
基于数组的内存池和分配器
5.00/5 (8投票s)
传统内存池的简单而有用的替代方案
布局
引言
C++ 中通用的内存管理机制,如 new 和 delete 运算符,旨在服务于各种具有不同需求的客户端。它们提供了易于使用的工具,适用于许多实际应用类型。但遗憾的是,在某些特定用例中,它们的性能不佳。鉴于通用算法必须尽可能快,并且要处理不同大小的对象并最小化内存碎片,这一点并不令人惊讶。后两个要求不仅在技术上具有挑战性,而且还会对应用程序的整体性能产生不利影响。
为了解决软件产品中的这些问题,程序员会采用各种自定义内存管理方法。当用户算法频繁创建和销毁小对象时,这些技术特别有效。资源有限的系统是这些方法的明显受益者。C++ 标准库通过在容器中支持自定义分配器来帮助开发人员。选择得当,某些标准容器操作的速度可以提高 3 到 10 倍。要理解这一点,请考虑英特尔和 AMD 之间的竞争。在计算速度上 10-20% 的优势对于对最佳性能处理器和系统感兴趣的买家来说是决定性的。
自定义内存管理的吸引力在于,一些方案非常简单。它们的复杂程度相当于智力题,并且可以用少量代码实现。虽然 C++ 程序员的书籍中讨论了自定义内存管理和分配器的方法,但简单的方案经常被新手重新发现。由于这些优点,自定义内存管理已成为专业人士用于性能优化的一种工具。
在实践中,选择自定义内存管理方案可能具有挑战性。一些权衡是不可避免的。设计决策会影响用户算法所需操作的效率。例如,某些分配器可以提供非常快速的分配操作,但释放单个对象的资源速度很慢或根本无法释放。在这方面,固定大小的内存池通常是一个合理的选择。它提供非常快速(恒定时间)的分配和释放操作,并且可以用于具有某些限制的对象。 尽管它有局限性,但对于特定情况仍然有用。
传统上,固定大小的内存池基于链表。在本文中,我们提出了一种简单的替代变体,这种内存池和标准 C++ 分配器使用了两个数组。这种变体在公共领域讨论的频率不如传统内存池。尽管如此,基于数组的变体在分配和释放操作方面提供了良好的速度和简单的实现代码。它具有有趣的特性,尽管存在一些限制,但仍可在应用程序中使用。
空闲列表
为了解释关键思想,我们从传统的固定大小块内存池开始讨论,该内存池通常基于单链表。“空闲列表”这个名字来源于它的表示:一个空闲内存块的链表。最优变体可能对初学者来说有点挑战,因为它的结构比基本链表更复杂。这种复杂性源于其实现使用了两种类型的链接节点:块(chunk)和块(block)。一个块被细分为相等大小的块,这些块被组织成一个链表。这些内存块或区域最初是空闲的,后来用于存储用户算法的对象。粗略结构可以看作是大型块的列表,细致结构可以看作是小型块的列表。这种复杂的结构提供了精细调整的优势,以获得最佳的时间和空间效率。
对于本文下面描述的内存池,我们通过假设一个块足够大以包含用户算法所需的所有块来减少这种复杂性。然后,简化的内存池代表一个普通的单链表,如图 1 所示。

将内存块组织成链表对于提高内存池的高效率至关重要,因为它使我们能够避免搜索空闲块等耗时的操作。当用户请求新对象内存时,内存池会断开列表的第一个节点,并将该节点内存块交付给用户。当用户返回不再需要的对象时,其内存块被添加为一个新节点,成为列表的第一个节点。解释内存池高性能的事实是,它使用链表的一端进行两个恒定时间操作。
这很有趣,因为还有其他数据结构支持所需的操作。因此,理论上,单链表可以被替换。但在我们寻找替代方案之前,有必要再次查看这两个操作。而且不难注意到,这些操作是栈的基本弹出(pop)和压入(push)操作。这听起来像是一个发现,简单但并不立即显而易见。
内存池中的链表代表一个栈。
其余很简单。
数组池
众所周知,栈操作由多种数据结构支持。因此,在 C++ 标准库中,类模板 stack 是一个容器适配器。它可以与三个标准容器实例化:list、vector 和 deque。其中没有一个适合我们变体的内存池,因为标准容器是我们即将开发的自定义分配器的客户端。为避免过度工程化我们的解决方案,我们应使用基本的 C++ 工具。尽管如此,类模板 stack 的设计表明了如何替换传统内存池中的单链表。我们只需要找到表示栈最高效的数据结构。我们选择数组是“自然的”,因为在支持压入和弹出操作方面,链式数据结构的速度无法与数组竞争。
这个选择的额外好处是,栈数组使我们能够将指向块的指针与块数组分开存储。此功能与使用链表的内存池不同,其中指向下一个节点的指针位于固定大小的块内部(参见图 1 中的绿色节点)。结果是基于数组的传统内存池变体由两个数组组成,如图 2 所示。
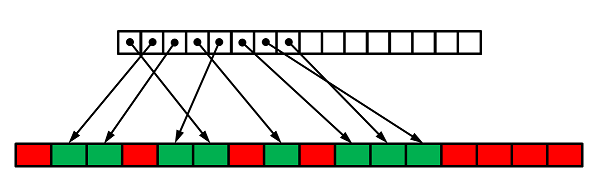
