
在线手写识别的多卷积神经网络方法
4.95/5 (36投票s)
本研究侧重于一种在线手写识别系统的单词识别技术,该系统使用多个组件神经网络(MCNN)作为分类器的可交换部分。
- 下载源代码 - 2.2 MB
- 下载源代码 - 6.8 MB
- 下载示例 - 159.2 KB
- 下载 lower_case_letter_v2.zip - 5.6 MB
- 下载 digit_v2.zip - 3.3 MB
- 下载 capital_letter_v2.zip - 5.6 MB
摘要
本文描述的研究侧重于一种在线手写识别系统的单词识别技术,该系统使用多个组件神经网络(MCNN)作为分类器的可交换部分。与大多数最新方法一样,该系统通过将手写单词分割成更小的部分(通常是字符)并单独识别它们来工作。然后,识别结果是个别识别部分的组合。它们依次被发送到单词识别模块的输入端,通过应用一些字典搜索算法来选择最佳结果。所提出的分类器克服了传统分类器在处理大字符类别时遇到的障碍和困难。此外,所提出的分类器还具有可扩展的能力,可以通过动态添加或更改组件网络和内置字典来识别其他字符类别。
引言
如今,触摸用户界面(TUI)越来越受欢迎,并在人机交互中发挥着重要作用。平板电脑、智能手机和接受手写笔或手指输入的TUI计算机已成为许多人不可或缺的一部分。使用手指或手写笔作为输入设备取代了许多传统鼠标和键盘的功能。手写笔相对于鼠标的一个主要优点是,手写笔是一种自然的书写工具,而鼠标作为书写工具则非常笨拙。然而,这需要一种可靠的方法将手写文本转换为计算机可以直接处理的编码,例如 ASCII。传统的转换模型通常包括一个预处理器,该预处理器从图像或输入屏幕中提取每个单词并将其分割成段。然后,神经网络分类器根据这些段找到每个可能字符的似然度。这些似然度被用作一个特殊算法的输入,该算法识别整个单词。近年来,手写识别的研究已经取得了商业应用的水平。尽管如此,这种单一神经网络分类器仍然存在显著的缺点,即大型网络组织复杂且扩展能力有限。
一个高识别率的神经网络可以很容易地用来识别小字符类别,但不能识别大字符类别。更大的输入和输出会增加神经网络的层数、神经元数量和连接数。因此,这给网络训练过程带来了更多困难,特别是识别率会显着下降。此外,单一神经网络分类器仅适用于特定字符类别。它不可交换或不可扩展,除非重新创建或重新训练神经网络,否则无法识别其他字符类别。
本文提出了一种基于多卷积神经网络(CNN)的新型在线手写识别系统。与传统的单一神经网络分类器不同,新型分类器包含一组协同工作的、识别率非常高的组件 CNN。每个 CNN 只正确识别大字符类别(数字、字母等)的一部分,但当这些网络通过编程算法组合在一起时,它们可以创建一个灵活的分类器,通过简单地添加或删除组件 CNN 和语言字典来识别不同的、大的字符类别。
卷积神经网络
卷积神经网络(CNN)是一类特殊的多层神经网络。与其他几乎所有神经网络一样,它们使用反向传播算法的某种版本进行训练。它们的不同之处在于架构。卷积神经网络设计用于直接从像素图像中识别视觉模式,并且只需要最少的预处理。它们可以识别具有极端可变性的模式(如手写字符),并且对失真和简单的几何变换具有鲁棒性。

图 1。 典型的卷积神经网络(LeNET 5)[1]
用于手写数字识别的 LeNET 5 卷积神经网络在 MNIST 数据集上获得了高达 99% 的可靠识别率。输入层大小为 32x32,接收包含待识别数字的灰度图像。像素强度在 -1 和 +1 之间进行归一化。第一个隐藏层 C1 由六个特征图组成,每个特征图有 25 个权重,构成一个 5x5 的可训练 卷积核和一个偏置。特征图的值是通过将输入层与相应的卷积核进行卷积并应用激活函数来计算的。特征图的所有值都被约束为共享相同的可训练卷积核或相同的权重值。由于边界效应,特征图的大小为 28x28,小于输入层。
每个卷积层后都跟着一个子采样层,该层将相应卷积层特征图的维度减小两倍。因此,隐藏层 S2 的子采样图大小为 14x14。类似地,层 C3 有 16 个大小为 10x10 的卷积图,层 S4 有 16 个大小为 5x5 的子采样图。这些层的函数实现方式与层 C1 和 S2 完全相同。S4 层的特征图大小为 5x5,对于第三个卷积层来说太小了。该神经网络的 C1 到 S4 层可以看作是一个可训练的特征提取器。然后,在特征提取器中添加了一个可训练的分类器,形式为 3 个全连接层(一个通用分类器)。

图 2。 基于 Dr. Patrice Simard 模型的一个卷积网络
多组件神经网络分类器
卷积神经网络对于数字或英文字母(26 个字符)等小字符类别的识别率非常高。然而,创建一个能够可靠识别更大集合(62 个字符)的大型神经网络仍然是一个挑战。寻找一个优化且足够大的网络变得更加困难,用大型输入模式训练网络需要更长的时间。网络的收敛速度更慢,特别是,准确率显着下降,因为笔画较大的字符、相似且易混淆的字符等。
