
数据挖掘: SQL Server 中的神经网络简介
3.11/5 (5投票s)
在 SQL Server 中实现神经网络
数据挖掘和神经网络的背景
对于商业和科学数据挖掘都有几种定义。数据挖掘是一种自动对大量数据进行分类以发现行为、模式和趋势的方法。它使公司能够做出主动的、数据驱动的决策。数据挖掘通过利用其历史经验(存储在关系数据库或数据立方体中)来预测未来,从而帮助从大型数据集中发现模式。
那么为什么我们不使用传统的数据仓库呢?数据仓库适用于描述性分析(例如发生了什么)和诊断性分析(例如为什么会发生)。然而,公司还需要进行深入分析,而这正是数据挖掘可以帮助进行预测性分析的地方。
人工智能、机器学习和深度学习现在是常用的术语。在过去几年中,随着人工智能在日常生活的各个方面的应用,包括用于客户服务的聊天机器人等会话式人工智能,情况确实取得了很大进展。
真正智能的机器将是那些能够像人类一样学习、推理和做出决策的机器。**神**经**网**络(NNs)可能是最接近提供答案的。
人脑由相互连接的神经元(神经细胞)网络组成。神经网络试图模仿这些网络。这将使“机器”能够像人类一样学习和做出决策。
我们的大脑以分层的方式进行组织或构建。我们大脑中的不同层处理信息并将其传递给下一层。输入的信息由层的神经元处理,提供洞察,然后将数据/洞察传递给下一层。
以您最喜欢的咖啡馆刚出炉的玛芬蛋糕为例,以及您随后的决策过程。我们的大脑会分多个阶段处理刚出炉的玛芬蛋糕的味道。最初,您闻到玛芬蛋糕的味道(数据输入),然后您会想“我喜欢玛芬蛋糕”(思考——下一层),然后“我至少想要一个玛芬蛋糕”(决定)。
什么是人工神经网络?
人工神经网络(ANN)试图模拟这种分层或多层次的信息处理和决策方法。ANN可以有三个基本的神经元层:输入层(输入数据)、隐藏层(核心处理层)和输出层(决策层)。我们正在以一个简单的ANN为例,但复杂的ANN可能包含多个隐藏层。然而,基本原理保持不变,信息就像在人脑中一样,从一个层流向另一个层。
当然,这是对我们大脑工作方式的非常简化的看法,但我希望您能理解“人工”神经网络试图实现的目标。
算法
输入层:数据挖掘模型的所有输入属性值及其概率
隐藏层:接收来自输入层的数据并为下一层提供输出。各种输入的概率可以被赋予权重。权重指的是输入的重要性。您可以将某个输入视为负值,这意味着该输入不利。
输出层:模型的预测值
SQL Server 中的 Microsoft 神经网络通常比决策树和朴素贝叶斯更高级。

神经网络模型必须包含一个密钥、输入(一个或多个)以及可预测的值(一个或多个)。数据挖掘模型会受到算法可用参数值的影。响。
如果您熟悉 AdventureWorks,我们将使用年龄和性别作为输入层的输入。
隐藏层是中间层,期望为每个输入分配权重。
所有预测的属性都映射到输出层。在此示例中,它是自行车的客户。
神经元以多种技术组合多个输入。类似地,Microsoft 神经网络使用加权和。最大值、平均值、逻辑与、逻辑或。
一旦计算出这些输入,就使用激活函数。“tanh”用作隐藏层的激活函数,而“sigmoid”函数用于输出层。
误差反向传播或反向传播
反向传播就像训练神经网络。它根据前一次迭代的错误率来微调神经网络中的权重。进一步的微调可以降低错误率并提高模型的可靠性。
那么,这在 SQL Server 的 Microsoft 神经网络算法中是如何工作的呢?
最初会为权重分配随机值,然后算法会计算训练数据集的输出和错误。该过程计算输出误差,然后更改或修改权重。整个过程重复进行,直到达到最小误差。
在 SQL Server 中实现人工神经网络
神经网络算法可能是最难解释的一种。SQL Server Analysis Services 提供了一种相对简单的方式来实现该算法以进行数据分析。
SQL Server 是一个非常流行的数据库,但主要用作数据仓库或事务数据存储。SQL Server 支持数据挖掘功能,这些功能对于预测分析非常出色。
本文使用 SQL Server 2019,但 2017 版本也兼容。
在本文中,我们将使用一个示例数据集,您可以下载 AdventureWorks 数据库并将其安装到您的 SQL Server 实例。本文中使用的数据集和示例基于 Adventureworks,这是一个广泛使用的示例集。
创建一个数据挖掘项目。打开 **Microsoft Visual Studio** 并使用 **Analysis Services 多维和数据挖掘模板**创建一个多维项目。您将在解决方案资源管理器中看到该项目。

