
StackExchange 服务: 实现数据提供程序
4.65/5 (17投票s)
用于将数据导入为 StackExchange 数据转储构建的关系数据服务的客户端数据提供程序。
请将文档包根目录中的示例数据提取到数据服务站点的根目录中。
以及 API 文档(可选)
请将文档包根目录中的所有 API 文档项提取到数据服务站点的根目录中。
注意:导入器和数据服务现在在 .Net 4.5.1 下运行,并且在 Asp.Net Mvc 5 下运行。
相关文章

引言
StackExchange (SE) 提供了一系列问答 (Q/A) 网站,这些网站对于在各种知识领域提出技术问题非常有用,其他知识渊博的用户可以回答这些问题。除了在线内容,他们还定期以 xml 格式提供他们的 数据转储。
Xml 数据不适合直接查询。由于数据显然是关系型的,因此最好将其导入关系数据库中以执行结构化查询。有一些现有的(例如,参见 此处 和 此处),但它们不是最新的,并且 SE 的数据结构已经发生变化。
本文介绍了如何为根据 SE 已发布数据推断出的数据模式构建的数据服务实现客户端数据导入器。根据要求,关系数据库中的数据导入通常可能很复杂。由于本文描述了一个通用解决方案,因此它必须正确处理以下情况
- 数据在初始导入后预计会多次导入。
- 数据可以从多个来源获取。
- 数据库不是只读的,这意味着在两次导入之间可以向其中添加或删除新数据。
- 数据表可以有自动生成的主键。由于上述情况,目标数据库中实体的自动生成主键值不可能与原始主键值相同,必须执行适当的主键映射。
- 数据可能不干净。源数据中存在重复、无效的外键。
- 提供程序提供的数据序列可能不符合数据关系(参见下文)。
在上述要求下进行关系数据导入的大部分逻辑已由数据服务处理,数据提供程序只需提供适当的关系数据并指定数据应如何逐个馈送到服务 API 中。
为 SE 构建的数据服务的在线演示是
- serverfault.com 的数据服务。它可以在 此处 找到。使用的数据库引擎是 PostgreSQL;
- gis.stackexchange.com 的数据服务。它可以在 此处 找到。使用的数据库引擎也是 PostgreSQL。
其中的数据是使用此处描述的数据导入器加载的。
尽管本文专门针对 SE 的数据导入,但它也为未来关于为 SE 构建的数据服务的几篇文章奠定了一些基础。此外,所描述的大部分内容也与我们的其他数据服务相关,例如 CodeProject 中发布的 成员服务。
背景
最初的想法是由 Scott Hanselman 的一篇博客文章(参见 此处)引发的,该文章是关于 SE 的 OData 服务。我们拥有根据给定数据模式半自动构建关系数据源的数据服务的能力(例如,参见 此处),我们接受了为 SE 构建数据服务的挑战。这比我们在飞机上花费的 12 小时要长得多。但额外的时间是值得的,因为结果对用户和开发人员来说更友好,至少对我们来说是这样。在本文以及后续关于同一主题的文章中,我们将展示原因。
SE 主持问答。然而,由于存在大量不相关的问题,找到用户提出的类似问题的答案并非总是易事。尽管使用标签系统可能会有所帮助,但当数据量超过一定水平时,扁平的单层标签系统效率会降低,在这种情况下,标签本身就成了问题,而不是解决方案。用户可以使用网络搜索引擎进行搜索,但获得的结果充其量是模糊且不可控的。这是因为通用搜索引擎不了解特定的知识领域,它们必须使用统计算法来猜测用户意图和选择结果,这可能会丢弃对提问者真正相关但被搜索引擎因某些原因误解或认为权重较低的信息。无论单一算法多么复杂,猜测和/或满足每个人的需求都是困难的。
解决此问题的一个方法是为感兴趣的问题领域构建垂直搜索引擎。SE 专注于几个大型知识领域,在这些领域中,提问者应该已经具备一些背景知识,这样他/她就可以与系统交互以检索更多这些背景知识,并提出越来越智能的问题,这些问题可以用简单关键字搜索无法匹配的方式表达,例如 ${查找正文匹配关键字“word1,word2,...”的问题,这些问题由姓名包含“john”的用户在“Datetime1”和“Datetime2”之间提出,并且其答案的得分大于 5,并且对所述答案的评论不匹配关键字“胡说八道” },然后 ${根据得分降序排列结果,对于得分相同的,根据发布时间升序排列 } 应该很容易构建,而无需学习“奇怪的新语言”或被持续的语法错误劝退;表达式应该由搜索引擎正确解释和执行,而无需强加其自身的“主观”判断(有关更多详细信息,请参见此处)。此外,用户可以将搜索结果保存到由表达式定义的虚拟子集中,以进行查看、报告或进一步提问,使用相同的过程递归进行数据挖掘。
我们的数据服务旨在成为此类系统。
数据模式和扩展
