
spSearchTables: 按名称或值搜索和查找表或列
5.00/5 (4投票s)
spSearchTables:
引言
我一直从事咨询工作,每1到3年更换一次项目。每次更换项目,你都必须处理新的数据库,而这些数据库通常都是没有文档的。我通常处理中等规模的数据库(少于300张表),也听说过同事处理过更大的数据库(约700张表),但最近我加入了一个新项目,这个项目非常庞大(有几个数据库,其中一些包含惊人的2000张表!),试图理解它们有时非常棘手。因此,我决定编写这个辅助存储过程,它允许你使用LIKE通配符语法搜索数据库、表、列或列数据。
背景
使用这段代码非常简单,只需将存储过程代码粘贴到SSMS中,然后使用你想要的搜索选项调用它。存储过程的T-SQL代码很复杂且棘手,但我认为任何对T-SQL有中等理解水平的人都能理解它。
Using the Code
你可以在我的GitHub仓库查看文档、源代码以及如何使用spSearchTables的示例查询。以下是实现的主要概念:
- 代码输出一个包含以下列的表:
- [
Database]:与@dbSearchPattern参数匹配的数据库名称 - [
Schema]:与表关联的架构名称 - [
Table]:与@tableSearchPattern参数匹配的表名称 - [
FullTableName]:它是数据库+架构+表的简单拼接 -
[
MatchingColumns]:当@columnsSearchPattern和@valuePattern不为null时,与它们匹配的列名的逗号分隔列表 -
[
MatchingWhereColumns]:辅助列,最终输出不显示;它类似于MatchingColumns,但显示用于LIKE模式匹配的转换后的列语句(见下文)。 - [
MatchingSelect]:当@valuePattern不为null时,返回匹配@valuePattern的行的select语句(支持所有列数据类型)。匹配的列首先在输出中显示。
- [
spSearchTables在执行以下查询从sys.databases 目录检索所有数据库列表后,会通过游标进行迭代。SELECT [name] FROM sys.databases
它不使用Microsoft的
sp_MSforeachdb,因为它支持的脚本长度有限,最多为2000个字符(此SP生成的脚本更长,最初我使用了sp_MSforeachdb,但在花了近2个小时才弄清楚为什么会出现奇怪的错误后,我才发现输入脚本在2K字符处被截断了🤬)。- 对于每个匹配的数据库,它都会执行这个通用脚本,并将4个输入参数
@valuePattern, @columnSearchPattern, @columnTypeSearchPattern和@schemaSearchPattern传递下去。USE [?] DECLARE @dbName nvarchar(200), @schemaName nvarchar(200),_ @tableName nvarchar(200), @columnName nvarchar(200), @columnType nvarchar(200), _ @fullTableName nvarchar(1000) -- current data DECLARE @oldDbName nvarchar(200), @oldSchemaName nvarchar(200),_ @oldTableName nvarchar(200), @oldFullTableName nvarchar(1000) -- old data DECLARE @whereColumnName nvarchar(200), @whereCondition nvarchar(400), _ @whereClause nvarchar(max), @sql nvarchar(max), @selectSql nvarchar(max), _ @columnListSelect nvarchar(max), @columnList nvarchar(max) -- helper variables -- try to parse innerValuePattern with geometry and geography types DECLARE @geometry geometry, @geography geography, @compatibilityLevel int BEGIN TRY SELECT @compatibilityLevel = compatibility_level _ FROM sys.databases WHERE database_id=DB_ID() SELECT @geography=geography::Parse(@innerValuePattern) SELECT @geometry=geometry::Parse(@innerValuePattern) END TRY BEGIN CATCH END CATCH PRINT N'Checking database [?]' DECLARE [tables] CURSOR LOCAL READ_ONLY FORWARD_ONLY FOR SELECT N'['+ DB_NAME() +N']' AS DatabaseName,N'['+ s.