
PsCal - 创建个性化 PDF 日历
5.00/5 (2投票s)
本文介绍了一组批处理、AWK 和 PostScript 文件,它们共同允许您为特定年份创建个性化的 12 页 PDF 日历。
引言
本文简要介绍了如何以多页 PDF 文件的形式创建各种年份的日历。一个可选的简单文本文件允许您个性化您创建的任何日历。这些日历是由我称为 PsCal 的一组文件创建的。PsCal 使用两种已经存在了几十年的编程语言来生成日历:AWK 和 PostScript。您可以在这里查看本文的原始版本。在那篇文章中,我简要讨论了 AWK 和 PostScript 语言,以及 PsCal 开发的历史。
在此更新中,在关于如何使用 PsCal 生成日历和 PsCal 文档的两个简短章节之后,我将讨论过去一年中我所做的一些更改,重点关注本地化 (L10n,这是一种很酷的 c9e 方法),以及介绍一些新的 PsCal 功能。
其中一些讨论特定于 PostScript,而且坦白说,对大多数人(如果不是全部的话)几乎没有实际用途。然而,我认为它在设计和规范方面是一个有趣的练习,如果仅此而已的话。
再往下,您可以阅读一些关于 UTF-16 和 UTF-8 文件的情况。与特定于 PostScript 的讨论不同,这些信息可能对任何处理 Unicode 格式文件的人(编写读取输入文件的任何程序员?)普遍有用。
下面是 PsCal 日历中一个月的示例。正如这个例子所示,我最近添加的新功能之一是支持除英语以外的几种语言。
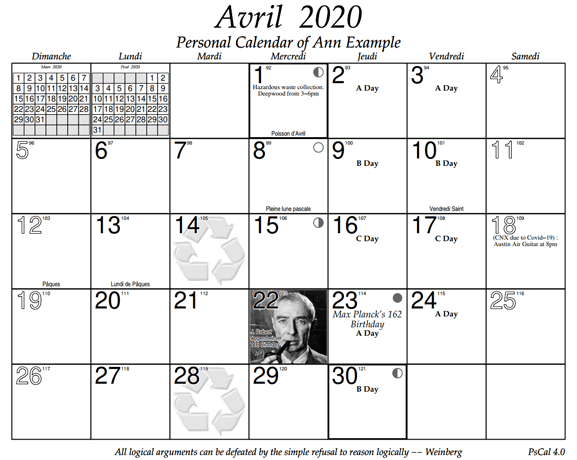
创建日历
要为当前年份创建日历,您只需执行 MakeCalendar 批处理文件,而不带任何参数。默认情况下,它将创建一个名为 <current year>.pdf 的文件的 12 个月日历。
此外,默认情况下,如果当前目录中存在名为 events.pse 的文件,则该文件中的事件将显示在日历上。只要该文件存在于当前目录中,它就会被使用,除非您在命令行中指定了另一个文件名。MakeCalendar.bat 的用法是:
MakeCalendar [OPTIONS]
OPTIONS can be one or more of:
-y=<Year> The year for which the calendar is to be generated. DEFAULT:
the current year.
-m=<MonthList> A list of months to be included in the calendar. DEFAULT:
1-12. Months are numbered from 1 (Jan) through 12 (Dec).
Specify a range of months by placing a dash (-) between two
months. Use a comma (,) to separate individual months and
ranges of months.
-e=<EventsFile> The name of a file containing events specific to you, such as
birthdays, anniversaries, paydays, etc. DEFAULT: a file named
"events.pse" in the current directory, if it exists. This
file can also contain data that can modify the appearance of
the calendar, such as headers and footers, fonts, and various
graphics effects.
-n=<BaseName> The base name of two output files that are created. One is
a PostScript file (which is deleted by default), and one is a
PDF file. Each of them will contain the calendar for the year
in (obviously) different formats. DEFAULT: the current (or
given) year, producing <year>.ps and <year>.pdf.
-edit Edit an events file to reflect PsCal 4.0 improvements to bitmap
and background image handling.
