
Azure WebState
5.00/5 (13投票s)
使用 Windows Azure 抓取大量(单个)网页信息并创建统计数据。
![]()
项目可在 http://azurewebstate.azurewebsites.net/[^] 获取。
目录
引言
Windows Azure 是一个云计算平台和基础设施。它提供平台即服务 (PaaS) 和基础设施即服务 (IaaS) 模型,并支持许多不同的编程语言(C#、C++、Java、JavaScript、Python 等)、工具(Visual Studio、命令行、Git、Eclipse 等)和框架(.NET、Zend、Node.js 等),以及不同的操作系统(Windows Server、SUSE、Ubuntu、OpenLogic 等)用于虚拟机。选择 Windows Azure 而非传统网页托管有几个原因。一个原因肯定是数据中心的覆盖范围。CDN 节点目前位于 24 个国家。
在这次“Windows Azure 开发者挑战”竞赛中,我将介绍开发一个成熟的基于云的应用程序所需的所有步骤,该应用程序利用 Windows Azure 平台的扩展和负载平衡功能。我们将看到设置一个使用 Microsoft 云提供商几个关键功能的配置是多么容易(或困难?希望不会!)
- 托管网站并使用 git 形式的集成源代码控制进行部署
- 使用(SQL)数据库存储关系数据
- 为不同需求安装第三方软件,例如用于文档存储的 MongoDB
- 设置虚拟机作为工作器,并具有扩展能力以按需增加工作器数量
在我们深入了解我的想法(和实现)的确切细节之前,我们应该先看看我的 Azure 账户。
我的 Azure 账户
本次竞赛的规则如下:“如果您不注册,将没有资格参加比赛。请确保您使用此链接注册试用,以便我们知道谁已注册。”
话虽如此,很明显必须注册。点击给定的链接,我们最终会到达 windowsazure.com/en-us/pricing/free-trial 页面(以及一些联盟网络参数)。试用账户将为我们提供以下为期 3 个月(免费)的功能:
- 虚拟机和云服务 / 每月 750 小时计算时间
- SQL Server / 750 小时 Web、标准或企业版
- 网站 / 10 个网站
- 移动服务 / 10 个移动服务
- 关系数据库 / 1 个 SQL 数据库
- SQL 报告 / 每月 100 小时
- 存储 / 70 GB,50,000,000 次存储事务
- 备份 / 20 GB
- 数据传输 / 无限入站和 25 GB 出站
- 媒体服务编码 / 50 GB(输入和输出总计)
- CDN / 20 GB 出站,500,000 次事务
- 缓存 / 128 MB
- 服务总线 / 1,500 中继小时和 500,000 条消息
这真是太棒了!这里每月 750 个计算小时略高于 31 天的纯计算能力。这足以让一台虚拟机一直运行(实际执行一些任务 - 而不是空闲或关闭)。我们还可以免费获得 10 个网站和一个 SQL 服务器运行整个月。存储和 CDN 流量数据也足以在云中拥有一台相当强大的机器。
