
现代可观测性问题
5.00/5 (2投票s)
可观测性问题——为什么系统会表现出这种行为?
- 第一部分:现代可观察性问题
- 第二部分:OpenTelemetry,缺失的环节
引言
在单个进程中调试应用程序通常很容易 💪,而且我们的大型单体应用中遇到的问题大部分都已经记录在案,并有标准解决方案。我们甚至可能已经自动化了修复。但如果没有,我们也知道应用程序的路径是有限的,并且追踪大多数问题的根源相对容易。

然而,大型现代微服务架构中复杂的交互会产生新颖的、一次性的错误,这些错误会跨越时间和空间。考虑到组件是基于广泛的技术栈构建的,这对支持它们提出了真正的挑战。
想象一下,像下图所示的少量服务。我们混合了同步 REST 通信和异步* 事件。如果我们在 service H 中收到一个错误,原因是 service B 中发生了一些事情,那么在没有正确信息的情况下,这将很难调查。

* 同步 HTTP 调用会同时请求并接收响应。当然,有时可能需要几秒钟,但足够快,我们可以轻松地将其与可能产生的任何副作用联系起来。异步通信,如事件,不一定会触发即时响应。甚至可能有一天才会处理添加到某个队列的事件!显然,将某些副作用的责任归咎于事件并不那么容易。
可见性不是可观察性
可观察性和监控是两件不同的事情。我们通常在监控方面做得很好,或者如果监控失败,用户会向我们抱怨。无论哪种方式,我们通常都知道何时存在问题。但我们并不总是擅长回答为什么的问题。
对我而言,这就是核心的可观察性问题:系统为何表现出这种行为?
如果您正确地进行了可观察性处理,那么您应该能够回答这个问题,而无需重新部署并添加额外的日志或“打印”语句。
如果您只能回答有关可预测问题的问题——那就是监控,而不是可观察性。
遥测与可观察性的三个支柱
- 您的汽车仪表盘显示油箱剩余油量
- 当您使用 Kibana 等工具过滤代码的日志输出时
- 当您查看了通过服务器的事件直方图时
这些都是遥测的例子——对系统行为或内部工作的洞察——系统发出的关于“黑盒”内部发生的事情的数据。您也可能听到这些被称为信号。
而插桩是产生遥测的数据。当我们谈论插桩时,我们指的是在我们的应用程序中添加库和/或代码,这些库和/或代码会收集日志、指标和跟踪等遥测数据。

在软件工程中,我们通常倾向于将遥测简化为三个不同的部分
日志:更具体地说,集中式日志记录——将我们组件的所有文本日志条目发送到单个数据源,以便通过搜索轻松进行关联。日志通常详细描述正在发生的事情,因此长期存储成本很高。它们并不总是与特定的用户/请求相关联,因此缺乏上下文,但尽管如此,仍然严重依赖它们来理解系统行为。
指标:通常关注可靠性,这是服务级别指标 (SLI) 和服务级别协议 (SLA) 讨论的内容。由于它们主要是计数器和速率等数值数据,因此它们的存储空间比日志少得多。这意味着它可以保留更长时间,从而能够更好地分析随时间变化的趋势。但请注意,随着复杂性的增加,大小也可能增加——基数——我们附加到每个指标的额外数据量,以使其更有用。
跟踪:更具体地说,分布式跟踪。将其视为分布式或大型系统中跨多个组件(和边界)的堆栈跟踪。它提供了指标的一些分析优势,但具有日志的基数。分布式跟踪还依赖于上下文传播,这是一个用于在服务之间移动用于关联跟踪的共享信息和标识符的组件。
通过在所有服务中进行跟踪插桩,并与日志正确关联,那么在我们虚构的系统中,我们可以看到我们想象的事务所经过的路径,从而找到出现问题的服务,在我们设想的场景中,是 service F 中一些错误的日志以及 service B 中未能优雅处理它的代码,导致错误直到 service H 才显现。

在 service A 调用 service B 后,如果 service B 中抛出异常,那么典型的可观察性工具对跟踪和日志的视图将如下面的图像所示。通过它,我们可以确切地看到 service A 中的哪个调用发出了请求,并进一步深入查看,查看相关的日志,从而获得整个事务的完整图景。