PsCal 文档
我在 PsCal 的顶级目录中包含了一个 readme 文件 (_readme.txt)。如果您想尝试使用 PsCal,这显然是一个很好的起点。在顶级目录中有一个名为 doc 的子目录。在那里您会找到三个 PDF 文件。
EventFileFormat.pdf Detailed information on PsCal's event file.
awkinfo.pdf A substantial overview of AWK.
psinfo.ps A terse overview of PostScript.
AWK 和 PostScript 文件可能有助于您更好地理解本文的后半部分,以及 PsCal 如何完成其任务,但这些文件绝非必读。
但是,如果您决定尝试制作自己的日历,则至少应浏览一下事件文件文档。它非常详细,展示了您可以在事件文件中做的所有事情,以使您的日历反映您独特的风格。
支持英语以外的语言
上面的法语句子日历图片得益于 codeProject 会员 FrogCoder5 关于 PsCal 非英语能力的提问。我不得不承认,我完全不了解如何在日历上显示非 ASCII 字符。
题外话:我将几乎所有与语言支持相关的 AWK 代码都放在了一个单独的文件中:gawk\LanguageParts.awk。如果您想改进任何受支持的语言(英语、法语、德语、意大利语、西班牙语和瑞典语),或者想添加当前不支持的语言,您应该阅读该文件开头的注释块。它包含有关语言支持以及控制日历上显示的节假日的宝贵信息——无论好坏,节假日都与语言选择相关。
蹒跚学步
在开始支持英语以外的语言的道路上,我最先需要的是一种方法来尝试一些非英语字符。有一次,我在玩维基百科或谷歌翻译,然后复制了一些包含 U-umlaut 字符 (Ü) 的文本。我记得当我将其粘贴到某个文件中时,它在 Notepad++ 中显示得很好。
现在我有了在用户事件文件中复制各种非 ASCII 字符的方法。我接下来要问的问题是,我可以用给定的 PostScript 字体实际显示哪些非 ASCII 字符?我很快了解到,PostScript 文本渲染功能允许您一次选择 256 种可能的字符图像中的一种。这些图像通常被称为字形。
PostScript 字体编码向量
在输出设备(显示器或实际纸张!)上渲染字形的关键部分是一个称为编码向量的实体。每个 PostScript 字体都有一个这样的编码向量,它只是一个包含 256 个名称的数组——这些名称是绘制 256 种可能字符图像(我在此后称为字形)的 PostScript 过程的名称。
通过修改字体编码向量中包含的全部或部分过程名称来更改渲染的字形。而且,幸运的是,大多数字体包含的字形绘制过程对应于默认未映射到 256 个编码向量条目之一的字符。
PostScript 的默认编码
像 (Abc) 这样的 PostScript 字符串被 show 操作符(负责在输出设备上渲染字符串)视为一系列数字。默认情况下,字符串 (Abc) 被解释为 0x41、0x62、0x63。然后,这三个数字用作字体编码向量的索引——它们选择当前所选字体定义的三个 PostScript 过程。这些过程用于在输出设备上渲染三个字形。
您可能认出上面的十六进制数字是“A”、“b”和“c”的 ASCII 码。PostScript 使用默认编码向量,其前 128 个条目与 ASCII 相同。然而,高 128 个条目中的许多位置是未定义的。幸运的是,PostScript 的创建者很容易更改为 256 个可能的过程名称中的任何一个绘制的字形,因此不必浪费那些高 128 个条目。
ISO Latin 1 编码 (ISO/IEC_8859-1)
事实证明,PostScript 定义了一个编码向量,该向量将 ISO Latin 1 字符集映射到 256 个字符位置。毫不奇怪,该向量的名称是 /ISOLatin1Encoding。该向量的前 128 个条目与默认字符集相同:大写和小写的 ASCII 字符、数字以及一些标点符号和控制字符。
幸运的是,它与字符位置 128 (0x80) 到 255 (0xFF) 关联的字形与 PostScript 的默认编码向量有显著不同。此链接显示了它映射的字符以及它们的位置(256 个可能的位置之一)。
