
生成式 AI 游乐场:在最新的 Intel® GPU 上使用 RunwayML 和 Stability AI 进行图像到图像的 Stable Diffusion
5.00/5 (1投票)
本文探讨了 Stable Diffusion 模型的使用,重点关注图像到图像的生成,并使用了英特尔新发布的英特尔数据中心 GPU Max 系列 1100。
本文最初发表于 Medium*。

2023 年 10 月 15 日 — Stable Diffusion* 模型已成为创作者、艺术家和设计师快速制作视觉创意原型的绝佳方式,无需寻求外部帮助。如果您曾使用过 Stable Diffusion 模型,可能对通过文本提示生成图像的方式比较熟悉。还有一些模型允许同时使用文本提示和图像作为起点来生成新图像。在本文中,我将展示如何在英特尔刚刚发布的 英特尔® 数据中心 GPU Max 系列 1100 上运行图像到图像的 Stable Diffusion 模型的预测。
我运行了两种不同的、托管在 Hugging Face* 上的 Stable Diffusion 模型进行图像到图像的生成。虽然这两种模型主要用于文本到图像的生成,但它们同样也适用于图像到图像的生成:
Stability AI 的 Stable Diffusion v2–1 模型
Stability AI 的 Stable Diffusion v2–1 模型是在一个由 32 x 8 x A100 GPU 组成的强大集群(总计 256 张 GPU 卡)上训练的。它是在一个 Stable Diffusion v2 模型的基础上进行微调的。原始数据集是 LAION-5B 数据集的一个子集,由 Stability AI 的 DeepFloyd 团队创建。截至本文撰写时,LAION-5B 数据集是最大的文本-图像对数据集,包含超过 58.5 亿个文本-图像对。图 2 展示了该数据集中的一些样本。
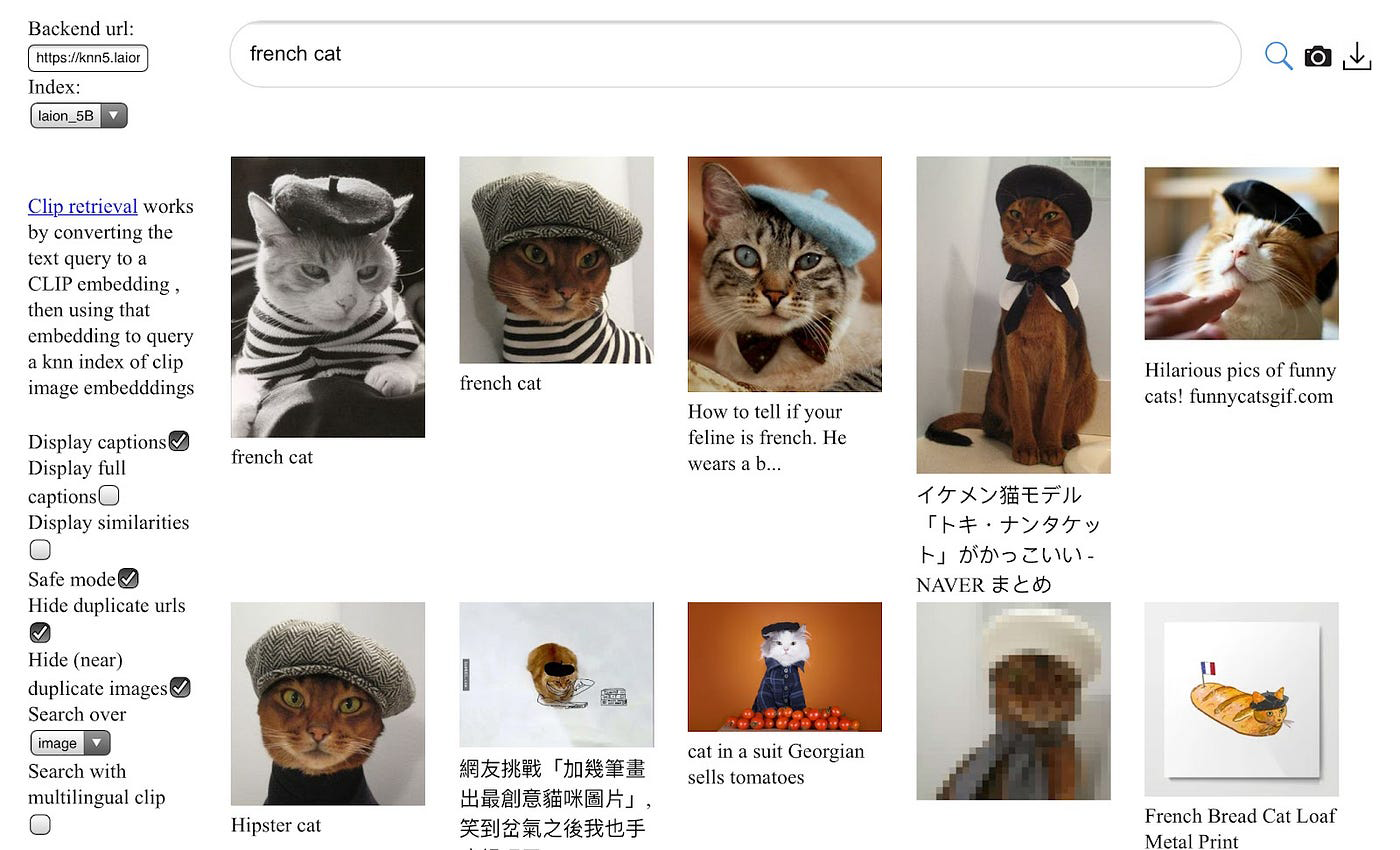
所展示的样本图像表明,原始图像的像素尺寸各不相同;然而,在实际训练这些模型时,通常会通过填充或调整图像大小的方式,使模型架构的输入图像具有一致的像素尺寸。
该数据集的细分如下:
- Laion2B-en: 23.2 亿个英文文本-图像对
- Laion2B-multi: 22.6 亿个来自 100 多种其他语言的文本-图像对
- Laion1B-nolang: 12.7 亿个语言无法检测的文本-图像对
追溯这些模型的训练路径有些复杂,但完整的故事是这样的:
- Stable Diffusion 2-Base 从头开始在 256 x 256 像素的图像上进行了 55 万步的训练,并过滤掉了色情内容,然后又在 512 x 512 像素的图像上进行了 85 万步的训练。
- Stable Diffusion v2 接续 Stable Diffusion 2-Base 的训练,在 512 x 512 像素的图像上又进行了 15 万步的训练,之后又在 768x768 像素的图像上进行了 14 万步的训练。
