
SQL 查询优化 FAQ 第一部分(附视频讲解)
4.91/5 (38投票s)
SQL 查询优化 FAQ 第一部分(附视频讲解)
SQL查询优化常见问题解答第一部分(SQL计划)
1) 引言和目标
2) 什么是SQL执行计划?
3) 我们能否逐步了解SQL查询计划是如何创建和执行的?
4) 好的,我应该从哪里开始?
5) 什么是表扫描(操作符1)?
6) 通过为表扫描添加唯一键,性能能否提高?
7) 什么是物理读和逻辑读?
8) 表扫描看起来效率不高?
9) 什么是查找扫描(操作符2)?
10) 我们能否实际演示查找扫描?
11) SQL Server中的堆表是什么?
12) SQL查询计划中的RID查找堆是什么?(操作符3)
13) 什么是书签查找?
14) 查找是代价高昂的操作,我们如何消除它们?
15) 什么是覆盖索引?
16) 我们还有其他创建覆盖索引的有效方法吗?
17) 索引的大小如何影响性能?
18) 唯一列如何提高索引性能?
19) 索引的顺序有多重要?
20) 索引的首选数据类型是什么?
21) 什么是索引视图,它如何提高性能?
22) 我们能否实际演示索引视图如何提高性能?
25) 参考资料
引言和目标
在本文中,我们将首先尝试理解什么是SQL计划,它是如何创建的,然后我们将转向理解如何读取SQL计划。在阅读SQL计划时,我们将尝试理解不同的操作符,如表扫描、索引查找扫描、聚集扫描、RID查找等。我们还将探讨与聚集索引和非聚集索引相关的最佳实践以及它们如何在内部工作。我们将实际演示索引视图如何提高性能以及在哪些场景下应该使用它们。
这是我送给我所有.NET朋友的小礼物,一本完整的400页FAQ电子书,涵盖了各种.NET技术,如Azure、WCF、WWF、Silverlight、WPF、SharePoint等等,请点击这里获取。
快速入门SQL Server性能调优视频
| 视频描述 | YouTube链接 |
| SQL Server调优向导如何帮助性能调优 | http://youtu.be/AaPaIVI-yyI?hd=1 |
| SQL计划概念、迭代器和逻辑读 | http://youtu.be/tWDM6PAA0S0 |
| 如何通过创建唯一键来提高表扫描性能 | http://youtu.be/P9nnYPdJ-78?hd=1 |
什么是SQL执行计划?
每个SQL查询都被分解为一系列执行步骤,称为操作符。每个操作符执行基本操作,如插入、搜索、扫描、更新、聚合等。操作符分为两种:逻辑操作符和物理操作符。
逻辑操作符描述了执行在概念层面如何执行,而物理操作符是执行操作的实际逻辑/例程。

在查询计划中,您总是会看到物理操作符。一个逻辑操作符可以映射到多个物理操作符。反之亦然,但这是一种罕见的情况。有些操作符既是物理操作符也是逻辑操作符。您可以在http://msdn.microsoft.com/en-us/library/ms191158.aspx查看SQL Server的所有逻辑和物理操作符。下表显示了逻辑操作符和物理操作符之间的一些示例映射。
| 逻辑操作符 | 物理操作符 |
| 内连接 | • 合并连接 • 嵌套循环 |
| 计算标量 | 计算标量 |
我们能否逐步了解SQL查询计划是如何创建和执行的?
SQL的解析和执行分三个阶段。

