
掌握 Pandas 的 MultiIndexes:强大的复杂数据分析工具
0/5 (0投票)
如何使用 pandas 中的多重索引,并举例说明监测地表温度变化等实际用例。
引言
Pandas 是 Python 中广泛使用的数据处理库,提供了强大的功能来处理各种类型的数据。其一项值得注意的特性是能够处理 MultiIndexes(也称为分层索引)。在这篇博文中,我们将深入探讨 MultiIndexes 的概念,并探索如何利用它们来处理复杂的多维数据集。
理解 MultiIndexes:分析体育运动表现数据
MultiIndex 是 Pandas 的一种数据结构,允许跨多个维度或级别进行索引和访问数据。它能够为行和列创建分层结构,提供一种组织和分析数据的灵活方式。为了说明这一点,让我们考虑一个场景:您是一位私人教练或教练,在运动员进行体育活动期间监测他们的健康参数。您想在特定的时间间隔内跟踪各种参数,例如心率、跑步配速和步频。
合成健康表现数据
为了处理这类数据,让我们开始编写 Python 代码来模拟健康表现数据,特别是心率和跑步步频。
from __future__ import annotations
from datetime import datetime, timedelta
import numpy as np
import pandas as pd
start = datetime(2023, 6, 8, 14)
end = start + timedelta(hours=1, minutes=40)
timestamps = pd.date_range(start, end, freq=timedelta(minutes=1), inclusive='left')
def get_heart_rate(begin_hr: int, end_hr: int, break_point: int) -> pd.Series[float]:
noise = np.random.normal(loc=0.0, scale=3, size=100)
heart_rate = np.concatenate((np.linspace(begin_hr, end_hr, num=break_point),
[end_hr] * (100 - break_point))) + noise
return pd.Series(data=heart_rate, index=timestamps)
def get_cadence(mean_cadence: int) -> pd.Series[float]:
noise = np.random.normal(loc=0.0, scale=1, size=100)
cadence = pd.Series(data=[mean_cadence] * 100 + noise, index=timestamps)
cadence[::3] = np.NAN
cadence[1::3] = np.NAN
return cadence.ffill().fillna(mean_cadence)
提供的代码片段展示了体育活动期间心率和步频的合成数据生成。它首先导入所需的模块,如 datetime、numpy 和 pandas。
体育活动的持续时间定义为 100 分钟,并利用 **pd.date_range** 函数在每分钟间隔生成一系列时间戳,以覆盖此期间。
get_heart_rate 函数生成合成心率数据,假设心率线性增加到一定水平,然后在活动的其余时间保持恒定水平。引入高斯噪声以增加心率数据的变异性,使其更真实。
类似地,get_cadence 函数生成合成步频数据,假设在整个活动过程中步频相对恒定。添加高斯噪声以创建步频值的变异性,噪声值每三分钟而不是每分钟更新一次,这反映了步频相对于心率的稳定性。
有了数据生成函数后,现在就可以为两位运动员 Bob 和 Alice 创建合成数据了。
bob_hr = get_heart_rate(begin_hr=110, end_hr=160, break_point=20)
alice_hr = get_heart_rate(begin_hr=90, end_hr=140, break_point=50)
bob_cadence = get_cadence(mean_cadence=175)
alice_cadence = get_cadence(mean_cadence=165)
此时,我们拥有 Bob 和 Alice 的心率和步频。让我们使用 matplotlib 绘制它们,以获得更多的数据洞察。
from __future__ import annotations
import matplotlib.dates as mdates
import matplotlib.pyplot as plt
date_formatter = mdates.DateFormatter('%H:%M:%S') # Customize the date format as needed
fig = plt.figure(figsize=(12, 6))
ax = fig.add_subplot(111)
ax.xaxis.set_major_formatter(date_formatter)
ax.plot(bob_hr, color="red", label="Heart Rate Bob", marker=".")
