
深入了解机器翻译
5.00/5 (1投票)
本文介绍构建基于机器学习的翻译器所需的主要理论概念。
引言
谷歌翻译的效果非常好,它常常看起来像魔术。但它不是魔术——它是深度学习!
在本系列文章中,我们将向您展示如何使用深度学习来创建一个自动翻译系统。本系列可以被视为一个逐步教程,帮助您理解和构建神经机器翻译。
本系列假定您熟悉机器学习的概念:模型训练、监督学习、神经网络,以及人工神经元、层和反向传播。
在我们开始编写代码之前,我们将快速深入了解人工智能语言翻译的工作原理。如果您想跳过数学部分直接开始编写代码,可以跳到“构建人工智能语言自动翻译系统的工具”。新闻
神经机器翻译(NMT)的运行机制
以下是我们用来构建自动翻译机器的主要工具和概念,在这种情况下,我们将从英语翻译成俄语。
- 循环神经网络(RNN)和长短期记忆(LSTM)
- 编码器和解码器
- 门控循环单元(GRU)
- 注意力机制
- 嵌入
- 语言模型
RNN 和 LSTM
首先,我们来看一下 RNN 的结构。一个基本的 RNN 结构如下图所示。正如您所见,该结构由层组成——\(layer_{0},layer_{1},...layer_{k},layer_{k+1},...\)——它们形成一个定向序列。
输入向量 \(X = (X_{0},...X_{n})\) 被转换为输出向量 \(Y = (Y_{0},...Y_{n})\)。
![]()
每一层都会产生一个激活值 \(a_{t}\)(就像任何神经网络层一样),但它也*直接*产生一个输出 \(Y_{t}\),这是 \(a_{t}\) 的一个函数。
描述我们简单 RNN 的方程如下:
和
其中:F 和 G 是激活函数,而 \(\alpha ,\beta ,\delta ,\epsilon \) 是取决于层系数的变量。
我们讨论的 RNN 被称为多对多:多个输入和多个输出。这通常是我们用于机器翻译(MT)的。具有唯一输入和多个输出的 RNN 被称为一对多 RNN,具有多个输入和唯一输出的 RNN 被称为多对一 RNN。
RNN 不仅在 MT 领域有用,还成功应用于语音识别、音乐生成、情感识别等领域。
在 MT 的情况下,我们需要一种略有不同的 RNN 类型。
![]()
在上图所示的图中,输入向量的 *k* 个分量是英语句子的单词,输出向量的 *l* 个分量是俄语翻译句子的单词。
LSTM 是先进的、经过改进的 RNN 架构,为更高效的 RNN 设计提供了支持。在这种设计中,几个(或所有)层被替换为 LSTM 单元。这些单元的构建方式与“普通”RNN 层不同。
让我们比较一下普通层和 LSTM 单元。很难精确地说明为什么 LSTM 单元比普通 RNN 层更有效,但它肯定更复杂。
一个 LSTM 单元有两个门:输入门  和遗忘门
和遗忘门  。西格玛符号表示线性组合[1](加上一个常数)。它还传递深度学习的隐藏状态[2]。
。西格玛符号表示线性组合[1](加上一个常数)。它还传递深度学习的隐藏状态[2]。

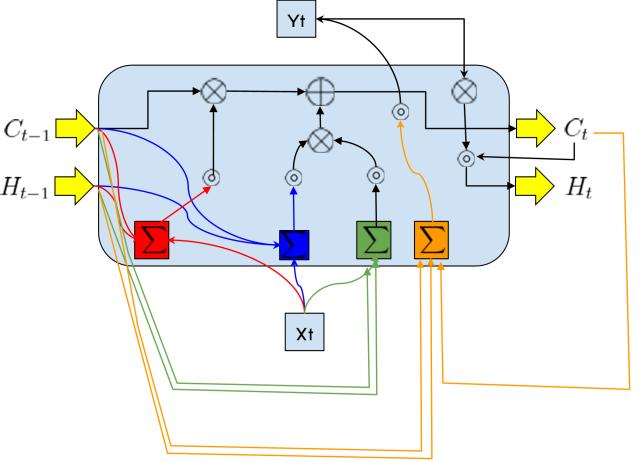
该单元模拟了人类的遗忘概念。例如,遗忘非必要信息。它是完全循环的,因为它也会重新输入前一个状态。
详细解释 LSTM 为什么如此擅长它所做的事情需要很多篇幅,但至少现在可视化起来更容易了。我们还想证明神经网络实际上是“抽象”的逻辑电路,其概念设计而非代码实现。
我们在上面适合 MT 的 RNN 图中已经说明了编码器-解码器的概念。实际上,这是两个 RNN。一个是编码器,它将一个单词序列编码成一个固定长度的向量;另一个是解码器,它执行相反的操作。这种 RNN 被称为序列到序列 RNN。
门控循环单元(GRU)
GRU 只是一个功能较少的 LSTM 单元,在某些方面可能比“普通”LSTM 表现更好。它可以用来简化一些设计,并且通常比普通 LSTM 运行得更快。在此项目中我们不使用 GRU,但在这里提及它很重要,因为如果您决定进一步探索人工智能语言翻译,您很可能会遇到它。
注意力机制
该注意力机制是 NMT 中的一个关键概念,相对较晚引入。它赋予待翻译句子中一个或多个单词更多的“权重”(重要性)。这个简单的机制解决了 NMT 中以前难以解决的许多问题。
嵌入
词嵌入是对单词的多维表示,它提供了有关该单词的统计信息,并将其与其他具有相似含义或密切关系的“基础”单词联系起来。例如,“猞猁”这个词可能被嵌入为相关术语列表,如(猫、动物、野生),每个术语都关联着一些坐标。
词嵌入促进了 skip-gram 技术:预测给定单词周围的单词。
语言模型
语言模型——或自然语言的语言表示——提供了一种语言的参数化视图,其中包含同义词、单词和句子之间的相似性等。在 AI 翻译系统中常用的语言模型示例包括 BERT、Word2vec、GloVe 和 ELMo。
后续步骤
在本系列文章的下一篇文章中,我们将讨论构建基于深度学习的自动翻译系统所需的工具和软件。敬请关注!