上述问题的拟议解决方案是用多个具有高识别率的、针对自身输出集的较小网络来取代一个独特复杂的神经网络。每个组件网络除了官方输出集(数字、字母等)之外,还有一个附加的未知输出(未知字符)。这意味着,如果输入模式未被识别为官方输出的字符,它将被理解为未知字符。

图 3. MCNNs 在线手写识别系统
分类器的字符识别模块是一个多组件神经网络的集合,它们同时对输入模式进行处理。手写单词通过分割成孤立的字符视觉模式进行预处理 []。然后将这些模式输入到所有组件神经网络的输入端,这些神经网络将识别每个自身字符的似然度。一个视觉模式可能被一个、几个或所有组件网络识别,因为不同的类别中有几个相似的字符。如果一个网络无法将该模式识别为其自身字符类的似然度,它将返回一个未知字符(空字符)。该模块的输出结果是一个可能的字符表,该表被组合成可能的单词,例如上例中的“Exper1, Expert, ExperJ, EXper1, EXpert, EXperJ” 。未知字符(空字符)不用于单词组合。然后,这些单词依次被送入下一个单词识别模块,以选择最正确的单词作为整个分类器的输出。在本例中,将选择“Expert” 这个单词。

图 4。 MCNNs 分类器模块的输出
字符识别模块中使用的单词组合算法全局变量
- charMatrix = List<List<Char>> {{E},{x,X},{p},{e},{r},{1,t,J}}// 字符表
- words =List<string> // 组合词列表。
- startIndex: 默认为 0
- baseWord: 默认为“
void GetWords(int startIndex, String baseWord)
{
String newWord = "";
if (startIndex == charMatrix.Count - 1)
{
for (int i = 0; i < charMatrix[startIndex].Count; i++)
{
newWord = String.Format("{0}{1}", baseWord, charMatrix[startIndex][i].ToString());
words.Add(newWord);
}
}
else
{
for (int i = 0; i < charMatrix[startIndex].Count; i++)
{
newWord = String.Format("{0}{1}", baseWord, charMatrix[startIndex][i].ToString());
int newIndex = startIndex + 1;
GetWords(newIndex, newWord);
}
}
} Word 识别模块实际上是一个拼写检查器,它使用几种字典搜索算法和单词纠错技术来获取最佳的有意义的单词。来自字符识别模块的所有可能的单词按顺序输入到字典搜索中。如果其中一个单词在内置字典中找到,它将成为分类器的输出单词。否则,将应用一些单词纠错技术来在自动模式下选择最正确的单词,或在手动模式下向用户显示一系列相似的单词。其中一些技术包括:
- 逐个交换每个字符,并尝试将所有字符替换到其位置,看这是否能构成一个好词。
private bool ReplaceChars(String word, out String result)
{
result = "";
bool isFoundWord = false;
foreach (WordDictionary dictionary in Dictionaries)
{
ArrayList replacementChars = dictionary.ReplaceCharacters;
for (int i = 0; i < replacementChars.Count; i++)
{
int split = ((string)replacementChars[i]).IndexOf(' ');
string key = ((string)replacementChars[i]).Substring(0, split);
string replacement = ((string)replacementChars[i]).Substring(split + 1);
int pos = word.IndexOf(key);
while (pos > -1)
{
string tempWord = word.Substring(0, pos);
tempWord += replacement;
tempWord += word.Substring(pos + key.Length);
if (this.TestWord(tempWord))
{
result = tempWord.ToString();
isFoundWord = true;
return isFoundWord;
}
pos = word.IndexOf(key, pos + 1);
}
}
}
return isFoundWord;
