
从 CFG 文法生成 SLR 解析表
4.92/5 (6投票s)
本文内容包括:从输入文法构建简单-LR (SLR) 解析表,并找出非终结符的 First 集和 Follow 集。
- 下载 FullClassDiagram.zip - 357.8 KB
- 下载 parseTableMaker-noexe.zip - 82.4 KB
- 下载 parseTableMaker.zip - 105.6 KB
- 下载 GrammarAndOutputParsTable.zip - 5 KB
引言
本文描述了一种为 LR (自左向右、自底向上) 解析器构建解析表的方法的实现,该解析器被称为 SLR 解析器或简单-LR 解析器。
促使我开始编写这个项目的核心原因是希望以可重用的格式导出解析表,供其他解析程序使用。
背景
解析
语法分析。识别语言中的句子。发现文档/程序的结构。构建(隐式或显式)一个树(称为解析树)来表示结构。
LR 解析器
识别大多数编程语言的 CFG。无需重写文法。
最通用的 O(n) 移入-归约方法。
最佳的语法错误检测。
LR 文法是 LL 文法的超集。
自底向上解析
从叶子节点到根节点构建解析树。
对应于逆向的最右推导。
- 解析器根据解析表信息执行操作。
- 移入 (Shift)。将下一个输入符号移入堆栈的顶部。
- 归约 (Reduce)。待归约字符串的右端必须在堆栈的顶部。在堆栈中定位字符串的左端,并决定用哪个非终结符替换该字符串。
- 接受 (Accept)。宣布解析成功完成。
- 错误 (Error)。发现语法错误并调用错误恢复例程。
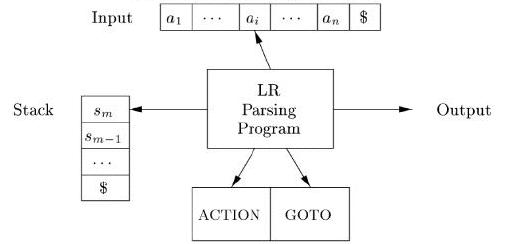
考虑以下示例文法和创建解析表的步骤。
文法
该文法的状态
状态创建规则
1- 状态 0 由额外的文法规则 S' -> S $ 构建,其中 S 是文法的所有起始符号。
并且有一个点 ( . ) 在 S 符号之前。
2- 如果点符号在非终结符之前,则添加在该规则的左侧有此非终结符的文法规则,并将点放在右侧部分的开头。
3-如果状态已存在(具有此规则和相同点位置的状态),则使用该状态而不是创建新状态。
4- 对于一个状态,如果步骤 4 尚未检查,则找到点符号在其前面的终结符和非终结符的集合。
5- 如果步骤 4 的集合非空,则转到 5,否则转到 7。
5- 对于集合步骤 4 中的每个终结符/非终结符,通过使用点位置在参考状态之前(该终结符/非终结符)的所有文法规则,通过增加点到右侧部分的下一部分来创建新状态。
6- 转到步骤 2。
7-状态构建结束
使用 SLR 算法规则填充解析表。
Goto:在解析表的行 StateNumber SN 和列非终结符 V 中,当存在从状态 SN 到状态 SX 的导出非终结符 V 时,设置为 GX。
Reduce:在解析表的行 StateNumber SN 和列终结符 T 中,当状态 SN 中存在具有点位于规则末尾的规则 X,并且 T 是规则 X 右侧的最后一个部分(终结符 T 在点之前)时,设置为 RX。
Shift :在解析表的行 StateNumber SN 和列终结符 T 中,当状态 SN 中存在点位于终结符 T 之前的规则,并且状态 SN 将 T 导出到状态 Y 时,设置为 SY。
Accept:在解析表的行 StateNumber SN 和列 $(添加到真实终结符的额外终结符)中,当 S' -> S 点(点在起始非终结符之后)是状态 SN 规则的成员时,设置为 Accept。
Error:所有空的解析表单元格都是解析错误。
当移入和归约条件同时满足时,文法可能在移入和归约之间产生歧义,并将解析表行 SN 设置为 RX/SY。



使用代码
为了避免在文法产生式数量、非终结符数量、终结符数量等方面的限制,所有类都实现了链表数据结构。
根据这个逻辑,所有类都实现了 3 个级别:
1- Item fields Struct
2- Node Class
3- List Class
类
类图已包含在下载列表中。
类的定义
1-ParsHead
这个类是所有详细类的顶层,包含主要属性。
非终结符列表对象的第一个(Head)。
所有终结符计数。
所有非终结符计数。
一个用于终结符的堆栈。
2-NonTerminals
用于管理非终结符。非终结符的父类是 ParsHead。
示例方法描述
文法规则被处理,并且 LHS 非终结符和 LawNumber 被发送到此方法,非终结符的纯名称通过分割 # 构建,其余部分是名称。之后,检查 Nonterminals 列表是否为空,如果是,则添加第一个节点,即 extraNonTerm,并添加规则号 0(添加的规则),然后退出方法。
如果第一个项不为空,则搜索名称等于搜索非终结符的非终结符节点。如果未找到,则添加新的 NonterminalNode 并将其添加到列表中。
最后,将 LawNum 添加到非终结符的 LawLink 中。
public void checkAdd(string nonTerm,int lawNum)
{
try
{
nonTerminalNode thisNode=null;
string []part=nonTerm.Split(' ');
string NonTerm=part[0].Substring(1,part[0].Length-1);
nonTerminalNode temp;