请注意这两个数组之间的重要区别。栈数组始终由两个连续的内存区域组成,而存储数组在通用情况下是碎片化的,因为用户对象可以存储在任意(不一定是随机)位置。换句话说,存储中空闲块和已分配块的位置与栈中匹配的位置不对应。唯一的限制是每个用户值都存在于存储数组中。
如果需要,可以通过对一端进行操作来获得存储数组中空闲块和已分配块的连续排列(参见图 3)。例如,将值附加到用户容器的末尾,并从末尾删除值。然而,这种方法对于许多实际应用来说过于严格。用户算法中对任意对象的分配和释放操作将破坏图 3 中所示的存储的完美连续排列。执行一段时间后,内存池存储将处于类似于图 2 的通用状态。同时,栈数组在任何内存池操作后仍然是无间隙的。

相同的数据集可以分散在系统内存中,也可以局部化在小区域中。数据集紧凑性的有用度量称为引用局部性。内存池卓越性能的关键因素是其高空间效率。它使用户算法能够将最大数量的对象放置在最快但最小的系统内存中,例如处理器缓存。在这方面,基于数组的内存池借鉴了其前身的最佳特性,并提供了重要的增强。
首先,本文讨论的每个内存池都保证比通用内存管理机制更好的空间引用局部性。这种优越性源于所有用户数据都包含在一个块中,尽管它们在给定的内存区域中任意分布。其次,与传统的固定大小内存池类似,基于数组的变体不需要保存每个内存块的大小。
说到区别,最显著的区别是基于数组的内存池的存储不包含特定于实现的连接数据。链接节点的等价物是指向块的指针。它们在用户算法执行期间不需要,因此驻留在单独的栈数组中。此外,数组存储对块大小没有限制,而在传统内存池中,块大小不能小于链接大小。因此,存储中的数据集可以更紧凑,以便在快速内存中处理更多的对象,而不是使用链表的内存池。对于小尺寸对象,这个优势很显著,尤其是在用户算法中的对象生命周期远长于其创建和销毁时间时。
传统内存池中块大小的最小限制是开发最高效编程解决方案的一个挑战。A. Alexandrescu [1] 在第 4 章“小对象分配”中提出了一种克服此限制的有趣方法。与基本变体类似,一个块中的所有固定大小块都组织成单链表。区别在于,此列表中的链接由字节类型索引表示,而不是指针。此技巧使用户能够将块的大小减小到仅一个字节,这与 64 位系统上的指针内存池相比,在空间效率上有了显著提高。然而,这种改进的代价是,一个块最多只能存储 255 个对象。对于更多的对象,此自定义分配器需要一个块容器(书中的 std::vector)。代码的复杂性增加,并且由于块之间的额外操作,最坏情况性能会下降。
本文介绍的基于数组的内存池提供了一种简单高效、通用且可移植的工具。它为用户算法提供了非常快速的分配和释放操作,以及针对数据集的缓存优化存储。它处理任意数量的值和任意大小的块,并且不受传统内存池的限制。
实现
自定义内存管理是一个巨大的领域,包含无数的变体和变化。为了避免不重要的细节并专注于主要特性,我们提供了一个简单的演示。该代码旨在作为开发基于数组的内存池和分配器的专门和高级变体的起点。为了帮助客户端处理不同类型的对象,我们选择了一个分配器,该分配器分配和释放固定大小的未初始化内存块。这种基于数组的内存池的最小变体可能看起来像这样:
template< unsigned int num_blocks, unsigned int block_size>
class ArrayPool
{
byte arr_bytes[num_blocks*block_size] ;
byte* arr_stack[num_blocks] ;
int i_top ;
public:
ArrayPool( ) : i_top(-1)
{
byte* p_block = arr_bytes ;
for ( int i = 0 ; i < num_blocks ; ++i, p_block+=block_size )
arr_stack[i] = p_block ;
i_top = num_blocks-1 ;
}
void* Allocate( )
{ return reinterpret_cast<void*>( arr_stack[i_top--] ) ; }
void Free( void* p_back )
{ arr_stack[++i_top] = reinterpret_cast<byte*>(p_back) ; }
bool IsEmpty( ) const { return i_top < 0 ; }
bool IsFull ( ) const { return i_top == (n_blocks-1) ; }
} ;
内存池的关键数据成员是两个数组:arr_bytes 和 arr_stack,它们分别代表用户对象的连续存储区域和管理存储的栈。i_top 是栈中当前顶部元素的索引。