ax.plot(alice_hr, color="red", label="Heart Rate Alice", marker="v")
ax.grid()
ax.legend()
ax.set_ylabel("Heart Rate [BPM]")
ax.set_xlabel("Time")
ax_cadence = ax.twinx()
ax_cadence.plot(bob_cadence, color="purple",
label="Cadence Bob", marker=".", alpha=0.5)
ax_cadence.plot(alice_cadence, color="purple",
label="Cadence Alice", marker="v", alpha=0.5)
ax_cadence.legend()
ax_cadence.set_ylabel("Cadence [SPM]")
ax_cadence.set_ylim(158, 180)

太棒了!对数据的初步分析提供了有趣的观察结果。我们可以轻松区分 Bob 和 Alice 在最高心率和心率增加速率上的差异。此外,Bob 的步频似乎明显高于 Alice。
使用 DataFrame 实现可扩展性
然而,您可能已经注意到,为每个健康参数和运动员使用单独的变量(bob_hr、alice_hr、bob_cadence 和 alice_cadence)的方法是不可扩展的。在现实世界中,如果运动员和健康参数数量庞大,这种方法会很快变得不切实际和繁琐。
为了解决这个问题,我们可以利用 Pandas 的强大功能,通过使用 Pandas DataFrame 来表示多个运动员和健康参数的数据。通过以表格格式组织数据,我们可以轻松地同时管理和分析多个变量。
DataFrame 的每一行可以对应一个特定的时间戳,每一列可以表示特定运动员的健康参数。这种结构允许高效地存储和操作多维数据。
通过使用 DataFrame,我们可以消除对单独变量的需求,并将所有数据存储在一个对象中。这增强了代码的清晰度,简化了数据处理,并提供了对整个数据集更直观的表示。
bob_df = pd.concat([bob_hr.rename("heart_rate"),
bob_cadence.rename("cadence")], axis="columns")
这就是 Bob 健康数据的 Dataframe 外观。
| 心率 | 步频 | |
2023-06-08 14:00:00 | 112.359 | 175 |
2023-06-08 14:01:00 | 107.204 | 175 |
2023-06-08 14:02:00 | 116.617 | 175.513 |
2023-06-08 14:03:00 | 121.151 | 175.513 |
2023-06-08 14:04:00 | 123.27 | 175.513 |
2023-06-08 14:05:00 | 120.901 | 174.995 |
2023-06-08 14:06:00 | 130.24 | 174.995 |
2023-06-08 14:07:00 | 131.15 | 174.995 |
2023-06-08 14:08:00 | 131.402 | 174.669 |
引入分层 DataFrame
最后一个 dataframe 已经看起来好多了!但是现在,我们仍然需要为每个运动员创建一个新的 dataframe。这时 Pandas MultiIndex 可以提供帮助。让我们看看如何优雅地将多个运动员和健康参数的数据合并到一个 dataframe 中。
from itertools import product
bob_df = bob_hr.to_frame("value")
bob_df["athlete"] = "Bob"
bob_df["parameter"] = "heart_rate"
values = {
"Bob": {
"heart_rate": bob_hr,
"cadence": bob_cadence,
},
"Alice": {
"heart_rate": alice_hr,
"cadence": alice_cadence
}
}
sub_dataframes: list[pd.DataFrame] = []
for athlete, parameter in product(["Bob", "Alice"], ["heart_rate", "cadence"]):
sub_df = values[athlete][parameter].to_frame("values")
sub_df["athlete"] = athlete
sub_df["parameter"] = parameter
sub_dataframes.append(sub_df)
df = pd.concat(sub_dataframes).set_index(["athlete", "parameter"], append=True)
df.index = df.index.set_names(["timestamps", "athlete", "parameter"])
此代码处理运动员 Bob 和 Alice 的心率和步频数据。它执行以下步骤:
- 为 Bob 的心率数据创建一个
DataFrame,并添加运动员和参数的元数据列。 - 定义一个字典,其中存储 Bob 和 Alice 的心率和步频数据。
