
AngleSharp
5.00/5 (85投票s)
使用C#编写的HTML5/CSS3解析器,将DOM引入C#。
![]()
目录
引言
如今,一切都围绕着网络。我们总是在下载或上传某些数据。我们的应用程序也越来越频繁地进行通信,因为用户希望同步他们的数据。另一方面,更新过程越来越直接,通过将应用程序的易变部分放在云端。
整个网络运动不仅仅伴随着二进制数据。这种运动主要是由 HTML 推动的,因为大多数输出最终将呈现为一种被称为 HTML 的描述代码。这种描述语言由两个不错的补充进行装饰:以 CSS3 形式的样式(又一种描述语言)和以 JavaScript 形式的脚本(官方指定为 ECMAScript)。
这种不可阻挡的趋势已经持续了十多年。如今,拥有一个设计精良的网页是任何公司的基石。好的一点是 HTML 非常简单,即使是没有编程知识的人也可以创建一个页面。最简单的近似方法就是我们在文件中插入一些文本,然后在浏览器中打开它(可能是在我们重命名文件为 *.html* 之后)。
长话短说:即使在我们的应用程序中,我们也可能需要与 Web服务器通信来提供一些 HTML。这都没问题,并且已经由框架解决了。我们有强大的类来处理整个通信,了解所需的 TCP 和 HTTP 操作。然而,一旦我们需要对文档进行一些操作,我们就基本束手无策了。这时 **AngleSharp** 就派上用场了。
背景
AngleSharp 的想法在大约一年前诞生(我将在接下来的段落中解释为什么 AngleSharp 超越了 *HtmlAgilityPack* 或类似解决方案)。使用 AngleSharp 的主要原因实际上是能够像在浏览器中一样访问 DOM。唯一的区别是,在这种情况下,您将使用 C#(或任何其他 .NET 语言)。还有一个区别(按设计),它将属性和方法的名称从驼峰式转换为帕斯卡式(即首字母大写)。
因此,在我们深入了解实现细节之前,我们需要看看 AngleSharp 的长期目标。实际上,有几个目标:
- HTML、XML、SVG、MathML 和 CSS 的解析器
- 创建 CSS 样式表/样式规则
- 返回文档的 DOM
- 对 DOM 进行修改
- * 提供可能渲染器的基础
核心解析器无疑是由 HTML5 解析器提供的。CSS4 解析器是一个自然的补充,因为 HTML 文档包含样式表引用和 style 属性。拥有另一个符合当前 W3C 规范的 XML 解析器是一个不错的补充,因为 SVG 和 MathML(也可能出现在 HTML 文档中)可以作为 XML 文档进行解析。唯一的区别在于生成的文档,它具有不同的语义并使用不同的 DOM。
第二个 * 点非常有趣。这个想法并非要用 C# 完全构建一个浏览器(不过,这也不是不可能)。其动机在于创建一个新的、跨平台的 UI 框架,该框架使用 HTML 作为描述语言,并使用 CSS 进行样式设计。当然,这是一个相当宏伟的目标,并且肯定不会只通过这个库来解决,但是,这个库将在创建这个框架的过程中发挥重要作用。
在接下来的几节中,我们将逐步介绍创建 HTML5 和 CSS4 解析器过程中一些重要的步骤。
HTML5 解析器
编写 HTML5 解析器比大多数人想象的要困难得多,因为 HTML5 解析器必须处理比这些尖括号多得多的内容。主要问题是,许多不明确定义的文档/文档片段会出现大量边缘情况。此外,格式化并不像看起来那么简单,因为某些标签需要与其他标签区别对待。
总而言之,没有官方规范也可以编写这样的解析器,但要么必须了解所有边缘情况(并设法将其编入代码或写在纸上),要么解析器将只能处理一小部分网页。
在这里,规范提供了极大的帮助,并为我们提供了所有可能的变体以及每种可能的突变。主要工作流程非常简单:我们从一个 Stream 开始,该 Stream 可以直接来自本地计算机的文件、来自网络的数据或已有的 string。这个 Stream 被交给预处理器,预处理器将控制从 Stream 读取的流程并缓冲已读取的内容。
最后,我们可以将一些数据交给分词器,分词器将预处理器的数据转换为一系列有用的对象。然后使用这些临时对象来构造 DOM。在构建树的过程中,可能需要多次切换分词器的状态。
下图显示了用于解析 HTML 文档的通用方案。

在接下来的几节中,我们将逐步介绍 HTML5 解析器实现中最重要 parts。
分词
拥有一个可工作的流预处理器是任何分词过程的基础。分词过程是构建树的基础,正如我们将在下一节中看到的。分词过程究竟做了什么?分词过程将输入流预处理器处理过的字符转换为所谓的“标记”。这些标记是对象,然后用于构建将成为 DOM 的树。在 HTML 中,标记的种类不多。事实上,我们只有少数几种:
- 标签(包含名称、开/闭标志、标签的属性和自闭合标志)
- 文档类型(包含附加属性)
- 字符(包含字符负载)
- 注释(包含文本负载)
- 文件结束
分词器的状态机实际上相当复杂,因为有许多(遗留)规则需要遵守。此外,有些状态不能仅从分词器进入。与大多数解析器相比,这也是 HTML 的一种特殊情况。因此,分词器必须对更改开放,这些更改通常由树构造器启动。
最常用的标记是字符标记。因为我们可能需要区分单个字符(例如,如果我们进入一个 <pre> 元素,则必须忽略开头的换行符),所以我们必须返回单个字符标记。初始分词器状态是 PCData 状态。该方法与其简单性一样:
HtmlToken Data(Char c)
{
switch (c)
{
case Specification.AMPERSAND:
var value = CharacterReference(src.Next);
if (value == null) return HtmlToken.Character(Specification.AMPERSAND);
return HtmlToken.Characters(value);
case Specification.LT:
return TagOpen(src.Next);
case Specification.NULL:
RaiseErrorOccurred(ErrorCode.NULL);
return Data(src.Next);
case Specification.EOF:
return HtmlToken.EOF;
default:
return HtmlToken.Character(c);
}
}
有些状态无法从 PCData 状态进入。例如,Plaintext 或 RCData 状态永远无法仅通过分词器进入。此外,Plaintext 状态永远无法离开。当 HTML 树构建检测到例如 <title> 或 <textarea> 元素时,将进入 RCData 状态。另一方面,我们还有一个 Rawtext 状态,它可以通过例如 <noscript> 元素调用。我们已经可以看到状态和规则的数量比我们最初想象的要大得多。
分词器(以及库中的其他分词器/解析器)一个相当重要的助手是 SourceManager 类。这个类处理输入的(字符)数据流。其定义如下所示。

这个助手或多或少是一个 Stream 处理程序,因为它接收一个 Stream 实例并使用检测到的编码读取它。在读取过程中也可以更改编码。将来,这个类可能会发生变化,因为到目前为止,它基于 TextReader 类来读取具有给定 Encoding 的文本数据流。将来,最好使用自定义类来处理,该类开箱即用支持以不同编码向后读取。
树构建
一旦我们拥有了工作的标记流,我们就可以开始构建 DOM。我们需要照顾几个列表:
- 当前打开的标签。
- 活动的格式化元素。
- 特殊标志。
第一个列表很明显。由于我们将打开包含其他标签的标签,因此我们需要记住我们沿着路径走了多远。第二个列表不那么明显。可能会出现当前打开的元素对插入的元素具有某种格式效果。这些元素被认为是格式化元素。一个很好的例子是 <b> 标签(粗体)。一旦应用,所有*包含的元素都会显示粗体文本。有一些例外(*),但这就是 HTML5 变得不那么简单的地方。
第三个列表实际上非常复杂,没有官方规范就无法重建。在某些场景下,某些元素有特殊情况。这就是为什么 HTML5 解析器区分 <body>、<table>、<select> 和其他几个部分。这种区分也是确定是否需要自动插入某些元素所必需的。例如,以下片段会自动转换:
<pre contenteditable>
HTML 解析器不将 <pre> 标签识别为 <html> 或 <body> 标签之前的合法标签。因此,会初始化一个回退机制,该机制首先插入 <html> 标签,然后是 <body> 标签。将 <body> 标签直接插入 <html> 标签内还会创建一个(空的)<head> 元素。最后,在文件末尾,所有内容都会关闭,这意味着我们的 <pre> 节点也会如期关闭。
<html>
<head/>
<body>
<pre contenteditable=""></pre>
</body>
</html>
存在一些非常棘手的边缘情况,非常适合测试树构造器的状态。以下是一个很好的测试,用于确定“海森堡算法”是否工作正常,以及在表和锚标签使用不规范时是否被调用。在插入另一个锚元素时应调用它。
<a href="a">a<table><a href="b">b</table>x
生成的 HTML DOM 树如下面的代码片段所示(不包含 <html>、<body> 等标签)
<a href="a">
a
<a href="b">b</a>
<table/>
</a>
<a href="b">x</a>
这里我们看到字符 *b* 被从 <table> 中取出。因此,超链接必须在表格之前开始,并在之后继续。这导致锚标签重复。总而言之,这些转换是非平凡的。
表格会导致一些边缘情况。大多数边缘情况是由于表格内文本没有单元格环境造成的。以下示例对此进行了说明:
A<table>B<tr>C</tr>D</table>
这里有一些文本没有 <td> 或 <th> 父级。结果如下:
ABCD
<table>
<tbody>
<tr/>
</tbody>
</table>
整个文本被移到了实际的 <table> 元素之前。此外,由于我们定义了一个 <tr> 元素,但没有 <tbody>、<thead> 或 <tfoot>,因此会插入一个 <tbody> 部分。
当然,事情比看起来要复杂得多。大量的 HTML5 有效解析工作涉及错误校正和构建表格。此外,格式化元素还必须满足某些规则。任何对细节感兴趣的人都应该看看代码。尽管代码可能不如常规 LOB 应用程序代码可读,但通过适当的注释和插入的区域,仍然应该可以阅读。
测试
集成单元测试是一个非常重要的点。由于解析器设计复杂,大部分工作并非通过 TDD 范例来完成,但在某些部分,测试是在编写任何代码行之前就已放置好的。总而言之,放置各种单元测试非常重要。HTML 解析器的树构造器是测试库的主要目标之一。
DOM 对象也经过了单元测试。这里的主要目标是确保这些对象按预期工作。这意味着错误只会在定义的非法操作上抛出,并且集成的绑定功能是可用的。在解析过程中,此类错误永远不应发生,因为树构造器预计永远不会尝试非法操作。
使用 *AzureWebState* 项目设置了另一个测试环境,该项目旨在从数据库中抓取网页。这使得很容易发现解析器中的严重问题(如 StackOverflowException 或 OutOfMemoryException)或潜在的性能问题。
可靠性测试不是我们唯一关心的测试类型。如果我们为了获得解析结果而等待太长时间,我们可能会遇到麻烦。现代网页浏览器处理网页通常需要 1 毫秒到 100 毫秒。因此,任何超过 100 毫秒的都需要进行优化。幸运的是,我们有一些很棒的工具。Visual Studio 2012 提供了一个很棒的性能分析工具,但对我来说,在某些场景下 **PerfView** 是最佳选择(它可以在整个机器上运行,并且独立于 VS)。

快速查看内存消耗会为我们提供一些指标,表明我们可能需要做一些事情来分配所有那些 HtmlCharacterToken 实例。在这里,一个字符标记池已经非常有益了。然而,首次测试表明,对性能(处理速度方面)的影响可以忽略不计。