内存池的构造函数将栈数组填充到存储中所有块的指针。在内存池的初始状态下,存储中的所有块都是空闲的,栈是满的。如果我们忽略上面的代码中的 reinterpret_cast,那么 Allocate() 和 Free() 就是对内存池存储中块指针栈的弹出和压入操作。析构函数释放初始化期间获得的所有资源。因此,与传统内存池类似,当客户端完成内置类型数据的处理时,无需逐个释放对象。
这就是主要实现细节。数组易于使用。它们使此变体的内存池代码比使用链表的变体更简单。附加文件中的基于数组的内存池技术性稍强一些。
在 C++ 代码中应用此内存池有两种选择:为标准容器提供类特定的内存管理运算符或分配器。我们选择的是无状态分配器,它是在 STL 的原始版本 [2] 中引入的。使用基于数组的内存池支持符合 STL 的分配器,可以让我们测量各种算法、容器及其底层数据结构的性能。
class ArrayAllocatorSTL 表示一个无状态 C++ 分配器。在此类中,ArrayPool 对象用作静态数据成员。一种分配器类型的所有实例都操作相同的内存或资源。此分配器可与基于节点的 STL 容器一起使用:forward_list、list、set、multiset、map 和 multimap。基础 class AllocrBaseSTL 被引入是为了更好的代码结构。它为符合 C++ 标准的分配器提供了类型定义以及成员函数,这些函数与基于数组的内存池和分配器的解释不太相关。
演示代码可在 Visual Studio 2019 和 Android Studio 中运行。但是,不能保证它可以在某些旧版本或未来版本的 STL 中编译,因为分配器的 C++ 标准规范不稳定。在出现编译错误的情况下,请检查您的编译器是否符合特定标准版本,并更新 class AllocrBaseSTL 和 ArrayAllocatorSTL 中的代码。
性能提升
随附代码提供了对标准容器上一些基本操作的性能测试。测试的运行时间因系统而异。这并不奇怪。更具挑战性的是,同一系统上的测量值可能在很大范围内变化。在这种情况下,系统缓存算法的影响最为显著。其迹象是运行时间取决于算法的执行顺序和数据集的大小。另一个复杂因素是系统可能不支持高分辨率计时器。因此,在性能测试中获得一致且可复现的运行时间值并非易事。通常,具有强大 Intel 和 AMD 处理器的 Windows 系统产生的偏差比 Android 系统要小。
本文测得的性能增益(或改进)是算法在 STL 默认分配器和基于数组的分配器下的运行时间之比。如上所述,数据集的空间效率是实现高性能的关键因素。这就是为什么对于小对象来说,改进更为显著:对象尺寸越小,性能增益越大。空间效率的另一个方面是为用户算法选择最佳数据结构。这是基于可互换 STL 容器的解决方案中的典型优化任务。在动态分配的数据结构方面,对于单链表(forward_list)观察到最佳的性能增益,它具有最小的特定于实现的数据大小——每个节点只有一个链接。第二好的是双链表(list),它有两个内部链接到节点。这种数据结构比红黑树(set)更节省空间。这些结果反映了内部数据对用户算法性能的影响。
基于数组的分配器已在多个 Android 移动设备和 Windows 计算机上进行了测试。这里,我们重点关注 Windows 系统上的一些有趣结果。Android 设备将在其他地方讨论。
在本文中,我们选择了两台 Windows 计算机。第一台是配备 Intel 7 Core 3770 处理器的 HP 工作站。第二台是配备 I7 1165G 处理器的 HP 移动工作站。为了测试基于数组的分配器提供的分配速度的性能增益,我们使用了单链表和双链表一端的操作。
| N | 1,000 | 10,000 | 100,000 | 1,000,000 |
std::forward_list<size_t>::push_front() | ||||
| I7 3770 | 18 | 15 | 16 | 14 |
| I7 1165G | 51 | 31 | 28 | 24 |
std::list<size_t>::push_back() | ||||
| I7 3770 | 7.2 | 7.3 | 7.0 | 6.3 |
| I7 1165G | 32 | 16 | 12 | 14 |
第一个观察是普遍的。在这两个系统上,单链表的性能增益都大于双链表。这个结果验证了前面提到的观点:更高的时效性与更高的空间效率密切相关。
如果我们继续分析具体数值,我们可以发现另一个有趣的现象。目前尚不清楚 51 的增益有多可靠,但很明显,新系统始终显著优于旧系统。为什么这个结果令人惊讶?普遍的看法是,自定义内存管理首先有利于资源有限的系统。下一个显而易见的问题是:为什么新系统提供的性能增益比旧系统显著更好?为了回答这个问题,让我们比较 L1、L2 和 L3 缓存的参数,请注意两个处理器都有四个核心。