- 生成运动员和参数的组合(Bob/Alice 和 heart_rate/cadence)。
- 对于每个组合,创建具有相应数据和元数据列的子
dataframe。 - 将所有子
dataframe串联成一个单独的dataframe。 - 将索引设置为包含时间戳、运动员和参数的级别。这就是实际
MultiIndex被创建的地方。
这就是分层 dataframe df 的外观。
| 值 | |
(Timestamp('2023-06-08 14:00:00'), 'Bob', 'heart_rate') | 112.359 |
(Timestamp('2023-06-08 14:01:00'), 'Bob', 'heart_rate') | 107.204 |
(Timestamp('2023-06-08 14:02:00'), 'Bob', 'heart_rate') | 116.617 |
(Timestamp('2023-06-08 14:03:00'), 'Bob', 'heart_rate') | 121.151 |
(Timestamp('2023-06-08 14:04:00'), 'Bob', 'heart_rate') | 123.27 |
(Timestamp('2023-06-08 14:05:00'), 'Bob', 'heart_rate') | 120.901 |
(Timestamp('2023-06-08 14:06:00'), 'Bob', 'heart_rate') | 130.24 |
(Timestamp('2023-06-08 14:07:00'), 'Bob', 'heart_rate') | 131.15 |
(Timestamp('2023-06-08 14:08:00'), 'Bob', 'heart_rate') | 131.402 |
此时,我们得到了一个单独的 dataframe,它包含了任意数量的运动员和健康参数的所有信息。我们现在可以轻松使用 .xs 方法来查询分层 dataframe。
df.xs("Bob", level="athlete") # get all health data for Bob
| 值 | |
(Timestamp('2023-06-08 14:00:00'), 'heart_rate') | 112.359 |
(Timestamp('2023-06-08 14:01:00'), 'heart_rate') | 107.204 |
(Timestamp('2023-06-08 14:02:00'), 'heart_rate') | 116.617 |
(Timestamp('2023-06-08 14:03:00'), 'heart_rate') | 121.151 |
(Timestamp('2023-06-08 14:04:00'), 'heart_rate') | 123.27 |
df.xs("heart_rate", level="parameter") *# get all heart rates*
| 值 | |
(Timestamp('2023-06-08 14:00:00'), 'Bob') | 112.359 |
(Timestamp('2023-06-08 14:01:00'), 'Bob') | 107.204 |
(Timestamp('2023-06-08 14:02:00'), 'Bob') | 116.617 |
(Timestamp('2023-06-08 14:03:00'), 'Bob') | 121.151 |
(Timestamp('2023-06-08 14:04:00'), 'Bob') | 123.27 |
df.xs("Bob", level="athlete").xs
("heart_rate", level="parameter") # get heart_rate data for Bob
| 时间戳 | 值 |
2023-06-08 14:00:00 | 112.359 |
2023-06-08 14:01:00 | 107.204 |
2023-06-08 14:02:00 | 116.617 |
2023-06-08 14:03:00 | 121.151 |
2023-06-08 14:04:00 | 123.27 |
用例:地球温度变化
为了展示分层 DataFrame 的强大功能,让我们探讨一个真实而复杂的用例:分析过去几十年来地球表面温度的变化。为此,我们将利用 Kaggle 上提供的 数据集,该数据集总结了 美国国家航空航天局戈达德空间研究所 (NASA-GISS) 分发的全球地表温度变化数据。
检查和转换原始数据
让我们开始读取和检查数据。在深入分析之前,这一步对于更好地理解数据集的结构和内容至关重要。以下是如何使用 Pandas 来完成此操作:
from pathlib import Path
file_path = Path() / "data" / "Environment_Temperature_change_E_All_Data_NOFLAG.csv"
df = pd.read_csv(file_path , encoding='cp1252')
df.describe()

从初步检查中可以明显看出,数据组织在一个 dataframe 中,不同月份和国家有单独的行。然而,不同年份的值分布在 dataframe 的多个列中,这些列以 'Y' 前缀标记。这种格式使得有效读取和可视化数据具有挑战性。为了解决这个问题,我们将把数据转换为更结构化和分层的数据框格式,使我们能够更方便地查询和可视化数据。