[name] +N']' _ AS SchemaName,N'['+ t.[name] +N']' AS TableName,N'['+ c.[name] +N']' _ AS ColumnName,tp.[Name] AS ColumnType, _ N'['+DB_NAME()+N'].['+s.[name]+N'].['+t.[name]+N']' AS FullTableName FROM sys.tables t INNER JOIN sys.schemas s ON t.schema_id=s.schema_id _ AND (@innerSchemaSearchPattern IS NULL OR s.[name] LIKE @innerSchemaSearchPattern) INNER JOIN sys.columns c ON (@innerColumnSearchPattern IS NULL _ OR c.[name] LIKE @innerColumnSearchPattern) AND c.[object_id]=t.[object_id] INNER JOIN sys.types tp ON tp.user_type_id = c.user_type_id _ AND (@innerColumnTypeSearchPattern IS NULL OR tp.[name] _ LIKE @innerColumnTypeSearchPattern) ORDER BY FullTableName SET @oldFullTableName = NULL OPEN [tables] FETCH NEXT FROM [tables] INTO @dbName, @schemaName, @tableName, _ @columnName, @columnType, @fullTableName WHILE (1=1) BEGIN IF ((@oldFullTableName<>@fullTableName AND @oldFullTableName IS NOT NULL) _ OR @@FETCH_STATUS<>0) BEGIN IF (@whereClause IS NOT NULL) BEGIN SET @whereClause = REPLACE(CONCAT(@whereClause,N'[???]') _ COLLATE DATABASE_DEFAULT,N'OR [???]',N'') --trim last "OR " SET @selectSql = N'SELECT [??] FROM '+@oldFullTableName+N' _ WHERE ' + @whereClause END ELSE SET @selectSql = NULL IF (@columnListSelect IS NOT NULL) BEGIN SET @columnListSelect = N'REPLACE(CONCAT('+@columnListSelect + _ N'''[???]'') COLLATE DATABASE_DEFAULT,N'',[???]'',N'''')' -- trim last "," SET @columnList = N'REPLACE(CONCAT('+@columnList + N'''[???]'') _ COLLATE DATABASE_DEFAULT,N'',[???]'',N'''')' -- trim last "," SET @sql = N' INSERT INTO #Output SELECT '''+@oldDbName+N''','''+_ @oldSchemaName+N''','''+@oldTableName+N''','''+@oldFullTableName+N''','+_ @columnList+N','+@columnListSelect+N','''+_ REPLACE(@selectSql COLLATE DATABASE_DEFAULT,'''','''''')+N''''+_ IIF(@whereClause IS NOT NULL,' FROM '+@oldFullTableName+' WHERE '+_ @whereClause,'') END ELSE IF (@oldDbName IS NOT NULL) BEGIN SET @columnList = N'REPLACE(CONCAT('+@columnList + N'''[???]'') _ COLLATE DATABASE_DEFAULT,N'',[???]'',N'''')' -- trim last "," SET @sql = N' INSERT INTO #Output SELECT '''+@oldDbName+N''','''+_ @oldSchemaName+N''','''+@oldTableName+N''','''+@oldFullTableName+N''','+_ @columnList+N',NULL,NULL' END IF (@selectSql IS NOT NULL) SET @sql = N'IF EXISTS ('+REPLACE(@selectSql _ COLLATE