} - 尝试逐个交换相邻的字符。
private bool SwapChar(String word, out String result)
{
result = "";
bool isFoundWord = false;
foreach (WordDictionary dictionary in Dictionaries)
{
for (int i = 0; i < word.Length - 1; i++)
{
StringBuilder tempWord = new StringBuilder(word);
char swap = tempWord[i];
tempWord[i] = tempWord[i + 1];
tempWord[i + 1] = swap;
if (this.TestWord(tempWord.ToString()))
{
result = tempWord.ToString();
isFoundWord = true;
return isFoundWord;
}
}
}
return isFoundWord;
}- 尝试一次省略单词中的一个字符。
- 尝试在每个字母前插入一个新字符。
private bool ForgotChar(String word, out String result)
{
result = "";
bool isFoundWord = false;
foreach (WordDictionary dictionary in Dictionaries)
{
char[] tryme = dictionary.TryCharacters.ToCharArray();
for (int i = 0; i <= word.Length; i++)
{
for (int x = 0; x < tryme.Length; x++)
{
StringBuilder tempWord = new StringBuilder(word);
tempWord.Insert(i, tryme[x]);
if (this.TestWord(tempWord.ToString()))
{
result = tempWord.ToString();
isFoundWord = true;
return isFoundWord;
}
}
}
}
return isFoundWord;
} - 将字符串在每个字符后拆分成两部分。如果两部分都是好词,则将其作为建议等。
private bool TwoWords(String word, out String result)
{
result = "";
bool isFoundWord = false;
for (int i = 1; i < word.Length - 1; i++)
{
string firstWord = word.Substring(0, i);
string secondWord = word.Substring(i);
if (this.TestWord(firstWord) && this.TestWord(secondWord))
{
string tempWord = firstWord + " " + secondWord;
result = tempWord;
isFoundWord = true;
return isFoundWord;
}
}
return isFoundWord;
}通过同时使用多个不同的语言字典在拼写检查器中,所提出的分类器可以正确识别不同的语言,如果存在可以识别这些语言字符类的组件神经网络。
public NNTestingControl()
{
InitializeComponent();
bitmap = null;
networks = null;
textSpellControl1.SpellChecker = this.multipleSpelling;
//English dicionary
multipleSpelling.Dictionaries.Add(this.wordDictionary1);
//France dictionary
//multipleSpelling.Dictionaries.Add(this.wordDictionary2);
//Italian dictionary
//multipleSpelling.Dictionaries.Add(this.wordDictionary3);
} 实验和结果
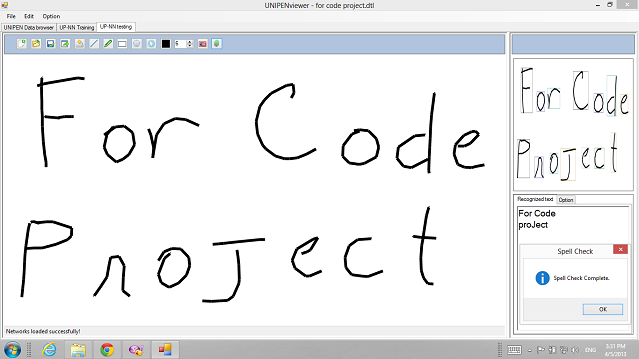
该演示使用三个组件 CNN 来识别 62 个英文字符类别。对于我自己的手绘样本,它可以获得很高的识别率。我真诚地希望这个项目能帮助任何想研究手写识别的人。目前我没有时间继续下去,但我希望有人能将其发展成一个好的开源项目。这是我所有先前文章的完整源代码。有关此项目的所有信息可以在这里 找到。
历史
2013/04/01:更新了一些图片