
可以在没有 RDB 的情况下执行 SQL 的开源 SPL
5.00/5 (5投票s)
SPL提供与SQL92标准等效的语法,可以执行丰富多样的计算。您还可以直接使用TXT/CSV/JSON/XML/XLS/Web Service/MongoDB/Salesforce…等作为数据表,执行SQL查询。
SQL语法贴近自然语言,学习门槛低,加上先发优势,很快在数据库厂商和用户之间普及。经过多年的发展,SQL已成为最广泛使用、最成熟的结构化数据计算语言。
然而,SQL必须基于RDB才能工作,而许多场景下并没有RDB,例如遇到CSV、RESTful JSON、MongoDB等数据源,或者对这些数据源进行混合计算,如CSV和XLS之间。在这些场景下,很多人会选择在Java或C#等高级语言中硬编码算法,这需要从头编写冗长的底层函数,执行效率也难以保证。很容易积累大家痛恨的“代码屎山”。也有人将数据加载到数据库后再用SQL计算,但加载过程非常繁琐,实时性也很差。有时,不得不求助于ETL工具。框架加重,风险增加,进行混合计算更是麻烦倍增。
现在,esProc SPL来了,这些问题都可以迎刃而解。
SPL是一项开源计算技术,它完全涵盖了SQL的计算能力,并支持广泛的数据源。现在,SQL无需RDB即可用于结构化数据计算。
完美的SQL计算能力
SPL提供与SQL92标准等效的语法,可执行丰富的计算,包括过滤、计算字段、选择部分列、重命名等。您还可以直接使用文本和XLS等文件作为数据表执行SQL查询。以CSV文件作为数据源为例:
- 过滤
基本比较运算:
$select * from d:/Orders.csv where Amount>=100
类似于
$select * from d:/Orders.csv where Client like '%bro%'
Null值判断:$select * from d:/Orders.csv where Client is null
and、or、not等逻辑运算符可以组合比较运算,实现联合过滤$select * from d:/Orders.csv where not Amount>=100 and Client like 'bro' or OrderDate is null
in:$select * from d:/Orders.csv where Client in ('TAS','KBRO','PNS')多层括号
$select * from d:/Orders.csv where (OrderDate<date('2020-01-01') and Amount<=100) or (OrderDate>=date('2020-12-31') and Amount>100) - 计算列
SPL拥有丰富的数学函数、字符串函数和日期函数
$select round(Amount,2), price*quantity from d:/Orders.csv $select left(Client,4) from d:/Orders.csv $select year(OrderDate) from d:/Orders.csv
case when:$select case year(OrderDate) when 2021 then 'this year' when 2020 then 'last year' else 'previous years' end from d:/Orders.csv
coalesce:$select coalesce(Client,'unknown') from d:/Orders.csv
SELECT$select OrderId, Amount, OrderDate from d:/Orders.csv
ORDER BY$select * from d:/Orders.csv order by Client, Amount desc
DISTINCT$select distinct Client ,Sellerid from d:/Orders.csv
GROUP BY … HAVING$select year(OrderDate),Client ,sum(Amount),count(1) from d:/Orders.csv group by year(OrderDate),Client having sum(Amount)<=100
聚合函数包括
sum、count、avg、max和min。可以直接进行聚合,无需分组$select avg(Amount) from d:/Orders.csv
JOIN左连接:$select o.OrderId,o.Client,e.Name e.Dept,e.EId from d:/Orders.txt o left join d:/Employees.txt e on o.SellerId=e.Eid
右连接:$select o.OrderId,o.Client,e.Name e.Dept,e.EId from d:/Employees.txt e right join d:/Orders.txt o on o.SellerId=e.Eid
全连接:$select o.OrderId,o.Client,e.Name e.Dept,e.EId from d:/Employees.txt e full join d:/Orders.txt o on o.SellerId=e.EId
内连接:$select o.OrderId,o.Client,e.Name e.Dept from d:/Orders.csv o inner join d:/Employees.csv e on o.SellerId=e.Eid
Inner join也可以写成where的形式$select o.OrderId,o.Client,e.Name e.Dept from d:/Orders.csv o ,d:/Employees.csv e where o.SellerId=e.Eid
- 子查询
$select t.Client, t.s, ct.Name, ct.address from (select Client ,sum(amount) s from d:/Orders.csv group by Client) t left join ClientTable ct on t.Client=ct.Client
with:
$with t as (select Client ,sum(amount) s from d:/Orders.csv group by Client) select t.Client, t.s, ct.Name, ct.address from t left join ClientTable ct on t.Client=ct.Client
in中的子查询$select * from d:/Orders.txt o where o.sellerid in (select eid from d:/Employees.txt)
AS使用'
as'关键字重命名字段、计算列、物理表和子查询$select price*quantity as subtotal from d:/detail.csv
Set操作包括
union、union all、intersect、minus。这里是一个示例$select * from Orders1.csv union all select * from Orders2.csv
into查询结果可以用'
into'关键字写入文件$select dept,count(1) c,sum(salary) s into deptResult.xlsx from employee.txt group by dept having s>100000
丰富的数据源支持
SPL支持各种非数据库数据源,包括各种非标准格式的文本。CSV已在前面的示例中展示。也支持制表符分隔的TXT,SPL将根据扩展名自动处理
$select * from d:/Orders.txt where Amount>=100 and Client like 'bro' or OrderDate is null
如果分隔符不是逗号或制表符,则需要使用SPL扩展函数。例如,分隔符是冒号
$select * from {file("d:/Orders.txt").import@t (;":")}
where Amount>=100 and Client like 'bro' or OrderDate is null
对于没有标题行的文件,列名可以用序号表示
$select * from {file("d:/Orders.txt").import()} where _4>=100 and _2 like 'bro' or _5 is null
特殊格式的某些字符串也应使用扩展函数解析。例如,日期格式不是标准的yyyy-MM-dd
$select year(OrderDate),sum(Amount) from
{file("d:/Orders.txt").import@t(orderid,client,sellerid,amount,orderdate:date:"dd-MM-yyyy")}
group by year(OrderDate)
SQL也可以在Excel文件上执行。对于标准格式的Excel,只需直接引用文件名即可
$select * from d:/Orders.xlsx where Amount>=100 and Client like 'bro' or OrderDate is null
您还可以读取指定的sheet
$select * from {file("D:/Orders.xlsx").xlsimport@t (;"sheet3")}
where Amount>=100 and Client like 'bro' or OrderDate is null
从远程网站下载的CSV/XLS文件
$select * from {httpfile("http://127.0.0.1:6868/Orders.csv).import@tc() }
where Amount>=100 and Client like 'bro' or OrderDate is null
HTTP协议有许多特性,如字符集、端口号、POST参数、Header参数、登录认证等。SPL扩展函数可以支持所有这些。扩展函数还可以抓取网页上的表数据,并支持从FTP服务器下载文件,这里不赘述。
JSON文件在解析前会被读取为字符串
$select * from {json(file("d:\\data.json").read())}
where Amount>=100 and Client like 'bro' or OrderDate is null
二维JSON很少见,多层是常态。SPL扩展函数可以将多层数据转换为二维记录,然后用SQL进行计算。细节在此不详述。
RESTful JSON
$select * from {json(httpfile("http://127.0.0.1:6868/api/getData").read())}
where Amount>=100 and Client like 'bro' or OrderDate is null
如果扩展函数很多很长,可以采用分步形式编写
| A | |
| 1 | =httpfile("http://127.0.0.1:6868/api/getData") |
| 2 | =A1.read() |
| 3 | =json(A2) |
| 4 | $select * from {A3} where Amount>=100 and Client like 'bro' or OrderDate is null |
与CSV/XLS类似,SPL也可以读取HTTP网站上的JSON/XML文件。
XML
$select * from {xml(file("d:/data.xml").read(),"xml/row")}
where Amount>=100 and Client like 'bro' or OrderDate is null
Web服务
$select * from {ws_call(ws_client("http://.../entityWS.asmx?wsdl"),
"entityWS ":" entityWSSoap":"getData")}
where Amount>=100 and Client like'bro' or OrderDate is null
SPL也支持NoSQL。
MongoDB
$select * from {mongo_shell@x
(mongo_open("mongodb://127.0.0.1:27017/mongo"),"main.find()")}