CSS4 解析器
市面上已经有一些 CSS 解析器,有些是用 C# 编写的。然而,大多数解析器只是进行非常简单的解析,而不评估选择器或忽略特定属性或值的特定含义。此外,大多数解析器都远低于 CSS3 标准,或者根本不支持任何 @-规则(如 namespace、import 等)。
由于 HTML 使用 CSS 作为其布局/样式语言,因此将 CSS 直接集成进来是很自然的。在几个地方已证明这非常有益:
- 对于
QuerySelector等方法,需要选择器。 - 每个元素都可以有一个
style属性,该属性具有非字符串的 DOM 表示。 - 样式表被 DOM 直接考虑。
<style>元素对 HTML 解析器具有特殊含义。
目前外部样式表不会被直接解析。原因很简单:AngleSharp 应该需要最少的外部引用。在最理想的情况下,AngleSharp 应该易于移植(甚至可以作为可移植类库存在)(“Metro”、“Windows Phone”和“WPF”之间的交集)。目前这可能不可行,因为在某些地方使用了 TaskCompletitionSource,但这就是为什么整个库没有到处都装饰 Task 实例甚至 await 和 async 关键字的原因。
分词
CSS 分词器不像 HTML 分词器那么复杂。使 CSS 分词器有些复杂的是它必须处理更多类型的标记。在 CSS 分词器中,我们有:
- 字符串(单引号或双引号)
- URL(
url()函数中的字符串) - 哈希(通常用于选择器,如 #abc 或类似,通常不是用于颜色)
- AtKeyword(用于 @-规则)
- Ident(任何标识符,即用于选择器、说明符、属性或值)
- 函数(函数主要出现在值中,有时也出现在规则中)
- 数字(任何数字,如 5 或 5.2 或 7e-3)
- 百分比(一种特殊的维度值,例如 10%)
- 维度(任何尺寸数,例如 5px、8em 或 290deg)
- 范围(范围值创建 Unicode 值范围)
- Cdo(一种特殊的开式注释,即
<--) - Cdc(一种特殊的闭式注释,即
-->) - Column(个人我从未在 CSS 中见过:
||) - Delim(任何分隔符,如逗号或单个哈希)
- IncludeMatch(属性选择器中的包含匹配
~=) - DashMatch(属性选择器中的破折号匹配
|=) - PrefixMatch(属性选择器中的前缀匹配
^=) - SuffixMatch(属性选择器中的后缀匹配
$=) - SubstringMatch(属性选择器中的子字符串匹配
*=) - NotMatch(属性选择器中的不匹配
!=) - RoundBracketOpen 和 RoundBracketClose
- CurlyBracketOpen 和 CurlyBracketClose
- SquareBracketOpen 和 SquareBracketClose
- Colon(冒号在属性中分隔名称和值)
- Comma(用于分隔各种值或选择器)
- Semicolon(主要用于结束声明)
- Whitespace(大多数空格仅用于分隔目的 - 在选择器中有意义)
CSS 分词器是一个简单的基于流的分词器,它返回一个标记的迭代器。然后可以使用这个迭代器。CssParser类中的每个方法都接受这样的迭代器。使用迭代器的巨大优点是我们基本上可以使用任何标记源。例如,我们可以使用另一个方法基于第一个迭代器生成第二个迭代器。此方法仅迭代一个子集(例如某些大括号内的内容)。巨大优点是两者都前进流,但我们不必进行非常复杂的标记管理。
因此,追加规则就像以下代码片段一样简单:
void AppendRules(IEnumerator<CssToken> source, List>CSSRule> rules)
{
while (source.MoveNext())
{
switch (source.Current.Type)
{
case CssTokenType.Cdc:
case CssTokenType.Cdo:
case CssTokenType.Whitespace:
break;
case CssTokenType.AtKeyword:
rules.Add(CreateAtRule(source));
break;
default:
rules.Add(CreateStyleRule(source));
break;
}
}
}
这里我们只是忽略一些标记。在 @-keyword 的特殊情况下,我们启动一个新的 @-rule,否则我们假设必须创建一个样式规则。正如我们所知,样式规则以选择器开头。有效的选择器对可能的输入标记施加了更多限制,但通常接受任何标记作为输入。
我们经常想跳过任何空白符,以便从当前位置移动到下一个位置。以下代码片段允许我们做到这一点:
static Boolean SkipToNextNonWhitespace(IEnumerator<CssToken> source)
{
while (source.MoveNext())
if (source.Current.Type != CssTokenType.Whitespace)
return true;
return false;
}
此外,我们还获取了是否到达标记流末尾的信息。
样式表创建
然后使用所有信息创建样式表。目前,像 CSSNamespaceRule 或 CSSImportRule 这样的特殊规则会被正确解析但随后被忽略。这将来必须在某个时候集成。
此外,我们只得到一个非常通用(且无意义)的属性,称为 CSSProperty。将来,通用属性将仅用于未知(或过时)的声明,而将使用更专业的属性来处理有意义的声明,如 color: #f00 或 font-size: 10pt。这还将影响值的解析,必须考虑所需的输入类型。