from dataclasses import dataclass, field
from datetime import date
from pydantic import BaseModel
MONTHS = {
"January": 1,
"February": 2,
"March": 3,
"April": 4,
"May": 5,
"June": 6,
"July": 7,
"August": 8,
"September": 9,
"October": 10,
"November": 11,
"December": 12
}
class GistempDataElement(BaseModel):
area: str
timestamp: date
value: float
@dataclass
class GistempTransformer:
temperature_changes: list[GistempDataElement] = field(default_factory=list)
standard_deviations: list[GistempDataElement] = field(default_factory=list)
def _process_row(self, row) -> None:
relevant_elements = ["Temperature change", "Standard Deviation"]
if (element := row["Element"]) not in relevant_elements or
(month := MONTHS.get(row["Months"])) is None:
return None
for year, value in row.filter(regex="Y.*").items():
new_element = GistempDataElement(
timestamp=date(year=int(year.replace("Y", "")), month=month, day=1),
area=row["Area"],
value=value
)
if element == "Temperature change":
self.temperature_changes.append(new_element)
else:
self.standard_deviations.append(new_element)
@property
def df(self) -> pd.DataFrame:
temp_changes_df = pd.DataFrame.from_records([elem.dict()
for elem in self.temperature_changes])
temp_changes = temp_changes_df.set_index
(["timestamp", "area"]).rename(columns={"value": "temp_change"})
std_deviations_df = pd.DataFrame.from_records([elem.dict()
for elem in self.standard_deviations])
std_deviations = std_deviations_df.set_index
(["timestamp", "area"]).rename(columns={"value": "std_deviation"})
return pd.concat([temp_changes, std_deviations], axis="columns")
def process(self):
environment_data = Path() / "data" /
"Environment_Temperature_change_E_All_Data_NOFLAG.csv"
df = pd.read_csv(environment_data, encoding='cp1252')
df.apply(self._process_row, axis="columns")
此代码介绍了 GistempTransformer 类,它演示了从 CSV 文件处理温度数据以及创建包含温度变化和标准偏差的分层 DataFrame。
GistempTransformer 类定义为 dataclass,包含两个列表 temperature_changes 和 standard_deviations,用于存储处理后的数据元素。_process_row 方法负责处理输入 DataFrame 的每一行。它会检查相关元素,例如“Temperature change”和“Standard Deviation”,从 Months 列中提取月份,并创建 GistempDataElement 类的实例。然后根据元素类型将这些实例附加到相应的列表中。
df 属性通过合并 temperature_changes 和 standard_deviations 列表来返回一个 DataFrame。这个分层 DataFrame 具有一个 MultiIndex,其级别代表时间戳和区域,从而提供了数据的结构化组织。
