBW ymm2, ymm1, ymm0
VPUNPCKHBW ymm3, ymm1, ymm0
vpaddw ymm4, ymm2, ymm3 ;add words low and high
这是 ymm4 中的打包字结果,您可以手动将 ymm2 和 ymm3 相加进行验证。

接下来,在 ymm2 和 ymm3 中将字扩展为双字,并对 ymm4 执行打包加法。
; Packed additions for doublewords
vmovdqa ymm1,ymm4
VPUNPCKLWD ymm2, ymm1, ymm0
VPUNPCKHWD ymm3, ymm1, ymm0
vpaddd ymm4, ymm2, ymm3 ;add dwords low and high
这是 ymm4 中的打包双字结果,同样可以手动验证。

寄存器 ymm5 是总和累加器,在循环完成之前,在每次迭代中不断地将 ymm4 中的八个双字相加。
; Packed addition last for doublewords
vpaddd ymm5, ymm5, ymm4 ;ymm5 = packed sums (8 dwords)
add eax,32 ;eax = next 32 byte block
dec ecx
jnz @B ;repeat loop if not done
完成后,为了得到最终总和,我需要做更多技巧。我需要使用 VPERMQ(编码为 00001110b)将 ymm5 中的上部两个 QWORD 移动到 ymm4。有关这个 *Qwords Element Permutation* 指令,请查阅 x86 and amd64 instruction reference。
; Compute final sum_x
vmovdqa ymm4, ymm5
; Qwords Element Permutation to move upper QWORD to xmm4
vpermq ymm4, ymm4, 00001110b
然后,我在 ymm4 和 ymm5 中都有了低部的两个四字。

现在,我只需要关注 ymm4 和 ymm5 中的两个低位四字,每个四字包含 4 个双字。这与 SumArraySSE 结束时的场景完全相同。因为 YMM0 到 YMM7 只是 XMM0 到 XMM7 的 128 位扩展,我可以使用 YMM 中的两个低位四字,如 SSE 中的 XMM 寄存器一样。因此,为了方便,我直接重用了那部分代码。
; Reuse this part of code in SSE
paddd xmm5,xmm4 ;xmm5 = packed sums (4 dwords)
movdqa xmm6,xmm5
PSRLDQ xmm6, 8 ;xmm6 Shifted Right Logical 8 bytes
paddd xmm5,xmm6
movdqa xmm6,xmm5
PSRLDQ xmm6, 4 ;xmm6 Shifted Right Logical 4 bytes
paddd xmm6,xmm5 ;xmm6[31:0] = final sum_x
movd eax,xmm6 ;eax = sum_x
ret
SumArrayAVX ENDP
基准测试驱动
为了测试从 SumArrayOriginal 到 SumArrayMMX/SSE/AVX 的四种过程,我必须创建一个基准程序,允许您输入循环次数并显示测量结果。一种方法是简单地将所有输入/输出任务委托给高级语言,这就像一些入门教程所使用的那样。但对于我们的基准测试,我更倾向于使用纯汇编代码,直接从操作系统调用 I/O,以实现更直接和准确的测量。为此,我建议链接到 Assembly Language for x86 Processors 上的 irvine32 库。您可以访问 Getting started with MASM and Visual Studio 2019 下载并安装该静态链接库来构建我附带的项目。作为参考,请参阅加州州立大学多明格斯山分校提供的在线 Irvine32 Library Help。
我需要两个辅助函数:一个用于生成伪随机字节并将其保存在数组中。
;----------------------------------------------------------------
FillArray PROC USES eax, pArray: DWORD, Count: DWORD
; Fills an array with a random sequence of 32-bit signed 1 to 255
; integers between LowerRange and (UpperRange - 1).
; Returns: nothing
;----------------------------------------------------------------
LOWVAL = 1h ; minimum value
HIGHVAL = 0FFh ; maximum value
; call Randomize
mov edi,pArray ; EDI points to the array
mov ecx,Count ; loop counter
L1:
mov eax,HIGHVAL ; get absolute range
call RandomRange
add eax,LOWVAL ; bias the result
stosb ; store AL into [edi]
loop L1
ret
FillArray ENDP
另一个是可重用的函数,用于输出四个过程调用的结果。
;----------------------------------------------------------------
OutputResult PROC uses edx,
resSum:DWORD, msec:DWORD, labMethod:PTR BYTE, labTime:PTR BYTE
;----------------------------------------------------------------
call GetMseconds ; get stop time
sub eax, msec
mov msec, eax
mov EDX, labMethod
call WriteString
mov eax, resSum
call WriteDec
mov EDX, labTime
call WriteString
mov eax, msec
call WriteDec ; display elapsed time
ret
OutputResult ENDP
我们的基准测试入口点可以这样开始:
;------------------------------------------------------------
mainBenchmark PROC
;------------------------------------------------------------
; Ask for count input
mov EDX, offset InputLabel2
call WriteString
call ReadDec
mov LoopCounter, eax
; Fill an array with random signed integers
INVOKE FillArray, ADDR array, LENGTHOF array
然后我这样进行每个测试:
; Original approach:
call GetMseconds
mov tm,eax
mov ECX, LoopCounter
LL1:
INVOKE SumArrayOriginal, ADDR array, MAX_ARRAY_SIZE
loop LL1
INVOKE OutputResult, eax, tm, addr LbSumOrg, addr TimeElapsed
call Crlf
; MMX approach:
call GetMseconds
mov tm,eax
mov ECX, LoopCounter
LL2:
INVOKE SumArrayMMX, ADDR array, MAX_ARRAY_SIZE
loop LL2
INVOKE OutputResult, eax, tm, addr LbSumMMX, addr TimeElapsed
call crlf
; SSE approach:
...
; AVX approach:
...
call WaitMsg
exit
mainBenchmark ENDP
最后但同样重要的是 MASM 的 *32 位指令* .XMM,它必须在开头声明。该指令的名称听起来含糊或不准确,因为它启用了本文中迄今为止所需的所有 SIMD 指令(包括 MMX、SSE 和 AVX)的汇编。
关于汇编编程的注意事项
本文讨论的汇编代码可以通过其 MASM 项目文件下载,并在最近的 Visual Studio 中运行。然而,当您的 Visual Studio 与 VC++ 正常工作时,并不意味着它可以运行一个*纯粹*的汇编代码项目。主要是出于安全原因,构建或启动汇编可执行文件可能会被防病毒应用程序或系统设置阻止。Visual Studio 可能出现的致命错误包括 LNK1104、ML A1000 等。这些错误难以理解,因为它们没有提供具体信息。
这是 Windows 10 中被 Defender 阻止的汇编代码的示例。