接下来,我们需要为项目配置数据源。选择一个新的数据连接,如下所示。
数据源连接到示例数据库 AdventureWorksDW2019。

下一步是提供 Analysis Service 连接数据库的凭据。在模拟信息屏幕上,选择“使用特定 Windows 用户名和密码”。

Analysis Service 是用于存储数据挖掘模型的容器。我在本示例中使用了 Windows 身份验证。
数据源将出现在解决方案资源管理器中(参见下面的屏幕截图)。

选择数据源视图。您可以选择项目所需的对象(表和视图的子集)。
在 **选择表和视图** 屏幕上,从“可用对象”中选择 **vTargetMail** 视图以包含在内。您可以筛选对象。如果您选择了具有外键约束的表,可以通过选择 **添加相关表** 来包含相关表。

您可以创建多个数据源视图。但是,对于给定的数据源视图,您只能有一个数据源。
数据源视图现在将出现在 **解决方案资源管理器** 窗口中。
数据挖掘模型
现在基本设置已完成,我们可以开始进行数据挖掘项目。基于数据视图 vTargetMail 模型创建挖掘结构。此视图包含与客户相关的历史数据,这也是我们想要用于数据挖掘模型以进行预测分析的数据。
在 **解决方案资源管理器** 中,突出显示并右键单击“挖掘结构”文件夹,然后创建新的挖掘结构。
将出现以下屏幕用于数据挖掘模型的创建。

在此示例中,我们正在使用现有的关系数据库或数据仓库选项。您可以选择 OLAP 多维数据集。
在下一个屏幕上,选择 Microsoft 神经网络作为数据挖掘技术。

接下来,选择之前创建的数据源视图并选择 vTargetMail。
请记住,我们正在训练神经网络。因此,是时候指定我们将提供什么作为输入以及我们想要预测什么了。
在 **指定训练数据** 页面上,选择 CustomerKey 作为键列。屏幕截图中显示的其余列将用作输入。BikeBuyer 是我们想要了解或预测的,因此请为 BikeBuyer 列勾选“可预测”框。

选择与预测自行车购买者相关的属性。例如,“Email”等属性无关紧要。因此,在本例中,我们选择 Age 和 CommuteDistance 等。预测属性是 BikeBuyer。
还有其他输入列的选择可能会影响我们的预测,例如某人是否已婚(maritalstatus 列),这可能会影响购买自行车的决定。
下一步是更改 Content 和 DataType。
内容类型
离散
内容类型为离散的列包含有限数量的值,这些值之间没有连续性。例如,性别列是典型的离散属性列。此列中的数据只能是特定数量的类别。
这些值不被视为已排序或有序。区号是数值离散数据的示例。离散列不能有小数。
连续
当一列包含表示数值数据且具有可变中间值的值时,该列被视为连续。此类列表示可量化的测量。天气温度是连续属性的一个示例。
神经网络支持连续类型。在此示例中,年龄和年收入是连续的,其他内容类型是离散的。Bike Buyer、Number Cars Owned、Number Children at Home 和 Total Children 等列的内容类型已更改为离散。Bike Buyer 是 True 或 False,因此 Bike Buyer 的数据类型已从 Long 更改为 Boolean。