另一点是 CSS 函数(url() 除外)尚未包含。然而,这些非常重要,因为 toggle() 和 calc() 或 attr() 函数如今越来越常用。此外,rgb() + rgba() 和 hsl() + hsla() 或其他函数是强制性的。
一旦我们遇到一个 at-rule,我们基本上就需要为特殊规则解析特殊情况。以下代码片段描述了这一点:
CSSRule CreateAtRule(IEnumerator<CssToken> source)
{
var name = ((CssKeywordToken)source.Current).Data;
SkipToNextNonWhitespace(source);
switch (name)
{
case CSSMediaRule.RuleName: return CreateMediaRule(source);
case CSSPageRule.RuleName: return CreatePageRule(source);
case CSSImportRule.RuleName: return CreateImportRule(source);
case CSSFontFaceRule.RuleName: return CreateFontFaceRule(source);
case CSSCharsetRule.RuleName: return CreateCharsetRule(source);
case CSSNamespaceRule.RuleName: return CreateNamespaceRule(source);
case CSSSupportsRule.RuleName: return CreateSupportsRule(source);
case CSSKeyframesRule.RuleName: return CreateKeyframesRule(source);
default: return CreateUnknownRule(name, source);
}
}
让我们看看 CSSFontFaceRule 的解析是如何实现的。在这里,我们看到在整个过程中,我们将 font-face 规则推送到开放规则的堆栈中。这确保了每个规则都被分配了正确的父规则。
CSSFontFaceRule CreateFontFaceRule(IEnumerator source)
{
var fontface = new CSSFontFaceRule();
fontface.ParentStyleSheet = sheet;
fontface.ParentRule = CurrentRule;
open.Push(fontface);
if(source.Current.Type == CssTokenType.CurlyBracketOpen)
{
if (SkipToNextNonWhitespace(source))
{
var tokens = LimitToCurrentBlock(source);
AppendDeclarations(tokens.GetEnumerator(), fontface.CssRules.List);
source.MoveNext();
}
}
open.Pop();
return fontface;
}
此外,我们使用 LimitToCurrentBlock 方法来停留在当前大括号内。另一件事是我们重新使用 AppendDeclarations 方法来将声明追加到给定的 font-face 规则。这不是一个普遍规则,因为例如,媒体规则将包含其他规则而不是声明。
测试
一个非常重要的测试类由 CSS 选择器表示。由于这些选择器在许多场合使用(在 CSS 中、用于查询文档等),因此包含一组有用的单元测试非常重要。幸运的是,维护 Sizzle Selector 引擎(主要在 jQuery 中使用)的家伙们已经解决了这个问题。
这些测试看起来像以下三个样本:
[TestMethod]
public void IdSelectorWithElement()
{
var result = RunQuery("div#myDiv");
Assert.AreEqual(1, result.Length);
Assert.AreEqual("div", result[0].NodeName);
}
[TestMethod]
public void PseudoSelectorOnlyChild()
{
Assert.AreEqual(3, RunQuery("*:only-child").Length);
Assert.AreEqual(1, RunQuery("p:only-child").Length);
}
[TestMethod]
public void NthChildNoPrefixWithDigit()
{
var result = RunQuery(":nth-child(2)");
Assert.AreEqual(4, result.Length);
Assert.AreEqual("body", result[0].NodeName);
Assert.AreEqual("p", result[1].NodeName);
Assert.AreEqual("span", result[2].NodeName);
Assert.AreEqual("p", result[3].NodeName);
}
因此,我们将已知结果与我们评估的结果进行比较。此外,我们还关心结果的顺序。这意味着树遍历器正在做正确的事情。
DOM 实现
没有给定 HTML 源代码的对象表示,整个项目将毫无用处。显然,我们有两个选择:
- 定义我们自己的格式/对象
- 使用官方规范
由于项目目标,决定非常明确:创建的对象应具有与官方规范相同/非常相似的公共 API。因此,AngleSharp 的用户将获得几个优势:
- 对于熟悉 DOM 的人来说,学习曲线不存在。
- 从 C# 到 JavaScript 的代码移植更加简化。