if(first==null)
{
first = new nonTerminalNode(nonTerminals.ExtraNonTerm,this);
first.lawLink.add(0,nonTerminals.ExtraNonTerm+" #"+NonTerm);
this.checkAdd(nonTerm,lawNum);
return;
}
else
{
temp=first;
while(temp.next!=null)
{
if(temp.item.Name==NonTerm)
{
thisNode=temp;
break;
}
temp=temp.next;
}
if(thisNode==null)
{
if(temp.item.Name!=NonTerm)
{
temp.next = new nonTerminalNode(NonTerm,this);
thisNode=temp.next;
count++;
}
else
thisNode=temp;
}
}
thisNode.lawLink.add(lawNum,nonTerm);
}
catch(Exception e1)
{
MessageBox.Show("in nonTerminals.CheckAdd : "+e1.Message);
}
}
3-Laws
用于管理规则。规则的父类是 Nonterminals。
4-LawsParts
用于管理规则部分。规则部分的父类是 Laws。
5-State
用于管理连接到 StateExports 和 StateLaws 的状态。
6-StateLaws
状态中的规则列表。StateLaws 的父类是 State。
7-StateExport
导出符号和下一个状态编号,并确定导出符号是终结符还是非终结符。
8- ParsTable
用于构建包含上述所有列表的头的解析表。
9-ParsTableElement
Shift ( S )、Reduce ( R )、Goto ( G ),用于保存在 ParseTable 单元格中。
10-TermNonTermList
构建规则部分的含义,该部分由项的数量和它们的类型组成。
考虑 MainForm 的 MakeStates_Click 方法(使用其他对象的主要方法)。
使用类的步骤
1- 创建 ParsHead 对象。
2- 从 RichTextBox 中加载的输入中逐行读取(每行最多一个规则),并通过 load 方法将项加载到 parsHead 对象中。
3- parsHead 现在已准备好使用(非终结符、终结符和规则以及它们之间的关系已创建)。
4- 使用 parsHead 创建 State 类。
5- 调用 State 类的 Create 成员函数来创建状态。
6- 现在可以通过之前的 ParsiHead 信息和对象来创建 ParsTable 对象了。
parsTable=new ParsTable(states.StateCount , ParsHead.terminals , parsHead.Head , this.dgTabel );
states.StateCount:由 state.create 方法根据输入文法创建的状态计数。
ParsHead.terminals:一个包含终结符的堆栈对象。
parsHead.Head:非终结符列表对象的根(第一个)。
this.dgTabel:当前窗体的 DataGridView 对象,用于填充创建的解析表。
7- 清空结果列表框。
8- 在结果列表框中显示输出。
9- 将 TabControl 的选定索引更改为解析表选项卡(第 3 个选项卡)。
10- 使用 parsTable 的 writeGrid 方法填充窗体 DataGridView。
11- 询问输出文件路径以保存解析表。
12- 使用 parseTable 中的 saveTo 方法导出到文件。
private void MakeStates_Click(object sender, System.EventArgs e)
{
try
{
parsHead=new ParsHead();
foreach(string s in content.Lines)
parsHead.load(s);
states=new State(parsHead);
states.create();
parsTable=new ParsTable(states.StateCount,ParsHead.terminals,parsHead.Head,this.dgTabel);
states.makeParsTable(this.parsTable);
result.Items.Clear();
parsTable.showContents(result);
tabControl1.SelectedIndex=2;
parsTable.writeGrid();
SaveFileDialog saveDlg=new SaveFileDialog();
saveDlg.Filter="(*.prt)|*.prt";
if(saveDlg.ShowDialog()==DialogResult.OK)
{
StreamWriter sw=new StreamWriter(saveDlg.FileName);
parsTable.saveTo(sw);
}
}
catch(Exception ex)