从 SE 导出的文件是 Badges.xml、Comments.xml、PostHistory.xml、Posts.xml、Users.xml 和 Votes.xml,它们映射到数据库中相应的表。然而,在阅读 readme.txt 后,会发现需要更多的表,它们是 PostTypes、PostHistoryTypes 和 VoteTypes。进一步检查 Post.xml 数据文件显示,帖子具有由 Tags 属性值表示的标签,其中标签由 < 和 > 包裹。它们最好由 Tags 表和用于将标签与帖子关联的链接表 PostTags 表示。如下图所示,有 11 个表。字段的名称和类型从数据文件和 此处 获取。PostTypes、PostHistoryTypes 和 VoteTypes 中的实体具有预定义的主键和值。这些值应从 此处 获取,因为 readme.txt 中定义的值与 xml 文件中的实际数据不一致。
外键约束如下图所示,大部分可以从字段名称轻松识别。Posts 表有两个引用自身的字段:AcceptedAnswerId 和 ParentId,当它们不为空时,都引用 Posts 中的另一个实体。但是,AcceptedAnswerId 不能作为外键。这是因为外键引用过去添加的现有实体(相对于当前实体添加的时间),但非空的 AcceptedAnswerId 引用未来的实体(当前问题的答案)。

使用的数据模式的图形表示。
这种数据模式指的是在传统关系数据库引擎中定义数据库实例的模式。然而,它们没有为半自动生产过程提供足够的信息。需要扩展。大部分扩展模式信息与本文无关。其中一个与本文相关的,是在我们系统中引入的**内在标识符**(ids)。内在标识符的目的之一是识别数据库副本集合中的实体。它们不一定与主键相同,因为某些类型的主键是由数据库根据其当时的状态分配的,例如最常用的自动生成主键,其值对于数据库是本地的,与实体是什么无关。它们可以在不同的数据库副本之间有所不同。然而,一个指向自动生成主键的不可变外键可以作为内在标识符,因为它已经由所述主键预先定义。
当前情况下实体的内在 ID 列在相应文档中(参见 此处)其对应的类。例如,由于 Posts 表的主键是自动生成的,Post 实体的内在 ID 被选择为 [ PostTypeId, OwnerUserId, Title, CreationDate ],这被认为可以唯一标识一个帖子。具有相同内在 ID 集的两个帖子在数据库中只记录一次,即使它们可能具有不同的其他属性,并且根据应用程序上下文,另一个副本被视为重复或更新。因此,选择适当的内在 ID 集对于系统的正确行为非常重要。
导入器
给定任何关系数据源的扩展数据模式,导入器类是自动生成的。随附的导入器类 StackExchangeBulkImporter 基于上述类。但是,以下描述的大部分内容也可以应用于为任何其他(扩展)数据模式构建的数据服务。数据服务和导入器共同处理数据导入的复杂逻辑,这些逻辑旨在满足以下一般要求
- 导入的数据必须已经具有有效的主键和/或外键值。
- 自动生成的主键将被分配一个新值,该值很可能与原始值不同。
- 当附加的数据库引擎支持时,会检查外键的有效性;具有无效外键的实体将被拒绝并报告。
- 指向自动生成主键的外键将被修改为相应的主键值。
- 具有相同内在 ID 集的实体只导入一次,所有后续导入(如果有)都将被忽略并记录为重复项。
- 允许多次导入同一数据集。现有数据不会受到多次导入的影响。
需要注意的是,除了 `PostType`、`PostHistoryType` 和 `VoteType` 集(表)之外,其他数据集的主键都是自增整数,以满足上述要求。在这种情况下,这里的数据导入不同于相同的数据库复制。因此,如果同时使用以这种方式构建的多个数据库副本(例如,在负载均衡设置中),客户端软件不应为自增键使用硬编码值,因为它们在数据集的副本之间会有所不同。这种导入更适合称为数据库重新创建,其中所有原始数据关系都得到尊重,并且所有被视为无效的数据都被删除。
当然,可以通过将所有主键设置为非自动生成来实现复制,然而,这种数据库将是只读的。本文没有选择此选项。
它通过三个部分与客户端数据提供程序和用户界面交互。
- 输入部分,可附加自定义数据馈送器;
- 输出部分,用于更新进度、导入状态报告等;
- 控制部分,允许用户设置各种导入参数并启动或停止导入。
输入部分
输入部分是为每个数据集提供的一组客户端提供的枚举器,其命名模式如下:
<实体名称> + "Enum"
其中 <实体名称> 是数据集中实体的名称。例如 PostEnum
/// <summary>
/// Client supplied <c>Post</c> enumerator.