这里有一些解决方法。对于防病毒应用程序,如果有一个可编辑的例外或排除选项,请将您的汇编代码测试文件夹添加到排除项中。以下是 Windows 10 中 Defender 的排除项选项。

如果没有这样的选项,但有禁用选项,可以暂时禁用它进行测试,但这将使您的计算机处于 unprotected 状态。您还可以阅读 Was your program's EXE file blocked by an anti-virus scanner?。
总结
我花费了大量精力来探索如此简单的程序的优化。您可以想象,对于软件编译器来说,需要投入多少精力来创建一个智能的实用工具。要了解编译器的行为,您可以使用反汇编器从 C/CPP 程序反向工程到汇编列表。有两种构建可用:*Debug* 构建相对易于阅读,几乎映射到原始逻辑,通常使用传统汇编;而 *Release* 构建则很难理解,因为它通常使用 SIMD 等现代汇编进行优化。您可以尝试在 *Visual Studio* 中构建本文提到的 SumArrayCPP 来观察,尽管其他平台的反汇编器会产生不同的汇编列表。另一个需要注意的地方是,编译器通常会随着技术的进步而升级,以集成新指令。因此,*Release* 的反汇编列表可能会因不同时期应用的优化方法(如本文所述)而与 *Visual Studio* 2010 到 2019 的有所不同。
写这篇文章的直接动机是为我在 CSCI 241 Assembly Language Programming 的学生提供一个简洁的补充材料。课程大纲主要侧重于传统的 *x86-64* 汇编语言编程。在密集学习后,学生们希望能更广泛地了解和体验现代汇编语言。虽然有很多不错的书籍,它们提供了详细的 SIMD 描述,但很难在几个小时内选择一本进行讲授。因此,我希望本文能为对现代汇编语言感兴趣的初学者提供有用的阅读和实践材料。
最近在软件行业,不同类型的汇编语言在新设备、移动和微芯片设计等方面发挥着重要作用。特别是,汇编项目的性能在时间和空间效率方面始终被强调为一个关键因素。在学术上,汇编语言编程被认为是大多数大学计算机科学课程中要求最高的课程之一。随着技术的不断进步,优化可以成为一个在更多领域进行讨论的好话题。
历史
- 2021 年 3 月 26 日:发布原版。