DATABASE_DEFAULT,'[??]','1')+N')' +@sql IF (@sql IS NOT NULL) BEGIN PRINT @sql EXECUTE sp_executesql @sql END IF (@@FETCH_STATUS<>0) BREAK SET @whereClause = NULL SET @columnListSelect = NULL SET @columnList = NULL END IF (@innerValuePattern IS NOT NULL) BEGIN SET @whereColumnName = (CASE WHEN @columnType _ COLLATE DATABASE_DEFAULT = N'image' THEN N'CONVERT(NVARCHAR(MAX),_ CONVERT(VARBINARY(MAX),'+@columnName+N'),1)' WHEN @columnType _ COLLATE DATABASE_DEFAULT = N'xml' THEN N'CONVERT(nvarchar(MAX),'+_ @columnName+N')' WHEN @columnType COLLATE DATABASE_DEFAULT _ IN (N'hierarchyid') THEN @columnName+N'.ToString()' _ WHEN @columnType COLLATE DATABASE_DEFAULT IN (N'datetime',N'datetime2',_ N'datetimeoffset',N'time') THEN N'CONVERT(nvarchar(50),'+_ @columnName+N',126)' ELSE @columnName END) IF (@columnType COLLATE DATABASE_DEFAULT IN (N'geography',N'geometry')) BEGIN IF (@compatibilityLevel>=130 AND ((@columnType _ COLLATE DATABASE_DEFAULT = N'geometry' AND @geometry IS NOT NULL) OR (@columnType COLLATE DATABASE_DEFAULT = N'geography' _ AND @geography IS NOT NULL))) SET @whereCondition = N'COALESCE('+@whereColumnName+N'.STContains_ ('+IIF(@columnType COLLATE DATABASE_DEFAULT = N'geometry',_ N'geometry::Parse('''+@geometry.ToString()+N''')),0)=1)',_ N'geography::Parse('''+@geography.ToString()+N''')),0)=1') ELSE SET @whereCondition = N'(' + @whereColumnName+N'.ToString() _ LIKE N'''+@innerValuePattern+N''' COLLATE DATABASE_DEFAULT)' SET @whereColumnName = @whereColumnName+N'.ToString()' END ELSE SET @whereCondition = N'(' + @whereColumnName+N' LIKE '''+_ @innerValuePattern+N''')' SET @whereClause = @whereClause + @whereCondition + N' OR ' SET @columnListSelect = @columnListSelect + N'IIF(SUM(CASE WHEN '+_ @whereCondition+' THEN 1 ELSE 0 END)>0,'''+@whereColumnName+' _ AS '+@columnName+','',NULL),' SET @columnList = @columnList + N'IIF(SUM(CASE WHEN '+@whereCondition+' _ THEN 1 ELSE 0 END)>0,'''+@columnName+','',NULL),' END ELSE BEGIN SET @whereClause = NULL SET @columnListSelect = NULL SET @columnList = @columnList + N'''' + @columnName + N','',' END SET @oldDbName = @dbName SET @oldSchemaName = @schemaName SET @oldTableName = @tableName SET @oldFullTableName = @fullTableName FETCH NEXT FROM [tables] INTO @dbName, @schemaName, @tableName, _ @columnName, @columnType, @fullTableName END CLOSE [tables]; DEALLOCATE [tables]; - 上面的通用脚本选择循环中的外部数据库,并再次查询*关于其表、架构、列及其数据类型的系统目录*,并对所有这些进行迭代。