如果您查看该链接,您会看到许多用于西欧语言的字符。因此,可以通过使用 /ISOLatin1Encoding 向量重新编码字体来使这些字符可用于 PostScript 程序。对我来说幸运的是,《PostScript Blue Book》中包含了重新编码整个字体和重新编码字体字形子集的示例过程。
重新编码 PsCal 字体
在 PsCal 的 PostScript 代码中,我必须添加一个函数来重新编码日历引用的每个字体以使用 ISO Latin 1 编码向量。对我来说,这个过程中最困难的部分是处理字体名称。
现有的 PsCal 代码只是按名称使用选定的字体。例如,/Palatino-Roman。我无法弄清楚如何获取这样的名称并以任何方式修改它。我最终不得不更改 pscal.awk 以生成字体定义字符串而不是名称,如下所示:
(Palatino-Roman) Win1252Recode findfont _FS 3 get scalefont
上面的行重新编码了 Palatino-Roman 字体并将其缩放到所需大小。Win1252Recode 过程在 (Palatino-Roman) 字符串前添加下划线,并将其转换为新创建的字体使用的名称,然后重新编码新字体。所以 /_Palatino-Roman 是一个新创建的字体,它使用 Palatino Roman 字体面,并且可以绘制默认情况下无法访问的各种字形。
Windows-1252 编码
您可能会对 Win1252Recode 这个名字感到惊讶。从到目前为止的讨论来看,我认为您可能会期望看到类似这样的内容:
(Palatino-Roman) IsoLatin1Recode findfont _FS 3 get scalefont
如果您确实预料到了这一点,那么恭喜您;您显然非常关注!
事实证明,很久很久以前,微软定义了自己的字符映射,称为 Windows-1252。而且,至少在我的情况来看,Windows 默认使用此映射。您可以在这里看到此方案使用的字符映射。
Windows-1252 编码与 ISO/IEC_8859-1 在 0x80 到 0x9F 之间的字符位置上有所不同——ISO Latin 1 在该范围内未定义任何字符。因此,Windows-1252 编码在该范围内添加了 27 个字符,例如“Euro”、“florin”、“Scaron”和“scaron”。
Windows-1252 编码方案是 PsCal 使用的方案。用于生成日历的任何字体都将被重新编码以反映此字符位置到字形绘制过程的映射。因此,日历可以包含此编码方案的任何字符。
进行到 Windows-1252 编码的更改
为了完成 Windows-1252 编码工作,我必须解决一个小问题。如果您查看 Windows-1252 代码页布局,您会看到 0x80 至 0x9F 之间的字符显示了它们的 Unicode 代码点值。但是,为了在某些 PostScript 字体编码向量中重新编码这些字符,我需要字体过程的名称,这些过程可以渲染这些字符。幸运的是,我能够在此找到必要的信息。
在该网页上,您可以搜索代码点值,以查找 Adobe 分配的字形绘制过程名称。有了这些信息,我就能够创建一个名为 /WinModificationsArray 的数组,您可以在 PsCal 的 PostScript 目录中的 PsStart.txt 文件中找到它的定义。它看起来像:
% Define an encoding array of changes Win1252 encoding makes to the ISO encoding.
/WinModificationsArray [
% ===== ================= ============ ========== =========
% Index Name Octal escape code point Character
% ===== ================= ============ ========== =========
16#80 /Euro % \200 U+20AC €
16#82 /quotesinglbase % \202 U+201A ‚
16#83 /florin % \203 U+0192 ƒ
...