- 不熟悉 HTML DOM 的用户也将学到一些关于 HTML DOM 的知识。
- 其他用户可能也会学到东西,因为一切都可以通过 Intellisense 访问。
最后一点在这里非常重要。项目付出了巨大的努力来(开始做一点)编写一些代表整个 API 和函数的合适文档。因此,枚举、属性和方法,以及类和事件都已记录在案。这意味着存在多种学习可能性。
此外,所有 DOM 对象都将用一种特殊的属性进行装饰,称为 DOMAttribute 或简单地称为 DOM。此属性可以帮助确定哪些对象(除了最常见的类型,如 String 或 Int32)可以在 JavaScript 等脚本语言中使用。在某种程度上,这整合了现代浏览器中使用的 IDL。
该属性还装饰属性和方法。一种特殊的属性是索引器。根据 W3C 的规定,大多数索引器都命名为 item,然而,由于 JavaScript 是一种支持索引器的语言,所以我们很少看到这一点。尽管如此,即使在这里也放置了装饰,这让我们选择了如何使用它。
基本的 DOM 结构显示在下图。

找到一个真正完整的参考非常困难。尽管 W3C 创建了官方标准,但它经常与自身矛盾。问题在于当前规范是 DOM4。如果我们查看任何浏览器,我们会发现要么并非所有元素都可用,要么还提供了其他元素。因此,将 DOM3 作为参考点更有意义。
AngleSharp 试图找到正确的平衡。该库包含大部分新 API(尽管并非所有功能都已实现,例如,整个事件系统或突变对象),但也包含 DOM3(或早期版本)中已实现并被所有主流浏览器使用的所有内容。
性能
整个项目在设计时都必须考虑性能,然而,这意味着有时可能会发现一些不太优美的代码。此外,一切都尽可能贴近规范进行编程,这始终是首要目标。第一个目标是应用规范并创建一个可以工作的程序。在实现这一目标后,已进行了一些性能优化。最终,与大型浏览器已知的解析器相比,整个解析器实际上非常快。
一个主要的性能问题是实际的启动时间。在这里,JIT 过程不仅将 MSIL 代码编译为机器代码,还执行(必要的)优化。如果我们运行一些示例,我们会立即看到热路径根本没有被优化。下一个截图显示了一个典型的运行。

然而,JIT 在这些优化方面也做得很好。代码的编写方式使得内联和其他关键(且大多是微不足道的)优化更有可能由 JIT 执行。一个相当重要的速度测试是从 JavaScript 世界借鉴而来的:Slickspeed。此测试向我们展示了大量数据:
- 我们的 CSS 分词器的性能。
- 我们的选择器创建器的性能。
- 我们的树遍历器的性能。
- 我们的 CSS 选择器的可靠性。
- 我们的节点树的可靠性。
在同一台机器上,最快的 JavaScript 实现大量使用了 document.QuerySelectorAll。因此,我们的测试几乎直接与浏览器(在本例中是 Opera)进行比较。最快的实现需要大约 12 毫秒的 JavaScript 时间。在 C# 中,我们可以在 3 毫秒内获得相同的结果(同一台机器,发布模式,64 位 CPU)。
注意:这个结果不应该说服您 C# / 我们的实现比 Opera / 任何浏览器都快,但表明性能至少处于稳固的领域。应该指出的是,浏览器通常更精简,可能更快,但是 AngleSharp 的性能是完全可以接受的。
下一个截图是在运行 Slickspeed 测试时拍摄的。请注意,实际时间总计高于 3 毫秒,因为时间已作为整数相加,以确保与原始 JavaScript Slickspeed 基准测试进行轻松比较。

总而言之,我们可以说性能已经相当不错了,尽管没有进行大规模的性能优化工作。对于中等大小的文档,我们肯定会远低于 100 毫秒,并最终(足够的预热、文档大小、CPU 速度)接近 1 毫秒。
使用代码
获取 **AngleSharp** 的最简单方法是使用 NuGet。文章末尾有 NuGet 包链接(或者只需在 NuGet 包管理器官方源中搜索 *AngleSharp*)。
GitHub 存储库提供的解决方案还包含一个名为 *Samples* 的 WPF 应用程序。该应用程序看起来如下所示:

每个示例都以不同的方式使用 HTMLDocument 实例。获取文档的基本方法非常简单:
async Task LoadAsync(String url, CancellationToken cancel)
{
var http = new HttpClient();
//Get a correct URL from the given one (e.g. transform codeproject.com to http://codeproject.com)
var uri = Sanitize(url);
//Make the request
var request = await http.GetAsync(uri);
cancel.ThrowIfCancellationRequested();
//Get the response stream
var response = await request.Content.ReadAsStreamAsync();
cancel.ThrowIfCancellationRequested();
//Get the document by using the DocumentBuilder class
var document = DocumentBuilder.Html(response);
cancel.ThrowIfCancellationRequested();
/* Use the document */
}
目前描述了四种示例用法。第一个是 DOM-浏览器。该示例创建了一个可以导航的 WPF TreeView。TreeView 控件包含文档的所有可枚举子项和 DOM 属性。文档是从给定 URL 获得的 HTMLDocument 实例。
读取这些属性可以通过以下代码实现。这里我们假设 element 是 DOM 树中的当前对象(例如,文档的根元素,如 HTMLHtmlElement 或属性,如 Attr 等)。