- Stability AI Stable Diffusion v2–1 在 Stable Diffusion v2 的基础上进一步微调,先是使用一种显式内容过滤器进行了 5.5 万步的训练,然后使用另一种过滤器进行了 15.5 万步的训练。
关于训练的更多细节可以在 Stability AI Stable Diffusion v2–1 Hugging Face 模型卡上找到。我想提一下,我重复了之前一篇关于文本到图像 Stable Diffusion 的文章中的描述,因为它们是同一个模型。
Runway ML 的 Stable Diffusion v1–5 模型
Runway ML 的模型实际上是在前面描述的 Stability AI v2–1 模型上进行微调的。它在 512 x 512 的分辨率下额外训练了 59.5 万步。其优点之一是相对轻量级:“该模型拥有 8.6 亿参数的 UNet 和 1.23 亿参数的文本编码器,相对轻量,可在至少拥有 10 GB 显存的 GPU 上运行。”(GitHub 来源)。英特尔数据中心 GPU Max 系列 1100 拥有 48 GB 的显存,因此对于这个模型来说绰绰有余。
英特尔 GPU 硬件
正如我刚才提到的,我用于推理测试的具体 GPU 是英特尔数据中心 GPU Max 1100,它拥有 48 GB 内存,56 个 Xe 核心,以及 300W 的热设计功耗。在命令行中,我可以先运行以下命令来验证我确实拥有预期的 GPU:
clinfo -l
我收到的输出显示,当前节点上有四个 Intel GPU 可供我使用。
Platform #0: Intel(R) OpenCL Graphics
+-- Device #0: Intel(R) Data Center GPU Max 1100
+-- Device #1: Intel(R) Data Center GPU Max 1100
+-- Device #2: Intel(R) Data Center GPU Max 1100
`-- Device #3: Intel(R) Data Center GPU Max 1100
与 nvidia-smi 函数类似,您可以在命令行中运行 xpu-smi,并选择一些选项来获取您想要的 GPU 使用统计信息。
xpu-smi dump -d 0 -m 0,5,18
结果是每秒打印一次设备 0 的重要 GPU 使用情况。
getpwuid error: Success
Timestamp, DeviceId, GPU Utilization (%), GPU Memory Utilization (%), GPU Memory Used (MiB)
13:34:51.000, 0, 0.02, 0.05, 28.75
13:34:52.000, 0, 0.00, 0.05, 28.75
13:34:53.000, 0, 0.00, 0.05, 28.75
13:34:54.000, 0, 0.00, 0.05, 28.75
运行 Stable Diffusion 图像到图像示例