16#9E /zcaron % \236 U+017E ž
16#9F /Ydieresis % \237 U+0178 Ÿ
] def
上面的数组包含成对的条目。一对中的第一个是编码数组的十六进制索引,第二个是渲染输出设备上字形的 PostScript 过程的名称。每对右侧的注释显示了可以在 PostScript 字符串中用于选择字符的八进制转义符、字符的 Unicode 代码点以及 PostScript 过程将渲染的字形的表示。
字体重新编码过程包括制作一个 PostScript 内置的 /ISOLatin1Encoding 向量的副本,并将其命名为 /Win1252Encoding,然后将 /WinModificationsArray 所包含的更改应用于该向量。最后,每当声明一个字体以在日历中使用时,它都会使用此 /Win1252Encoding 向量进行重新编码。
因此,通过这种方式,PsCal 创建的 PostScript 日历可以渲染英语和许多西欧语言中使用的大多数(如果不是全部)字符。
支持 UTF-8 和 UTF-16 事件文件
为了支持 Windows-1252 编码,我不得不清理 PsCal 对 UTF-8 和 UTF-16 格式事件文件的处理。接下来,我将简要介绍我所做的一些更改,以及一些可能对 Unicode 文件有用的通用信息。
UTF-16 输入
我一直知道使用 GAWK 手动处理 UTF-16 文件是可能的,但这将是一项艰巨的工作。所以,多年前我写了一个名为 LibOpenPossibleUtf16File() 的库函数,它可以检测 UTF-16LE 和 UTF-16BE 文件,并创建一个新的临时文件——一个 ASCII 副本,使用该文件所有偶数或奇数字节(取决于其 LE 或 BE 状态)。文件中的其他(通常为 0x00)字节被简单地忽略。如果给定的文件不是 UTF-16 编码的,那么它将简单地打开给定的文件。无论哪种情况,它都会返回它打开的文件的名称(原始文件或副本)。
我不知道的关于 UTF-16 文件的一个重要事实是,它们由 2 字节的 Unicode 代码点组成。也就是说,UTF-16 文件中的“A”表示为 0x0041,这是该字符的 Unicode 代码点。因此,通过丢弃高位的零字节,您就得到了“A”的 ASCII 码。
现在,如果 PsCal 只支持 ISO Latin 1 字符,那么 LibOpenPossibleUtf16File() 函数的原始版本将按原样工作。这是因为 ISO Latin 1 编码中所有字符的 Unicode 代码点都在 0xFF 或以下——所有 ISO Latin 1 字符的代码点的高字节都是 0x00。因此,忽略高位 0x00 字节不会造成任何损害。
然而,Windows-1252 编码添加的字符的代码点是 0x0100 或更高,所以在 UTF-16 文件中,它们的上字节是非零的。例如,zcaron 字符 ž 的 Unicode 代码点是 0x017E。这意味着我必须开始注意 UTF-16 文件中的高字节(当它们非零时),看看它们是否是 Windows-1252 编码所包含的字符代码点的第一个字节。
当我遇到这些字符时,我所做的更改是将字符在 Windows-1252 编码方案中的索引发出到文件副本中。例如,对于 zcaron 字符,它会将 0x9E 放入输出文件“副本”中。代码点大于 0xFF 但不在 Windows-1252 中的任何字符都将被替换为空格字符。
UTF-8 输入
我知道 GAWK 支持 UTF-8 文件,但我不知道其支持的范围。我认为 GAWK 的支持非常简单——据我所知,它只是将 UTF-8 文件中的每个字节视为一个单独的字符。
我也不知道 UTF-8 文件,就像 UTF-16 文件一样,由 Unicode 代码点组成,而不是 ASCII 字符。而且,与 UTF-16 文件不同,代码点的编码长度可以是 1、2、3 或 4 个字节。
在 UTF-8 文件中,“A”(代码点为 0x0041)由单个字节 0x41 表示。事实上,代码点 0-127 被定义为匹配 ASCII 字符集,并且它们在文件中都编码为单个字节。这就是为什么人们有时会混淆 ASCII 和 UTF-8 文件,认为它们在某种程度上是相同的,但它们绝对不是!
UTF-8 文件中任何最高位设置为 1 的字节都是某个字符的 Unicode 代码点的多字节编码的一部分。我需要对 UTF-8 文件做的事情与我对 UTF-16 文件所做的事情类似。最大的区别是将可变长度的多字节代码转换为正确的 Windows-1252 字符索引。
如果您有兴趣了解我是如何做到的,您可以在下面查看 AWK 函数 LibConvertUtf8ToWin1252()。此函数以 UTF-8 文本行为输入,并返回一个将任何编码的 Windows-1252 字符替换为其 Windows-1252 字符索引的行。文本中的任何未被编码到 Windows-1252 字符集中的编码字符都将被替换为空格字符。
################################################################################
## If there are any UTF-8 encoded Unicode code point characters embedded in the
## input text and they are part of the Win1252 encoding scheme (including the
## ISO Latin 1 characters), replace them in the text by their Win1252/ISO Latin
## 1 character index.
##
## INPUT:
## Text The UTF-8 encoded text to convert.
##
## RETURNS: Text with valid code points replaced by their character positions in
## the Win1252/ISO scheme. Invalid code points (i.e. those not included
## in the Win1252/ISO scheme) are replaced by a space.
################################################################################
function LibConvertUtf8ToWin1252(Text, # Parameter
NewText,n,TextChars,i,Utf8Code) # Local vars
{
NewText = "" # Text to be returned.
n = split(Text,TextChars,"") # Text --> array of n characters.
for (i = 1; i <= n; i++) { # For each character in the array...