我们将在下一篇文章,关于 OpenTelemetry 中更详细地讨论跟踪。
最终,日志、指标和跟踪是排练过的“3 大支柱”,但还有其他支柱,例如运行状况检查。无论我们选择如何细分,我们都有一些原始的非结构化数据,需要对其进行转换才能回答有关系统行为的问题。
什么是正确的遥测?
摆脱那种寻找可预测问题的监控思维模式,确保您的系统发出足够多的正确遥测数据,以便您能够解决您无法预见的问题,因为生产环境中的微服务架构会提供大量此类问题!发出正确的遥测数据是使系统可观察的关键。
到底是什么阻止了内部用户工作或外部客户完成他们需要的事情?
每个服务的业务价值是什么?
与业务中的同事保持开放的对话,以了解与系统有关的哪些问题对他们很重要。利用这一点来决定应该插桩哪些正确的数据。
这将使可观察性成为一个更强大的工具,可用于“假设”场景和预测。
技术问题

我们将在左侧看到用各种技术(及更多)构建的应用程序,它们执行着我们想了解的事情(随着我们故意转向组合式架构和更小的微服务,这种情况正在变得更加复杂)。
而在右侧,我们有所有这些选项(及更多),我们可能想使用它们来收集和分析左侧事物正在做的事情。
现实情况是这一切的混合。一些文件,一些自定义数据库,也许一个团队已经走上了自己的路,在本地使用 Elastic,另一个在云端。所有这些都在发出遥测信号,但格式不一定相同,这意味着要全面了解“黑盒”内部发生的情况变得非常困难。例如
- 如果日志不使用共享格式,您将无法聚合日志并在整个系统中运行查询。我见过编写了日志传输代理来重新格式化日志,但跨技术栈维护代理和客户端会消耗大量资源。
- 我曾目睹过团队之间的困惑,每个团队都试图找出他们应该为跨越多个团队拥有的服务进行事务添加哪些通用上下文。这个差距很容易通过建立标准来填补,但内部建立标准需要时间和精力。
供应商锁定
使用语言框架提供的抽象来构建我们自己的数据库或文件日志记录是可以的。但规模化生产需要专用自托管或 SaaS 可观察性解决方案的强大功能。问题在于,它们以自己的方式对代码进行插桩,这使得切换到不同的解决方案成为一项艰巨的任务。
我们将此称为“供应商锁定”,其影响是双向的
- 我们的所有服务都依赖于它们现在已连接的日志记录解决方案。
- 日志记录解决方案只支持 X 和 Y 技术栈,限制了我们更改这些服务的自由。
当然,如果您只有少量 C# Web 应用程序,而且您只制作这些应用程序,那么锁定到特定的可观察性后端是可以的。
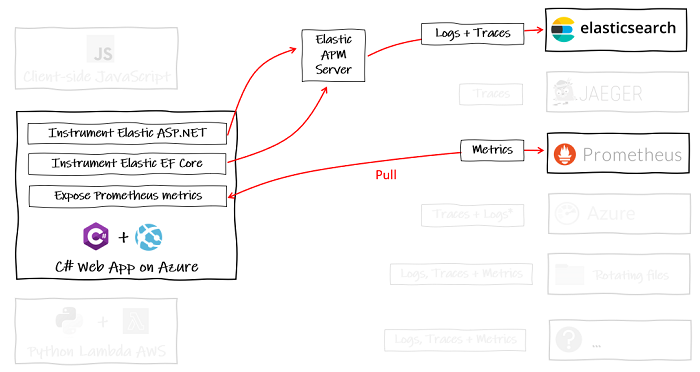
摘要
要解决大型微服务系统中的问题

- 我们必须能够找出它们为何发生。
- 为此,我们的系统必须是可观察的。
- 要做到可观察,系统需要进行插桩,以便代码发出遥测数据,通常是日志、跟踪和指标。
- 必须将这些遥测数据发送到一个后端,该后端支持将这些遥测数据连接起来并回答有关系统行为的问题。
有许多开源和商业后端,有自托管或 SaaS 版本,其中许多在这方面做得非常出色。问题在于,它们都以自己的方式做事——没有标准。将日志、指标和跟踪集成到我们所有服务中是一项艰巨的任务,这意味着一旦您为某个供应商完成了一次,您可能在短期内不会再做一次,这大大降低了您保持灵活性和适应性的自由。
OpenTelemetry (OTeL) 是 OpenTracing 和 OpenCensus 项目理念的演进,旨在构建一个单一的、供应商中立的标准。我们将在第二部分:OpenTelemetry,缺失的环节中对此进行探讨。
历史
- 2022 年 11 月 2 日:初稿
- 2022 年 11 月 8 日:链接到第二部分