/// </summary>
public IEnumerable<Post> PostEnum
{
get;
set;
}
...
以及用于进度报告的源实体预计数,命名模式如下:
<实体名称> + "Entities"
例如 PostEntities
...
/// <summary>
/// Client supplied <c>Post</c> number of entities, if known.
/// </summary>
public Int64? PostEntities
{
get;
set;
}
...
如果未设置相应的“实体”,则给定数据集的进度信息不可用。
输出部分
事件
...
/// <summary>
/// Occurs when the enumeration state is changed.
/// </summary>
public event Action<EnumProgressStateEvent> EnumStateChanged = null;
/// <summary>
/// Occurs when the enumeration is progressing.
/// </summary>
public event Action<EnumProgressEvent> EnumProgress = null;
/// <summary>
/// Occurs when the update is incomplete.
/// </summary>
public event Action<EntitySetType, IEnumerable<IUpdateResult>> UpdateIncomplete = null;
...
报告
状态报告以内部属性的形式记录,命名模式如下:
"Invalid" + <实体名称> + "s"
例如 InvalidPosts
...
internal List<IUpdateResult> InvalidPosts
{
get
{
if (_invalidPosts == null)
_invalidPosts = new List<IUpdateResult>();
return _invalidPosts;
}
}
private List<IUpdateResult> _invalidPosts = null;
...
它们通过事件 UpdateIncomplete 推送到客户端。
控制部分
设置
有各种公共字段和属性可用于控制导入。用户可以在代码中找到文档以了解其用途,此处不再赘述。
方法
客户端软件可以调用五个方法来控制导入。它们是
/// <summary>
/// It initializes the visitor before enumerating data entities.
/// </summary>
/// <param name="baseAddress">The base http address for the source data service that contains the data.</param>
/// <param name="credentials">Application agent credentials required to access the data source service.</param>
public void Init(string baseAddress, CallerCredentials credentials = null)
{
...
}
/// <summary>
/// Start the importation.
/// </summary>
public void StartProcess()
{
...
}
/// <summary>
/// Stop the importation.
/// </summary>
public void StopProcess()
{
...
}
/// <summary>
/// Load a previous state so the importing can be started from it next.
/// </summary>
public void LoadState(string statepath)
{
...
}
/// <summary>
/// Save the current state so the importing can be started from current state later.
/// </summary>
public void SaveState(string statepath)
{
...
}
关于导入器的一些细节
讨论自动生成的导入器的一些细节对于正确实现数据提供程序很有用。StartProcess 方法以一种尊重不同实体类型之间相互依赖关系的方式处理来自数据提供程序的每个特定表的馈送数据。对于依赖于其他实体类型的实体集(表)来说,这相对容易。但是,对于依赖于同一集合中其他实体的实体,例如 Post 集合,逻辑更复杂。这是因为实际上无法保证 SE 的 xml 数据源以尊重数据依赖关系的正确顺序提供 Post 实体,实际上它并没有这样做。此外,Post 集合中的实体具有一个名为 AcceptedAnswerId 的属性(参见模式部分),需要映射到新的键值,这些键值仅在添加所有 Post 实体后才可用。这两个“问题”需要后处理,这在专门用于 Post 集合的代码块末尾进行处理
#region import into "Posts" set.
//...
//... foreach entity feed by the data provider, try add it to the database ...
//...
if (InvalidPosts.Count > 0)
{
var ifkeys = (from d in InvalidPosts
where (d.OpStatus & (int)EntityOpStatus.InvalideForeignKey) > 0
select d).ToArray();
// remove all invalid posts that have invalid foreign key
foreach (var e in ifkeys)
InvalidPosts.Remove(e);
l.Clear();
//
// Load all invalid posts that have invalid foreign key and try to add them to the database
// for the second time. Of course, the ones with true invalid keys will be rejected and added
// to InvalidPosts again.
//
foreach (var e in ifkeys)
{
l.Add((e as PostUpdateResult).UpdatedItem);
if (l.Count == DataBlockSize)
{
if (HandlePostBlock(svc, set, l, totalKnown, ref add_perc, ref added))
ProcessedPosts = added;
l.Clear();
}
}
if (l.Count > 0)
{
if (HandlePostBlock(svc, set, l, totalKnown, ref add_perc, ref added))
ProcessedPosts = added;
}
// ...