{
// MessageBox.Show(ex.Message);
MessageBox.Show("Grammar is incorrect : please check your grammar , example : There is one NonTerminal in Right side that never apear in left side!!!");
}
}
这个类是所有详细类的顶层,包含主要属性。
非终结符列表对象的第一个(Head)。
所有终结符计数。
所有非终结符计数。
一个用于终结符的堆栈。
2-NonTerminals
用于管理非终结符。非终结符的父类是 ParsHead。
示例方法描述
文法规则被处理,并且 LHS 非终结符和 LawNumber 被发送到此方法,非终结符的纯名称通过分割 # 构建,其余部分是名称。之后,检查 Nonterminals 列表是否为空,如果是,则添加第一个节点,即 extraNonTerm,并添加规则号 0(添加的规则),然后退出方法。
如果第一个项不为空,则搜索名称等于搜索非终结符的非终结符节点。如果未找到,则添加新的 NonterminalNode 并将其添加到列表中。
最后,将 LawNum 添加到非终结符的 LawLink 中。
public void checkAdd(string nonTerm,int lawNum)
{
try
{
nonTerminalNode thisNode=null;
string []part=nonTerm.Split(' ');
string NonTerm=part[0].Substring(1,part[0].Length-1);
nonTerminalNode temp;
if(first==null)
{
first = new nonTerminalNode(nonTerminals.ExtraNonTerm,this);
first.lawLink.add(0,nonTerminals.ExtraNonTerm+" #"+NonTerm);
this.checkAdd(nonTerm,lawNum);
return;
}
else
{
temp=first;
while(temp.next!=null)
{
if(temp.item.Name==NonTerm)
{
thisNode=temp;
break;
}
temp=temp.next;
}
if(thisNode==null)
{
if(temp.item.Name!=NonTerm)
{
temp.next = new nonTerminalNode(NonTerm,this);
thisNode=temp.next;
count++;
}
else
thisNode=temp;
}
}
thisNode.lawLink.add(lawNum,nonTerm);
}
catch(Exception e1)
{
MessageBox.Show("in nonTerminals.CheckAdd : "+e1.Message);
}
}
3-Laws
用于管理规则。规则的父类是 Nonterminals。
4-LawsParts
用于管理规则部分。规则部分的父类是 Laws。
5-State
用于管理连接到 StateExports 和 StateLaws 的状态。
6-StateLaws
状态中的规则列表。StateLaws 的父类是 State。
7-StateExport
导出符号和下一个状态编号,并确定导出符号是终结符还是非终结符。
8- ParsTable
用于构建包含上述所有列表的头的解析表。
9-ParsTableElement
Shift ( S )、Reduce ( R )、Goto ( G ),用于保存在 ParseTable 单元格中。
10-TermNonTermList
构建规则部分的含义,该部分由项的数量和它们的类型组成。
考虑 MainForm 的 MakeStates_Click 方法(使用其他对象的主要方法)。
使用类的步骤
1- 创建 ParsHead 对象。
2- 从 RichTextBox 中加载的输入中逐行读取(每行最多一个规则),并通过 load 方法将项加载到 parsHead 对象中。
3- parsHead 现在已准备好使用(非终结符、终结符和规则以及它们之间的关系已创建)。
4- 使用 parsHead 创建 State 类。
5- 调用 State 类的 Create 成员函数来创建状态。
6- 现在可以通过之前的 ParsiHead 信息和对象来创建 ParsTable 对象了。
parsTable=new ParsTable(states.StateCount , ParsHead.terminals , parsHead.Head , this.dgTabel );
states.StateCount:由 state.create 方法根据输入文法创建的状态计数。
ParsHead.terminals:一个包含终结符的堆栈对象。
parsHead.Head:非终结符列表对象的根(第一个)。
this.dgTabel:当前窗体的 DataGridView 对象,用于填充创建的解析表。
7- 清空结果列表框。
8- 在结果列表框中显示输出。
