
SortedSplitList - C# 中的索引算法
4.96/5 (38投票s)
一个用于在应用程序中管理数千万个对象的列表。
本文的法文版本可从此链接获取。
引言
几年前,我开发了一个 NoSQL DBMS 技术的存储部分。
服务器应该以键/值的形式将数据存储在磁盘上,并且能够管理各种方面,例如事务系统、复制、锁、修复损坏的段、压缩以及数据库中数据量、浪费空间等的计数器。
为了克服所有这些功能,数据应该用一个头部块记录,并且所有这些块应该放置在具有多个条件的几个索引中。
最初,我使用了 .NET Framework 提供的标准工具:SortedList、Dictionary、SortedDictionary,但很快,在负载测试期间发现了故障。
因此,有必要创建我自己的列表,以帮助构建一个能够处理大量数据、快速、内存使用率低,并能够通过对多个键进行排序来索引数据集的服务器。
背景
在开始介绍我的解决方案之前,我将解释这个问题。
为此,我们将观察 .NET Framework 提供的不同算法的行为,同时尝试用随机数据注入 1000 万个对象。
在这些测试中,我将收集每个测试工具使用的内存量和花费的时间。
这是将用于填充我们的索引的对象
public class DataObject
{
private static readonly Random Random = new Random();
private readonly Guid _id = Guid.NewGuid();
private readonly DateTime _date =
new DateTime(Random.Next(1980, 2020),Random.Next(1,12), Random.Next(1,27));
private readonly int _number = Random.Next();
public Guid ID
{
get { return _id; }
}
public DateTime Date
{
get { return _date; }
}
public int Number
{
get { return _number; }
}
}
一个工厂将在我们的测试中生成所需的实例
public static class DataFactory
{
public static List<dataobject> GetDataObjects(int number)
{
var result = new List<dataobject>();
for(int i = 0; i < number; i++)
result.Add(new DataObject());
return result;
}
} 您会注意到工厂直接返回一个列表而不是一个枚举。这是为了不影响每个对象的生成时间的时间计算。
我们还将建立一个性能计数器,以收集有关算法使用的时间和内存量的数据
public class PerfCounter : IDisposable
{
private readonly Stopwatch _stopwatch = new Stopwatch();
private readonly long _currentMemoryUsage = Process.GetCurrentProcess().WorkingSet64;
private readonly string _filePath;
public PerfCounter(string filePath)
{
if( string.IsNullOrEmpty(filePath) )
throw new FileNotFoundException();
string directoryPath = Path.GetDirectoryName(filePath);
if( string.IsNullOrEmpty(directoryPath) )
throw new FileNotFoundException();
Directory.CreateDirectory(directoryPath);
if (!File.Exists(filePath))
File.AppendAllText(filePath, "Memory\tTime\r\n");
_filePath = filePath;
_stopwatch.Start();
}
public void Dispose()
{
_stopwatch.Stop();
GC.Collect();
long memory = Process.GetCurrentProcess().WorkingSet64 - _currentMemoryUsage;
File.AppendAllText(_filePath, _stopwatch.Elapsed.ToString() + "\t" + memory + "\r\n");
}
}
现在我们有了所需的工具来开始我们的分析,让我们从第一个可用的工具开始。
SortedList
SortedList 是按键排序的键/值对集合,可以通过键和索引访问。
我们将使用以下方法注入 100 万个随机对象
private static void TestSortedList()
{
var sortedList = new SortedList<Guid, DataObject>();
for (int i = 0; i < 10; i++) {
List<DataObject> datas = DataFactory.GetDataObjects(100000);
using (var counter = new PerfCounter("c:\\Indexation\\SortedList.txt")) {
foreach (DataObject dataObject in datas) {
sortedList.Add(dataObject.ID, dataObject);
}
}
}
}
以下是这个小程序的结果

插入 100 万个项目的总时间:785 秒
索引 100 万个项目的总内存:54 MB
如您所见,在 SortedList 中插入速度极慢,因为插入 100 万个对象用了 13 分钟。我提醒您,我们的目标是管理数千万个对象,使用这种方法是不可想象的。
为什么 SortedList 这么慢?
原因很简单:列表是存储在连续元素中的数组。
![]()
当您将一个项目添加到列表末尾时,它只是像这样堆叠
![]()
这不会给算法带来任何成本。这也是为什么在对非随机数据进行性能测试时,您可能会认为在列表中包含数据速度极快,因为系统会将数据添加到列表中。
相反,如果您想在列表中间插入一个元素(这是一个排序列表),我们别无选择,只能移动整个更高元素的块以为新数据腾出空间,然后在此系列之后拾取列表末尾的数据。

