
在 C# 中实现简单的垃圾回收器
5.00/5 (6投票s)
如何在 C# 中实现一个简单的垃圾回收器?
引言
垃圾回收是计算机编程和内存管理中的一个过程,在这个过程中,系统会自动识别并释放程序不再使用的内存。垃圾回收的主要目的是回收程序不再可达或引用的对象或数据结构所占用的内存,从而防止内存泄漏并提高内存利用效率。
我们将深入探讨这一范式的核心原理和优势,并简单地(在 C# 中)实现我们所讨论的理论概念,从而深入了解每个概念的局限性。最终,我们的目标是全面理解现代编程语言中的垃圾回收机制。
关于此主题的权威教材是《垃圾回收手册》,该书于 2023 年出版。这本书汇集了过去六十年来研究人员和开发人员在自动内存管理领域积累的丰富知识。
本文最初发布于:在 C# 中实现一个简单的垃圾回收器
垃圾回收究竟是什么?
正如引言中所说,垃圾回收是计算机编程和内存管理中的一个过程,在这个过程中,系统会自动识别并释放程序不再使用的内存。
垃圾回收的关键概念
-
垃圾回收自动化了内存释放的过程,消除了程序员手动管理内存的需要。这有助于防止常见的内存泄漏和悬空指针(见下文)等问题。
-
如果对象被程序直接或间接引用,则认为对象是可达的。垃圾回收器识别并标记那些不再可达的对象,使其可供删除。
-
垃圾回收器识别并释放未被引用的对象所占用的内存,将其返回到可用内存池供将来使用。
-
垃圾回收可以由各种事件触发,例如当系统内存不足时,或者当分配的内存达到特定阈值时。
垃圾回收被几乎所有现代编程语言普遍采用。
- Java 利用 JVM 的垃圾回收器,其中包含各种算法,例如分代垃圾回收器 (G1 GC)。
- .NET (C#) 实现了一个采用分代方法的垃圾回收器。
垃圾回收通过自动化内存管理和减少内存相关错误的发生几率,来提高程序的整体健壮性和可靠性。
手动(显式)内存管理有什么问题?
手动内存管理本身并没有问题,并且仍在某些重要的编程语言(如 C++)中使用。然而,许多人都遇到过归因于内存泄漏的关键错误。这就是为什么在计算机科学的早期(第一种技术可追溯到 20 世纪 50 年代),人们就开始研究自动管理内存的方法。
手动内存管理确实带来了几个挑战和潜在问题。
-
未能正确释放内存可能导致**内存泄漏**。当程序分配内存但未能释放时,就会发生内存泄漏,导致可用内存随时间逐渐耗尽。
-
对指针处理不当可能导致**悬空指针**,这些指针指向已被释放的内存位置。访问此类指针可能导致未定义行为和应用程序崩溃。
-
内存的错误操作,例如写入超出分配内存范围,可能导致**内存损坏**。内存损坏可能导致意外行为、崩溃或安全漏洞。
-
手动内存管理增加了代码的复杂性,使程序更容易出错且更难维护。开发人员需要仔细跟踪和管理整个代码库中的内存分配和释放。
-
手动内存管理可能导致内存碎片,即空闲内存分散在小的、不连续的块中。这种碎片化可能导致内存利用效率低下。
-
可能会发生分配和释放操作不匹配的情况,导致双重释放或内存泄漏等错误。这些错误很难识别和调试。
-
显式内存管理可能需要额外的代码来进行分配和释放,从而影响程序性能。在性能关键型应用程序中,内存分配和释放操作可能成为瓶颈。
-
手动内存管理缺乏自动内存管理系统所具备的安全功能。开发人员需要仔细处理与内存相关的操作,这使得程序更容易出错。
自动内存管理通过自动化内存分配和释放过程来解决这些问题,减轻了开发人员的负担,并最大限度地减少了内存相关错误的发生几率。
《垃圾回收手册》提供了对垃圾回收的好处和显式内存管理缺点的更全面概述。
什么是栈、堆以及更多?
