
Priori - 动态 cast<> 的快速替代方案
4.96/5 (11投票s)
本文讨论了 Priori,一种动态 cast<> 的快速替代方案的实现和使用。
- 在 GitHub 上下载项目
- 在 helleboreconsulting.com 上查看 更新版文章。
引言
在 2008 年发表的一篇题为“面向硬实时系统的实用且可验证的 C++ 动态转换”的论文中,Dechev、Mahapatra 和 Stroustrup 发表了一个关于在类型转换系统中利用素数来替代 dynamic_cast 的想法。这种方法存在局限性,但适用时,可以极大地提高性能。dynamic_cast<> 本身不提供任何时间保证,而 priori_cast<> 可以。虽然本文讨论的库不支持跨动态库的继承,但 priori_cast<> 也可以克服这一点。
请注意,这不是 dynamic_cast<> 的替代品。priori_cast<> 经过专门调整,可以从基类型快速转换为派生类型。
背景
许多经验丰富的开发者会告诉你,优化代码的最佳时机是当你通过测量得出需要优化的时候。最近在一个大型 C++ 项目中工作时,我开始进行测量以发现热点。令我惊讶的是,在工作量排名前 25 的区域中,赫然出现了古老的 dynamic_cast<>。虽然我明白 RTTI 有开销,因此 dynamic_cast<> 也有开销,但我却低估了大量的类型转换对性能的影响竟然如此之大。
通过一些小的重构,dynamic_cast<> 的开销开始从我的热点列表中下降。然而,我想找到一种方法,在不付出如此高昂代价的情况下使用 dynamic_cast<>。这时 priori_cast<> 出现了。
实现
我正在开发的大部分软件都保留了大量的基类指针,并尝试将它们向上转换为各种类型。一旦成功,就会激活对象特定的逻辑。解决这类问题的一种简单轻量级的方法是在基类中添加一个“Type”属性,作为一种简陋的 RTTI。然而,在动态插件架构中,这可能很麻烦且不切实际。
priori_cast<> 利用了“面向硬实时系统的实用且可验证的 C++ 动态转换”中的思想,并为基类的每个派生类分配一个唯一的素数。然后,就可以执行 dynamic_cast<> 所做的所有工作,而无需 RTTI 的开销。
虽然目前的实现尚未完全优化,但它表明存在实际的、动态的方法来支持从基类向上转换为派生类,并且这些方法的性能明显优于 dynamic_cast<>。
Using the Code
Priori 使用的所有类都必须继承自 priori 基类。(这是实现的一个限制。)
class Base
{
public:
Base();
Base(Base& other);
Base(Base&& other);
virtual ~Base() throw();
bool priori(const int x) const;
protected:
void priori(Base* x);
private:
int prioriFactor;
};
extern int get(priori::Base* x);
extern int get(const std::type_info& x);
在每个派生类的构造函数中,派生类调用基类的受保护 priori 函数来注册自己的类型并获得分配的唯一因子。
class Alpha : public priori::Base
{
public:
Alpha()
{
this->priori(this);
}
};
在将需要使用 Priori 的类继承自这个基类之后,您就可以像使用 dynamic_cast<> 一样使用模板化的 priori_cast<>。
template<class T, class V> T priori_cast(V base)
{
if(base != nullptr)
{
const auto factor = priori::get(typeid(std::remove_pointer<T>::type));
if((factor != 0) && (base->priori(factor) == true))
{
return reinterpret_cast<T>(base);
}
}
return nullptr;
}
有了这个模板,在适当的时候用 priori_cast<> 替换 dynamic_cast<> 就变得很自然了。请注意,dynamic_cast<> 仍然可以正常工作。
// Alpha derives from priori::Base
Alpha a;
// A class not derived from priori::Base
Beta b;
auto baseClassPointer = priori_cast<priori::Base*>(&a);
auto derivedClassPointer = priori_cast<Alpha*>(checkedBaseClassPointer);
auto nullPointer = priori_cast<priori::Base*>(&b);
结果
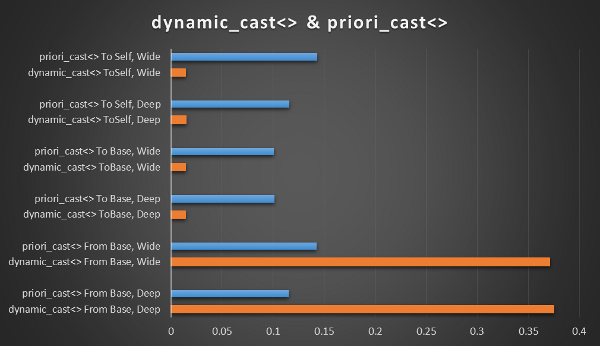
试图替换我们代码中如此普遍的 dynamic_cast 的全部原因是为了获得可衡量的性能提升。使用 Celero 性能测试框架,对各种类型的 dynamic_cast 调用成本进行了基线测量。创建了一个十个对象宽(十个独立的类继承自一个共同的基类)或十个对象深(每个十个类继承自前一个类)的继承结构。然后,运行了从基类到派生类、从派生类到基类以及从类到自身的类型转换测试。
Celero 基线测试的结果如下所示。
[==========]
[ CELERO ]
[==========]
[ STAGE ] Baselining
[==========]
[ RUN ] priori_deep_fromBase.dynamic_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_deep_fromBase.dynamic_cast (0.749996 sec) [2000000 calls in 749996 usec]
[0.374998 us/call] [2666680.888965 calls/sec]
[ RUN ] priori_wide_fromBase.dynamic_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_wide_fromBase.dynamic_cast (0.741270 sec) [2000000 calls in 741270 usec]
[0.370635 us/call] [2698072.227394 calls/sec]
[ RUN ] priori_deep_toBase.dynamic_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_deep_toBase.dynamic_cast (0.028151 sec) [2000000 calls in 28151 usec]
[0.014075 us/call] [71045433.554758 calls/sec]
[ RUN ] priori_wide_toBase.dynamic_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_wide_toBase.dynamic_cast (0.028013 sec) [2000000 calls in 28013 usec]
[0.014007 us/call] [71395423.553350 calls/sec]
[ RUN ] priori_deep_toSelf.dynamic_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_deep_toSelf.dynamic_cast (0.029868 sec) [2000000 calls in 29868 usec]
[0.014934 us/call] [66961296.370698 calls/sec]
[ RUN ] priori_wide_toSelf.dynamic_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_wide_toSelf.dynamic_cast (0.027973 sec) [2000000 calls in 27973 usec]
[0.013987 us/call] [71497515.461338 calls/sec]
[ RUN ] rttiCosts.typeinfo -- 70 samples, 2000000 calls per run.