SELECT N'[' + DB_NAME() + N']' AS DatabaseName, N'[' + s.[name] + N']' AS SchemaName, N'[' + t.[name] + N']' AS TableName, N'[' + c.[name] + N']' AS ColumnName, tp.[Name] AS ColumnType, N'[' + DB_NAME() + N'].[' + s.[name] + N'].[' + t.[name] + N']' _ AS FullTableName FROM sys.tables t INNER JOIN sys.schemas s ON t.schema_id=s.schema_id _ AND (@innerSchemaSearchPattern IS NULL OR s.[name] LIKE @innerSchemaSearchPattern) INNER JOIN sys.columns c ON (@innerColumnSearchPattern IS NULL _ OR c.[name] LIKE @innerColumnSearchPattern) AND c.[object_id]=t.[object_id] INNER JOIN sys.types tp ON tp.user_type_id = c.user_type_id _ AND (@innerColumnTypeSearchPattern IS NULL OR tp.[name] _ LIKE @innerColumnTypeSearchPattern) ORDER BY FullTableName然后代码变得非常复杂和棘手,但基本上,它会构建并执行下面两个查询之一,这两个查询会将找到的过滤后的表/列的信息填充到输出表中。
-
当
@valuePattern参数为null时生成的查询INSERT INTO #Output SELECT '[Northwind]', '[dbo]', '[Order Details]', '[Northwind].[dbo].[Order Details]', REPLACE( CONCAT('[OrderID],', '[ProductID],', '[UnitPrice],', _ '[Quantity],', '[Discount],', '[???]') _ COLLATE DATABASE_DEFAULT, N',[???]', N'' ), NULL, NULLMatchingColumns基本上是一个可变长度的CONCAT,包含所有列名加上逗号,再加上一个额外的自定义后缀('[???]',希望它不会匹配任何表名)。后缀用于删除最后一个逗号(通过REPLACE函数将字符串',[???]'替换为空字符串)。这是一种变通方法,可以避免执行内部子查询来检索字符串长度,以便使用SUBSTRING来修剪最后一个逗号。由于我们不查询任何值,所以
MatchingWhereColumns / MatchingSelect参数为NULL。 - 当
@valuePattern参数不为null时生成的查询IF EXISTS ( SELECT 1 FROM [AdventureWorks2022].[Person].[Address] WHERE ([AddressID] LIKE '%898)') OR ([AddressLine1] LIKE '%898)') OR ([AddressLine2] LIKE '%898)') OR ([City] LIKE '%898)') OR ([StateProvinceID] LIKE '%898)') OR ([PostalCode] LIKE '%898)') OR ([SpatialLocation].ToString() LIKE N'%898)' _ COLLATE DATABASE_DEFAULT) OR ([rowguid] LIKE '%898)') OR (CONVERT(nvarchar(50), [ModifiedDate], 126) LIKE '%898)') ) INSERT INTO #Output SELECT '[AdventureWorks2022]', '[Person]', '[Address]', '[AdventureWorks2022].[Person].