显然,这是非常昂贵的,因为列表中的元素越多,复制/粘贴操作就越长,尤其是在列表开头插入元素时。
在这里,插入时间的趋势线的方程是 ![]()
因此,理论上将 1000 万个随机元素导入 SortedList 需要 36 小时!
词典
字典是基于 Hashtable 算法的键/值类型泛型对象集合。
和以前一样,我们将获取 1000 万个对象算法的执行时间和使用的内存量。
结果如下

插入 1000 万个项目的总时间:2 秒
索引 1000 万个项目的总内存:638 MB
插入时间好得多,但内存使用量太高。
想象一下,如果我们想为每个对象创建五个索引,每个索引 20 字节,那么所有元素的重量将是 200 MB,而算法将占用 3 GB 和 190 MB 的 RAM!
为什么哈希表占用这么多空间?
当在 hashtable 中添加一个项目时,会使用一个键来计算一个相对唯一的数字(称为 hashcode)。我说“相对”是因为可能有两个不同的键具有相同的哈希码,这称为冲突。
为了克服这个问题,hashtable 内部有一个二维表(称为桶),其中包含以结构形式的条目,具有多个参数。这些条目占用了大量空间。
通常,一个条目由 hashcode、一个键、一个值和一个指向下一个元素的指针组成,因为桶实际上是链表数组。

整个结构的目的是智能地存储由 hashcode 索引的数据。
基本上,哈希码会受到桶长度的模数运算,这会给出存储条目的索引。一旦知道索引,循环将遍历所有匹配的条目,以将所有键及其哈希码与要插入的项目进行比较。
如果找到相同的键,系统将返回错误。
如果找到相同的哈希码但键不同,则在链表中创建一个新条目。
如果您查看图表,您可以观察到在 600 万个对象时,内存异常增加了 100%。我猜这一定是在大量冲突之后在桶中进行了预分配。
因此,要索引的对象越多,冲突的可能性就越高,迫使哈希表分配大量内存以保持其性能水平。当您想要处理大量对象时,不建议使用此技术!
SortedDictionary 和 SortedDictionary2
根据 MSDN,SortedDictionary 类旨在克服 SortedList 的插入速度问题。让我们看看我们的测试系统会发生什么

插入 1000 万个项目的总时间:5 秒
索引 1000 万个项目的总内存:612 MB

插入 1000 万个项目的总时间:5 秒
索引 1000 万个项目的总内存:649 MB
根据结果,您会想知道为什么要使用 SortedDictionary 而不是仅仅使用 Dictionary?因为在内存消耗相同的情况下,Dictionary 的速度是两倍!
这里我们遇到了问题的第二个维度,不同深度的索引。
我们所有的测试都基于单个键搜索,但在某些情况下,我们希望按日期、大小和 ID 的组合对对象进行排序。如果我们要使用简单的 Dictionary 来实现这一点,我们必须按如下方式实现
Dictionary<DateTime, Dictionary<int, Dictionary<Guid, DataObject>>> index =
new Dictionary<DateTime, Dictionary<int, Dictionary<Guid, DataObject>>>(); 如您所见,我们嵌套了三个字典。这不仅增加了实现级别的复杂性,而且使用的内存量也将乘以 3,需要 2GB RAM,而不是 SortedDictionary 的 650MB。
SortedDictionary 通过强制实现一个“比较器”来消除问题,该比较器将允许它对内部字典列表进行二进制搜索。
我的解决方案:SortedSplitList
与之前的测试模型相同,这是将 1000 万个对象插入 SortedSplitList 的结果
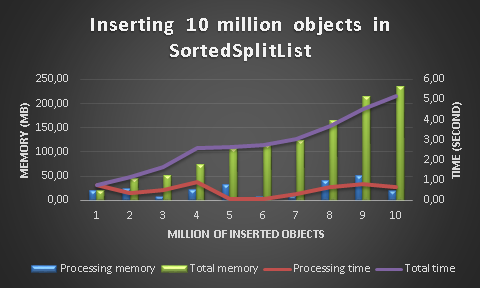
插入 1000 万个项目的总时间:5 秒
索引 1000 万个项目的总内存:235 MB
该算法的插入时间与 SortedDictionary 相同,但内存消耗比 Dictionary 或 SortedDictionary 低三倍!
它是如何工作的?
为了开发这个算法,我试图提高标准 SortedList 的插入速度。
正如对 SortedList 的性能分析中解释的那样,缓慢只在列表开头插入元素时出现。实际上,系统必须首先删除要插入元素的所有上层元素,然后在此之后重新堆叠。
为了意识到执行此操作所浪费的时间,只需将一百个盘子堆叠在一起,然后将一个盘子插入到第十八个位置。
因此,方法不是在一个可能巨大的单个列表上工作,而是在几个小列表行上工作