测试集
接下来创建测试集。
现在让我们用有效的数据集来测试我们的模型。顾名思义,训练数据集用于训练模型,而测试数据集用于测试模型。
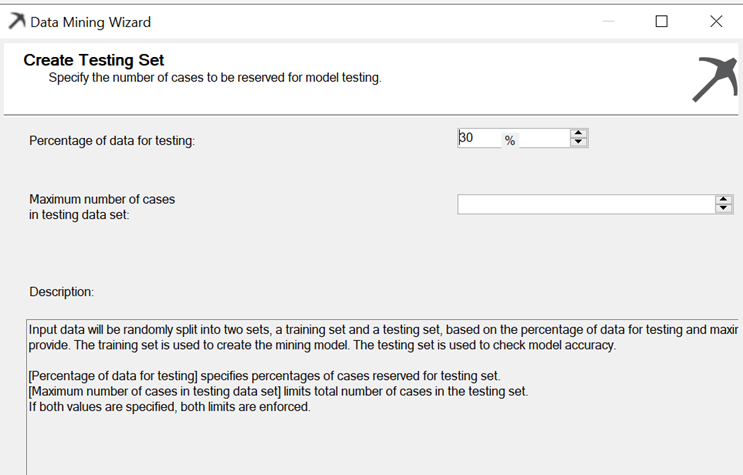
通常,我们将训练/测试数据集的比例设置为 70/30。输入数据将随机分为两组:训练集和测试集。这取决于用于测试的数据百分比和测试数据集中最大记录数。训练集用于创建挖掘模型,而测试集用于检查模型的准确性。
用于测试的数据百分比指定保留用于测试的记录百分比。测试数据集中的最大记录数受限于指定的总测试记录数。如果指定了这两个值,则两者都会生效。
您可以添加另一个模型(挖掘结构可以包含多个挖掘模型以进行比较)来分析年收入。完成此步骤,并为挖掘结构名称和挖掘模型命名。

挖掘结构现在将出现在解决方案资源管理器中。
为了进行比较,我创建了另一个关于收入的模型。如果您选择创建此模型,则在模型创建后,将年收入更改为要预测的值。
处理模型
单击“**挖掘模型查看器**”选项卡。SSAS 对象将部署到项目属性中指定的服务器。当提示“您是否要先生成并部署项目?”时,选择“**是**”。
当“处理挖掘模型”窗口出现时,单击“**运行…**”按钮。


挖掘模型查看器
现在已使用 Microsoft 人工神经网络算法处理了模型,并且可以使用挖掘模型查看器获得自行车购买者模型的分析结果。

上面的屏幕截图显示,收入在 79,000 美元至 154,000 美元之间的“客户”更有可能购买自行车。我们可以进一步筛选结果。在上面的屏幕截图中,我已将年龄筛选到 35-44 岁,通勤距离筛选到 1 到 2 英里。
尝试分析另一个视图,例如单身、女性且拥有两辆车的分析结果。
通过分析这些视图,数据科学家和分析师可以了解哪些因素促使客户购买自行车。
预测
现在我们有了数据挖掘模型,让我们“询问”预测引擎,具有特定特征的客户是否会购买自行车。我们可以为此创建查询。
单击“**挖掘模型预测**”选项卡。点击那里。挖掘模型预测的用户界面如下面的屏幕截图所示。