Utf8Code = 0
while (LibOrd(TextChars[i]) >= 0x80) { # Over 0x7F is part of an encoding.
# Collect bytes of this UTF-8 encoded Unicode code point.
Utf8Code = (Utf8Code * 0x100) + LibOrd(TextChars[i++])
}
if (Utf8Code == 0) {
NewText = (NewText TextChars[i]) # Current character is ASCII.
}
else {
--i
if (Utf8Code in gConvLibUtf8ToWin1252) {
# Convert Windows-1252-specific characters.
NewText = (NewText gConvLibUtf8ToWin1252[Utf8Code])
}
else if (Utf8Code >= 0xC2A0 && Utf8Code <= 0xC2BF) {
# Convert characters in ISO Latin 1.
NewText = (NewText sprintf("%c",and(Utf8Code,0xFF)))
}
else if (Utf8Code >= 0xC380 && Utf8Code <= 0xC3BF) {
# Convert more characters in ISO Latin 1.
NewText = (NewText sprintf("%c",0x40 + and(Utf8Code,0xFF)))
}
else if (Utf8Code <= 0xFF) {
# This is a character that has already been converted into its
# proper Win1252 character index.
NewText = (NewText sprintf("%c",Utf8Code))
}
else {
# The encoded character is NOT in the Win1252 layout.
NewText = (NewText " ")
}
}
}
return NewText
}
上面代码中一个可能不太清楚的 AWK 特定部分是:
if (Utf8Code in gConvLibUtf8ToWin1252) {
# Convert Unicode code points existing in Windows-1252.
NewText = (NewText gConvLibUtf8ToWin1252[Code])
}
该代码测试 Utf8Code 是否是数组 gConvLibUtf8ToWin1252 的索引,如果是,则将该数组条目的值附加到文本中。数组定义如下:
# The indexes below are the UTF-8 encodings converted to a decimal number.
# For example, 14844588 === 0xE282AC.
gConvLibUtf8ToWin1252[14844588] = sprintf("%c", 0x80) # U+20AC E2 82 AC €
gConvLibUtf8ToWin1252[14844058] = sprintf("%c", 0x82) # U+201A E2 80 9A ‚
gConvLibUtf8ToWin1252[50834] = sprintf("%c", 0x83) # U+0192 C6 92 ƒ
...
gConvLibUtf8ToWin1252[50579] = sprintf("%c", 0x9C) # U+0153 C5 93 œ
gConvLibUtf8ToWin1252[50622] = sprintf("%c", 0x9E) # U+017E C5 BE ž
gConvLibUtf8ToWin1252[50616] = sprintf("%c", 0x9F) # U+0178 C5 B8 Ÿ
传递给 sprintf() 函数的值是 Windows-1252 编码方案中字符的索引。每条目右侧的注释显示了字符的 Unicode 代码点、其 UTF-8 编码以及实际字符。
请注意,AWK 可以轻松处理稀疏数组,如 gConvLibUtf8ToWin1252。在 AWK 中,所有数组索引实际上都被视为字符串,然后进行哈希处理。因此,AWK 数组实际上是作为哈希表实现的。
上面函数还有另一个可能引起一些困惑的方面。前面我说过 ISO Latin 1 字符的 Unicode 代码点都小于或等于 0xFF,但在上面的函数中,0xC2A0-0xC2BF 和 0xC380-0xC3BF 范围内的值被视为指向 ISO Latin 1 字符。这是因为这些范围覆盖了 Unicode 代码点从 0xA0-0xFF 的 UTF-8 编码。换句话说,上面的函数处理的是 Unicode 代码点的 UTF-8 编码,而不是代码点本身。