9- 将 TabControl 的选定索引更改为解析表选项卡(第 3 个选项卡)。
10- 使用 parsTable 的 writeGrid 方法填充窗体 DataGridView。
11- 询问输出文件路径以保存解析表。
12- 使用 parseTable 中的 saveTo 方法导出到文件。
private void MakeStates_Click(object sender, System.EventArgs e)
{
try
{
parsHead=new ParsHead();
foreach(string s in content.Lines)
parsHead.load(s);
states=new State(parsHead);
states.create();
parsTable=new ParsTable(states.StateCount,ParsHead.terminals,parsHead.Head,this.dgTabel);
states.makeParsTable(this.parsTable);
result.Items.Clear();
parsTable.showContents(result);
tabControl1.SelectedIndex=2;
parsTable.writeGrid();
SaveFileDialog saveDlg=new SaveFileDialog();
saveDlg.Filter="(*.prt)|*.prt";
if(saveDlg.ShowDialog()==DialogResult.OK)
{
StreamWriter sw=new StreamWriter(saveDlg.FileName);
parsTable.saveTo(sw);
}
}
catch(Exception ex)
{
// MessageBox.Show(ex.Message);
MessageBox.Show("Grammar is incorrect : please check your grammar , example : There is one NonTerminal in Right side that never apear in left side!!!");
}
}
程序是 Tab 页式的,包含以下 4 个选项卡:
1-文法输入
从输入文件获取文法或直接输入。
输入文法语法 (.grm)
1-每个非终结符都以#开头。
示例:
#Vars
2-非终结符的开头没有 #。
示例:phrase a 是一个终结符。
#B a
3-单独的非终结符表示空文法。
示例:
#B
4-文法右侧的所有非终结符必须至少有一个在文法的左侧。
示例:
#B #A p
#A a
5-文法中短语的分隔符是一个空格。
文法样本输入包含在文章下载链接中。
1-每个非终结符都以#开头。
示例:
#Vars
2-非终结符的开头没有 #。
示例:phrase a 是一个终结符。
#B a
3-单独的非终结符表示空文法。
示例:
#B
4-文法右侧的所有非终结符必须至少有一个在文法的左侧。
示例:
#B #A p
#A a
5-文法中短语的分隔符是一个空格。
文法样本输入包含在文章下载链接中。

2-First & Follow
根据定义计算非终结符的 First 集和 Follow 集。
根据定义计算非终结符的 First 集和 Follow 集。


3- 解析表
显示解析表的导出版本(导出文件中不包含空格字符,仅用于显示空格字符)。
N=终结符计数+非终结符计数
解析表 (.prt) 格式:
第一行:
状态计数空格N
第二行:
终结符计数空格非终结符计数
第三行(括号仅用于阅读目的,导出文件中不存在):
[终结符符号,用空格分隔]空格[非终结符符号,用空格分隔]
从第 4 行到 StateCount+3 行:
状态编号:空格ParseCell1Value空格ParseCell2Value...ParseCellNValue
如果解析表的一个单元格有多个值或存在歧义,则单元格值用分隔符 / 分隔。
例如:
S107/R77
对于文件中空的解析表单元格,使用连字符“-”符号。

显示解析表的导出版本(导出文件中不包含空格字符,仅用于显示空格字符)。
N=终结符计数+非终结符计数
解析表 (.prt) 格式:
第一行:
状态计数空格N
第二行:
终结符计数空格非终结符计数
第三行(括号仅用于阅读目的,导出文件中不存在):
[终结符符号,用空格分隔]空格[非终结符符号,用空格分隔]
从第 4 行到 StateCount+3 行:
状态编号:空格ParseCell1Value空格ParseCell2Value...ParseCellNValue
如果解析表的一个单元格有多个值或存在歧义,则单元格值用分隔符 / 分隔。
例如:
S107/R77
对于文件中空的解析表单元格,使用连字符“-”符号。
4- 网格视图
关注点此选项卡显示解析表的网格视图。

这个程序可以简单地构建 LALR 和 CLR 解析。因为这些算法与 SLR 非常接近,我分发此源代码的兴趣在于让其他程序员将其他 LR 系列解析器添加到当前源代码中。
历史
我于 2005 年实现了这个项目,并在 2013 年进行了更新。
参考文献
该项目代码实现了 Aho、Sethi 和 Ullman 于 1986 年在《编译器:原理、技术和工具》(Dragon Book)中描述的SLR算法。