where Amount>=100 and Client like 'bro' or OrderDate is null
MongoDB中经常有多层数据,包括RESTful和Web服务,它们都可以通过SPL扩展函数转换为二维数据。
Salesforce
$select * from {sf_query(sf_open(),"/services/data/v51.0/query",
"Select Id,CaseNumber,Subject From Case where Status='New'")}
where Amount>=100 and Client like 'bro' or OrderDate is null
Hadoop HDFS csv/xls/json/xml:
| A | |
| 1 | =hdfs_open(;"hdfs://192.168.0.8:9000") |
| 2 | =hdfs_file(A1,"/user/Orders.csv":"GBK") |
| 3 | =A2.import@t() |
| 4 | =hdfs_close(A1) |
| 5 | $select Client,sum(Amount) from {A3} group by Client |
HBase
| A | |
| 1 | =hbase_open("hdfs://192.168.0.8", "192.168.0.8") |
| 2 | =hbase_scan(A1,"Orders") |
| 3 | =hbase_close(A1) |
| 4 | $select Client,sum(Amount) from {A2} group by Client |
HBase也提供filter和CMP等访问方式,SPL均可支持。
Hive有通用的JDBC接口,但性能较差。SPL提供了高性能接口。
| A | |
| 1 | =hive_client("hdfs://192.168.0.8:9000","thrift://192.168.0.8:9083","hive","asus") |
| 2 | =hive_query(A1, "select* fromtable") |
| 3 | =hive_close() |
| 4 | $select Client,sum(Amount) from {A2} group by Client |
Spark
| A | |
| 1 | =spark_client("hdfs://192.168.0.8:9000","thrift://192.168.0.8:9083","aa") |
| 2 | =spark_query(A1,"select * from tablename") |
| 3 | =spark_close(A1) |
| 4 | $select Client,sum(Amount) from {A2} group by Client |
阿里云
| A | |
| 1 | =ali_open("http://test.ots.aliyuncs.com","LTAIXZNG5zzSPHTQ","sa","test") |
| 2 | =ali_query@x(A1,"test",["id1","id2"],[1,"10001"]:[10,"70001"], ["id1","id2","f1","f2"],f1>=2000.0) |
| 3 | $select Client,sum(Amount) from {A2} group by Client |
Cassandra
| A | |
| 1 | =stax_open("127.0.0.1":9042,"mycasdb","cassandra":"cassandra") |
| 2 | =stax_query(A1,"select * from user where id=?",1) |
| 3 | =stax_close(A1) |
| 4 | $select Client,sum(Amount) from {A2} group by Client |
ElasticSearch
| A | |
| 1 | =es_open("localhost:9200","user":"un1234") |
| 2 | =es_get(A1,"/person/_mget","{\"ids\":[\"1\",\"2\",\"5\"]}") |
| 3 | =es_close(A1) |
| 4 | $select Client,sum(Amount) from {A2} group by Client |
Redis
| A | |
| 1 | =redis_open() |
| 2 | =redis_hscan(A1, "runoobkey", "v*", 3) |
| 3 | =redis_close (A1) |
| 4 | $select key,value from {A2} where value>=2000 and value<3000 |
SAP BW
| A | |
| 1 | =sap_open("userName","passWord","192.168.0.188","00","000",”E") |
| 2 | =sap_cursor(A1, "Z_TEST1","IT_ROOM").fetch() |
| 3 | =sap_close(A1) |
| 4 | $select * from {A2} where Vendor like '%software%' |
InfluxDB
| A | |
| 1 | =influx_open("http://127.0.0.1:8086", "mydb", "autogen", "admin", "admin") |
| 2 | =influx_query(A1, "SELECT * FROM Orders") |
| 3 | =influx_close(A1) |
| 4 | $select Client,sum(Amount) from {A2} group by Client |
Kafka
| A | |
| 1 | =kafka_open("D://kafka.properties";"topic-test") |
| 2 | =kafka_poll(A1) |
| 3 | =kafka_close (A1) |