如果您有兴趣了解 UNICODE 代码点在 UTF-8 文件中是如何编码的,您应该研究这个维基百科页面。
字节顺序标记 (BOM)
我猜你们大多数人都至少对 UTF-16 字节顺序标记 (BOM) 有些了解。我在清理 Unicode 文件支持时遇到的一件事是,BOMs 实际上是不被鼓励的,尤其是在 UTF-8 文件中。
多年来,我一直认为 UTF-16 文件需要 BOM,但这可能表明过去(好吧,让我们只说很多年)我只使用了 Windows 和 UEFI。如果您创建了 UTF-16 格式的 PsCal 事件文件,则必须包含 BOM。像许多优秀的程序员一样,我有点懒惰,我真的不想添加代码来尝试解析文件的编码。
然而,我发现处理包含 BOM 的 UTF-8 文件很容易,所以 UTF-8 格式的 PsCal 事件文件无论有无 BOM 都可以接受。任何缺少 BOM 的事件文件都假定为 UTF-8 文件。
下面是我添加到 pscal.awk 的一个函数的定义。它在读取了事件文件(或它包含的某个文件)的第一行之后,但在采取任何其他操作之前被调用。它极大地简化了 PsCal 对各种输入文件格式的处理。
################################################################################
## Decode a file's BOM and take appropriate action.
##
## LineIn should be the first line read from gEventsFile. If the BOM is one that
## is recognized, it is stripped from Line, then Line is assigned back to $0.
##
## If the BOM indicates a UTF-16 file, a library function is invoked to make an
## ASCII (UTF-8) copy which is then assigned to gEventsFile. The first line of
## this copy is then read into $0.
##
## If the BOM is NOT recognized, $0 is not modified and UTF-8 is assumed.
##
## RETURNS: The file type (gUtf32, gUtf16LE, gUtf16BE, gUtf8BOM, or gUtf8).
################################################################################
function _HandleBom(LineIn, # Parameter
Byte1,Byte2,Byte3,Byte4,UTF32) # Local vars
{
Byte1 = LibOrd(substr(LineIn,1,1))
Byte2 = LibOrd(substr(LineIn,2,1))
Byte3 = LibOrd(substr(LineIn,3,1))
Byte4 = LibOrd(substr(LineIn,4,1))
if (Byte1 == 0xEF && Byte2 == 0xBB && Byte3 == 0xBF) {
$0 = substr(LineIn,4)
return gUtf8BOM
}
if ((Byte1 == 0xFE && Byte2 == 0xFF) || (Byte1 == 0xFF && Byte2 == 0xFE)) {
close(gEventsFile)
gEventsFile = LibOpenPossibleUtf16File(gEventsFile)
getline < gEventsFile # Re-read line 1 without the BOM or encoding.
return (Byte1 == 0xFF) ? gUtf16LE : gUtf16BE
}
UTF32 = Byte1 + lshift(Byte2,8) + lshift(Byte3,16) + lshift(Byte4,24)
if (UTF32 == 0xFFFF0000 || UTF32 == 0x0000FFFF) {
return gUtf32
}
return gUtf8
}
全局变量 gEventsFile 存储了第一行被读入另一个全局变量 $0 并赋值给 LineIn 参数(在调用 _HandleBom 函数之前)的文件的名称。
如果 LineIn 的前 3 个字节是 UTF-8 BOM,那么它们将从 $0 中被剥离,这样更高级别的代码就永远不会看到它们。
