
借助 Intel® Distribution of OpenVINO™ toolkit Execution Provider 和 Intel® DevCloud,为深度学习模型实现更快的性能
0/5 (0投票)
Intel® Distribution of OpenVINO™ toolkit 是一个全面的工具包,可快速开发用于解决各种任务的应用程序和解决方案,包括人类视觉模拟、自动语音识别、自然语言处理、推荐系统等等。
您是否知道,只需一行额外的代码,您就可以将深度学习模型的性能提升近 50%?我们在 i7 CPU1 上使用 ONNX Tiny YOLOv2 对象检测模型时,看到了从 30 FPS 到 47 FPS 的飞跃。这几乎是 50% 的提升,对您的深度学习模型的性能产生了实质性影响。
现在,您一定在想,一行代码如何能为您带来您所寻求的额外性能提升?答案很简单: Intel® Distribution of OpenVINO™ toolkit。 Intel® Distribution of OpenVINO™ toolkit 是一个全面的工具包,可快速开发用于解决各种任务的应用程序和解决方案,包括人类视觉模拟、自动语音识别、自然语言处理、推荐系统等等。OpenVINO™ toolkit 利用最先进的优化技术,专门针对 Intel® 硬件进行了优化,从而提升您深度学习模型的性能。
现在您知道了 OpenVINO™ toolkit 的作用,您一定想知道它如何与 ONNX Runtime (RT) 等流行的 AI 框架集成。像您一样的开发人员,可以通过 ONNX Runtime 获得 Intel® Distribution of OpenVINO™ toolkit 的强大功能,通过加速 ONNX 模型推理来提升性能,这些模型可以从 TensorFlow、PyTorch、Keras 等 AI 框架导出或转换而来。Intel 和 Microsoft 合作创建了 OpenVINO™ Execution Provider for ONNX Runtime,它使 ONNX 模型能够使用 ONNXRuntime API 进行推理,后端为 OpenVINO™。借助 OpenVINO™ Execution Provider,ONNX Runtime 在相同的硬件上比默认的 Intel® CPU、GPU 和 VPU 执行提供程序提供了更好的推理性能。最棒的是,您只需一行额外的代码即可获得您所寻求的性能提升。我们在不同的工作负载上看到了 OpenVINO™ Execution Provider 带来了巨大的性能提升。
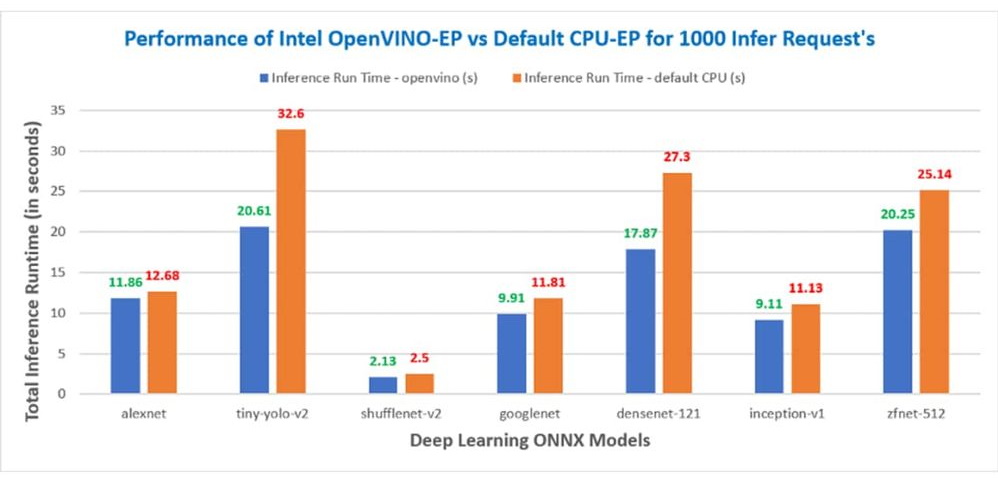
在图 1 中,您可以看到与默认 CPU (MLAS) 相比,使用 OpenVINO™ Execution Provider 获得的性能提升。推理时间越短,性能越好。
没有 Intel® 硬件?Intel 提供了一个设备沙盒, Intel® DevCloud,您可以在上面免费开发、测试和运行您的工作负载,并在最新的 Intel® 硬件集群上运行。请继续阅读,并查看我们使用 OpenVINO™ Execution Provider for ONNX RT 创建的一些示例,这些示例可以在 Intel® DevCloud 上找到。
在图 2 中,您可以看到 OpenVINO™ Execution Provider for ONNXRuntime 的架构图。有关更多详细信息,您可以参考 OpenVINO™ Execution Provider 文档。

示例
为了展示您可以使用 OpenVINO™ Execution Provider for ONNX Runtime 完成什么,我们创建了一些托管在 Intel® DevCloud 上的示例,这些示例展示了您只需一行额外的代码即可获得的性能提升。
这段代码片段显示了您需要添加的一行代码才能获得性能提升。它只需将 OpenVINO™ 设置为推理我们的深度学习模型以及我们想要运行推理的具体 Intel® 硬件/加速器的执行提供程序。

Cleanroom 示例