var type = element.GetType();
var typeName = FindName(type);
/* with the following definition:
FindName(MemberInfo member)
{
var objs = member.GetCustomAttributes(typeof(DOMAttribute), false);
if (objs.Length == 0) return member.Name;
return ((DOMAttribute)objs[0]).OfficialName;
}
*/
var properties = type.GetProperties(BindingFlags.Public | BindingFlags.Instance | BindingFlags.GetProperty)
.Where(m => m.GetCustomAttributes(typeof(DOMAttribute), false).Length > 0)
.OrderBy(m => m.Name);
foreach (var property in properties)
{
switch(property.GetIndexParameters().Length)
{
case 0:
children.Add(new TreeNodeViewModel(property.GetValue(element), FindName(property), this));
break;
case 1:
{
if (element is IEnumerable)
{
var collection = (IEnumerable)element;
var index = 0;
var idx = new object[1];
foreach (var item in collection)
{
idx[0] = index;
children.Add(new TreeNodeViewModel(item, "[" + index.ToString() + "]", this));
index++;
}
}
}
break;
}
}
悬停在不包含项的元素上通常会产生其值(例如,表示 int 值的属性将显示当前值)作为工具提示。在属性名称旁边显示了确切的 DOM 类型。下图显示了示例应用程序的这部分。

渲染器示例乍一看可能很有趣,但实际上它只是以非常基础的方式使用了 WPF FlowDocument。输出实际上不是很可读,并且与其他解决方案(例如 CodePlex 上的 HTMLRenderer 项目)的渲染相去甚远。
尽管如此,该示例展示了如何使用 DOM 获取各种类型对象的信息并使用它们的信息。作为一个小技巧,<img> 标签也会被渲染,至少为渲染器增加了一点色彩。截图是在维基百科英文主页上拍摄的。

统计信息示例则有趣得多。在这里,我们从给定的 URL 收集数据。有四种统计数据可用,这些数据可能比较有趣:
- 前 8 个元素(使用频率最高)
- 前 8 个类名(使用频率最高)
- 前 8 个属性(使用频率最高)
- 前 8 个单词(使用频率最高)
统计演示的核心是以下代码片段:
void Inspect(Element element, Dictionary<String, Int32> elements, Dictionary<String, Int32> classes, Dictionary<String, Int32> attributes)
{
//The current tag name has to be evaluated (for the most elements)
if (elements.ContainsKey(element.TagName))
elements[element.TagName]++;
else
elements.Add(element.TagName, 1);
//The class names have to be evaluated (for the most classes)
foreach (var cls in element.ClassList)
{
if (classes.ContainsKey(cls))
classes[cls]++;
else
classes.Add(cls, 1);
}
//The attribute names have to be evaluated (for the most attributes)
foreach (var attr in element.Attributes)
{
if (attributes.ContainsKey(attr.Name))
attributes[attr.Name]++;
else
attributes.Add(attr.Name, 1);
}
//Inspect the other elements
foreach (var child in element.Children)
Inspect(child, elements, classes, attributes);
}
此代码片段首先在文档的根元素上使用。从这一点开始,它将递归地调用子元素上的方法。之后,可以使用 LINQ 对字典进行排序和评估。
此外,我们还对文本内容(以单词形式)进行了一些统计。这里任何单词都必须至少有两个字母。对于这个示例,OxyPlot 被用来显示饼图。显然,CodeProject 喜欢使用锚标签(谁不喜欢呢?)和一个名为 *t* 的类(在我看来,非常自解释的名称!)。
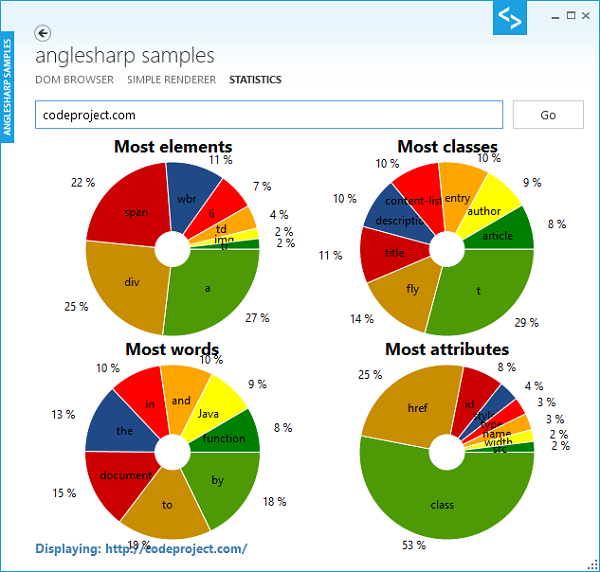
最后一个示例展示了 DOM 方法 querySelectorAll 的用法。遵循 C# 命名约定,我们在这里使用 QuerySelectorAll。元素列表会根据您在 TextBox 元素中输入的选择器进行过滤。框的背景颜色指示查询的状态——一个红色框告诉我们由于查询中的语法错误将抛出异常。