在讨论垃圾回收时,经常会提到诸如栈和堆之类的术语,以至于人们可能会认为它们是操作系统内置的固有数据结构,因此必须毫无疑问地普遍采用。然而,实际上堆和栈只是实现细节。在本节中,我们的目的是阐明和澄清所有这些概念。
起初是文字
程序本质上是由计算机需要理解的指令组成的文本。编译器的责任是负责将这些高级指令翻译成可执行代码。
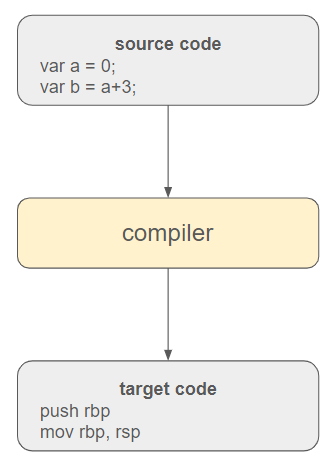
在现代编程语言中,通常会在源代码和操作系统之间插入一个虚拟执行引擎。此外,源代码最初会被翻译成一种中间语言,以提高可移植性并适应不同环境。

这个执行引擎包含垃圾回收器和其他技术(如类型检查、异常管理等)来管理程序。最终翻译成目标代码是由即时 (JIT) 编译器执行的。
专注于垃圾回收器
当然,垃圾回收器是执行引擎中最关键的组件之一。在这种情况下,我们将重点描述内存是如何组织的,以便进行有效的管理。
只有当程序产生结果时,它才有价值,并且不可避免地需要声明变量并分配内存来存储信息。
- 执行引擎可以提前预知所需的空间,例如处理整数等简单类型。相反,某些数据类型(包括自定义类或字符串、对象数组等内置类型)不允许进行如此直接的推断。
- 编译器可能只能在运行时确定存储变量的具体位置并在此刻保留内存(动态分配)。如果编译器能够确定变量的生命周期,特别是当它是一个过程的局部变量时,就可以更容易地理解变量何时不再需要(即何时可以释放)。相反,数据可能会在函数或子程序调用之后持续存在,并长期存在。
变量生命周期与预先知道所需的空间之间的差异,需要区分两个内存区域。尽管这种区分并非强制性,但它已成为普遍接受和实现的。选择不采用这种抽象的编程语言可能会面临被淘汰的风险,但必须认识到其他方案也是可能的。此外,需要注意的是,这种观点仅在执行引擎的上下文中有效。从操作系统的角度来看,一切最终都归结为分配在某个地方的内存块。
结论
- 当执行引擎能够预测变量的生命周期并推断出所需的空间时,它会在内部称为**栈**的内存区域中分配。
- 在其他情况下,当生命周期无法确定或所需空间不确定时,执行引擎会将变量分配在称为**堆**的内存区域中。
免责声明:此描述仅提供了各种编程语言中栈和堆的简要概述,纯粹主义者可能会觉得过于简化。这绝不是官方定义,因为这些抽象可能存在各种实现和解释。关键要点是在执行引擎级别区分两个内存区域以促进高效的内存管理。

理论够了,代码走起!
应该设想一种场景,其中程序最初用源代码编写,然后编译成中间表示,即一系列指令。我们将假设 IL 编译器已生成此指令列表。下面提供了一个此类列表的示例。
thread1;CREATE_THREAD;
thread1;PUSH_ON_STACK;Jubilant
thread2;CREATE_THREAD;
thread1;PUSH_ON_STACK;Radiant
thread1;POP_FROM_STACK
...