使用我的 Microsoft 账户(以前称为 Microsoft Passport、Live ID 或 Windows Live 账户)登录后,我获得了一个升级。作为 Microsoft Visual C# MVP 的好处是拥有 Microsoft MSDN 和 TechNET 订阅。这也为我在 Windows Azure 上提供了 Windows Azure MSDN - Visual Studio Ultimate 订阅。此包具有以下属性:
- 虚拟机和云服务 / 每月 1500 计算小时
- SQL Server / 1500 小时 Web、标准或企业版
- 网站 / 10 个网站
- 移动服务 / 10 个移动服务
- 关系数据库 / 5 个 SQL 数据库
- SQL 报告 / 每月 100 小时
- 存储 / 90 GB,100,000,000 次存储事务
- 备份 / 40 GB
- 数据传输 / 无限入站和 40 GB 出站
- 媒体服务编码 / 100 GB(输入和输出总计)
- CDN / 35 GB 出站,2,000,000 次事务
- 缓存 / 128 MB
- 服务总线 / 3,000 中继小时和 1,000,000 条消息
所有更改都用粗体标记。所以我获得的计算能力差不多是免费试用的两倍,这还不错。接下来我们讨论我的想法及其即将实现的可能功能。
主要构想
我的项目名为 Azure WebState,它代表一个基于 Azure 的网页统计创建器/数据爬虫。这意味着什么?在过去的一个月里,我构建了一个功能齐全的 HTML5 和 CSS3 解析器。该项目即将开源发布,CodeProject 文章也即将发布。我尝试实现完整的 DOM(DOM Level-3,部分 DOM Level-4),这意味着一旦 HTML 文档被解析,就可以使用 QuerySelector() 或 QuerySelectorAll() 查询元素。当然,GetElementById() 等方法也已实现。
这个库如何对本项目有用?在我们深入细节之前,先了解一下大局
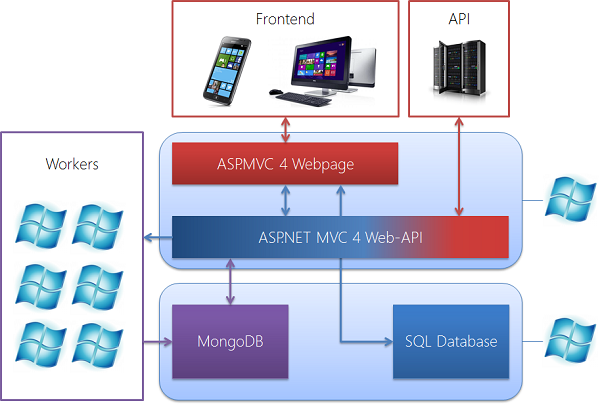
我试图构建的是一个主要使用 Web API 的 MVC 4 网页。当然,有一个可见的前端,它使用了部分公开可用的 API 和部分仅内部可用的 API。该 API 可用于各种用途:
- 获取特定网页的信息(统计数据)
- 获取公开可用统计视图的信息
- 获取受限统计视图的信息
- 在爬取列表中搜索
爬取列表是一个 URL 列表,统计数据基于此列表。该页面将预定义一个包含大约 100-500 个最受欢迎网页的列表(包括 Amazon、Bing、CodeProject、Facebook、Google、Netflix、StackOverflow、Twitter、Wikipedia、YouTube 等),但是,用户可以在页面上注册(例如,获取 API 密钥)并设置自己的爬取列表(可以基于预定义列表,但不是必须)。
爬取页面、解析页面并根据其数据创建统计数据的要求也反映在数据库架构中。本项目将不只是使用关系型(基于 SQL)数据库,还将同时使用 SQL 数据库和 NoSQL 数据库。两者之间的关系如下:

关系型数据库将存储所有关系型数据(例如用户及其爬取列表(一对多)、爬取列表及其对应视图(一对多)、爬取列表及其条目(一对多)、用户及其设置(一对一)等),而 NoSQL 数据库将提供一种文档存储。
我们选择 MongoDB 有多种原因。一个很好的原因是 MongoDB 在 Windows Azure 上可用。另一个原因是 MongoDB 基于 JSON/BSON,并内置 JavaScript API。这意味着我们能够直接从 MongoDB 向客户端返回一些查询作为原始 JSON 数据。
选择 NoSQL 数据库的原因解释起来很快:每个爬取条目都会有一个(文本)blob(如果文档的历史记录也保存下来,可能更多)(代表 HTML 页面),并且(很可能)也会有其他(文本)blob(一个文档可以附加零到多个 CSS 样式表)。所以这已经不是固定布局了。下一个原因是统计条目的数量可能会随着时间增长。一开始,只为单个条目收集官方统计数据,但是,一个用户可以选择相同的条目并请求收集其他统计数据。因此,总而言之,我们必须能够轻松地按条目扩展数据。这在关系数据库中是不可能的(实际上有办法,但效率不高)。
这个项目的目的是什么?爬取网络并创建相关统计数据。一个网页上有多少元素。一个网页的平均大小是多少。请求时间是多少,平均解析时间是多少。所有这些数据都将被保存并提供。
网页上将有大量的统计数据(每个人都可以访问),每个人都能够创建一个账户(通过 OpenID)并创建/发布自己的爬取列表和统计视图。
将涵盖哪些类型的统计数据?这实际上非常开放。任何基于网页的 HTML 和 CSS 内容的统计数据都可以涵盖。每个用户都可以设置其他统计数据进行确定。预定义的统计数据包括:
- 元素数量 (HTML)
- 规则数量 (HTML)
- 响应时间 (HTML)
- 解析时间 (HTML, CSS)
- 元素百分比 (
div,p, ...) - 样式规则百分比
- HTML 中的最大层级
- 信息(文本)与文档大小(HTML)之比。
- 图片数量 (HTML)。
- 链接数量 (HTML)。
- 不同颜色数量 (CSS)。
- 以及更多更多 ...
还将有一些跨所有条目的统计数据,例如 CSS 类名的百分比(可能某个名称比其他名称更常见)或最常见的媒体查询。
理论上(尽管这在竞赛期间实现的几率很低),我还可以通过标签目录扩展数据库,从而能够搜索已爬取的内容。
我将如何应对挑战?我将从一个前端开始,它显示一个网页并包含所有必需的内容。下一步,我将创建基于 SQL 的关系数据库并将其与网页连接起来。现在是时候设置主工作器以及 MongoDB 数据库了。主工作器将处理联合爬取列表(当然,是所有爬取列表的统一,具有不同的条目)并将工作分配给其他工作(负载均衡和可伸缩性)。
在最后一步,我将完善 API 并创建一个移动访问体验,该体验允许离线查看统计数据,并启用通知等更多功能。
挑战
在本节中,我将讨论我如何体验(并希望能克服)各种挑战。我将展示代码、屏幕截图以及我在云端之路上发现的有用资源。
第一个挑战:入门
这很容易,因为我只需点击链接(上面或挑战页面上给出的)并升级到我的 MSDN Azure 订阅。一切顺利,我的账户在 2 分钟内就激活了。
Azure 如何受益或改变我今天做事的方式
Windows Azure 使我摆脱了固定硬件或软件设置等限制(如果我需要更多计算能力——我能得到;如果我需要运行 Linux 来使用这个救命工具——我启动一个 Linux VM)。Azure 为像 WebState 这样可扩展的数据驱动应用程序提供内存和计算能力。
第二个挑战:构建一个网站
在 Windows Azure 上编写和部署网页有多种方法。其中最好的方法之一是使用 ASP.NET MVC。一方面,我们可以使用最先进、最舒适的语言 C# 编写网页,另一方面,我们可以获得 Microsoft Visual Studio 提供的最佳工具。
我决定选择使用 ASP.NET MVC 4 的单页应用程序。选择它有多个原因:
- 我们获得了许多我们无论如何都会使用的功能,并且已经集成。工作量更少!
- 页面的一部分大量使用了 API,就像此项目模板中提供的 ToDo 示例(样板)一样。
- OAuth 已包含在内,并且提供的代码优先数据库模型与我们的目标非常接近。
- 包含 Knockout.js,使 API 驱动元素的 MVVM 绑定变得容易
- Web API 已包含在内,并有一个专门区域显示 API 使用帮助
总而言之,如果我们选择单页应用程序项目模板,我们将获得许多好处,这在此情况下极大地提高了我们的开发速度。
使用 OAuth
我首先要做的就是重新配置一些默认设置。我从 App_Start 文件夹中的 AuthConfig.cs 开始。此文件中定义的类在启动时用于执行一些 OAuth 配置。我的代码如下所示:
public static void RegisterAuth()
{
OAuthWebSecurity.RegisterGoogleClient();
OAuthWebSecurity.RegisterMicrosoftClient(
clientId: /* ... */,
clientSecret: /* ... */);
OAuthWebSecurity.RegisterTwitterClient(
consumerKey: /* ... */,
consumerSecret: /* ... */);
OAuthWebSecurity.RegisterYahooClient();
}
为了获取这些代码,我必须在 Microsoft 和 Twitter 的开发者服务上注册网页。幸运的是,ASP.NET 网页上有一份文档,其中包含这些服务的直接链接。
在 Twitter 开发者主页上进行注册看起来像这样:
在微软主页上,过程也相当类似,但在我看来,侵扰性较小。这里我的输入在网页上产生了以下输出:

现在一切都已为 OAuth 设置好,我准备好修改提供的模型。竞赛的这一部分尚未涉及数据库(我们仍然缺少 VM,因此尚无工作程序可生成统计数据),但是,我们仍然可以以代码优先的方式完成整个关系映射。这将使用 Microsoft SQL Express 数据库进行部署,我们无需过多担心。
代码优先与 Entity Framework
正如已经说过的,在比赛的这一部分,我们还不关心真实的统计数据、MongoDB(这将是下一个挑战的一部分,与 Microsoft SQL 一起)或在一个或多个工作器实例中爬取数据。
让我们看看为一些统计/视图工作准备的模型。

基本上,每个用户可以拥有多个视图。每个视图可以分配一个唯一的 API 密钥,或者只是相同的。API 密钥仅用于外部(即 API)访问 - 如果用户已登录,他总是可以访问其视图(即使是受限视图)。
每个视图都有多个统计项,即描述从给定爬取列表中获取何种统计数据的数据。此数据将用类似 SQL 的语言描述。此概念背后还有很多内容,但我将在下一节介绍 MongoDB 和第四节介绍工作器/VM 时解释其中一部分。在这里,我只想指出,爬取条目也存在于 MongoDB 中,其中包含每个爬取项的统计字段。这基本上是给定爬取项的所有统计字段的并集。我们将看到 MongoDB 将非常适合生成的数据类型。
每个用户还可以管理爬取列表。他可以创建新的爬取列表或使用现有(公共或他自己的私有)爬取列表。他还可以基于现有(公共或他自己的私有)爬取列表创建新的爬取列表。
由于没有工作程序(也没有 MongoDB 形式的文档存储),并且所有数据都高度依赖于工作程序,因此网页中最动态的部分将暂时保持禁用状态。
部署到 Windows Azure
登录 Windows Azure 管理中心后,我们只需点击屏幕底部的新建。现在我们可以转到网页,然后选择快速创建。输入 URL 即可开始设置实际网页

设置过程可能需要几秒钟。在网页创建过程中会显示加载动画。网页创建完成后,我们可以返回 Visual Studio 并部署我们的应用程序。

为了高效地完成此操作,我们从 Windows Azure 管理中心下载一个生成的发布配置文件,并将其导入 Visual Studio。我们也可以通过在门户中设置部署凭据,然后通过任何 FTP 客户端将应用程序推送到 Windows Azure,直接通过 FTP 发布 Web 应用程序,但是,考虑到我们已经在使用 Visual Studio,为什么不选择更简单的方式呢?
最后,一切就绪!我们可以在 Visual Studio 中右键单击项目,选择发布,然后在该对话框中选择导入下载的发布配置文件

非常重要的是,所有内容,即用于 Web API 文档的生成 XML 文件,都必须包含在项目中。如果文件只是放置在(正确的)目录中,它将不会被发布。只有包含在项目中的文件才会被发布。当然,对于图像等内容文件也是如此。
彩蛋!
我不会公布真正的彩蛋(这并不难发现),但我想要宣布一个我制作的小彩蛋。如果你打开网页的源代码,你会看到一个注释,里面显示了一些 ASCII 艺术图形,那就是……CodeProject 的 Bob(你猜对了)!
关于响应式设计:目前整个网页都是以桌面优先的方式创建的。这是一个统计主页,旨在用于专业用途——而不是仅仅消费数据。最后一个挑战将把公共统计数据转化为对移动设备非常有用的东西。这将是样式表扩展和操作,以及 ASP.NET MVC 4 的一些功能(如用户代理检测)大放异彩的地方。
有用的资源
当然,有一些有用的网页提供了关于 ASP.NET MVC (4) 网页、在 Azure 上部署网页或其他方面的一些有趣技巧。我发现以下资源非常有用:
第三个挑战:在 Azure 上使用 SQL
我已经在上一个挑战中创建了一个 SQL 数据库——只是为了支持网页上的登录功能。在本节中,我将扩展数据库,执行额外的配置并安装 MongoDB。
我们从安装 MongoDB 开始。MongoDB 将是整个解决方案的文档存储。如果仍不清楚为什么项目使用 MongoDB,那么以下论点列表可能会有所帮助:
- 内置高可用性
- 内置数据复制和持久性
- 我们可以按需扩展
- 我们可以按需横向扩展
- 轻松度过实例重启
- 与 Azure 诊断集成
对于 Windows Azure,我们正在使用标准的 MongoDB 二进制文件。这些二进制文件的代码是开源的。当 MongoDB 工作程序启动时,我们必须执行以下停止操作:
- 我们必须注册更改通知器
- 我们应该挂载存储(blob)
- 启动 MongoDB 服务 (mongod)
- 我们必须运行 cloud 命令
当然,我们还需要执行一些步骤来停止服务
- 我们必须下台
- 我们应该停止服务 mongod
- 最后,我们必须卸载 blob
挑战存在于各个领域。例如,调试并不那么容易。此外,由于我们没有固定的分配机器(这也是云计算的优势),IP 可能会在重启时发生变化。使多组配置保持同步也不是那么容易。
幸运的是,有一个运行良好的模拟器。在这里,云存储被模拟为本地挂载的驱动器。部署 MongoDB 时,我们必须执行以下步骤。
- 创建存储帐户(获取密钥)
- 创建服务
- 在解决方案中指定存储帐户(密钥)
如今,大部分工作都已自动化。我们唯一需要做出的决定是,我们是要部署到平台即服务 (PaaS) 还是基础设施即服务 (IaaS)。在第一种情况下,我们可以选择将其安装在 Windows 虚拟机或 Linux 虚拟机上。在第二种情况下,我们根本无需关心!
为了使用 Windows Azure 命令行工具以及以 MongoDB 的形式安装 VM,我们需要一个包含我们发布设置的文件。这可以从 Windows Azure 网页 (windows.azure.com/download/publishprofile.aspx) 获取。