我的同事 Rahul Nair 编写了 Stable Diffusion 图像到图像的 Jupyter* Notebook,该 Notebook 直接托管在英特尔® 开发者云上。它提供了使用我前面提到的任一模型的选项。以下是您可以开始的步骤:
- 访问 Intel Developer Cloud。
- 注册为标准用户。
- 登录后,进入培训与研讨会部分。
- 选择GenAI 启动 Jupyter Notebook。您可以在那里找到并运行文本到图像的 Stable Diffusion 图像到图像 Jupyter Notebook。
在 Jupyter Notebook 中,为了加速推理,使用了英特尔® PyTorch* 扩展。其中一个关键函数是 _optimize_pipeline,该函数调用 ipex.optimize 来优化 DiffusionPipeline 对象。
def _optimize_pipeline(
self, pipeline: StableDiffusionImg2ImgPipeline
) -> StableDiffusionImg2ImgPipeline:
"""
Optimize the pipeline of the model.
Args:
pipeline (StableDiffusionImg2ImgPipeline): The pipeline to optimize.
Returns:
StableDiffusionImg2ImgPipeline: The optimized pipeline.
"""
for attr in dir(pipeline):
if isinstance(getattr(pipeline, attr), nn.Module):
setattr(
pipeline,
attr,
ipex.optimize(
getattr(pipeline, attr).eval(),
dtype=pipeline.text_encoder.dtype,
inplace=True,
),
)
return pipeline
图 3 展示了 Jupyter Notebook 内部用于图像到图像生成的便捷迷你用户界面。选择一个模型,输入所需的图像 URL,输入一个提示,选择要生成的图像数量,然后您就可以开始创作自己的图像了。

图 1 和图 4 展示了我使用这款英特尔 GPU 运行文本 + 图像提示所生成的全新图像样本。我觉得很有趣的是,从一张真实的地球自然瀑布照片开始,告诉它生成一个火星瀑布,然后看到它适应成了红色的景观(图 1)。然后在图 4 中,模型将一张木星的图像转变为具有一些地球大陆结构但仍然是红色的图像,同时保留了一些木星的显著特征。

我通过运行 Jupyter Notebook 生成了这些图像,推理过程在几秒钟内就能完成。欢迎通过以下链接与我联系,在社交媒体上分享您的图像。如果您有任何问题或在开始尝试 Stable Diffusion 方面需要帮助,也请随时告诉我。
您可以联系我:
- DevHub Discord* 服务器(用户名 bconsolv)
- LinkedIn*
- X(原 Twitter*)