每条指令包含三个部分。第一个指示受指令影响的线程,第二个描述要执行的操作,第三个(可选)提供一个值来补充操作。在提供的示例中,编译器首先被指示创建一个名为 `thread1` 的线程,然后将一个名为 `Jubilant` 的变量推送到该线程的栈上。第三条指令要求创建另一个名为 `thread2` 的线程,以此类推。第五条指令尝试弹出 `thread1` 的栈。
这个指令列表可以被看作是一种中间表示 (IR),如图《编译原理:技术与工具》中所述。
我们当前的任务是实现一个能够处理这些指令的执行引擎(运行时),特别关注内存的分配和释放。
实现运行时
事不宜迟,以下是我们在代码中实现运行时的方式。
public class Runtime
{
private List<Instruction> _instructions;
private Collectors.Interfaces.GarbageCollector _collector;
public Runtime(List<Instruction> instructions, string collectorStrategy)
{
_instructions = instructions;
_collector = GetCollector(collectorStrategy);
}
#region Public Methods
public void Run()
{
foreach (var instruction in _instructions)
{
_collector.ExecuteInstruction(instruction);
_collector.PrintMemory();
}
}
#endregion
}
执行引擎拥有要执行的指令列表和一个(如下所述的)垃圾回收器,用于在内存释放期间使用。它还包含一个由主线程调用的 `Run` 方法。
public class Program
{
static void Main(string[] args)
{
var instructions = new List<Instruction>();
var contents = File.ReadAllLines(AppContext.BaseDirectory + "/instructions.txt");
foreach (var line in contents)
{
var c = line.Split(';');
var intruction = new Instruction(c[0], c[1], c[2]);
instructions.Add(intruction);
}
var runtime = new Runtime(instructions, "MARK_AND_COMPACT");
runtime.Run();
}
}
`Runtime` 类还需要一种内存收集策略来应用。正如我们将要探讨的,内存收集有几种可能性,设计一个有效的垃圾回收器确实是一门精细的艺术。
定义垃圾回收器接口
`Runtime` 类需要一个 `GarbageCollection` 实例来运行。该实例实现了 `GarbageCollection` 抽象类,其方法如下所述。
public abstract class GarbageCollector
{
public abstract void ExecuteInstruction(Instruction instruction);
public abstract int Allocate(string field);
public abstract void Collect();
public abstract void PrintMemory();
}
本质上,这里呈现的 `GarbageCollector` 类充当一个协调器,用于执行指令列表和管理内存分配及收集。在实际实现中,这些抽象通常会分开,但为了简化起见,这里的目标是精简表示。
`PrintMemory` 方法仅仅是一个辅助函数,用于在调试时可视化堆的内容。
定义一个线程
线程是指进程内执行的最小单位。进程是独立运行的程序,拥有自己的内存空间,并且在一个进程内可以存在多个线程。每个线程与同一进程中的其他线程共享相同的资源,例如内存。
- 线程能够实现任务的并发执行,允许多个操作同时进行。它们独立运行,拥有自己的程序计数器、寄存器和栈,但它们共享相同的内存空间。同一进程内的线程可以相互通信和同步。
- 线程在现代软件开发中被广泛使用,以提高应用程序的性能、响应能力和资源利用率,应用范围从桌面软件到服务器应用程序和分布式系统。
public class RuntimeThread
{
private Collectors.Interfaces.GarbageCollector _collector;
private Stack<RuntimeStackItem> _stack;
private Dictionary<int, RuntimeStackItem> _roots;
private int _stackSize;
private int _index;
public string Name { get; set; }
public RuntimeThread(Collectors.Interfaces.GarbageCollector collector,
int stackSize, string name)
{
_collector = collector;
_stack = new Stack<RuntimeStackItem>(stackSize);
_roots = new Dictionary<int, RuntimeStackItem>();
_stackSize = stackSize;
_index = 0;
Name = name;
}
public Dictionary<int, RuntimeStackItem> Roots => _roots;
public void PushInstruction(string value)
{
_index++;
if (_index > _stackSize) throw new StackOverflowException();
var address = _collector.Allocate(value);
var stackItem = new RuntimeStackItem(address);
_stack.Push(stackItem);
_roots.Add(address, stackItem);
}
public void PopInstruction()
{
_index--;
var item = _stack.Pop();