代码非常简单。基本上,我们获取 document 实例并调用 QuerySelectorAll 方法,传入一个选择器字符串(例如 * 或 body > div 等)。任何熟悉 JavaScript 中的基本 DOM 语法的人都会立即识别它。
try
{
var elements = document.QuerySelectorAll(query);
source.Clear();
foreach (var element in elements)
source.Add(element);
Result = elements.Length;
}
catch(DOMException)
{
/* Syntax error */
}
最后,我们获取元素列表(QuerySelectorAll 返回一个 HTMLCollection(这是 Element 实例的列表),而 QuerySelector 只返回一个元素或 null)并将其推送到视图模型的观察集合中。
更新
另一个有趣的演示可能是处理样式表。示例应用程序已更新了一个简短的演示,该演示读取任意网页并显示可用的样式表(<link> 或 <style> 元素)。
总而言之,示例看起来如下(左侧为可用源,右侧为样式表树):

同样,所需的代码并不复杂。为了获取 HTMLDocument 对象的可用样式表,我们只需要遍历其 StyleSheets 属性上的元素。在这里,我们不会得到 CSSStyleSheet 类型的对象,而是 StyleSheet。这是 W3C 规定的一个更通用的类型。
for (int i = 0; i < document.StyleSheets.Length; i++)
{
var s = document.StyleSheets[i];
source.Add(s);
}
在下一部分,我们实际上需要创建一个 CSSStyleSheet 来包含规则。这里我们有两种选择:
- 样式表源自
<style>元素并内联。 - 样式表与
<link>元素关联,必须从外部源加载。
在第一种情况下,我们已经可以访问源。在第二种情况下,我们需要先下载 CSS 样式表的源代码。由于大部分时间将用于接收源代码,因此我们需要确保我们的应用程序保持响应。
最后,我们将新元素(节点带有子节点,可能带有子节点……)分块添加,每次 100 个——只是为了在填充树时保持一点响应性。
var content = String.Empty;
var token = cts.Token;
if (String.IsNullOrEmpty(selected.Href))
content = selected.OwnerNode.TextContent;
else
{
var http = new HttpClient { BaseAddress = local };
var request = await http.GetAsync(selected.Href, cts.Token);
content = await request.Content.ReadAsStringAsync();
token.ThrowIfCancellationRequested();
}
var css = DocumentBuilder.Css(content);
for (int i = 0, j = 0; i < css.CssRules.Length; i++, j++)
{
tree.Add(new CssRuleViewModel(css.CssRules[i]));
if (j == 100)
{
j = 0;
await Task.Delay(1, cts.Token);
}
}
决定性的部分实际上是使用 DocumentBuilder.Css 来构建 CSSStyleSheet 对象。在 CssRuleViewModel 中,只需区分各种规则以确保每种规则都得到适当的显示。有三种类型的规则:
- 包含声明的规则(使用
Style属性)。示例:Keyframe、Style。 - 包含其他规则的规则(使用
CssRules属性)。示例:Keyframes、Media。 - 不包含任何内容(使用特殊属性)或具有特殊内容的规则。示例:Import、Namespace。
以下代码显示了这些类型之间的基本区分。请注意,CSSFontFaceRule 属于第三类——它具有形式为特殊声明集的特殊内容。
public CssRuleViewModel(CSSRule rule)
{
Init(rule);
switch (rule.Type)
{
case CssRule.FontFace:
var font = (CSSFontFaceRule)rule;
name = "@font-face";
Populate(font.CssRules);
break;
case CssRule.Keyframe:
var keyframe = (CSSKeyframeRule)rule;
name = keyframe.KeyText;
Populate(keyframe.Style);
break;
case CssRule.Keyframes:
var keyframes = (CSSKeyframesRule)rule;
name = "@keyframes " + keyframes.Name;
Populate(keyframes.CssRules);
break;
case CssRule.Media:
var media = (CSSMediaRule)rule;
name = "@media " + media.ConditionText;
Populate(media.CssRules);
break;
case CssRule.Page:
var page = (CSSPageRule)rule;
name = "@page " + page.SelectorText;