transformer = GistempTransformer()
transformer.process()
df = transformer.df
| 温度变化 | 标准偏差 | |
(datetime.date(1961, 1, 1), 'Afghanistan') | 0.777 | 1.95 |
(datetime.date(1962, 1, 1), 'Afghanistan') | 0.062 | 1.95 |
(datetime.date(1963, 1, 1), 'Afghanistan') | 2.744 | 1.95 |
(datetime.date(1964, 1, 1), 'Afghanistan') | -5.232 | 1.95 |
(datetime.date(1965, 1, 1), 'Afghanistan') | 1.868 | 1.95 |
分析气候数据
现在我们已经将所有相关数据整合到一个 dataframe 中,我们可以继续检查和可视化数据。我们的重点是检查每个区域的线性回归线,因为它们提供了对过去几十年温度变化的总体趋势的见解。为了便于可视化,我们将创建一个函数来绘制温度变化及其相应的回归线。
def plot_temperature_changes(areas: list[str]) -> None:
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(211)
ax2 = fig.add_subplot(212)
for area in areas:
df_country = df[df.index.get_level_values("area") == area].reset_index()
dates = df_country["timestamp"].map(datetime.toordinal)
gradient, offset = np.polyfit(dates, df_country.temp_change, deg=1)
ax1.scatter(df_country.timestamp, df_country.temp_change, label=area, s=5)
ax2.plot(df_country.timestamp, gradient * dates + offset, label=area)
ax1.grid()
ax2.grid()
ax2.legend()
ax2.set_ylabel("Regression Lines [°C]")
ax1.set_ylabel("Temperature change [°C]")
在此函数中,我们在 Pandas MultiIndex 上使用 **get_level_values** 方法,以在不同级别上有效地查询分层 Dataframe 中的数据。让我们使用此函数来可视化不同大陆的温度变化。
plot_temperature_changes
(["Africa", "Antarctica", "Americas", "Asia", "Europe", "Oceania"])

从这张图中,我们可以得出几个关键结论:
- 所有大陆的回归线都具有正斜率,这表明全球地表温度呈上升趋势。
- 与其它大陆相比,欧洲的回归线斜率明显更陡,这意味着欧洲的温度升幅更为明显。这一发现与欧洲升温速度快于其它地区的观察结果一致。
- 导致欧洲温度升幅高于南极洲的具体因素很复杂,需要详细的科学研究。然而,一个促成因素可能是洋流的影响。欧洲受到湾流等暖洋流的影响,这些洋流将热量从热带地区输送到该区域。这些洋流在调节温度方面发挥作用,并可能导致欧洲观察到的相对升温幅度更大。相比之下,南极洲被寒冷的洋流包围,其气候深受南大洋和南极环流的影响,它们阻碍了温暖海水的入侵,从而限制了升温效应。
现在,让我们将分析重点放在欧洲本身,检查欧洲不同地区的温度变化。我们可以通过为每个欧洲地区创建单独的图来做到这一点。
plot_temperature_changes
(["Southern Europe", "Eastern Europe", "Northern Europe", "Western Europe"])
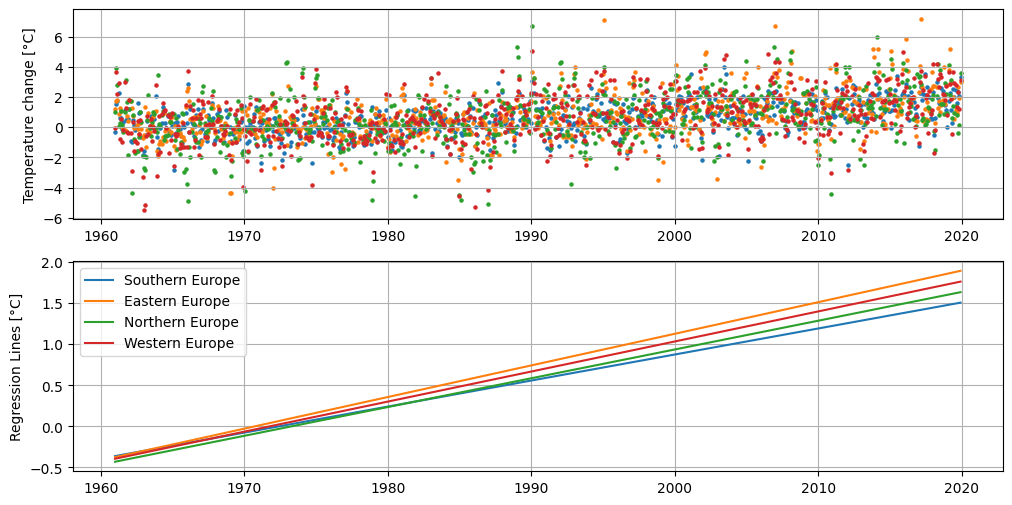
从欧洲不同地区绘制的温度变化来看,我们观察到整个欧洲大陆的总体温度上升幅度相当。虽然不同地区回归线的陡峭程度可能略有差异,例如东欧的回归线比南欧略陡,但在地区之间未观察到显著差异。
受气候变化影响最大和最小的十个国家
现在,让我们将重点转移到识别自 2000 年以来平均温度升幅最大的前 10 个国家。以下是如何检索国家列表的示例:
df[df.index.get_level_values(level="timestamp") >
date(2000, 1, 1)].groupby("area").mean().sort_values
(by="temp_change",ascending=False).head(10)
| 区域 | 温度变化 | 标准偏差 |
斯瓦尔巴群岛和扬马延岛 | 2.61541 | 2.48572 |
爱沙尼亚 | 1.69048 | nan |
科威特 | 1.6825 | 1.12843 |
白俄罗斯 | 1.66113 | nan |
芬兰 | 1.65906 | 2.15634 |
斯洛文尼亚 | 1.6555 | nan |
俄罗斯联邦 | 1.64507 | nan |