// ... codes used to update progress
// ...
}
else
{
//...
//... codes used to update progress
//...
}
// Post processor provided by the data provider
if (PostPostProcessor != null && !PostPostProcessDone)
{
PostPostProcessor(cntx, svc, PostKeyMap);
PostPostProcessDone = true;
}
#endregion
以下是 Post 实体的处理程序
private bool HandlePostBlock(PostServiceProxy svc, PostSet set, List<Post> l,
bool totalKnown, ref double add_perc, ref Int64 added)
{
// update the ParentId foreign key
for (int i = 0; i < l.Count; i++)
{
if (l[i].ParentId != null)
{
int newkey;
if (PostKeyMap.TryGetValue(l[i].ParentId.Value, out newkey))
l[i].ParentId = newkey;
}
}
// update the LastEditorUserId foreign key
for (int i = 0; i < l.Count; i++)
{
if (l[i].LastEditorUserId != null)
{
int newkey;
if (UserKeyMap.TryGetValue(l[i].LastEditorUserId.Value, out newkey))
l[i].LastEditorUserId = newkey;
}
}
// update the OwnerUserId foreign key
for (int i = 0; i < l.Count; i++)
{
if (l[i].OwnerUserId != null)
{
int newkey;
if (UserKeyMap.TryGetValue(l[i].OwnerUserId.Value, out newkey))
l[i].OwnerUserId = newkey;
}
}
int iptr = 0;
int cnt = l.Count;
for (int i = 0; i < cnt; i++)
{
// check to see whether or not the entity is already in the the database
// according to intrinsic ids: PostTypeId, OwnerUserId, Title and CreationDate
var r = svc.LoadEntityByNature(cntx, l[iptr].PostTypeId, l[iptr].OwnerUserId,
l[iptr]. Title, l[iptr].CreationDate);
if (r != null && r.Count > 0)
{
// yes, remove it from the entity list to be added
PostKeyMap.Add(l[iptr].Id, r[0].Id);
l.RemoveAt(iptr);
added++;
//...
//... codes used to update progress
//...
}
else
iptr++;
}
if (l.Count == 0)
return true;
for (int i = 0; i < l.Count; i++)
l[i].UpdateIndex = i;
// add the list of entities to the database
var rs = svc.AddOrUpdateEntities(cntx, set, l.ToArray());
if (rs != null && rs.ChangedEntities != null)
{
// check each entity's status and handle it
foreach (var r in rs.ChangedEntities)
{
if ((r.OpStatus & (int)EntityOpStatus.Added) != 0 ||
(r.OpStatus & (int)EntityOpStatus.Updated) != 0 ||
(r.OpStatus & (int)EntityOpStatus.NoOperation) != 0 ||
(r.OpStatus & (int)EntityOpStatus.NewPrimaryKey) != 0 ||
(r.OpStatus & (int)EntityOpStatus.NewForeignKey) != 0)
{
if ((r.OpStatus & (int)EntityOpStatus.NewPrimaryKey) != 0)
{
var olditem = l[r.UpdatedItem.UpdateIndex];
PostKeyMap[olditem.Id] = r.UpdatedItem.Id;
}
added++;
}
else
InvalidPosts.Add(r);
}
}
else
return false;
if (PostEntities.HasValue)
{
//...
//... codes used to update progress
//...