Populate(page.Style);
break;
case CssRule.Style:
var style = (CSSStyleRule)rule;
name = style.SelectorText;
Populate(style.Style);
break;
case CssRule.Supports:
var support = (CSSSupportsRule)rule;
name = "@supports " + support.ConditionText;
Populate(support.CssRules);
break;
default:
name = rule.CssText;
break;
}
}
此外,声明和值也有自己的构造函数,尽管它们不必像所示的构造函数那样具有选择性。
更新 2
AngleSharp 的另一个有趣(但显而易见)的使用方式是读取 HTML 树。如前所述,解析器会考虑 HTML5 解析规则,这意味着生成的树可能不是微不足道的(由于解析器应用的各种例外/容差)。
尽管如此,大多数页面都尝试尽可能有效,这不需要任何特殊的解析规则。以下截图显示了树示例的外观:

这方面的代码可能看起来比实际的要简单,但是,它区分了不同类型的节点。这样做是为了隐藏换行符,这些换行符(按定义)在文档树中变成了文本节点。此外,多个空格被合并为一个空格字符。
public static TreeNodeViewModel Create(Node node)
{
if (node is TextNode) //Special treatment for text-nodes
return Create((TextNode)node);
else if (node is Comment) //Comments have a special color
return new TreeNodeViewModel { Value = Comment(((Comment)node).Data), Foreground = Brushes.Gray };
else if (node is DocumentType) //Same goes for the doctype
return new TreeNodeViewModel { Value = node.ToHtml(), Foreground = Brushes.DarkGray };
else if(node is Element) //Elements are also treated specially
return Create((Element)node);
//Unknown - we don't care
return null;
}
Element 必须区别对待,因为它可能包含子元素。因此,我们需要以下代码:
static TreeNodeViewModel Create(Element node)
{
var vm = new TreeNodeViewModel { Value = OpenTag(node) };
foreach (var element in SelectFrom(node.ChildNodes))
{
element.parent = vm.children;
vm.children.Add(element);
}
if (vm.children.Count != 0)
vm.expansionElement = new TreeNodeViewModel { Value = CloseTag(node) };
return vm;
}
当查看 SelectFrom 方法时,圆圈就闭合了。
public static IEnumerable<TreeNodeViewModel> SelectFrom(IEnumerable<Node> nodes)
{
foreach (var node in nodes)
{
TreeNodeViewModel element = Create(node);
if (element != null)
yield return element;
}
}
这里我们只返回一个迭代器,该迭代器遍历所有节点并返回创建的 TreeNodeViewModel 实例(如果有)。
兴趣点
当我开始这个项目时,我从 JavaScript 程序员的角度已经相当熟悉 W3C 官方规范和 DOM。然而,实现规范不仅提高了我在 Web 开发方面的总体知识,还提高了我在(可能的)性能优化和有趣(但鲜为人知)的问题方面的知识。
我认为在 C# 中拥有一个维护良好的 DOM 实现绝对是未来的一个不错选择。我目前正忙于做其他事情,但这是一种我未来几年一定会继续推进的项目。
话虽如此,我希望我能引起一些关注,并且有一些人有兴趣为该项目贡献代码。能够有一个良好、干净(并且尽可能完美)的 C# HTML 解析器实现将是非常棒的。
参考文献
所有这些工作都离不开 W3C 提供的出色的文档和规范。我必须承认,有些文档似乎不太有用或已过时,而另一些则完美无瑕且是最新的。质疑其中的一些观点也非常重要,因为(通常只有很小的)错误也可能被发现。
这是我个人最常使用的(W3C 和 WHATWG)文档列表:
- HTML 5.1 规范(草案)
- CSS 语法
- CSS 选择器
- DOM 规范
- 字符定义
- XML 1.1 规范(推荐)
- XHTML 语法
- CSS 选择器 4(草案)
- CSS 2.1 属性
- WHATWG HTML 标准
当然,还有其他几份有用的文档(所有这些都由 W3C 或 WHATWG 提供),但上面列出的列表是一个很好的起点。
此外,以下链接可能很有帮助:
历史
- v1.0.0 | 初始发布 | 2013 年 6 月 19 日
- v1.1.0 | 添加了样式表示例 | 2013 年 6 月 22 日
- v1.1.1 | 修复了一些拼写错误 | 2013 年 6 月 25 日
- v1.2.0 | 添加了样式表示例 | 2013 年 7 月 4 日