解析:- 第一阶段是解析SQL查询的语法并创建一个查询处理器树,该树定义了执行SQL的逻辑步骤。这个过程也称为“代数器”。
优化:- 下一步是找到执行由“代数器”定义的查询处理器树的优化方法。此任务由“优化器”完成。“优化器”获取数据统计信息,例如行数、行中唯一数据的数量、表是否跨越多个页面等。换句话说,它获取关于数据的数据信息。所有这些统计信息都被获取,查询处理器树被获取,并使用资源、CPU和I/O准备一个基于成本的计划。优化器使用数据统计、查询处理器树、CPU成本、I/O成本等生成并评估许多计划,以选择最佳计划。
优化器得出一个估计计划,对于这个估计计划,它试图在缓存中找到一个实际执行计划。估计计划基本上是优化器产生的,而实际计划是在查询实际执行后生成的。
执行:- 最后一步是执行由优化器发送的计划。
好的,我应该从哪里开始?
到目前为止,我们已经了解了操作符以及SQL计划的创建和执行方式。因此,第一件事是理解不同的操作符及其逻辑。正如之前讨论的,操作符构成了SQL计划的基本单元,如果我们能够理解它们,我们就可以在很大程度上优化我们的SQL。那么让我们来理解基本而重要的操作符。
什么是表扫描(操作符1)?
在我们尝试理解表扫描操作符之前,让我们先看看如何查看SQL计划。进入SQL Management Studio后,点击“新建查询”并编写您想要查看SQL计划的SQL。点击查询窗口中显示的图标,如下图所示。点击图标后,您将看到查询计划。

既然我们已经了解了如何查看查询计划,那么让我们来理解第一个基本操作符,即表扫描。为了理解它,我们创建了一个简单的公司表,包含公司代码和描述。不要创建任何主键或索引。现在编写一个简单的SQL,其中包含一个针对其中一个属性的select子句,我们目前选择了公司代码,如上图所示。
如果您点击查询计划图标,您将在查询计划中看到表扫描。现在让我们来理解它表示什么。

如果存在主键,表扫描操作符会逐行扫描每个记录,直到找到精确的记录。例如,在我们的搜索条件中,我们给出了“500019”作为公司代码。在表扫描中,它会逐行扫描,直到找到记录。一旦找到记录,它就会将该记录作为输出发送给终端客户端。
如果表没有主键,它将继续向前搜索以查找更多匹配项(如果有的话)。
通过为表扫描添加唯一键,性能能否提高?
是的,如果您为表扫描搜索条件添加唯一键,性能会提高。让我们来看一个实际的演示。右键单击表字段,并在客户代码字段上创建一个唯一键,如下图所示。

现在我们进入SQL Server分析器,使用“set statistics io on”将统计信息设置为“ON”。在统计信息打开的情况下,我们还执行带有客户代码条件的查询,如以下代码片段所示。
set statistics io on SELECT TOP 1000 [CustomerCode] ,[CustomerName] FROM [CustomerNew].[dbo].[Customers] where customercode=524412
如果单击消息,您将看到逻辑读为“3”。
(1 row(s) affected) Table 'Customers'. Scan count 0, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
现在我们去删除唯一键,逻辑读是17,这意味着与唯一键相比,性能下降了。
(1 row(s) affected) Table 'Customers'. Scan count 1, logical reads 17, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
什么是物理读和逻辑读?
数据库的主要工作是存储和检索数据。换句话说,大量的磁盘读写操作。读写操作消耗大量的资源,并且需要很长时间才能完成。SQL Server为缓存分配虚拟内存以加速I/O操作。每个SQL Server实例都有自己的缓存。
当数据被读取时,它会存储在SQL缓存中,直到不再被引用或缓存因某种目的而需要时。因此,不是从物理磁盘读取,而是从SQL缓存读取。同样,对于写入,只有在数据被修改时才写回磁盘。
因此,当数据从SQL缓存中获取时,称为逻辑读;当数据从物理数据库中读取时,称为物理读。
表扫描看起来效率不高?
如果表中的记录数量较少,表扫描操作符是很好的。如果表中的记录数量较多,那么表扫描效率非常低,因为它需要逐行扫描才能找到记录。
因此,对于表中大量行,首选查找扫描操作符而不是表扫描操作符。
什么是查找扫描(操作符2)?
查找扫描不会扫描所有行来获取记录,它使用索引和B-树逻辑来获取记录。下面是一个示例图,解释了B-树的基本工作原理。下图显示了索引如何对1-50的数字起作用:-
• 假设您要搜索39。SQL Server将首先从第一个节点即根节点开始。
• 它会看到该数字大于30,因此它移动到50节点。
• 在非叶节点中,它会比较是否大于40或小于40。由于它小于40,它会循环遍历属于40节点的叶节点。
在表扫描中,它扫描所有行,而在查找扫描中,它扫描的行数相对较少。例如,要获取记录39,它只扫描了9条记录,而不是遍历所有50条记录。