[ DONE ] rttiCosts.typeinfo (0.027951 sec) [2000000 calls in 27951 usec]
[0.013976 us/call] [71553790.562055 calls/sec]
[==========]
[ STAGE ] Benchmarking
[==========]
[ RUN ] priori_deep_fromBase.priori_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_deep_fromBase.priori_cast (0.231020 sec) [2000000 calls in 231020 usec]
[0.115510 us/call] [8657259.111765 calls/sec]
[ BASELINE ] priori_deep_fromBase.priori_cast 0.308028
[ RUN ] priori_wide_fromBase.priori_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_wide_fromBase.priori_cast (0.285642 sec) [2000000 calls in 285642 usec]
[0.142821 us/call] [7001771.448176 calls/sec]
[ BASELINE ] priori_wide_fromBase.priori_cast 0.385341
[ RUN ] priori_deep_toBase.priori_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_deep_toBase.priori_cast (0.202565 sec) [2000000 calls in 202565 usec]
[0.101283 us/call] [9873373.978723 calls/sec]
[ BASELINE ] priori_deep_toBase.priori_cast 7.195659
[ RUN ] priori_wide_toBase.priori_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_wide_toBase.priori_cast (0.202305 sec) [2000000 calls in 202305 usec]
[0.101153 us/call] [9886063.122513 calls/sec]
[ BASELINE ] priori_wide_toBase.priori_cast 7.221826
[ RUN ] priori_deep_toSelf.priori_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_deep_toSelf.priori_cast (0.231435 sec) [2000000 calls in 231435 usec]
[0.115718 us/call] [8641735.260440 calls/sec]
[ BASELINE ] priori_deep_toSelf.priori_cast 7.748594
[ RUN ] priori_wide_toSelf.priori_cast -- 70 samples, 2000000 calls per run.
[ DONE ] priori_wide_toSelf.priori_cast (0.286469 sec) [2000000 calls in 286469 usec]
[0.143234 us/call] [6981558.213978 calls/sec]
[ BASELINE ] priori_wide_toSelf.priori_cast 10.240911
[ RUN ] rttiCosts.typeinfoHash -- 70 samples, 2000000 calls per run.
[ DONE ] rttiCosts.typeinfoHash (0.317680 sec) [2000000 calls in 317680 usec]
[0.158840 us/call] [6295643.414757 calls/sec]
[ BASELINE ] rttiCosts.typeinfoHash 11.365604
[ RUN ] rttiCosts.typeinfoName -- 70 samples, 2000000 calls per run.
[ DONE ] rttiCosts.typeinfoName (0.054228 sec) [2000000 calls in 54228 usec]
[0.027114 us/call] [36881315.925352 calls/sec]
[ BASELINE ] rttiCosts.typeinfoName 1.940109
[==========]
[ STAGE ] Completed. 15 tests complete.
[==========]
从这些测量结果可以看出,只要是从基类转换为派生类,priori_cast 的运行时成本大约是 dynamic_cast 的 31% 到 39%。这可以节省大约 60% 的开销。这种性能提升受到 priori_cast 在其他转换场景下成本高达 dynamic_cast<> 11.3 倍的事实的影响。
未来工作
priori_cast<> 的概念通过这个库得到了证明,因为它能够显著降低从基类转换为派生类的成本。虽然此实现的性能在各种用例中相当一致,但它仍然太慢,无法成为 dynamic_cast<> 的通用替代品。应该努力降低 priori_cast<> 在某些常见特殊情况(如转换为自身)下的总体成本。
关注点
性能测试应始终在 Release 版本上进行。切勿在 Debug 版本上测量性能并根据结果进行更改。对于代码性能而言,(优化)编译器是您的朋友。
Priori 提供了其 API 的 Doxygen 文档。
历史
- 2013 年 6 月 20 日 - 首次发布
- 2013 年 6 月 28 日:源代码已更新,性能大幅提升