| 4 | $select Client,sum(Amount) from {A2} group by Client |
MDX多维数据库
| A | |
| 1 |
|
| 2 |
|
| 3 | =olap_close(A1) |
| 4 | $select * from {A2} where SalesAmount>10000 |
除了支持海量数据源,SPL还可以在数据源之间进行混合计算。例如,在CSV和RDB之间
$select o.OrderId,o.Client,e.Name e.Dept
from d:/Orders.csv o inner join d:/Employees.xls e on o.SellerId=e.Eid
在MongoDB和数据库之间
| A | B | |
| 1 | =mongo_open("mongodb://127.0.0.1:27017/mongo") | |
| 2 | =mongo_shell@x(A1,"detail.find()").fetch() | =connect("orcl").query@x("select * from main") |
| 3 |
| |
任意数据源之间都可以进行混合计算,SQL语法不受数据源影响。
更深层的计算能力
事实上,SPL的本意是Structure Process Language,即用于结构化数据处理的语言。在之前的例子中,已经展示了SPL本身的一些语法(那些扩展函数)。SQL只是SPL提供的一个功能,SPL本身拥有比SQL更强大、更便捷的计算能力。有些计算逻辑非常复杂,很难用SQL甚至存储过程来编码,而SPL可以用更简单的代码完成计算。
例如,这里有一个任务:计算股票连续上涨天数最长是多少。SQL需要使用多层嵌套子查询和窗口函数,代码冗长且不易理解。
select max(continuousDays)-1
from (select count(*) continuousDays
from (select sum(changeSign) over(order by tradeDate) unRiseDays
from (select tradeDate,
case when price>lag(price) over(order by tradeDate)
then 0 else 1 end changeSign
from AAPL) )
group by unRiseDays)
而SPL只需要两行代码
| A | B | |
| 1 | =T("d:/AAPL.xlsx") | 读取Excel文件,第一行是标题 |
| 2 | =a=0,A1.max(a=if(price>price[-1],a+1,0)) | 获取最大连续上涨天数 |
对于简单的计算,使用基本的SQL非常方便,但是当计算需求变得复杂时,SQL就不适用了。即使提供更多的函数(如窗口函数),也无法简化计算。在这种情况下,我们建议用户直接使用SPL,代码简洁,而不是编写多层嵌套的复杂SQL。为此,SPL中的SQL只支持SQL92标准,不提供包括窗口函数在内的更多语法。
SQL不提倡多步计算。它倾向于将一个计算任务写在一个大的语句中,这会增加任务的难度。SPL自然支持多步计算,可以轻松地将复杂的大型计算任务分解成简单的子任务,这大大降低了编码难度。例如,找出累计销售额占总销售额一半的N个主要客户,并按销售额从大到小排序。
| A | B | |
| 1 | = T("D:/data/sales.csv").sort(amount:-1) | 获取数据,降序排序 |
| 2 | =A1.cumulate(amount) | 计算累计序列 |
| 3 | =A2.m(-1)/2 | 最后一个累积值是总和 |
| 4 | =A2.pselect(~>=A3) | 所需位置(大于一半) |
| 5 | =A1(to(A4)) | 按位置获取值 |
灵活的应用结构
如何使用SPL?
对于交互式计算和分析,SPL拥有专业的IDE,不仅具备完善的调试功能,还能直观地观察每一步的中间计算结果。
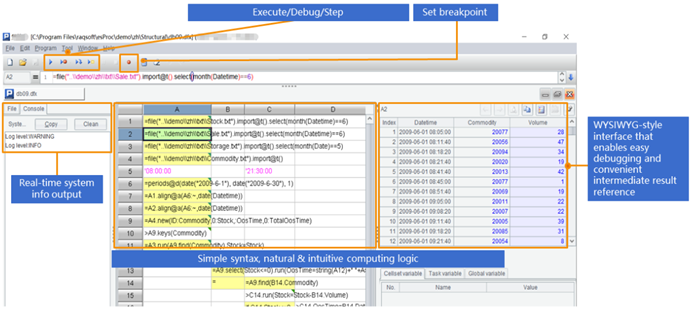
SPL还支持命令行执行,并支持任何主流操作系统。
D:\raqsoft64\esProc\bin>esprocx.exe -R select Client,sum(Amount)
from d:/Orders.csv group by Client
Log level:INFO
ARO 899.0
BDR 4278.8
BON 2564.4
BSF 14394.0
CHO 1174.0
CHOP 1420.0
DYD 1242.0
…
对于应用程序中的计算,SPL提供了标准的JDBC驱动程序,可以轻松集成到Java中。
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
PrepareStatement st = conn.prepareStatement
("$select * from employee.txt where SALARY >=? and SALARY<?");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…
应用程序中会有频繁修改或复杂计算。SPL允许将代码放在Java程序之外,可以大大降低代码耦合度。例如,上述SPL代码可以保存为脚本文件,然后在Java中以存储过程的形式调用。
…
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement st = connection.();
CallableStatement st = conn.prepareCall("{call getQuery(?, ?)}");
st.setObject(1, 3000);
st.setObject(2, 5000);
ResultSet result=st.execute();
…
有了开源SPL,您可以轻松地在没有RDB的情况下使用SQL。
扩展阅读
- SPL: The Open-source Java Library to Process Structured Data
- Which Tool Is Ideal for Diverse Source Mixed Computations
历史
- 2022年6月24日:初版