当存在 UTF-16 BOM 时,事件文件将被关闭,然后调用 LibOpenPossibleUtf16File() 函数创建一个 AWK 可以正确处理的副本。gEventsFile 被重新定义以反映库函数创建的临时文件的名称。最后,getline 函数将文件副本的第一行读入全局变量 $0,因此,同样,更高级别的代码也不会意识到输入文件有任何“奇怪”之处,也不必处理 BOM 或多字节字符。
如果没有 UTF-32 BOM,该函数将默认假定文件是 UTF-8 且无 BOM。
我曾经考虑过像处理 UTF-16 文件一样处理 UTF-8 文件,方法是创建一个副本,其中 Windows-1252/ISO Latin 1 集合中所有多字节编码的 Unicode 代码点都被转换为其字符索引。我最终决定放弃这种方法,而是选择在从事件文件中读取 UTF-8 文件的每一行时调用 LibConvertUtf8ToWin1252 库函数。
我之所以能够这样做,是因为 PsCal 使用一个单一函数从事件文件中读取行。该函数处理多个编辑任务,例如跳过注释块中的行、删除某些空格和行内注释、组合续行等等。在这里处理多字节 UTF-8 编码字符似乎是一项合理的任务,尤其考虑到我相信大多数用户事件文件都将采用 UTF-8 编码。
现在(关于 Monty Python 团队)我们将进入一个完全不同的内容……
新的文本效果功能
我最近添加到 PsCal 的新功能之一是能够在渲染日历某天上的事件文本时选择几种文本效果之一。您可以通过在事件定义中添加一个选项来实现,如下所示:;efx=<effect> 最终我得到了 2 种文本发光效果、4 种文本框效果和一个数字效果,该效果选择渲染文本时使用的黑色百分比。
文本发光
文本发光效果命名为 WGlow 和 BGlow,其中“W”和“B”分别表示白色和黑色。它们以黑色或白色显示事件文本,并带有相反“颜色”的外发光。这些效果确保在图像上打印的任何文本都可读,无论背景图像是什么。
我将 WGlow 设置为 PsCal 的默认效果。因此,您不再需要为要在日历日显示的背景图像进行任何亮化处理。也就是说,无论背景图像有多少种灰色,WGlow 效果都确保您在图像上显示的任何文本都可读,例如 PsCal 2020 示例日历中的这个例子。

文本框
文本框效果命名为 WBox、BBox、WWBox 和 WBBox,与发光效果一样,“Box”前面的“W”和“B”分别表示白色或黑色框。WBox 和 BBox 效果绘制一个仅够容纳事件文本的白色或黑色框,然后以相反的颜色绘制文本。
WWBox 和 WBBox 效果的操作与之前描述的框效果类似,不同之处在于它们绘制的框是日历上的一整天宽度——它不是根据文本宽度调整的。
文本灰度
最后一种效果控制用于打印事件文本的灰色阴影。您将阴影指定为黑色的整数百分比,因此 ;efx=100 打印完全黑色的文本,;efx=50 打印灰色的文本,;efx=10 打印非常浅的灰色文本。
杂项事件文件添加
我在用户事件文件中添加了几项新功能,其中一些我在此介绍。
我将简单提及的功能包括:续行、任何行上的行内注释、单个事件定义中允许多个图形函数、注释块,以及消除了 ps_functions 和 fonts 部分行首需要“@”的麻烦。
请注意,上面提到的更改以及下面介绍的更改都包含在 PsCal 的 doc 目录下的 EventFileFormat.pdf 文件中。
@month:<month> 和 @year:<year>
这两个新关键字允许您指定默认月份和默认年份。当这些关键字后面的任何事件未指定事件的月份或年份时,PsCal 会假定它发生在默认月份和年份。这些关键字可以在事件文件中出现多次。
@include:[<drive>:][<path>;]<file name>
include 关键字允许您像包含其他文件一样将它们包含在事件文件中。我认为这对于包含您想放在日历上的 PostScript 图像最有帮助。您也可以决定使用此功能将每年的事件保存在单独的文件中。
@include_dir:[<drive>:]<path>[;[<drive>:]<path>[;...]]
include_dir 关键字允许您定义 PsCal 应该查找 include 文件的目录。任何不包含路径信息的 include 文件引用都假定位于当前目录。如果它不存在于当前目录,并且前面有一个 include_dir 关键字,那么 PsCal 将在 include_dir 关键字定义的目录中搜索 include 文件(按列出的顺序)。
结论
首先,我诚挚地感谢任何有毅力读完这篇文章的人!我希望您能从中学习到一些未来对您有用的东西。
为 PsCal 添加对英语以外语言的支持对我来说是一次很棒的学习机会,也很有趣。我欠 FrogCoder5 一个感激之情,是他给了我这个推动!由于我为此付出的努力,我对 PostScript 语言的设计有了更深入的了解,对 Unicode 文件也有了更好的理解。