
Azure Synapse Analytics 实时数据科学和 BI 系列第三部分:执行实时数据科学和商业智能
5.00/5 (1投票)
在本文中,我们将探讨 Azure Synapse Studio 的功能,以便几乎无需编写代码即可查询、筛选和聚合数据。
在本系列的第一篇文章中,我们讨论了如何在不影响应用程序性能的情况下分析实时数据。在第二篇文章中,我们准备了 Azure Cosmos DB 帐户,添加了零售销售样本数据,创建了 Azure Synapse 工作区,并链接了 Azure Synapse Studio。
在这里,我们将设置 Power BI 来显示我们的数据,帮助我们深入了解零售销售业绩。
查询数据
让我们开始使用 Synapse Apache Spark 查询我们的零售销售数据。Azure Synapse Studio 中的手势提供了示例代码,可以快速开始查询已链接的 Azure Cosmos DB 数据库中的数据。我们可以通过“数据”选项卡中的“操作”上下文菜单访问手势。下图显示了我们在上一篇文章中创建的 SalesData 和 SalesDataHTAP 容器的手势


我们看到,在最一般的情况下(启用了 HTAP 的容器),我们可以通过三种方式查询数据:
- 加载到 DataFrame:在这种情况下,Synapse Analytics 将数据导入为 DataFrame。它会在 Spark 会话的生命周期内缓存数据。这意味着 Azure Synapse 将分析存储快照加载到 DataFrame 中。因此,Azure Synapse 会评估我们在 DataFrame 上执行的所有操作是否针对此快照。实际上,当我们更新分析存储中的数据时,DataFrame 中不会看到更新。
- 创建 Spark 表:与前一种情况相反,Azure Synapse 将数据从分析存储导入到 Spark 表中。每次执行我们针对 Spark 表执行的查询时,都会从底层存储重新加载数据。
- 从容器加载流式 DataFrame:Azure Synapse 将数据从分析存储加载到 DataFrame,并将其存储在主数据湖帐户中,即我们在创建 Azure Synapse 工作区时配置的帐户。
创建 Spark 表并分析数据
为了演示数据导入,让我们从 SalesDataHTAP 创建 Spark 表。为此,我们使用“创建 Spark 表”手势,该手势将生成以下代码:
%%sql
-- Create a Spark table over Cosmos DB analytical store
-- To select a preferred list of regions in a multi-region Cosmos DB account, add spark.cosmos.preferredRegions '<Region1>,<Region2>' in the config options
create table YOURTABLE using cosmos.olap options (
spark.synapse.linkedService 'CosmosDb_Sales_Info',
spark.cosmos.container 'SalesDataHTAP'
)
我们通过替换 YOURTABLE 占位符为 SalesDataHTAP 来修改此手势。

在运行笔记本之前,我们需要附加 Apache Spark 池。我们可以通过 Synapse Studio 的“管理”选项卡来完成此操作。但是,我们可以使用“附加到”下拉列表(请参阅上面屏幕截图的上半部分)中的“管理池”选项快速导航到此视图。此选项会带我们进入另一个视图,在该视图中,我们可以单击“创建 Apache Spark 池”按钮或“+”图标。
Apache Spark 池配置窗格会显示在右侧。我们使用此窗格配置新池。
我们使用以下值:
- Apache Spark 池名称:synapseap
- 节点大小:small
- 自动缩放:disabled
- 节点数:three

设置 Apache Spark 池后,我们可以创建新的 **synapseap** 池(Apache Spark 池名称)并单击“全部运行”按钮来启动笔记本。

从 Azure Cosmos DB 获取数据需要一些时间。我们应该会看到类似以下的输出:

我们现在将使用导入的数据。让我们创建一个新单元格(单击输出下方的“+”图标,然后选择“代码单元格”)。然后,让我们添加以下代码将数据导入 DataFrame 并显示所有列:
df = spark.sql("SELECT * FROM SalesDataHTAP")
display(df)
执行此代码后,我们应该会看到以下输出:

当然,我们可以使用 DataFrame 进行进一步分析。例如,我们可以按年份计算项目数:
df.groupBy('Year').count().show()
它会产生如下输出:

结果表显示了每年的项目数。总数为 10,因为我们的 Azure Cosmos DB 中有 10 个项目。
请注意,上述方法不适用于 SalesData 容器,因为它不支持实时快照。如果我们尝试针对此容器运行上述代码,我们将看到以下错误:

总之,当我们创建 Spark 表时,它会显示在“数据”选项卡下的“工作区/数据库”组中。从那里,我们可以访问更多手势,使我们能够快速开始。例如,我们可以使用“新建笔记本/加载到 DataFrame”手势来生成将数据从表加载到 DataFrame(如我们上面使用的)的代码,或者使用机器学习手势。

我们也可以随时使用以下语句删除该表:
spark.sql("SELECT * FROM <TABLE_NAME>")
加载快照到 DataFrame
在学习了如何使用 Spark 表后,我们将了解如何将分析存储的快照加载到 DataFrame。为此,我们可以使用“加载到 DataFrame”手势。它将生成以下代码:
# Read from Cosmos DB analytical store into a Spark DataFrame and display 10 rows from the DataFrame
# To select a preferred list of regions in a multi-region Cosmos DB account, add .option("spark.cosmos.preferredRegions", "<Region1>,<Region2>")
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService", "CosmosDb_Sales_Info")\
.option("spark.cosmos.container", "SalesDataHTAP")\
.load()
display(df.limit(10))
让我们修改此默认代码以添加我们在上一节中进行的聚合 `(df.groupBy('Year').count().show())`。当然,输出看起来相同:

然而,这两种方法的区别将在我们更新底层分析存储时显现出来。
更新分析存储
到目前为止,我们已成功通过两种不同的方法获取了数据并执行了简单的聚合。现在让我们看看实际差异,以展示 Azure Cosmos DB 的 Azure Synapse Link 的优势。
为此,我们将修改 Azure Cosmos DB 中的数据。最简单的方法是使用我们的 ImportSalesData 笔记本,并向表中插入超过 10 个项目。我们可以将 data_count 从 10 更改为 30,然后在 Azure Cosmos DB 下重新运行笔记本。

现在,让我们回到 Azure Synapse Studio 并运行使用“加载到 DataFrame”手势的笔记本。我们将看到输出没有改变,即使在刷新了整个 CosmosDb_Sales_Info 链接后也是如此。我们刚才捕获的数据快照将在整个 Spark 会话中保持有效。刷新信息的唯一方法是启动新会话。
但是,如果我们现在回到使用 Spark 表的第一个笔记本,我们可以在不重启 Spark 会话的情况下刷新数据。

但是,刷新数据有时可能需要重新创建表。请记住,您可以使用以下语句删除现有表:
spark.sql("DROP TABLE SalesDataHTAP")
预览数据
在上面的示例中,我们使用了一种相对简单的方法来聚合和以简单表格形式呈现我们的销售数据。借助 Azure Synapse Studio,我们可以快速完成更多工作,例如无需编写代码即可制作可自定义的图表。制作这些图表的工作方式与 Azure 机器学习 Studio 非常相似。因此,如果您熟悉该工具,就可以轻松切换到 Azure Synapse Studio。
为了演示此功能,我们从表中加载数据到 DataFrame,然后显示它:
df = spark.sql("SELECT * FROM default.salesdatahtap")
display(df)
结果数据将显示在表中。我们使用“视图”切换来更改默认设置,从“表格”更改为“图表”。然后,我们打开“视图选项”(右上角的一个小图标)。这将打开另一个窗格,我们在其中按如下方式配置选项:
- 图表类型:column chart
- Key:country
- Values:price
- Series Group:year
- Aggregation:sum
- Stacked:checked
- Aggregating overall results:unchecked
下图显示了此配置以及示例结果:

我们的图表按国家/地区显示年度销售价格。
在 Power BI 中创建图表
如果我们希望获得更全面的数据可视化,我们可以将 Azure Synapse Studio 与 Microsoft Power BI 进一步链接。然后,我们可以像使用 Power BI Desktop 或 Power BI 服务一样,从我们的数据构建交互式 Power BI 图表。具体来说,我们使用 Azure Synapse Studio 生成可下载的数据集。
要创建此数据集,我们使用 Azure Synapse Studio 中的专用 SQL 池。一旦我们拥有了这个池,我们就可以导入所需的数据。我们可以首先实际执行数据清理或聚合,然后在专用 SQL 池中创建一个新表。
基于此,Azure Synapse Studio 会创建一个 *.pisb 文件,我们下载该文件,然后将其导入 Power BI Desktop。然后,我们使用这些数据来生成报表,该报表将在发布到工作区后在 Azure Synapse Studio 中可用。此路径要求我们安装 Power BI Desktop,因此我们需要一台安装了 Windows 10 的计算机。
我们可以在Microsoft 文档中找到所有安装要求和详细信息。
首先,我们需要将 Power BI 与 Azure Synapse Studio 链接。我们转到“管理”选项卡,然后在左侧单击“链接服务”,从那里单击“+ 新建”:

我们看到一个带有一个“连接到 Power BI”按钮的黄色矩形与 Power BI 链接。单击此按钮后,我们需要提供服务名称和订阅。在这里,我们将服务名称设置为 PowerBiSynapseDemo,并在 Power BI 下创建一个名为 SynapseDemo 的工作区。
请注意,要使此功能正常工作,您需要 Power BI Pro 许可证才能在 Power BI 服务中创建工作区。我们需要有一个 Pro 许可证,或者注册一个月的免费 Power BI Pro 试用。
下图总结了我们的配置,我们在其中使用了 SynapseDemo Power BI 工作区:

完成 Power BI 配置后,单击“管理/链接服务”中的“保存”,然后单击“全部发布”按钮。
现在,我们需要创建一个专用 SQL 池。为此,我们遵循Microsoft 文档中的说明。我们转到“管理”选项卡,然后单击“SQL 池/新建”。之后,我们为池命名(例如,SynapseSQLPool),然后选择我们的性能级别。在这里,我们将性能设置为 DW100c 以最大程度地降低成本。
为了继续进行,我们需要将数据复制到此专用 SQL 池。然后,我们生成数据集,可以将其导入 Power BI Desktop。
Azure Synapse Studio 提供了一个连接器,可将数据从 DataFrame 传输到专用 SQL 池中的表。目前,此连接器仅适用于 Scala。
作为补偿,我们首先将数据从 Azure Cosmos DB 加载到 DataFrame。之后,我们筛选此 DataFrame 并将结果保存到 Spark 表。我们使用另一个 Scala 笔记本单元格从 Spark 读取表,然后将其保存到 SynapseSQLPool。
这是第一步的代码:
# Load data from Cosmos DB to Spark table
df = spark.read\
.format("cosmos.olap")\
.option("spark.synapse.linkedService", "CosmosDb_Sales_Info")\
.option("spark.cosmos.container", "SalesDataHTAP")\
.load()
# Select interesting columns and filter out '0' Year
df_filtered = df.select("Year","Price","Country").where("Year > 0")
# Display data
display(df_filtered)
# Write data to a Spark table
df_filtered.write.mode("overwrite").saveAsTable("default.sales")
此代码生成的输出与下图所示的输出类似:

我们还应该在“数据”选项卡(工作区/默认值(Spark)/表/sales)中看到 sales 表。
现在,我们创建一个新单元格,将数据从 Spark 表复制到专用 SQL 池:
%%spark
val scala_df = spark.sqlContext.sql("select * from sales")
scala_df.write.synapsesql("synapsesqlpool.dbo.sales", Constants.INTERNAL)
运行单元格后,我们应该会在 SQL 池中看到新表:

我们可以继续确认数据是否已存在。我们只需使用的操作上下文菜单(dbo.sales)中的“新建 SQL 脚本/SELECT TOP 100 rows”手势。它将创建一个 SQL 查询。运行此查询后,它将产生下图所示的输出:

现在,当数据进入我们的 SQL 池后,我们可以创建 Power BI 报表。我们需要转到“开发”选项卡。它现在包含 Power BI 组,在该组下我们可以找到我们的工作区(例如,PowerBIWorkspaceSynapseDemo)。工作区包含我们的 Power BI 数据集和报表。此时,两者都应该是空的,因为我们创建了一个新工作区。否则,Azure Synapse Studio 会显示我们的工作区元素。
现在,让我们从销售数据创建新的数据集。为此,我们单击 Power BI 数据集上下文菜单中的“打开”选项。然后,将出现一个新窗口,我们在其中单击顶部窗格中的“+ 新建 Power BI 数据集”链接。此操作会在右侧打开新窗格。
此窗格提供了所有进一步的说明,要求我们:
- 下载并安装 Power BI Desktop。如果我们已安装,则可以跳过此步骤。
- 选择数据源。应该只有一个项目:SynapseSQLPool。我们单击它,然后按“继续”按钮。
- 下载 SynapseSQLPool.pbids 文件。

获得数据集后,我们在 Power BI Desktop 中打开它。Power BI Desktop 将要求我们提供凭据。我们切换到我们的 Microsoft 帐户并登录,然后单击“连接”。

从这一点开始,我们将看到一个熟悉的导航器屏幕。在这里,我们将选择所需的表。选择我们的 **Sales** 表,然后单击“加载”。可选地,我们可以在此处进一步转换数据或将此表与其他数据集中的表相关联。单击“加载”后,将出现“连接设置”对话框。使用此对话框通过不选择 DirectQuery 来禁用与 SQL 池的实时连接。

加载数据后,我们可以构建报表。我们将使用地图可视化,并使用来自销售表的以下数据填充属性:
- Location:country
- Legend:year
- Size:price
此配置将渲染以下可视化:
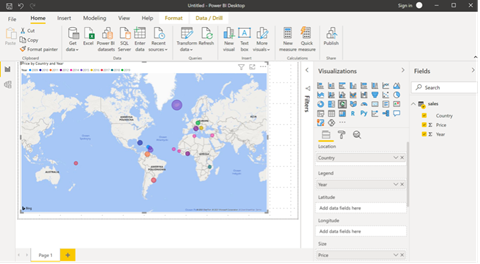
我们现在可以将报表发布到我们的工作区。我们将报表本地保存,然后单击顶部窗格中的“发布”按钮。Power BI Desktop 会要求我们登录到我们的帐户,然后选择目标工作区。我们选择我们之前创建的工作区(SynapseDemo)。

片刻之后,报表将发布,我们可以返回 Azure Synapse Studio。无需刷新 Studio,报表就会在“开发”选项卡(Power BI)下可见。单击报表时,它将像在 Power BI Desktop 和 Power BI 服务中一样渲染。

我们也可以直接从 Azure Synapse Studio 修改报表。此功能使我们能够在不离开环境的情况下调整源数据并立即看到所做的更改。
摘要
本文探讨了 Azure Synapse Studio 的功能,以便几乎无需编写代码即可查询、筛选和聚合数据。为此,我们仅对自动生成的代码块进行了少量修改,使 Azure Synapse Studio 成为数据科学家(可能不专门从事代码开发)的绝佳工具。
我们了解到 Azure Synapse Studio 可以轻松与其他 Azure 服务(如 SQL 池、Spark 池和 Azure Cosmos DB)以及 Microsoft 应用程序(如 Power BI)同步。这些集成使我们能够将数据科学和机器学习管道纳入现有应用程序,以从所有数据中获取见解,而不会减慢应用程序的速度。在 Azure Cosmos DB 的 SQL API 中,我们需要迁移现有容器以支持分析存储。
在本次学习过程中,我们处理了小型数据集以降低将数据写入 Azure Cosmos DB 的成本。但是,Azure Synapse 可以在几分钟内轻松导入数百万行。例如,官方 Azure Synapse 数据集可以在一分钟内将两百万行 NYC Taxi 数据加载到专用 SQL 池。您可以使用本系列文章中的工具和技术来分析您的大型数据集。
请查看 GitHub 存储库以查找更多代码示例。
想要获得更多 Azure Synapse 培训?请查看 Microsoft 的Azure Synapse Analytics 实战培训系列。您可以启动您的第一个 Synapse 工作区,构建无代码 ETL 管道,原生连接到 Power BI,连接和处理流式数据,以及使用无服务器和专用查询选项。