我们的第一个查询和预测
第一个查询是“一个 36 岁的客户,通勤距离为 1-2 英里,拥有高中教育、专业职业、男性、单身、房屋所有者,年收入为 45,000 美元”是否会购买自行车。
您也可以在 SQL Server Management Studio (SSMS) 中使用 DMX 查询,如下面的屏幕截图所示。我个人更喜欢使用查询而不是用户界面。
SELECT
(Predict([NNetwork].[Bike Buyer])) as [Buyer],
(PredictProbability([NNetwork].[Bike Buyer])) as [Probability_to_buy]
From
[NNetwork]
NATURAL PREDICTION JOIN
(SELECT 36 AS [Age],
'True' AS [Bike Buyer],
'1-2 Miles' AS [Commute Distance],
'High School' AS [English Education],
'Professional' AS [English Occupation],
'M' AS [Gender],
'1' AS [House Owner Flag],
'S' AS [Marital Status],
0 AS [Number Cars Owned],
0 AS [Number Children At Home],
0 AS [Total Children],
45000 AS [Yearly Income]) AS t

上述查询的购买概率为 73.8%。
我们可以在 SSMS 中尝试另一个查询。这次,我们询问“一个 45 岁、通勤 1-2 英里、职业为专业人士、女性、房屋所有者、已婚、拥有 2 辆汽车和 2 个在家儿童,年收入为 80,000 美元”的结果。
SELECT
(Predict([NNetwork].[Bike Buyer])) as [Buyer],
(PredictProbability([NNetwork].[Bike Buyer])) as [Probability_to_buy]
From
[NNetwork]
NATURAL PREDICTION JOIN
(SELECT 45 AS [Age],
'True' AS [Bike Buyer],
'1-2 Miles' AS [Commute Distance],
'High School' AS [English Education],
'Professional' AS [English Occupation],
'F' AS [Gender],
'1' AS [House Owner Flag],
'M' AS [Marital Status],
2 AS [Number Cars Owned],
2 AS [Number Children At Home],
2 AS [Total Children],
80000 AS [Yearly Income]) AS t
我的购买概率为 60.4%。结果可能会因您拥有的数据而异。接下来,我们尝试预测“一个 36 岁、拥有学士学位、职业为专业人士、男性、拥有房屋且单身,年收入为 85,000 美元”的人是否会购买自行车。
SELECT
(Predict([NNetwork].[Bike Buyer])) as [Buyer],
(PredictProbability([NNetwork].[Bike Buyer])) as [Probability_to_buy]
From
[NNetwork]
NATURAL PREDICTION JOIN
(SELECT 36 AS [Age],
'True' AS [Bike Buyer],
'1-2 Miles' AS [Commute Distance],
'Bachelors' AS [English Education],
'Professional' AS [English Occupation],
'M' AS [Gender],
'1' AS [House Owner Flag],
'S' AS [Marital Status],
0 AS [Number Cars Owned],
0 AS [Number Children At Home],
0 AS [Total Children],
85000 AS [Yearly Income]) AS t
结果的概率为 88%。
算法参数
Microsoft 神经网络有可以改进结果的模型参数。我们在示例中使用了默认值。
训练数据挖掘模型需要采取几个步骤。这些步骤受算法参数值的影。响。算法首先从数据源提取训练数据进行评估。一部分训练数据将保留用于评估网络的准确性。这称为**保留数据**。在整个训练过程中,网络在每次遍历训练数据后都会进行评估。当准确性无法进一步提高时,训练过程将停止。
SAMPLE_SIZE 和 HOLDOUT_PERCENTAGE 参数的值用于确定训练数据样本的数量以及要保留的用于保留数据的记录数量。HOLDOUT_SEED 参数的值有助于确定为保留数据随机保留的记录。然后,算法使用 HIDDEN_NODE_RATIO 参数的值来确定隐藏层初始神经元的数量。
您可以在 此处找到更多详细信息。
摘要
尽管 SQL Server 中还有许多其他可用于数据挖掘的算法,但 Microsoft 人工神经网络是最复杂的算法之一。该算法模拟了我们大脑如何通过分层输入和输出进行工作,这使其对数据科学家来说非常强大。
历史
- 2022 年 1 月 8 日:初版