| L1 | L2 | L3 | |
| I7 3770 | 256 KB | 1 MB | 8 MB |
| I7 1165G | 320 KB | 5 MB | 12 MB |
新系统的一个显著优势是更大的 L2 缓存:5 MB 对比 1 MB。另一个区别是,在 I7 1165G 中,每个核心的 L1 大小为 80 KB,而在 I7 3770 中为 64 KB。与 L2 相比,这并不是一个很大的增加,但它可能负责当元素数量减少到零时性能的急剧增长。
新系统的性能提升非常出色,这告诉我们应该立即更换旧电脑。但这还不是故事的全部。有一个奇怪的发现。如果我们在这两个系统上测试相同的算法,使用默认分配器,并比较它们以微秒为单位的运行时间,我们会发现新系统比旧系统慢(!),这绝对不是好消息。
| N | 1,000 | 10,000 | 100,000 | 1,000,000 |
std::forward_list<size_t>::push_front() | ||||
| I7 3770 | 43.2 | 370 | 3865 | 40110 |
| I7 1165G | 102 | 534 | 4817 | 43260 |
| 比率 | 2.36 | 1.44 | 1.25 | 1.08 |
std::list<size_t>::push_back() | ||||
| I7 3770 | 45.6 | 438 | 4602 | 47400 |
| I7 1165G | 123 | 598 | 5228 | 50050 |
| 比率 | 2.70 | 1.37 | 1.13 | 1.06 |
从这些测量结果可以看出,新系统中的处理器缓存和合适的算法是针对数组而不是经典链式数据结构进行优化的。这一事实解释了新系统中基于数组的分配器提供的卓越性能。
正如我们在之前的讨论中所提到的,基于数组的内存池和分配器为用户数据集提供了紧凑的存储。因此,我们可以预期,在分配器中对象的生命周期内,高空间效率将提高用户算法的时间效率。检查生命周期性能的最简单方法之一是测量顺序算法(如求和)的运行时间。在这些测试中,与默认分配器的性能增益范围为 1.0 到 2.5。虽然这些值不像前一个测试那样令人印象深刻,但它们可能足以满足许多实际应用。
在转向局限性之前,让我们总结一下性能测试结果。首先,它们证实了不仅仅是资源有限的系统可以从自定义内存管理中受益。该技术在拥有强大处理器的计算机上也很有效。其次,对不同代际相似系统上性能增益的比较表明,在最新计算机上使用基于数组的内存池和分配器更有益,因为计算能力有所提高。在硬件方面,CPU 速度不是整体性能的唯一因素。系统的另一个重要参数是每个处理器缓存级别的快速内存大小。拥有大量快速内存的计算机最适合基于数组的内存池和分配器。当可以接受一些空间损失时,这些系统可以提供可观的性能增益。
局限性
自定义分配器通常很有用,因为它们提高了对象的创建和销毁速度。但是,整体性能还取决于对象的生命周期以及它们在算法中的使用方式。自定义内存管理未能带来预期的性能提升并不少见。
与使用链表的传统内存池不同,这里描述的基于数组的变体不够灵活。它对容量有严格的上限,因此,它能存储的最大对象数量也有限。由于此限制,程序员面临着选择分配器数组正确大小的棘手困境。如果分配器存储对于所有用户对象来说太小,分配器性能将下降。如果存储太大,许多块将保持未使用状态。
理论上,基于数组的分配器以恒定因子提高性能。实际上,存在引用局部性的影响,应该对其进行测量,因为它会使结果和分析复杂化。这种影响的缺点是性能增益是系统特定的。用户算法的最佳性能取决于 CPU 多级缓存。
扩展基于数组的内存池和分配器的功能并非易事。每个新功能都使我们能够服务更多用户算法和数据结构。但是,它会使分配和释放操作的实现更加复杂且效率降低。复制默认内存管理运算符功能的可能性不大。内存池和分配器是用于开发高效但专业化算法和数据结构变体的工具。由于智力题和计算机科学之间存在显著的差距,自定义内存管理的实用规则是“越简单越好”。
如果性能改进不理想怎么办?
简而言之,分析给定算法,找出并修复其性能瓶颈。最终的方法是重新设计和重新实现所需的算法。
如果实现的性能仍然不够好怎么办?
告诉您的经理或客户是时候购买一台量子计算机了。性能改进总是有空间的。
参考文献
- A. Alexandrescu. Modern C++ Design. Addison Wesley, 2001.
- B. Stroustrup. The C++ Programming Language. Third Edition, Addison Wesley, 2007.
历史
- 2023年1月30日:初始版本
- 2023年2月6日:添加了参考文献