
创建你自己的自定义聊天机器人
在 Intel® 处理器上快速轻松地训练大型语言模型
大型语言模型 (LLM) 近来因其在对话代理方面的非凡表现而备受关注,例如 ChatGPT*、GPT-4* 和 Bard*。然而,LLM 受限于训练或微调所需的高昂成本和时间。这是由于其庞大的模型规模和数据集。
在本文中,我们将演示如何利用现有的硬件轻松训练和微调自定义聊天机器人。我们使用第四代 Intel® Xeon® 可扩展处理器,通过系统化的方法来创建我们的聊天机器人,该方法能够生成特定领域的数据库和优化的微调代码库。
我们的方法
斯坦福的 Alpaca 是一个指令遵循语言模型,它是在 Meta 的 LLaMA 模型基础上进行微调的。受该项目的启发,我们开发了一种增强的方法来创建自定义的、特定领域的聊天机器人。虽然有几种语言模型可供选择(包括一些性能更好的模型),但我们选择了 Alpaca,因为它是一个开源模型。
聊天机器人的工作流程包含四个主要步骤:引导式种子生成、自由(非引导式)种子生成、样本生成和微调(图 1)。

在详细介绍这些步骤之前,我们想先介绍一个在种子任务生成中很有用的提示模板。图 2 显示了来自 Alpaca 的通用任务示例提示。

我们修改了模板,增加了一个新要求;即:“生成的任务指令应与 <领域名称> 相关问题相关。”这有助于生成与指定领域相关的种子任务。为了生成更多样化的种子任务,我们同时使用了引导式和自由(非引导式)种子任务生成。
引导式种子任务生成利用了来自 Alpaca 的现有种子任务。对于每个种子任务,我们将领域提示模板的内容结合起来,并将其输入到现有的对话代理中。我们预期会生成相应数量的任务(例如,在图 2 的提示模板中定义的 20 个)。此类文本生成是因果语言模型的典型用例之一。
非引导式种子任务生成直接将领域提示模板输入到对话代理中,而无需指定额外的种子任务。我们将非引导式种子任务生成称为“自由”生成。我们使用这种方法生成新的领域种子任务(图 3)。
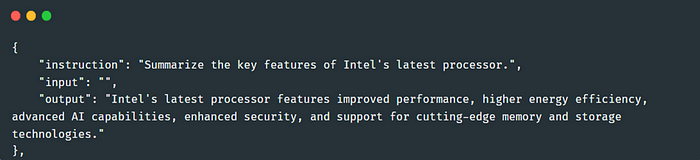
利用这些种子任务,我们再次调用现有的对话代理来生成指令样本。由于使用了领域提示模板,输出遵循“指令”、“输入”和“输出”的格式要求。我们重复此过程,生成 2,000 个指令样本用于微调(图 4)。

您可能已经注意到领域种子任务和指令样本之间的相似之处。您可以将它们分别视为 ChatGPT 的提示和由此产生的输出,前者影响后者。
训练您自己的聊天机器人
我们使用 低秩适应 (LoRA) 方法来高效地微调 LLM,而不是对拥有数十亿参数的整个 LLM 进行微调。LoRA 会冻结预训练模型的权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每个层中,从而大大减少下游任务的可训练参数数量。
除了参数高效微调之外,我们还可以利用硬件和软件加速来加快微调过程。硬件加速的一个例子是 Intel® Advanced Matrix Extensions (Intel® AMX-BF16) 指令,可在第四代 Intel Xeon 可扩展处理器上使用,这些指令专门用于加速 AI 性能。包含在 PyTorch*、Intel® Extension for PyTorch* 和 Hugging Face* transformers 中的软件优化也有助于加快性能,与这些框架和库的未优化版本相比。
我们还可以启用指令样本拼接,以进一步改进微调过程。基本思想是将多个标记化的句子拼接成一个更长、更集中的句子作为训练样本,而不是使用多个不同长度的训练样本。这有助于最大化底层硬件效率。
以上所有优化都在单个计算节点上进行。您还可以在微调过程中执行多节点微调,并使用分布式数据并行来利用更多的计算能力。
现在,让我们开始训练一个领域聊天机器人
- 查看来自 Intel® Extension for Transformers 的示例代码。
- 安装 requirements 文件 中定义的必要软件包。
- 下载预训练模型。您可以从 Hugging Face 下载 FLAN-T5。您可以直接从 Meta 请求访问 LLaMA,或者使用 Hugging Face 上的替代版本。
- 使用图 5 中所示的脚本和命令开始训练。有关更多详细信息,请参阅 用户指南。
 图 5. 多节点微调脚本
图 5. 多节点微调脚本
结果
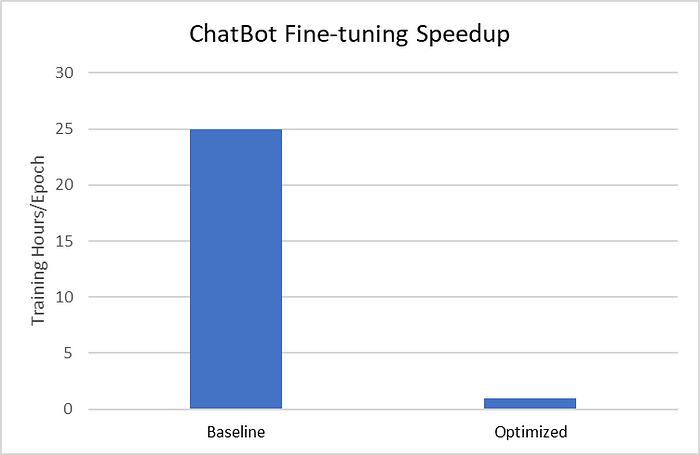
我们使用 52,000 个来自 Alpaca 的通用指令样本和我们生成的 2,000 个领域指令样本,在两个流行的 LLM(LLaMA-7B 和 FLAN-T5 XL)上测试了微调。利用前面描述的软件优化技术,我们在第四代 Intel Xeon 可扩展处理器上观察到高达 25 倍的速度提升(图 6)。
我们使用新的 Massive Multitask Language Understanding (MMLU) 基准测试来衡量模型在预训练期间获得的知识,该基准在零样本和少样本设置下专门评估模型。从表 1 中可以看出,我们的聊天机器人在平均和大多数领域子任务上都表现出更好的结果。我们的 MMLU 结果与 GPT-3* (175B) 相当,但参数量却小 25 倍。我们鼓励您也尝试使用其他开源语言模型构建此系统,并利用 Intel® 硬件加速和软件优化。

除了 MMLU 基准测试外,我们还进行了定性对话评估,例如:
- 输入提示:在哪里可以找到 Intel 微芯片的产品信息?
- Alpaca 的响应:您可以在 Intel 官网上找到 Intel 微芯片的产品信息,Intel.com。在那里,您将找到有关其处理器、显卡、主板和其他产品的信息。您还可以找到产品规格、教程和其他资源。
- 我们的聊天机器人的响应:您可以在 Intel 官网上找到 Intel 微芯片的产品信息,https://www.intel.com/content/www/us/en/support/processors/top-questions.html。
总结
我们在 Intel Extension for Transformers 中发布了 源代码 和特定领域的数据集。我们鼓励您在 Intel® CPU 上创建自己的聊天机器人,并探索 Intel® AI 工具 和优化,作为您 AI 工作流程的一部分。
我们的下一步是启用量化和压缩技术,以加速 Intel 平台上的聊天机器人推理。如果您想接收我们最新优化的通知,请给 Intel Extension for Transformers 加星,如果您有任何问题,请随时与我们联系。