_roots.Remove(item.StartIndexInTheHeap);
}
}
线程的特点是有一个名称,并执行自己的指令列表。关键点在于线程共享相同的内存。这意味着在一个程序中,可能存在多个线程,因此存在多个栈,但通常存在一个堆供所有线程共享。
在提供的示例中,当线程执行指令时,它会被放在其栈上,并且任何对堆的潜在引用都会保留在内部字典中。这种机制确保每个线程维护自己的栈,同时跟踪对共享堆的引用,以有效地管理内存分配和释放。
定义栈和堆
如前所述,栈和堆是实现细节,因此它们的代码被推迟到 `GarbageCollector` 的具体类中。尽管如此,提供它们的简要描述仍然是有益的,因为正如我们所观察到的,这些概念被普遍采用。
实现栈
在 C# 中,已经存在栈的数据结构。为了简单起见,我们将使用它,特别是它非常适合我们的需求。
我们将 `RuntimeStackItem` 类的实例推送到此栈上。`RuntimeStackItem` 仅包含对堆中地址的引用。
public class RuntimeStackItem
{
public int StartIndexInTheHeap { get; set; }
public RuntimeStackItem(int startIndexInTheHeap)
{
StartIndexInTheHeap = startIndexInTheHeap;
}
}
实现堆
堆必须代表一个内存区域,我们将简单地使用 `char` 类来模拟每个内存单元。通过这种抽象,堆只不过是一个可以分配的单元列表。它还包括额外的“管道”代码,例如指针,用于管理哪些单元已被占用或可以回收。
public class RuntimeHeap
{
public RuntimeHeap(int size)
{
Size = size;
Cells = new RuntimeHeapCell[size];
Pointers = new List<RuntimeHeapPointer>();
for (var i = 0; i < size; i++)
{
Cells[i] = new RuntimeHeapCell();
}
}
#region Properties
public int Size { get; set; }
public RuntimeHeapCell[] Cells { get; set; }
public List<RuntimeHeapPointer> Pointers { get; set; }
#endregion
}
我们的任务现在是定义 `GarbageCollection` 的具体类,以观察垃圾回收器在运行。
实现标记-清除算法
对于此策略和后续策略,我们将分配一个 64 个字符的堆,并且**我们认为不可能从操作系统请求额外的空间**。在实际场景中,垃圾回收器通常能够请求新内存,但为了说明起见,我们施加了此限制。重要的是要注意,此限制既不会阻碍也不会损害整体理解。
实现 `ExecuteInstruction` 方法
对于所有策略,此方法几乎相同。它一次处理一条指令,在栈上推送或弹出变量。
public override void ExecuteInstruction(Instruction instruction)
{
if (instruction.Operation == "CREATE_THREAD")
{
AddThread(instruction.Name);
return;
}
var thread = _threads.FirstOrDefault(x => x.Name == instruction.Name);
if (thread == null) return;
if (instruction.Operation == "PUSH_ON_STACK")
{
thread.PushInstruction(instruction.Value);
}
if (instruction.Operation == "POP_FROM_STACK")
{
thread.PopInstruction();
}
}
实现 `Allocate` 方法
如果内存不足,垃圾回收器会尝试回收内存,然后重试分配过程。如果仍然没有足够的空间,则会引发异常。
public override int Allocate(string field)
{
var r = AllocateHeap(field);
if (r == -1)
{
Collect();
r = AllocateHeap(field);
}
if (r == -1) throw new InsufficientMemoryException();
return r;
}
private int AllocateHeap(string field)
{
var size = _heap.Size;
var cells = field.ToArray();
var requiredSize = cells.Length;
// We need to find a contiguous space of requiredSize char.
var begin = 0;
while (begin < size)
{
var c = _heap.Cells[begin];
if (c.Cell != '\0')
{
begin++;
continue;
}
// Do not continue if there is not enough space.
if ((size - begin) < requiredSize) return -1;
// c = 0 => This cell is free.
var subCells = _heap.Cells.Skip(begin).Take(requiredSize).ToArray();
if (subCells.All(x => x.Cell == '\0'))
{
for (var i = begin; i < begin + requiredSize; i++)
{
_heap.Cells[i].Cell = cells[i - begin];
}
var pointer = new RuntimeHeapPointer(begin, requiredSize);
_heap.Pointers.Add(pointer);
return begin;
}
begin++;
}
return -1;
}
重要提示:分配过程始终寻找连续的可用空间(源代码第 23 行)。例如,如果它必须分配 8 个单元,它必须找到 8 个连续的可用单元。此观察结果将在后续部分(见下文)中发挥关键作用。
标记-清除算法是什么?