我们能否实际演示查找扫描?
在上面的相同示例中,让我们在公司代码字段上创建一个聚集索引,然后再次点击SQL计划图标查看SQL计划。

如果您查看带有公司代码的SELECT查询的SQL计划,您将看到一个聚集索引查找操作符,如下图所示。换句话说,它表示它将使用B-树逻辑进行搜索,而不是逐行遍历。

如果您的公司代码上有非聚集索引,它将显示一个非聚集索引操作符,如下图所示。您可能想知道查询计划中的RID查找和嵌套循环是什么,我们稍后会讨论。
下图表明它正在使用非聚集索引逻辑操作符。

SQL Server中的堆表是什么?
没有聚集索引的表称为堆表。堆表的数据行未排序,因此访问堆表的开销巨大。
SQL查询计划中的RID查找堆是什么?(操作符3)
当您在连接查询中使用非聚集索引时,会看到RID查找。例如,下面是一个简单的客户表和地址表通过“custcode”连接的示例。
SELECT Customers.CustomerName, Address.Address1 FROM Address INNER JOIN Customers ON Address.Custcode_fk = Customers.CustomerCode
如果您此时不在主表(即客户表)上放置索引,并且查看SQL计划,您应该会看到RID查找堆,如下图所示。我们将理解它的含义,请先尝试大致了解这个操作符。
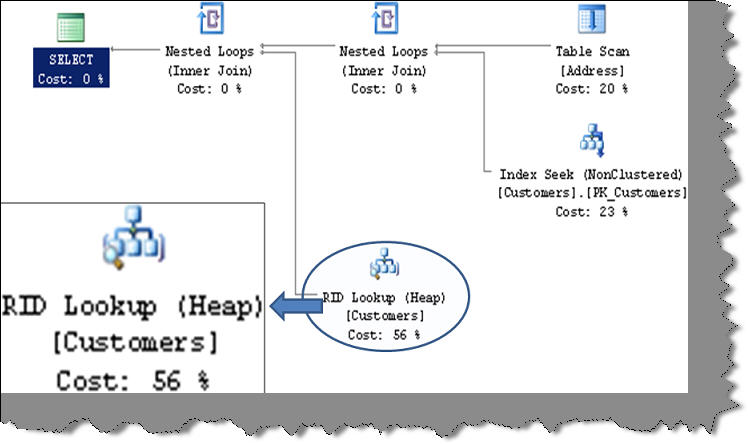
为了理解RID查找,我们首先需要理解非聚集索引如何与聚集索引和堆表协同工作。下面是一个简单的图,描述了它们的工作原理和关系。

非聚集索引也使用B-树结构的基本原理来搜索数据。在非聚集索引中,叶节点是一个“Rowid”,它根据两种情况指向不同的事物:-
场景1:- 如果在连接中具有主键的表在连接键(当前连接键是custcode)上具有聚集索引,那么叶节点(即“rowid”)将指向聚集索引的索引键,如下图所示。

场景2:- 如果具有主键的表没有聚集索引,那么非聚集索引叶节点“rowid”将指向堆表上的实际行。由于数据存储在不同的堆表中,它使用查找(即RID查找)来获取实际行。下面是一个没有聚集索引的连接查询计划。