显然(从程序员的角度来看),IaaS 和 PaaS 之间的选择无关紧要。因此,我们选择 PaaS 解决方案,因为有一个很棒的(但正如我们将看到的可能已过时的?)安装程序工具可用,并且我们可以(稍后)根据我们的需求调整操作系统。即将进行的操作系统调整是一个重要的点,因为它们将使我们能够与正在运行的服务建立更直接的连接。我们将能够克隆完整的 VM,而不是在多个配置上摸索。安装程序是一个命令行实用程序(powershell 脚本),必须以管理员身份运行。

为了运行该脚本,我们还需要降低执行 (powershell) 脚本的限制。通常情况下,这限制得很严格。通过使用 Set-ExecutionPolicy 命令,我们可以在安装期间将其设置为 Unrestricted(允许所有脚本运行,即不需要证书或明确权限)。当前值可以通过使用 Get-ExecutionPolicy 命令获取。
然而,有光的地方也有影。问题在于安装程序依赖于 node.js 和(提供的)JavaScript 文件。显然,安装程序的作者并不关心正确的版本,就像 npm 的作者通常不关心一样。尽管版本概念已融入其中,但通常依赖项都是以最新版本下载的。这是一个巨大的问题,因为以下语句无法再执行:
var azure = require(input['lib'].value + '/azure');
var cli = require(input['lib'].value + '/cli/cli');
var utils = require(input['lib'].value + '/cli/utils');
var blobUtils = require(input['lib'].value + '/cli/blobUtils');
因此脚本无法执行,并在此处失败

问题是包 azure-cli 的依赖包 (azure) 发生了很大的变化。最后我搜索了所需的等价物,然后(出于懒惰)直接将完整路径复制到 require 参数中
var azure = require('.../azure-cli/node_modules/azure/lib/azure');
var cli = require('.../azure-cli/lib/cli');
var utils = require('.../azure-cli/lib/util/utils');
var blobUtils = require('.../azure-cli/lib/util/blobUtils');
经过修改后,脚本现在按预期工作,我们终于可以进入下一步了!

本次安装不使用副本。当页面增长时,这些副本很可能会派上用场。这提供了快速修改访问,同时具有更快且负载平衡的读取访问。此外,系统更加健壮,数据丢失的失败可能性更小。处理副本集时将遵循以下方案。

在我们了解我们的 Web 应用如何与刚创建的 MongoDB 实例交互之前,我们应该先看看如何在 Windows Azure 上创建(真实的)SQL 数据库。添加数据库本身的过程相当简单。
我们首先登录 Windows Azure 管理网页。然后我们只需点击“新建”,并选择“数据服务”、“SQL 数据库”。现在我们可以导入之前导出的 SQL 数据库,使用自定义选项创建数据库,或者使用默认选项快速创建数据库。
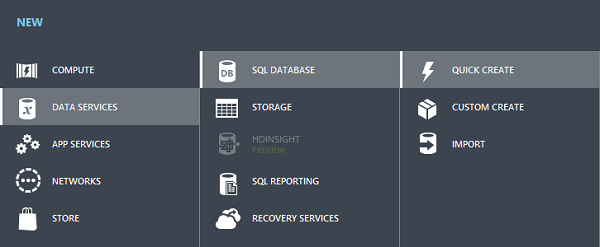
通常选择快速创建选项就足够了。在我们的例子中,我们只需要一个持久存储用户数据的地方,这正是标准 SQL 数据库非常适合的情况之一。我们的数据完美地符合预定义的方案,并且使用 Entity Framework ORM,我们无需过多关心 SQL 管理。
然而,除了使用 SQL Management Studio 或类似工具的传统方式外,我们还可以通过 Windows Azure 网页管理我们的数据库。已经创建了一个 silverlight 插件,它允许我们执行所有必要的管理。当我们点击“管理”时,首先会要求我们为当前 IP 创建一个防火墙规则。我们可以安全地这样做,但(稍后)应该删除此规则。
创建此防火墙规则可能需要几分钟。规则创建完成后,我们可以登录 SQL 管理区域。

在这里,我们可以创建、编辑或删除存储过程、表和视图。数据库管理员的大部分任务都可以通过这个 Silverlight 插件完成。网页发布后,我们数据库表的快速视图如下:

总而言之,一切都通过 Visual Studio 中的发布代理程序设置完成。我们所要做的就是输入我们刚创建的数据库的连接字符串并测试连接。然后,此连接将自动用于部署。所需的表将自动生成,一切都将根据 Entity Framework 检测到的规则进行设置。
在下一个挑战中,我们将设置工作程序并连接 MongoDB 和我们工作程序之间的通信。我们的工作程序还需要与 SQL 数据库通信,这也将在讨论之列。
目前,Web 应用程序的状态是用户可以注册、登录(或注销)、更改密码或关联账户。数据已以虚拟形式呈现。在下一阶段,我们将完成大部分工作,允许用户创建自己的爬取列表和视图。我们还将集成工作程序,它是我们应用程序的基石。
有用的资源
- 用于部署到 Azure 的 MongoDB 解决方案/包
- 在 Azure 上安装 MongoDB 的教程
- 部署 MongoDB 工作角色
- 在 Azure 上使用 MongoLab 形式创建带 MongoDB 网页的教程
- 将 MongoDB 与官方 C# 驱动程序一起使用
- Windows Azure 上 SQL 的性能
- 如何在 .NET 应用程序中使用 Windows Azure SQL 数据库
第四个挑战:虚拟机
原则上,上一个挑战也设置了一个虚拟机(也就是说,目前已经有一个虚拟机在运行)。然而,挑战不仅仅是设置一个虚拟机。因此,在这些段落中,我将详细介绍什么是虚拟机,我们如何通过创建一个虚拟机来获益,以及我们如何创建一个虚拟机。最后几段将专门讨论系统配置、管理和安装我们的工作器。
但不要着急!我们将详细讨论的另一件事是工作器实际上是如何编写的以及它在做什么。毕竟,工作器可能是整个应用程序中最核心的部分,因为它创建了为 Web 应用程序提供数据的数据。因此,在讨论如何设置和使用虚拟机之后,我们将深入探讨工作器应用程序的细节。
那么让我们直接深入了解虚拟机。如果我们启动浏览器,每个人都已经启动了一种虚拟机(因此您目前已经在运行一个)。现代浏览器允许我们通过提供一组 API 来运行网页(有时也称为 Web 应用程序),这些 API 提供线程、存储、图形、网络等(操作系统提供给我们的一切)。如果我们将浏览器视为操作系统,那么我们正在用它运行一个虚拟机,因为我们知道一次只能运行一个操作系统。
这意味着任何其他操作系统都只是虚拟的。其他操作系统看到的是一种虚拟机(而不是真实的机器),因为机器是从真实硬件抽象/修改而来(但也受限于它)。那么,虚拟机到底是什么?它是一个抽象层,伪造一台机器,以便任何操作系统都可以在现有操作系统中启动。
我们已经看到这种抽象是有些昂贵的。毕竟,所有成本都必须在某个地方支付。从虚拟机中运行的系统对内存地址的每次调用都必须映射到真实的内存地址。对图形卡、USB 端口等系统资源的每次调用现在都是间接的。另一方面,有几个非常酷的好处:
- 系统非常容易沙盒化。
- 系统资源可以很容易地控制。
- 看起来像物理硬件的系统资源可能不存在,或者可能是几个组件的组合。
- 整个系统可以非常容易地复制。
- 系统可以轻松地进行监控和修改。
Windows Azure 代表着两个重要的里程碑。一方面,它是微软卓越基础设施的代名词,拥有遍布全球的(巨大)计算中心。另一方面,它是底层操作系统的名称,该操作系统专门用于管理可用的计算能力、负载平衡以及托管虚拟机。大多数计算机运行 Windows Azure,因此可以托管高度优化的虚拟机,这些虚拟机尽可能接近真实硬件。然而,它们仍然拥有虚拟机的所有优势。
这使我们能够以存储磁盘的形式附加(虚拟)硬盘,这些硬盘超出了任何可用的存储容量。诀窍在于我们在不知不觉中一次性访问 Microsoft 计算中心中的大量驱动器。
有几种方法可以创建一个新的 VM 在 Windows Azure 中运行。最简单的方法是使用 Web 界面创建一个。下图显示了如何完成此操作。