}
return true;
}
请注意,数据服务的默认行为是在尝试添加无效实体时抛出异常。在执行批处理时,这种行为是不可取的。CallContext 类型的 cntx 参数有一个名为 IgnoreInvalidItems 的属性,当设置为 true(参见 Init 方法)时,它将阻止服务在输入无效实体时抛出异常,而是将更新状态记录在更新结果的 OpStatus 位标志中,其类型命名模式为
<实体名称> + "UpdateResult"
其中 <实体名称> 再次是正在考虑的实体的名称。
其他实现细节可以在代码中找到,并且已进行文档说明。
数据提供程序
数据提供程序应实现预定义接口。
数据提供程序接口
数据提供程序应在程序集 StackExchangeShared 中实现接口 IStackExchangeImportProvider。该接口的文档可以在 此处 找到。
DataSourceParams 属性是一个数据结构,用于指定数据源,在当前情况下是 xml 文件。因此,此属性被分配一个字符串值,表示可以找到 xml 文件的目录。
UpdateEntityCount 属性是一个回调,用于更新特定集合的实体计数。那些没有项计数的数据集将不会发送进度数据。
每个实体集的实体枚举器通过调用按以下模式命名的函数返回
"Get" + <实体名称> + "s"
其中 <entity name> 是相应集合中实体的名称,例如 GetPosts()。
由于 Post 集是自依赖的,因此有一个后处理委托 PostPostProcessor,实现者可以设置它来执行上面提到的后处理。
数据提供程序的实现
PostType、PostHistoryType 和 VoteType 实体集具有预定义的值和主键,这些值应从 此处 获取,因为 readme.txt 中定义的值与 xml 文件中的实际数据不一致。它们是硬编码的,例如
public IEnumerable<PostType> GetPostTypes()
{
List<PostType> DataList = new List<PostType>();
DataList.Add(new PostType { IsPersisted = true, Id = 1, Name = "Question" });
DataList.Add(new PostType { IsPersisted = true, Id = 2, Name = "Answer" });
DataList.Add(new PostType { IsPersisted = true, Id = 3, Name = "Wik" });
DataList.Add(new PostType { IsPersisted = true, Id = 4, Name = "TagWikiExcerpt" });
DataList.Add(new PostType { IsPersisted = true, Id = 5, Name = "TagWiki" });
DataList.Add(new PostType { IsPersisted = true, Id = 6, Name = "ModeratorNomination" });
DataList.Add(new PostType { IsPersisted = true, Id = 7, Name = "WikiPlaceholder" });
DataList.Add(new PostType { IsPersisted = true, Id = 8, Name = "PrivilegeWiki" });
if (UpdateEntityCount != null)
UpdateEntityCount(EntitySetType.PostType, DataList.Count);
return DataList;
}
Badge、Comment、PostHistory、Post、User 和 Vote 实体是使用快速只进读取器 XmlReader 从相应的 xml 文件中读取的。例如,对于 Post 实体
public IEnumerable<Post> GetPosts()
{
char cps = System.IO.Path.DirectorySeparatorChar;
System.IO.Stream strm;
string fname = dataPath + cps + "Posts.xml";
if (System.IO.File.Exists(fname))
{
strm = new System.IO.FileStream(fname, System.IO.FileMode.Open,
System.IO.FileAccess.Read);
if (UpdateEntityCount != null)
UpdateEntityCount(EntitySetType.Post, GetRowCount(strm));
XmlReaderSettings xrs = new XmlReaderSettings();
xrs.IgnoreWhitespace = true;
xrs.CloseInput = false;
XmlReader xr = XmlReader.Create(strm, xrs);
xr.MoveToContent();
if (xr.ReadToDescendant("row"))
{
do
{
var e = new Post { IsPersisted = true };
xr.MoveToAttribute("Id");
e.Id = int.Parse(xr.Value);
xr.MoveToAttribute("PostTypeId");
e.PostTypeId = byte.Parse(xr.Value);
if (xr.MoveToAttribute("LastEditorUserId"))
e.LastEditorUserId = int.Parse(xr.Value);
if (xr.MoveToAttribute("OwnerUserId"))
e.OwnerUserId = int.Parse(xr.Value);
if (xr.MoveToAttribute("ParentId"))
e.ParentId = int.Parse(xr.Value);
xr.MoveToAttribute("Body");
e.Body = xr.Value;
e.IsBodyLoaded = true;
if (xr.MoveToAttribute("AcceptedAnswerId"))
e.AcceptedAnswerId = int.Parse(xr.Value);
if (xr.MoveToAttribute("LastEditorDisplayName"))
e.LastEditorDisplayName = xr.Value;
if (xr.MoveToAttribute("OwnerDisplayName"))