什么是书签查找?
正如前一节所讨论的,当查询在不属于非聚集索引的列上进行搜索时,需要进行查找。如前所述,您要么需要在聚集索引上进行查找,要么需要在堆表上进行查找,即RID查找。
这些查找的旧定义被称为“书签”查找。如果您使用SQL 2000查看SQL计划,您应该在查询计划中看到书签查找。在SQL 2000中,书签查找使用专用的迭代器来确定表是堆表还是索引表,并相应地更改搜索逻辑。
因此,简而言之,索引查找和RID查找不过是书签查找的类型。
查找是代价高昂的操作,我们如何消除它们?
是的,查找是代价高昂的操作,应尽可能避免。为了避免RID查找或聚集查找,我们可以使用覆盖索引。
下面是一个简单的表,包含客户代码和客户名称两个字段。聚集索引定义在客户代码上,非聚集索引定义在客户名称上,如下图所示。
| 索引 | 字段名 |
| 聚集索引 | 客户代码 |
| 非聚集索引 | 客户姓名 |
让我们执行下面的语句,并查看其查询计划。请注意,我们正在非聚集索引列上进行搜索。
SELECT * FROM [CustomerNew].[dbo].[Customers] where CustomerName='20 microns'
由于非聚集索引需要在聚集索引上进行查找,它使用RID查找来获取聚集索引。这种查找的发生是因为客户名称非聚集索引没有关于聚集索引数据的信息。如果我们可以以某种方式让非聚集索引知道聚集索引数据,就可以避免RID查找。

为了让非聚集索引(即客户名称)知道聚集索引(即客户代码),我们可以在客户和客户代码上创建一个组合非聚集索引,如下图所示。
| 索引 | 字段名 |
| 聚集索引 | 客户代码 |
| 非聚集索引 | 客户姓名 客户代码 |
现在,如果您生成计划,您会看到RID查找被完全消除了。在这种情况下,客户代码键被称为覆盖索引。

什么是覆盖索引?
如上所述。它有助于消除查找操作。
我们还有其他创建覆盖索引的有效方法吗?
复合非聚集索引的创建存在一些缺点:-
• 您无法在varchar(max)、XML等数据类型上创建复合索引。
• 索引大小增加了键的大小,从而进一步影响性能。
• 可能超出索引键大小900字节的限制。
创建覆盖索引的最佳实践是使用include关键字。因此,您创建非聚集索引,如以下代码片段所示。
您可以看到,我们已将客户代码主键作为非聚集索引客户名称的一部分包含在内,当您重新运行计划时,您可以看到书签查找是如何被删除以及如何使用聚集索引的。
CREATE NONCLUSTERED INDEX [MyIndex] ON [dbo].[Customers] ( CustomerName ) INCLUDE (CustomerCode) ON [PRIMARY]
索引的大小如何影响性能?
在回答这个问题之前,我们先下一个结论:“索引键的大小越大,性能也会相应下降。”让我们通过一个小的实际例子来理解其影响。下面是一个简单的客户表,包含客户代码和客户姓名字段,数据类型如下表所示。
* 请注意,客户代码具有聚集索引,数据类型为int。
| 字段名 | 数据类型 |
| 客户代码(聚集索引) | int |
| 客户姓名 | Varchar(50) |
现在执行以下SQL语句。在下面的SQL脚本中,“Customer”是数据库,“CustomerTable”是表。此SQL语句提供了用于存储索引的页面数量的详细信息。
对于刚接触SQL Server页面的朋友,请注意:页面是存储的基本单位。换句话说,硬盘上分配的磁盘空间被划分为页面。页面大小通常为8 KB。页面包含SQL Server的数据行。如果您的行可以容纳在一个页面中,您就不需要从一个页面跳转到另一个页面,这会提高性能。