[Address]', REPLACE( CONCAT( IIF(SUM(CASE WHEN ([AddressID] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[AddressID],', NULL), IIF(SUM(CASE WHEN ([AddressLine1] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[AddressLine1],', NULL), IIF(SUM(CASE WHEN ([AddressLine2] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[AddressLine2],', NULL), IIF(SUM(CASE WHEN ([City] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[City],', NULL), IIF(SUM(CASE WHEN ([StateProvinceID] _ LIKE '%898)') THEN 1 ELSE 0 END) > 0, '[StateProvinceID],', NULL), IIF(SUM(CASE WHEN ([PostalCode] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[PostalCode],', NULL), IIF( SUM( CASE WHEN ([SpatialLocation].ToString() _ LIKE N'%898)' _ COLLATE DATABASE_DEFAULT) THEN 1 ELSE 0 END ) > 0, '[SpatialLocation],', NULL), IIF(SUM(CASE WHEN ([rowguid] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[rowguid],', NULL), IIF( SUM( CASE WHEN (CONVERT(nvarchar(50), _ [ModifiedDate], 126) LIKE '%898)') THEN 1 ELSE 0 END ) > 0, '[ModifiedDate],', NULL), '[???]' ) COLLATE DATABASE_DEFAULT, N',[???]', N'' ), REPLACE( CONCAT( IIF(SUM(CASE WHEN ([AddressID] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[AddressID] AS [AddressID],', NULL), IIF(SUM(CASE WHEN ([AddressLine1] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[AddressLine1] AS [AddressLine1],', NULL), IIF(SUM(CASE WHEN ([AddressLine2] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[AddressLine2] AS [AddressLine2],', NULL), IIF(SUM(CASE WHEN ([City] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[City] AS [City],', NULL), IIF( SUM( CASE WHEN ([StateProvinceID] LIKE '%898)') THEN 1 ELSE 0 END ) > 0, '[StateProvinceID] AS [StateProvinceID],', NULL), IIF(SUM(CASE WHEN ([PostalCode] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[PostalCode] AS [PostalCode],', NULL), IIF( SUM( CASE WHEN ([SpatialLocation].ToString() _ LIKE N'%898)' _ COLLATE DATABASE_DEFAULT) THEN 1 ELSE 0 END ) > 0, '[SpatialLocation].ToString() _ AS [SpatialLocation],', NULL), IIF(SUM(CASE WHEN ([rowguid] LIKE '%898)') _ THEN 1 ELSE 0 END) > 0, '[rowguid] AS [rowguid],', NULL), IIF( SUM( CASE WHEN (CONVERT(nvarchar(50), _ [ModifiedDate], 126) _ LIKE '%898)') THEN 1 ELSE 0 END ) > 0, 'CONVERT(nvarchar(50),[ModifiedDate],126) _ AS [ModifiedDate],', NULL), '[???]' ) COLLATE DATABASE_DEFAULT, N',[???]', N'' ), 'SELECT [??] FROM [AdventureWorks2022].[Person].