e.OwnerDisplayName = xr.Value;
if (xr.MoveToAttribute("Tags"))
{
e.Tags = xr.Value;
handleTags(e.Id, e.Tags);
}
if (xr.MoveToAttribute("Title"))
e.Title = xr.Value;
xr.MoveToAttribute("CreationDate");
e.CreationDate = DateTime.Parse(xr.Value + "+00:00").ToUniversalTime();
if (xr.MoveToAttribute("AnswerCount"))
e.AnswerCount = int.Parse(xr.Value);
if (xr.MoveToAttribute("ClosedDate"))
e.ClosedDate = DateTime.Parse(xr.Value + "+00:00").ToUniversalTime();
if (xr.MoveToAttribute("CommentCount"))
e.CommentCount = int.Parse(xr.Value);
if (xr.MoveToAttribute("CommunityOwnedDate"))
e.CommunityOwnedDate = DateTime.Parse(xr.Value + "+00:00").ToUniversalTime();
if (xr.MoveToAttribute("FavoriteCount"))
e.FavoriteCount = int.Parse(xr.Value);
if (xr.MoveToAttribute("LastActivityDate"))
e.LastActivityDate = DateTime.Parse(xr.Value + "+00:00").ToUniversalTime();
if (xr.MoveToAttribute("LastEditDate"))
e.LastEditDate = DateTime.Parse(xr.Value + "+00:00").ToUniversalTime();
if (xr.MoveToAttribute("Score"))
e.Score = int.Parse(xr.Value);
if (xr.MoveToAttribute("ViewCount"))
e.ViewCount = int.Parse(xr.Value);
e.NormalizeValues();
yield return e;
} while (xr.ReadToNextSibling("row"));
}
strm.Close();
}
}
此处可能已经注意到,日期时间属性(例如 CreationDate)是使用以下方式转换的:
DateTime.Parse(xr.Value + "+00:00").ToUniversalTime()
这是因为:1) 我们的数据服务使用通用时间坐标记录时间,2) SE 的 xml 数据文件中的日期时间值不包含时区信息,我们不得不假设它们也使用通用时间坐标。
另一点需要注意的是,来自 SE 的 xml 文件没有明确的 Tags 和 PostTags 文件。它们必须使用 handleTags 方法从 Post 数据中的 Tags 字段派生出来
private SortedDictionary<string, List<int>> TagMap
= new SortedDictionary<string, List<int>>();
private Dictionary<int, List<int>> PostTag
= new Dictionary<int, List<int>>();
private void handleTags(int id, string tagstr)
{
if (string.IsNullOrEmpty(tagstr))
return;
int ipos = tagstr.IndexOf("<");
if (ipos == -1)
return;
tagstr = tagstr.Substring(ipos + 1);
ipos = tagstr.IndexOf(">");
Action<string> addtag = tag =>
{
List<int> l;
if (!TagMap.TryGetValue(tag, out l))
{
l = new List<int>();
TagMap.Add(tag, l);
}
l.Add(id);
};
while (ipos != -1)
{
string tag = tagstr.Substring(0, ipos).TrimStart('<');
addtag(tag);
tagstr = tagstr.Substring(ipos + 1);
ipos = tagstr.IndexOf("<");
if (ipos == -1)
break;
tagstr = tagstr.Substring(ipos + 1);
ipos = tagstr.IndexOf('>');
}
if (!string.IsNullOrEmpty(tagstr))
{
addtag(tagstr.Trim("<>".ToCharArray()));
}
}
其中标签和帖子标签关联分别记录在 TagMap 和 PostTag 中。
最后,我们必须对帖子的 AcceptedAnswerId 属性进行后处理,以将其映射到相应的新帖子 ID
private void PostPostProc(CallContext cntx, IPostService2 svc,
Dictionary<int, int> map)
{
QueryExpresion qexpr = new QueryExpresion();
qexpr.OrderTks = new List<QToken>(new QToken[] {
new QToken { TkName = "Id" },
new QToken { TkName = "asc" }
});
qexpr.FilterTks = new List<QToken>(new QToken[] {
new QToken { TkName = "AcceptedAnswerId" },
new QToken { TkName = "is not null" }
});
PostSet set = new PostSet();
set.PageSize_ = 50;
set.PageBlockSize = 20;
PostPage prev_page = null;
PostPageBlock curr_pages = svc.NextPageBlock(cntx, set, qexpr, null);