SortedSplitList 的内部结构
假设我们要插入元素 27。首先,我们对所有列表进行二分查找,以找到包含该元素的列表;

在列表中搜索以容纳新元素
一旦找到结果列表,只需在该列表中进行第二次二分查找,并像经典的排序列表元素一样插入

定位子列表中的集成

插入新项目。
通过这种简单的方法,插入时间的影响大大减少,同时保持了内存消耗优化的优势!
Using the Code
要使用 SortedSplitList,您必须首先声明一个要索引的对象的“比较器”默认值
要索引的对象
public class TestObject
{
public int Id { get; set; }
public int Id2 { get; set; }
public DateTime Date { get; set; }
public string Data { get; set; }
}
默认比较器
public class CompareById : IComparer<TestObject>
{
public int Compare(TestObject x, TestObject y)
{
if (x.Id == y.Id)
return 0;
if (x.Id < y.Id)
return -1;
return 1;
}
}
然后像这样创建一个新的 SortedSplitList 实例
SortedSplitList<TestObject> sortedSplitList =
new SortedSplitList<TestObject>(new CompareById());
完成之后,您可以使用 Add()、Retrieve() 或 BinarySearch() 以及 Remove() RemoveAll() 或 Clear() 方法从列表中添加、检索或删除项目。
关于 Retrieve 方法,第一个参数必须是根据您要搜索的参数配置的对象实例。
例如,如果我想查找一个 ID 为 78 的 TestObject,其 Data 字段的值,我必须按以下方式操作
var searchObject = new TestObject {Id = 78};
var foundObject = sortedSplitList.Retrieve(searchObject);
Console.WriteLine(foundObject != null ? foundObject.Data : "Data not found.");
BinarySearch() 方法允许检索所查找项的索引,从而可以根据您的需要浏览 SortedSplitList。
要了解如何使用 BinarySearch 方法(索引)返回的对象,请参阅 MSDN 中关于泛型列表的 BinarySearch() 方法。
使用多条件存储的记录
想象一下我们的 TestObject 有一个 Date + Id 的复合键。如何将元素存储和检索到 SortedSplitList 中?
存储项目很简单。只需按如下方式定义一个默认比较器
public int Compare(TestObject x, TestObject y)
{
int dateResult = x.Date.CompareTo(y.Date);
if (dateResult == 0) {
if (x.Id == y.Id)
return 0;
if (x.Id < y.Id)
return -1;
return 1;
}
return dateResult;
}
因此,Add() 和 Retrieve() 方法允许您处理复合键元素。
现在,如果我们想知道给定日期的所有元素怎么办?
看到 SortedSplitList 允许访问枚举器,编程初学者可能会尝试使用以下方法
foreach (var testObject in sortedSplitListSortedById.Where
(a => a.Date == DateTime.Parse("2003/01/01")))
Console.WriteLine(testObject.Data);
如果您的列表包含的元素很少,这可能非常有效,但如果列表包含数百万个对象,则此行代码的性能可能是灾难性的。
在这种情况下,适当的方法是使用专门的日期比较搜索进行二分查找,然后反向遍历列表中的项目以找到第一个。一旦找到,只需沿正确方向重新追溯列表,只返回符合搜索条件的项目。
如果所有这些听起来实现起来很复杂,PartiallyEnumerate() 方法可能有助于完成此任务。以下是如何使用它。
首先,我们定义一个特殊的日期搜索,并且只按日期搜索
public class CompareByDate : IComparer<TestObject>
{
public int Compare(TestObject x, TestObject y)
{
return x.Date.CompareTo(y.Date);
}
}
然后我们可以调用 PartiallyEnumerate() 方法,向其传递一个带有我们想要的日期的比较对象,以及上面的比较器
foreach (var testObject in sortedSplitList.PartiallyEnumerate(new TestObject()
{ Date = DateTime.Parse("01/01/2003") }, new CompareByDate()) )
Console.WriteLine(testObject.Id);
通过这种方法,如果我们的列表包含数百万个对象,foreach 将显示所有日期为 2003 年 1 月 1 日的 ID 元素,而不会花费数分钟。
结论
尽管 .NET 框架提供的索引对于大多数软件工具需求来说已经足够,但 SortedSplitList 对于在应用程序中处理大量对象可能非常有用,它结合了 SortedList 的内存优化、SortedDictionary 的插入速度,同时提供了在多个键上工作的机会。
因此,您可以轻松地根据多个条件索引数据,而无需担心过快出现 OutOfMemoryException。