标记-清除算法包含两个主要阶段:标记和清除。
- 在标记阶段,算法从根(通常是全局变量或程序直接引用的对象)开始遍历堆中的所有对象。它通过设置一个特定的标志或属性,将每个访问过的对象标记为“可达”或“活动”。在此遍历期间未标记的对象被认为是不可达的,并且可能是释放的候选。

- 在清除阶段,算法扫描整个堆,识别并释放未标记(不可达)对象所占用的内存。已标记(可达)对象所占用的内存将被保留。清除后,堆再次被视为一个连续的可用内存块,可供新分配使用。

标记-清除算法以其简单性和识别及回收不再使用内存的有效性而闻名。然而,正如我们接下来将看到的,它也有一些缺点。
总而言之,一个对象被认为是无效的(因此可回收的),直到它通过从程序中的某处可达来证明其有效性。.
public override void Collect()
{
MarkFromRoots();
Sweep();
}
实现标记阶段
标记-清除算法必须从根开始遍历。这些根是什么?通常,它们包括全局变量或每个栈帧中包含的引用。在我们简化的示例中,我们将根定义为仅包含栈中引用的对象。
private void MarkFromRoots()
{
var pointers = _heap.Pointers;
foreach (var root in _threads.SelectMany(x => x.Roots))
{
var startIndexInTheHeap = root.Value.StartIndexInTheHeap;
var pointer = pointers.FirstOrDefault(x => x.StartCellIndex == startIndexInTheHeap);
if (pointer == null) return;
pointer.SetMarked(true);
}
}
在此过程结束时,活动对象已被标记,而无效对象则未被标记。
实现清除阶段
清除阶段扫描整个堆,并从未标记的对象中回收内存。
private void Sweep()
{
var cells = _heap.Cells;
var pointers = _heap.Pointers;
foreach (var pointer in pointers.Where(x => !x.IsMarked))
{
var address = pointer.StartCellIndex;
for (var i = address; i < address + pointer.AllocationSize; i++)
{
cells[i].Cell = '\0';
}
}
var list = new List<RuntimeHeapPointer>();
foreach (var pointer in pointers.Where(x => x.IsMarked))
{
pointer.SetMarked(false);
list.Add(pointer);
}
pointers = list;
}
在此过程中,我们不会忘记重新初始化标记指针并将其设置为未标记,以确保下一次收集能够干净地重新开始。
运行程序
我们将使用两个指令列表来执行程序。第一个与上一篇文章中的相同。第二个将突出显示此算法特有的现象,即碎片化。
使用与以前相同的指令集,我们观察到程序运行到最后,没有引发异常。“Cascade”一词得到了正确分配,因为垃圾回收器成功回收了足够的内存。

此算法确保在需要时正确回收内存。但是,在下面的示例中,当我们稍微修改指令并尝试为长单词(16 个字母)分配内存时,我们将遇到一个不良效果。
...
thread1;PUSH_ON_STACK;Enigmatic
thread2;POP_FROM_STACK;
thread1;PUSH_ON_STACK;Cascade
thread2;POP_FROM_STACK;
thread2;PUSH_ON_STACK;GarbageCollector <= 16-letter words
奇怪的是,即使堆中似乎有足够的可用内存,仍然会引发异常。


堆中有 19 个可用单元,我们正在尝试分配 16 个单元,那么为什么垃圾回收器无法完成任务呢?
实际上,垃圾回收器试图找到 16 个连续的可用单元,但似乎堆中没有。尽管它有超过 16 个可用单元,但它们不是连续的,导致分配不可能。这种现象称为碎片化,并且有一些不良影响。
更一般地说,堆碎片是指堆中的可用内存分散在不连续的块中,使得即使总的可用空间足够,也难以分配一个大的、连续的内存块。虽然可用内存总量可能很大,但这些块的分散性质阻碍了大型连续内存部分的分配。
在标记-清除算法的上下文中,由于堆中可用内存单元的散布排列,某些分配对连续内存块的需求可能会受到阻碍。因此,即使总可用空间足够,也可能因无法找到足够大的连续段而导致分配失败。
因此,解决堆碎片对于优化内存使用和提高垃圾回收器的性能至关重要。.
您可以在此处找到本文的续篇。
历史
- 2023 年 11 月 18 日:初始版本