现在,如果您执行上述SQL语句,它将为您提供用于存储聚集索引的页面数量。您可以从下面的结果中看到,带有“int”的聚集索引使用了12个页面。
SELECT Indextable.Name
,Indextable.type_desc
,PhysicalStat.page_count
,PhysicalStat.record_count
,PhysicalStat.index_level
FROM sys.indexes Indextable
JOIN sys.dm_db_index_physical_stats(DB_ID(N'Customer'),
OBJECT_ID(N'dbo.CustomerTable'),NULL, NULL, 'DETAILED') AS PhysicalStat
ON Indextable.index_id = PhysicalStat.index_id
WHERE Indextable.OBJECT_ID = OBJECT_ID(N'dbo.CustomerTable')
| 名称 | type_desc | page_count | record_count | index_level |
| IX_Customers | CLUSTERED | 12 | 3025 | 0 |
| IX_Customers | CLUSTERED | 1 | 12 | 1 |
现在让我们将数据类型更改为numeric,如下图所示。
| 字段名 | 数据类型 |
| 客户代码(聚集索引) | 数值 |
| 客户姓名 | Varchar(50) |
现在,如果您再次执行上述查询,您会发现页面数量增加了,这意味着SQL引擎必须在页面之间跳转才能获取数据行。换句话说,这会降低性能。
| 名称 | type_desc | page_count | record_count | index_level |
| IX_Customers | CLUSTERED | 14 | 3025 | 0 |
| IX_Customers | CLUSTERED | 1 | 14 | 1 |
如果您将数据类型更改为“char”或“varchar”,“page_count”将具有最差的值。下图显示了由于数据类型原因,页面数量是如何增加的。

因此,总结来说,索引大小越大,页面数量越多,性能越差。避免使用“char”、“varchar”等数据类型,“int”是索引的首选数据类型。
如果聚集索引较小,我们将获得以下优势:-
- 减少I/O,因为8KB页面数量减少。
- 随着大小的减小,缓存大小增加。
- 所需存储空间更少。
唯一列如何提高索引性能?
在唯一列值上创建索引可以提高索引的性能。因此,唯一列始终是聚集索引的最佳候选。让我们演示一下,在唯一列上创建聚集索引与在非唯一值列上创建索引相比,如何提高性能。
下面是一个简单的查询,针对客户表执行,该表有两个字段:“active”和“customercode”。“customercode”字段具有唯一值,而“active”字段具有非唯一值,它只有“1”和“0”两个值。下面是一个带有统计信息IO ON的SQL语句。
set statistics io on SELECT * FROM Customers where active=1 and CustomerCode=500008
如果您在“customercode”字段上使用聚集索引执行上述语句,逻辑读取次数为“2”。
(1 row(s) affected) Table 'Customers'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
如果您在“active”字段上使用聚集索引执行上述SQL语句,逻辑读取次数为16。换句话说,性能受到了影响。
(1 row(s) affected) Table 'Customers'. Scan count 1, logical reads 16, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
索引的顺序有多重要?
创建复合索引时,复合索引中列的顺序也至关重要。例如,对于下面的客户表,我们创建了一个索引,其中“customercode”作为第一列,“customerid”作为第二列。

如果您项目中的大多数SQL语句如下所示,即“where”子句中以“customerid”作为第一列,那么“customerid”应该作为复合索引的第一列。
Select * from Customer where Customerid=1 and CustomerCode=9898998
如果“where”子句中“customercode”是第一列,如下图所示,那么复合键应该将“customercode”作为您的联合索引键的第一列。
Select * from Customer where CustomerCode=9898998 and Customerid=1
索引的首选数据类型是什么?
与“char”、“varchar”等字符串数据类型相比,“integer”数据类型是索引的首选数据类型。如有需要,您也可以选择“bigint”、“smallint”等。算术搜索比字符串搜索更快。
什么是索引视图,它如何提高性能?
索引视图是一个虚拟表,表示一个SELECT语句的输出。通常,当我们创建视图时,视图不存储任何数据。因此,当我们查询视图时,它会查询底层基础表。
但是当我们创建索引视图时,结果集会持久化到硬盘上,这可以节省大量的开销。所以让我们了解索引视图的优点和缺点。
优点
通过创建索引视图,您可以将预计算值、昂贵的计算和连接存储在索引视图中,这样我们就不需要一遍又一遍地重新计算它们。