[Address] _ WHERE ([AddressID] LIKE ''%898)'') OR ([AddressLine1] _ LIKE ''%898)'') OR ([AddressLine2] LIKE ''%898)'') _ OR ([City] LIKE ''%898)'') OR ([StateProvinceID] LIKE ''%898)'') _ OR ([PostalCode] LIKE ''%898)'') OR ([SpatialLocation].ToString() _ LIKE N''%898)'' COLLATE DATABASE_DEFAULT) OR ([rowguid] _ LIKE ''%898)'') OR (CONVERT(nvarchar(50),[ModifiedDate],126) _ LIKE ''%898)'') ' FROM [AdventureWorks2022].[Person].[Address] WHERE ([AddressID] LIKE '%898)') OR ([AddressLine1] LIKE '%898)') OR ([AddressLine2] LIKE '%898)') OR ([City] LIKE '%898)') OR ([StateProvinceID] LIKE '%898)') OR ([PostalCode] LIKE '%898)') OR ([SpatialLocation].ToString() LIKE N'%898)' _ COLLATE DATABASE_DEFAULT) OR ([rowguid] LIKE '%898)') OR (CONVERT(nvarchar(50), [ModifiedDate], 126) LIKE '%898)')
-
基本上,在INSERT语句之前,我们有一个IF EXISTS语句,它通过查询检查过滤后的任何列是否使用标准的SQL LIKE子句和OR条件匹配@valuePattern参数。INSERT语句类似于之前的查询之一,唯一的改变是:
MatchingColumns (MatchingWhereColumns 当时为null):第一个区别是我们还有一个FROM和WHERE子句来测试过滤后的列是否匹配@valuePattern参数,这意味着可能会返回多个匹配的行,因此必须执行某种聚合函数来只返回一个字符串。我使用了一个CASE条件,如果列匹配@valuePattern参数,则返回1或0,然后我们通过SUM运算符聚合所有这些值,所以查询基本上返回n值,如果正在检查的列在n行中与@valuePattern匹配。最后,我们通过一个IIF运算符将此数字转换为字符串,如果SUM大于0(即,至少有一个匹配项),则返回列名后跟逗号,否则返回NULL。同样,这里使用了REPLACE / CONCAT技巧来删除最后一个逗号。
MatchingSelect这次列不为null,但它包含IF EXISTS子查询,以便用户可以从输出表结果中提取它,并在SSMS中执行它,以快速检索特定表中的匹配列和行。
最后一点,我指出,对于某些特定的列数据类型,为了能够与LIKE运算符一起使用,需要进行某种转换。
image --> CONVERT(NVARCHAR(MAX),CONVERT(VARBINARY(MAX),@columnName),1)xml --> CONVERT(nvarchar(MAX),@columnName)hierarchyid -->@columnName.ToString()geometry或geography--> 这两种列类型行为不同,因为除了列之外,它们还会更改where条件,该条件是以下两者之一:@columnName.STContains(geography::Parse(@valuePattern)),如果@valuePattern代表一个有效的WKT并且支持STContains方法,例如,数据库compatibility_level是>= 130 [SQL Server 2016]@columnName.ToString() LIKE @valuePattern在所有其他情况下
datetime,datetime2,datetimeoffset,time --> CONVERT(nvarchar(50),@columnName,126)[这是ISO8601格式,即'yyyy-mm-ddThh:mi:ss.mmm']
以下是示例表输出:
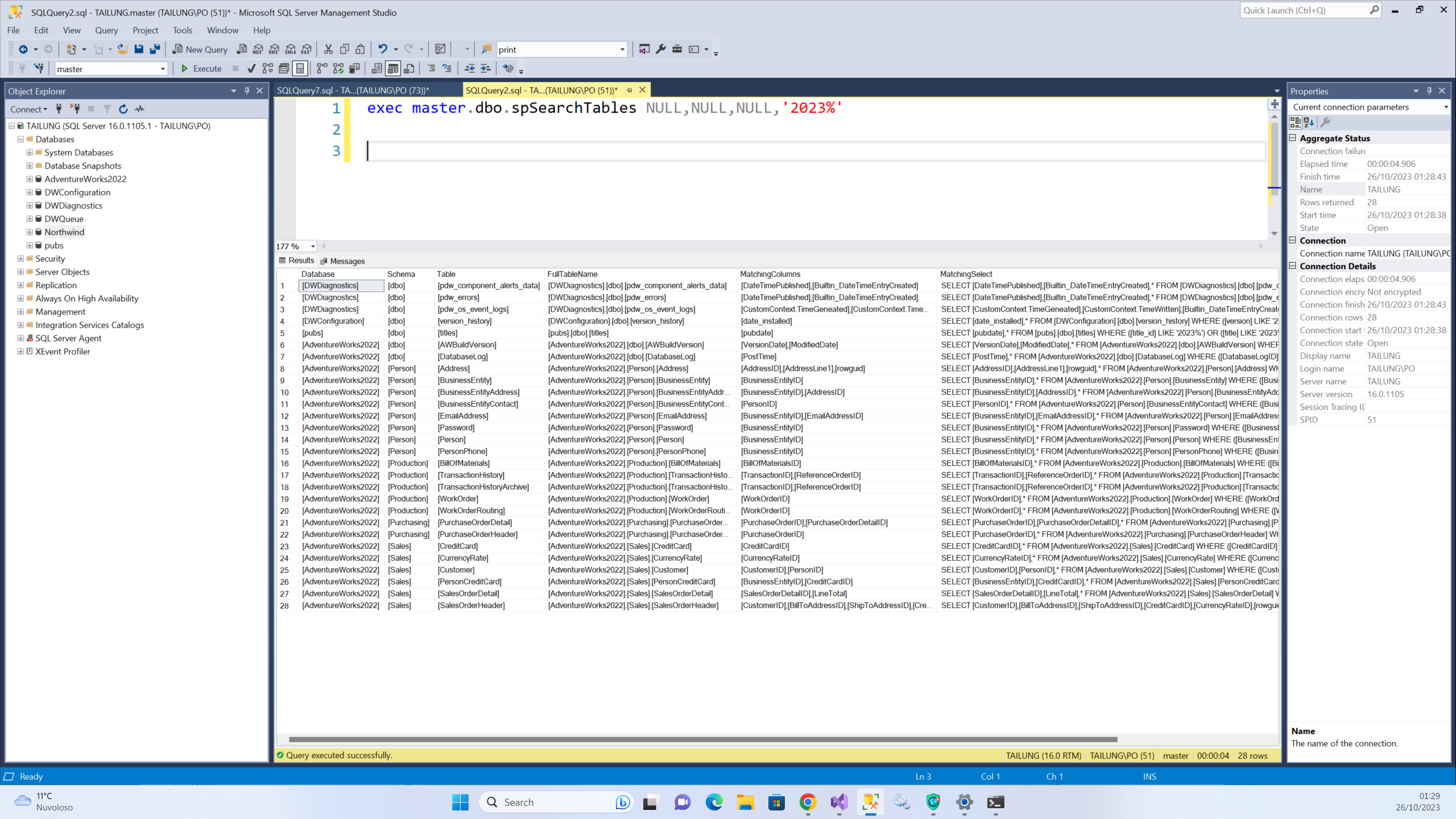
spSearchTables会在SSMS的**Messages**选项卡中记录用于故障排除的通用脚本,然后是为每个表执行的所有查询,以填充输出表。
我在Microsoft提供的三个著名SQL Server数据库(Northwind, AdventureWorks2022和pubs)上测试了该代码,一切运行正常,因此希望此查询能够支持大量的数据库和几乎任何类型的列数据类型(如果不支持,请通过电子邮件告知我)。将来我可能还会添加某种单元测试,当我有空闲时间的时候。
关注点
我认为从匹配查询的行中提取逗号分隔的匹配列列表非常巧妙(尽管有点 hacky),所以请仔细阅读关于MatchingColumns输出string是如何创建的部分。
历史
- V1.0(2023年10月26日)
- 初始版本
- V1.1(2023年10月31日)
- 添加了
@schemaSearchPattern和@columnTypeSearchPattern参数。 - 修复了geometry列类型中的bug,WKT可用于
@valuePattern以对空间列执行STContains查询(当支持时,例如数据库兼容级别>=130)。
- 添加了