另一种(更高级的)可能性是使用命令行实用程序。以下代码片段创建一个名为 my-vm-name 的新 VM,它使用名为 MSFT__Windows-Server-2008-R2-SP1.11-29-2011 的标准镜像,用户名为 username。
azure vm create my-vm-name MSFT__Windows-Server-2008-R2-SP1.11-29-2011 username --location "Western US" -r
一切都可以通过命令行实用程序进行管理。这还使我们能够上传自己的虚拟机(以 vhd 文件格式指定)。优点是任何虚拟机都可以复制。因此,我们可以创建合适的配置,在我们自己的场所进行测试,上传它,然后将其扩展到相当多的实例。
以下代码片段从文件 Sample.vhd 创建了一个名为 mytestimage 的新 VM。
azure vm image create mytestimage ./Sample.vhd -o windows -l "West US"
回到我们创建的虚拟机,我们可能首先通过远程桌面协议(RDP)直接连接到它。我们甚至不需要打开远程桌面程序或类似的东西,因为 Windows Azure 已经包含了一个指向 *.rdp 文件的直接链接,其中将包含我们所需的配置。打开这个文件通常会产生以下警告:

可以通过安装所需的证书来关闭此警告。目前我们可以忽略它。只需继续连接到我们的虚拟机,如果输入了已安装的管理员账户的正确数据,我们最终将能够登录我们的系统。
下图显示了成功登录在 Windows Azure 上运行的我们自己的虚拟机后可以直接捕获的屏幕。

现在是时候谈谈工作程序应用程序了。该应用程序是一个简单的控制台程序。选择控制台程序的原因真的没什么好说的。事实上,它可以是一个没有任何输入或输出的服务,但屏幕上至少显示一些信息绝不是坏事。应用程序将通过复制/粘贴发布文件夹进行部署。我们可以使用 Windows RDP 客户端提供的剪贴板复制机制。
程序本身几乎和下面的代码片段一样简单:
static void Main(string[] args)
{
//Everything will run in a task, hence the possibility for cancellation
cts = new CancellationTokenSource();
/* Evaluation of arguments */
//The log function prints something on screen and logs it in the DB
Log("Worker started.");
//Connect to MongoDB using the official 10gen C# driver
client = new MongoClient("mongodb://");
server = client.GetServer();
db = server.GetDatabase("ds");
//Obviously something is wrong
if (server.State == MongoServerState.Disconnected)
{
Log("Could not connect to MongoDB.");
//Ah well, there are plenty of options but I like this one most
Environment.Exit(0);
}
Log("Successfully connected to MongoDB instance.");
//This runs the hot (running) task
var worker = Crawler.Run(db, cts.Token);
//Just a little console app
while (true)
{
Console.Write(">>> ");
string cmd = Console.ReadLine();
/* Command pattern */
}
//Make sure we closed the task
cts.Cancel();
Log("Worker ended.");
}
基本上,主函数只是连接到 MongoDB 实例并启动爬虫作为 Task。创建控制台应用程序的优点之一是可以通过命令行以相当简单和“自然”的方式与之交互。
在我们深入爬虫的核心之前,我们需要看一下整个项目最重要的库:AngleSharp。我们通过与其他所有库相同的方法获取该库:通过 NuGet。AngleSharp 的当前状态是它离完成还有很长的路要走,但是,当前状态足以在该项目中使用。