缺点
索引视图不适用于事务频繁的表,因为如果基础表发生变化,SQL引擎也需要更新索引视图。
我们能否实际演示索引视图如何提高性能?
下面是一个简单的查询,根据客户表中的“注册日期”计算计数。
SELECT dbo.Customers.RegisterDate as RDate, count(*) as CountCust FROM dbo.Customers group by dbo.Customers.RegisterDate
为了理解这一点,我们将进行以下操作:-
• 我们将执行上述针对没有索引的表的聚合SELECT查询,并测量其逻辑读。我们还将测量对该表的插入操作的逻辑读。
• 在下一步中,我们将创建一个聚集索引,并再次记录SELECT和INSERT操作的逻辑扫描。
• 最后,我们将创建一个索引视图,并再次测量SELECT和INSERT操作的逻辑扫描。

无索引基准测试
现在让我们执行上述聚合语句,不带任何索引,并打开统计I/O,如下面的代码片段所示。
Set statistics io on go SELECT dbo.Customers.RegisterDate as RDate, count(*) as CountCust FROM dbo.Customers group by dbo.Customers.RegisterDate
如果您查看SQL计划,它会使用哈希匹配。

上述操作的SELECT查询的总逻辑读取次数为16。
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customers'. Scan count 1, logical reads 16, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
对于插入操作,总逻辑读操作为1。
set statistics io on insert into Customers values(429,'Shiv','1/1/2001') Table 'Customers'. Scan count 0, logical reads 1, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected)
使用聚集索引进行基准测试
现在,让我们在“customers”表上创建一个聚集索引,打开统计I/O,然后查看计划。您可以看到它使用索引扫描并使用stem聚合逻辑操作符来提供结果。

SELECT查询执行上述SQL查询需要10次逻辑读取。
(6 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customers'. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
使用聚集索引插入需要2次逻辑读取。
Table 'Customers'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected)
使用索引视图进行基准测试
现在让我们创建一个索引视图,并尝试再次对SELECT和INSERT查询进行基准测试。下面是创建索引视图的SQL代码片段。请注意,'count' 不适用于索引视图,我们需要使用 'count_big'。一些函数(如 'avg' 等)也不允许与索引视图一起使用。
CREATE VIEW IndexedView WITH SCHEMABINDING as SELECT dbo.Customers.RegisterDate as RDate, COUNT_BIG(*) as CountCust FROM dbo.Customers group by dbo.Customers.RegisterDate GO CREATE UNIQUE CLUSTERED INDEX NonInx ON IndexedView(RDate); GO
如果您查看计划,您会发现没有聚合逻辑操作符,因为它们已在索引视图中预先计算。

SELECT统计信息显示逻辑读取为1。
Table 'Customers'. Scan count 0, logical reads 1, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
如下图所示,索引视图的插入逻辑扫描为18。
Table 'IndexedView'. Scan count 0, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 3, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customers'. Scan count 0, logical reads 1, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected)
因此,总而言之,索引视图对于选择聚合查询很有利,它们可以提高性能。另一方面,如果您的表事务繁忙,那么索引视图可能会降低您的性能。
下图是一个简单的性能影响图,使用上述基准数据绘制。您可以看到SELECT加索引视图如何减少逻辑扫描,以及INSERT逻辑如何随索引视图增加。

插入索引视图的性能会受到影响,因为对基表的任何更新也需要反映到索引视图中,这会降低性能。

Note: - If your base table is highly transaction indexed views will decrease performance of your insert, update and delete queries.
参考文献
• http://en.wikipedia.org/wiki/Query_plan
• Grant FritChey 的执行计划基础 http://www.simple-talk.com/sql/performance/execution-plan-basics/
• 关于逻辑和物理操作符的最佳指南 http://msdn.microsoft.com/en-us/library/ms191158.aspx
• Microsoft SQL Server 2005 内部:Kalen Delaney 的查询调优和优化
详细讨论物理和逻辑读取的链接
• http://netindonesia.net/blogs/kasim.wirama/archive/2008/04/20/logical-and-physical-read-in-sql-server-performance.aspx
• http://msdn.microsoft.com/en-us/library/aa224763(SQL.80).aspx
• http://msdn.microsoft.com/en-us/library/ms184361.aspx
如需进一步阅读,请观看以下面试准备视频和分步视频系列。