巴林 | 1.64209 | 0.937431 |
东欧 | 1.62868 | 0.970377 |
奥地利 | 1.62721 | 1.56392 |
为了提取自 2000 年以来平均温度升幅最大的前 10 个国家,我们执行以下步骤:
- 使用
df.index.get_level_values(level='timestamp') >= date(2000, 1, 1)过滤dataframe,使其仅包含年份大于或等于2000的行。 - 使用
.groupby('area')按 'Area'(国家)对数据进行分组。 - 使用
.mean()计算每个国家的平均温度变化。 - 使用
**.sort_values(by="temp_change",ascending=True).head(10)**选择平均温度变化最大的前 10 个国家。
这一结果与我们之前的观察一致,证实欧洲比其它大陆经历了更高的温度升幅。
继续我们的分析,现在让我们探讨受温度升幅影响最小的十个国家。我们可以利用与之前相同的方法来提取这些信息。以下是如何检索国家列表的示例:
df[df.index.get_level_values(level="timestamp") > date(2000, 1, 1)].groupby
("area").mean().sort_values(by="temp_change",ascending=True).head(10)
| 区域 | 温度变化 | 标准偏差 |
皮特凯恩群岛 | 0.157284 | 0.713095 |
马绍尔群岛 | 0.178335 | nan |
南乔治亚岛和南桑威奇群岛 | 0.252101 | 1.11 |
密克罗尼西亚(联邦) | 0.291996 | nan |
智利 | 0.297607 | 0.534071 |
威克岛 | 0.306269 | nan |
诺福克岛 | 0.410659 | 0.594073 |
阿根廷 | 0.488159 | 0.91559 |
津巴布韦 | 0.493519 | 0.764067 |
南极洲 | 0.527987 | 1.55841 |
我们观察到此列表中的大多数国家都是位于南半球的偏远小岛。这一发现进一步支持了我们之前的结论,即与其它地区相比,南部大陆(尤其是 南极洲)受气候变化的影响较小。
夏季和冬季的温度变化
现在,让我们深入进行更复杂的查询,使用分层 dataframe。在本特定用例中,我们的重点是分析冬季和夏季的温度变化。为了本次分析的目的,我们将冬季定义为 12 月、1 月和 2 月,而夏季则包括 6 月、7 月和 8 月。通过利用 Pandas 和分层 dataframe 的强大功能,我们可以轻松可视化欧洲在这些季节的温度变化。以下是完成此任务的示例代码片段:
all_winters = df[df.index.get_level_values(level="timestamp").map
(lambda x: x.month in [12, 1, 2])]
all_summers = df[df.index.get_level_values(level="timestamp").map
(lambda x: x.month in [6, 7, 8])]
winters_europe = all_winters.xs("Europe", level="area").sort_index()
summers_europe = all_summers.xs("Europe", level="area").sort_index()
fig = plt.figure(figsize=(12, 6))
ax = fig.add_subplot(111)
ax.plot(winters_europe.index, winters_europe.temp_change,
label="Winters", marker="o", markersize=4)
ax.plot(summers_europe.index, summers_europe.temp_change,
label="Summers", marker='o', markersize=4)
ax.grid()
ax.legend()
ax.set_ylabel("Temperature Change [°C]")

从这张图中,我们可以观察到冬季的温度变化比夏季的温度变化更不稳定。为了量化这种差异,让我们计算两个季节的温度变化标准差。
pd.concat([winters_europe.std().rename("winters"),
summers_europe.std().rename("summers")], axis="columns")
| 冬季 | 夏季 | |
温度变化 | 1.82008 | 0.696666 |
结论
总之,精通 Pandas 中的 MultiIndex 为处理复杂的数据分析任务提供了强大的工具。通过利用 MultiIndex,用户可以以灵活直观的方式有效地组织和分析多维数据集。处理行和列的分层结构的能力增强了代码的清晰度,简化了数据处理,并能够同时分析多个变量。无论是跟踪运动员的健康参数还是分析地球随时间的温度变化,理解和利用 Pandas 中的 MultiIndex 都能充分发挥该库处理复杂数据场景的潜力。
您可以在此处找到此帖子中包含的所有代码:https://github.com/GlennViroux/pandas-multi-index-blog。