整个爬虫的核心通过调用静态的 Run 方法执行。这基本上是一个遍历所有条目的大循环。这个循环再次被包装在一个循环中,因此该过程是无限的延续。原则上,我们也可以在完成大循环后将进程设置为空闲状态,直到满足特定条件。例如,该条件可以是每天只处理一次大循环,即条件是起始日期与当前日期不同。
让我们看看 Run 方法。
public class Crawler
{
public static async Task Run(MongoDatabase db, CancellationToken cancel = new CancellationToken())
{
//Flag to break
var continuation = true;
//Don't consume too many (consecutive) exceptions
var consecutivecrashes = 0;
//Initialize a new crawler
var crawler = new Crawler(db, cancel);
Program.Log("Crawler initialized.");
//Permanent crawling
do
{
//Get all entries
var entries = db.GetCollection<CrawlEntry>("entries").FindAll();
//And crawl each of them
foreach (var entry in entries)
{
try
{
//Alright
await crawler.DoWork(entry);
//Apparently no crash - therefore reset
consecutivecrashes = 0;
}
catch (OperationCanceledException)
{
//Cancelled - let's stop.
continuation = false;
break;
}
catch (Exception ex)
{
//Ouch! Log it and increment consecutive crashes
consecutivecrashes++;
Program.Log("Crawler crashed with " + ex.Message + ".");
//We already reached the maximum number of allowed crashes
if (consecutivecrashes == MAX_CRASHES)
{
continuation = false;
Program.Log("Crawler faced too many (" + consecutivecrashes.ToString() + ") consecutive crashes.");
break;
}
continue;
}
}
}
while (continuation);
Program.Log("Crawler ended.");
}
/* Crawler Instance */
}
这里没什么特别的。该方法创建爬虫类的新实例并执行异步的 DoWork 方法。此方法依赖于 MonogoDB 数据库实例、其他一些类成员和一个静态变量。静态变量被标记为 ThreadStatic,以便多个内核在不相互干扰的情况下运行。
[ThreadStatic]
Stopwatch timer;
async Task DoWork(CrawlEntry entry)
{
//Init timer if not done for this thread
if(timer == null)
timer = new Stopwatch();
cancel.ThrowIfCancellationRequested();
//Get response time for the request
timer.Start();
var result = await http.GetAsync(entry.Url);
var source = await result.Content.ReadAsStreamAsync();
timer.Stop();
cancel.ThrowIfCancellationRequested();
var response = timer.Elapsed;
//Parse document
timer.Restart();
var document = DocumentBuilder.Html(source);
timer.Stop();
//Save the time that has been required for parsing the document
var htmlParser = timer.Elapsed;
cancel.ThrowIfCancellationRequested();
//Get the stylesheets' content
var stylesheet = await GetStylesheet(document);
cancel.ThrowIfCancellationRequested();
//Parse the stylesheet
timer.Restart();
var styles = CssParser.ParseStyleSheet(stylesheet);
timer.Stop();
var cssParser = timer.Elapsed;
cancel.ThrowIfCancellationRequested();
//Get all elements in a flat list
var elements = document.QuerySelectorAll("*");
//Get the (original) html text
var content = await result.Content.ReadAsStringAsync();
cancel.ThrowIfCancellationRequested();
//Build the entity
var entity = new DocumentEntry
{
SqlId = entry.SqlId,
Url = entry.Url,
Content = content,
Created = DateTime.Now,
Statistics = new BsonDocument(),
Nodes = new BsonDocument(),
HtmlParseTime = htmlParser.TotalMilliseconds,
CssParseTime = cssParser.TotalMilliseconds,
ResponseTime = response.TotalMilliseconds
};
//Perform the custom evaluation
EvaluateNodes(entity.Nodes, elements);
EvaluateStatistics(entity.Statistics, document, styles);
timer.Reset();
//Add to the corresponding MongoDB collection
AddToCollection(entity);
}
在 EvaluateNodes 和 EvaluateStatistics 方法背后也存在某种魔力。目前,这些函数将不进行详细讨论。这两个函数基本上是评估生成的 DOM 和样式表。在这里,我们使用一种 DSL,用于执行任何注册用户可以输入的自定义评估。
工作程序程序的输出显示在下一张图片中。

工作器使用一种“神奇的”命令行程序来打印带有信息的新行,同时不干扰当前用户输入。为了实现这一点,Log 方法调用 MoveBufferArea 方法。在下面的(简化)版本中,我们只是将缓冲区区域移动一行,但是,有时需要多于一行才能容纳新消息。
public static void Log(string msg)
{
var left = Console.CursorLeft;
var top = Console.CursorTop;
Console.SetCursorPosition(0, top);
Console.MoveBufferArea(0, top, Console.BufferWidth, 1, 0, ++top);
var time = DateTime.Now;
Console.WriteLine("[ {0:00}:{1:00} / {2:00}.{3:00}.{4:00} ] " + msg,
time.Hour, time.Minute, time.Day, time.Month, time.Year - 2000);
Console.SetCursorPosition(left, top);
}
至此,关于工作器的讨论结束。在下一节中,我们将继续开发网页,最终允许用户创建自己的爬取列表并设置自己的统计数据。
第五个挑战:移动访问
本节即将推出。
兴趣点
我对 Windows Azure 平台很感兴趣已经很长时间了。这次比赛终于给了我尝试和更好地了解它的机会。我喜欢 Scott Guthrie 管理这个团队,因为他不仅是一位出色的演讲者,而且对技术充满热情,并且非常热衷于创造令人惊叹的产品。我建议任何对 ASP.NET(历史)或当前 Windows Azure 动态感兴趣的人查看官方博客:weblogs.asp.net/scottgu/。
历史
- v1.0.0 | 首次发布 | 2013年4月27日
- v1.1.0 | 第二个挑战完成 | 2013年5月12日
- v1.1.1 | 文章顶部添加链接 | 2013年5月17日
- v1.2.0 | 第三个挑战完成 | 2013年5月26日
- v1.3.0 | 第四个挑战完成 | 2013年6月9日