List<Post> l = new List<Post>();
while (true)
{
for (int i = 0; i < curr_pages.Pages.Length; i++)
{
PostPage page = curr_pages.Pages[i];
if (i == 0 && page.LastItem == null)
continue;
page.Items = svc.GetPageItems(cntx, set, qexpr,
prev_page == null ? null :
prev_page.Items[prev_page.Items.Count - 1]
).ToList();
foreach (var e in page.Items)
{
int newid;
if (map.TryGetValue(e.AcceptedAnswerId.Value, out newid))
{
e.AcceptedAnswerId = newid;
e.IsAcceptedAnswerIdModified = true;
e.IsEntityChanged = true;
l.Add(e);
if (l.Count == 50)
{
svc.AddOrUpdateEntities(cntx, set, l.ToArray());
l.Clear();
}
}
}
prev_page = page;
}
if (curr_pages.IsLastBlock)
break;
curr_pages = svc.NextPageBlock(cntx, set, qexpr,
prev_page.Items[prev_page.Items.Count - 1]);
if (curr_pages == null || curr_pages.Pages.Length == 0)
break;
}
if (l.Count > 0)
svc.AddOrUpdateEntities(cntx, set, l.ToArray());
}
它的作用是枚举所有 AcceptedAnswerId 不为空的帖子,更新从 map 参数获取的值,并将修改后的帖子发送回数据库进行更新。由于数据库的服务性质,实体以数据块(页面)的形式从数据库中检索,并且更新也以块的形式进行。
用户界面
用户界面采用 WPF 的 ModernUI 风格,使用标准 MVVM 设计模式。它是多语言的。它假设有一个数据源和多个目标数据库。但是,如果存在多个数据库,则在导入之前只应启用一个数据库进行导入。
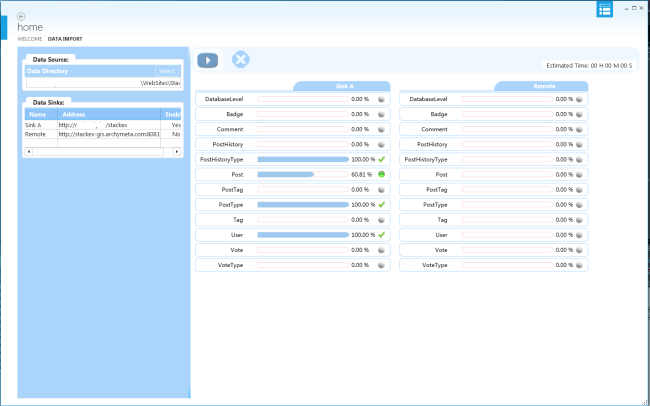
尽管它具有出色的进度报告功能,但由于篇幅限制,本文不再详细讨论。读者可以阅读随附的代码,找到其感兴趣的部分。
与数据导入直接相关的部分位于 DataImportPage 类中,在绑定到启动按钮的 OnImportData 方法中
private void OnImportData(object sender, RoutedEventArgs e)
{
if (IsProcessing)
return;
bool loadstates = false;
string statepath = AppContext.AppDataPath + AppContext.DefaultStateFile;
if (System.IO.File.Exists(statepath))
{
var dr = MessageBox.Show(
Properties.Resources.PreviousStoppedImportWarning,
Properties.Resources.WarningWord, MessageBoxButton.YesNoCancel);
switch (dr)
{
case MessageBoxResult.Cancel:
return;
case MessageBoxResult.Yes:
loadstates = true;
break;
}
}
IsProcessing = true;
this.Cursor = Cursors.Wait;
ImportContext.Current.SetupSyncProc();
var t = Task.Factory.StartNew(() =>
{
ImportContext.Current.ProcessingStopped = false;
if (loadstates)
ImportContext.Current.Importer.LoadState(statepath);
ImportContext.Current.Importer.StartProcess();
if (!ImportContext.Current.ProcessingStopped)
{
ImportContext.Current.SetupSyncProc2();
ImportContext.Current.Importer.StartProcess();
}
}).ContinueWith(task =>
{
Dispatcher.Invoke((Action)(() =>
{
ImportContext.Current.ShutdownSyncProc();
this.Cursor = Cursors.Arrow;
IsProcessing = false;
}), null);
});
}
由于在所有帖子处理之前标签和帖子标签关联未知,因此导入分两个阶段进行
第一阶段:它从不包含
Tag和PostTag实体集的数据中导入。第一阶段通过调用ImportContext类的SetupSyncProc方法设置。public void SetupSyncProc() { if ((from d in CommitedSinks where d.IsEnabled select d).Count() > 1) { MessageBox.Show(Properties.Resources.SelectOneSinkInfo, Properties.Resources.WarningWord); return; } ProcessingStopped = false; var s = (from d in CommitedSinks where d.IsEnabled select d).SingleOrDefault(); if (s != null) { char schar = System.IO.Path.DirectorySeparatorChar; DataProvider.DataSourceParams = Source.ImportFileDir.TrimEnd(schar); DataProvider.UpdateEntityCount = EntityCountUpdate; Importer.PostPostProcessor = DataProvider.PostPostProcessor; Importer.ProcessingStoppedHandler = StoppedHandler; Importer.PostTypeEnum = DataProvider.GetPostTypes(); Importer.VoteTypeEnum = DataProvider.GetVoteTypes(); Importer.PostHistoryTypeEnum = DataProvider.GetPostHistoryTypes(); Importer.UserEnum = DataProvider.GetUsers(); Importer.PostEnum = DataProvider.GetPosts(); Importer.BadgeEnum = DataProvider.GetBadges(); Importer.TagEnum = null; Importer.CommentEnum = DataProvider.GetComments(); Importer.PostHistoryEnum = DataProvider.GetPostHistorys(); Importer.VoteEnum = DataProvider.GetVotes(); Importer.PostTagEnum = null; Importer.ErrorHandler = handleError; s.DelProcStateChanged = s.OnProcStateChanged; Importer.EnumStateChanged += s.DelProcStateChanged; s.DelProcProgressing = s.OnProcProgressing; Importer.EnumProgress += s.DelProcProgressing; Importer.EnumProgress += new Action<EnumProgressEvent>(SourceWalker_EnumProgress); s.DelImporterUpdateIncomplete = s.OnImporterUpdateIncomplete; Importer.UpdateIncomplete += s.DelImporterUpdateIncomplete; Importer.Init(s.ServiceAddress, null); } }其中
TagEnum和PostTagEnum设置为 null,以避免在此阶段更新相应的数据集。第二阶段:它导入从相应的 xml 节点构建的
Post实体中检索到的Tag和PostTag实体。第二阶段通过调用ImportContext类的SetupSyncProc2方法设置。public void SetupSyncProc2() { if (ProcessingStopped) return; var s = (from d in CommitedSinks where d.IsEnabled select d).SingleOrDefault(); if (s != null) { Importer.PostTypeEnum = null; Importer.VoteTypeEnum = null; Importer.PostHistoryTypeEnum = null; Importer.UserEnum = null; Importer.PostEnum = null; Importer.BadgeEnum = null; Importer.TagEnum = DataProvider.GetTags(); Importer.CommentEnum = null; Importer.PostHistoryEnum = null; Importer.VoteEnum = null; Importer.PostTagEnum = DataProvider.GetPostTags(); } }其中除了
TagEnum和PostTagEnum之外的所有其他“枚举”都设置为 null。
插件架构
使用像 MEF 这样的插件框架来提供数据提供程序是可取的,因为它在编译后是必需的。然而,尽管架构存在,但当前版本的导入器为了简单起见,在代码中设置了提供程序,部分原因是目前只有一种 SE 数据转储。它将在以后的版本中升级为真正的可插拔。
设置测试环境
演示数据服务
将成员数据服务包中的文件解压到一个文件夹中,为其配置一个网站(这是一个 ASP.NET MVC 5 Web 应用程序)。在您的系统中启用 WCF 的 HTTP 激活。基本上就是这样。
随附的示例数据是随机选择的,因为它足够小,可以在 CodeProject 下载。如果读者对开发 SE 移动应用程序感兴趣,其中的内容可能会非常有用,因为它来自 stackapps.com。它可以作为此处讨论的导入测试的数据源,也可以作为直接加载到数据库中以研究数据本身的现有数据。
该服务由自定义构建的内存数据库支持,可以直接加载 SE xml 数据文件,无需任何导入手段。数据直接插入到内部数据结构中,不进行任何数据完整性检查。感兴趣的用户可以使用它加载其他 SE 数据集进行查询。但是,当数据量很大(例如 > 200 k)时,尤其是在需要数据连接时,它的性能不会很好,因为它目前不使用任何索引技术来加速搜索。
该服务支持 统一全文索引 搜索。以下是为 stackapps.com 数据(直接加载而非导入,因为导入会更改主键)预构建的索引包:
请将压缩包根目录中的文件解压到服务站点的根目录中。注意:它仅适用于直接加载的 stackapps.com 数据。
要从 SE 的其他站点加载数据,如果已加载,请重置服务并将数据转储到目录中
App_Data\StackExchange\Data
并从“数据源”页面中加载它。
要重置服务,只需更改根 Web.config 文件,然后将其更改回来并保存文件即可。这样会清除内存中加载的数据。
使用导入器
尽管我们为 SE 定制的内存数据库可以直接(且速度非常快地)加载 XML 数据,但对于其他类型的数据库引擎来说,这并不容易。后一种情况正是通用导入器应该使用的场景。
在开始导入过程之前,需要为选定的 SE 数据转储文件指定一个源数据目录,并为目标数据服务(针对 SE)指定一个目标基本 URL 列表。当目标数据服务的数量大于一个时,在继续之前只启用其中一个。
注意:如果您正在使用自定义内存数据库并且它已加载,请在导入之前使用上述方法重置数据服务。
摘要
为自定义构建的 SE 数据服务编写数据提供程序并不难,因为大部分复杂逻辑已由数据服务本身处理。
历史
- 版本 1:初始发布。
- 版本 1.0.1:由于服务 JavaScript 中的错误,添加或更新项目时的不正确行为已得到纠正。添加了更多视图。只更改了服务包。
- 版本 1.0.2:整体系统更新、错误修复和功能增强。
- 版本 1.2.0:导入器和数据服务现在在 .Net 4.5.1 下运行,并且在 Asp.Net Mvc 5 下运行。