这个特定的示例是关于使用 ONNX Runtime 和 OpenVINO™ toolkit 作为执行提供程序的 ONNX Tiny Yolo V2 模型进行对象检测。它通过处理视频中的每一帧来提高模型的性能,同时保持准确性。
CPP 示例
CPP 示例使用了 ONNX 模型库中的一个公共 SqueezeNet 深度学习 ONNX 模型。该示例涉及使用 ONNX Runtime 处理图像,并利用 OpenVINO™ Execution Provider 在各种 Intel® 硬件设备上运行推理。
使用 Squeezenet 和 OpenVINO™ Execution Provider 在 CPP 中进行图像分类
您现在需要做的事情
- 在 Intel® DevCloud 上注册并尝试 OpenVINO™ Execution Provider for ONNX Runtime 示例
- 前往 Docker Hub,在您的 Linux 机器上下载 OpenVINO™ Execution Provider docker 镜像
- 查看 OpenVINO™ Execution Provider for ONNX Runtime 的各种 Python wheel 包
- 创建您自己的 AI 用例,并利用 OpenVINO™ Execution Provider 在 Intel® 硬件上实现更快的推理
声明和免责声明
性能因用途、配置和其他因素而异。详情请访问 www.Intel.com/PerformanceIndex。
性能结果基于截至所示日期的测试配置,可能无法反映所有公开可用的更新。 请参阅备份以获取配置详细信息。 没有产品或组件可以绝对安全。
您的成本和结果可能会有所不同。
英特尔技术可能需要启用硬件、软件或服务激活。
© Intel Corporation. Intel、Intel 徽标和其他 Intel 标识是 Intel Corporation 或其子公司在中国大陆的商标。 其他名称和品牌可能被宣称为他人财产。
参考文献
1. 处理器: Intel(R) Core(TM) i7-7700T CPU @ 2.90GHz,每个插槽的核数:4,每个核的线程数:2
显卡: Intel HD Graphics 630,时钟:33MHz
内存: 8192 MB,类型:DDR4
BIOS 版本: V2RMAR17,供应商:American Megatrends Inc.
操作系统: 名称:Ubuntu,版本:18.04.5 LTS
系统信息: 制造商:iEi,型号:TANK-870AI-i7/8G/2A-R11,产品名称:SER0,版本:V1.0
微码: 0xde
框架配置: ONNXRuntime 1.7.0,OpenVINO™ 2021.3 二进制发行版,构建类型:Release 模式
应用程序配置: ONNXRuntime Python API,EP:OpenVINO™,默认 CPU,输入:视频文件
应用程序指标: 每秒帧数 (FPS): (1.0 / 运行一次 ONNXRuntime 会话所需时间)
测试日期:2021 年 5 月 14 日
测试者: Intel®
2. 处理器: Intel(R) Core(TM) i7-7700T CPU @ 2.90GHz,每个插槽的核数:4,每个核的线程数:2
显卡: Intel HD Graphics 630,时钟:33MHz
内存: 8192 MB,类型:DDR4
BIOS 版本: V2RMAR17,供应商:American Megatrends Inc.
操作系统: 名称:Ubuntu,版本:18.04.5 LTS
系统信息: 制造商:iEi,型号:TANK-870AI-i7/8G/2A-R11,产品名称:SER0, 版本:V1.0
微码: 0xde
框架配置: ONNXRuntime 1.7.0,OpenVINO™ 2021.3 二进制发行版,构建类型:Release 模式
编译器版本: gcc 版本:7.5.0
应用程序配置: onnxruntime_perf_test,推理请求数:1000,EP:OpenVINO™,
会话数 1
测试日期:2021 年 5 月 14 日
测试者: Intel®