
Web Scraping(问题与解决方案)
通过本文,您将能够对网页抓取有一个基本的了解,并了解一些在工作中遇到的问题及其解决方案。
引言
网页抓取被认为是抓取不同网络源数据的最有效和程序化的方法。基本上,网页抓取是在网页上进行的。这是一种从其他网页收集必要信息到个人数据库的简单技术。
需要考虑的因素
- HTML结构。
- 正确的标签。
1. HTML结构:
我们网页抓取要考虑的第一个因素是HTML结构。抓取需要我们的内容HTML是结构化的。没有结构化的HTML代码,抓取将非常混乱,因为耗时且危险。如果内容结构良好,那么它将是收集数据的绝佳方式。
2. 正确的标签
内容HTML标签需要正确格式化。它需要ID或类。如果内容HTML只有内联HTML,那么它将是一团糟。它需要一个标识来获取数据。正确的方式是放置一个我们可以使用的ID或类名。如果内容HTML具有此功能,那么抓取将是一个好主意。
网页抓取用途
- 在线价格比较
- 联系人抓取
- 天气数据监控
- 网站变更检测
- 研究
- Web Mashup
- Web数据集成
- 电话号码收集
- 地址收集
- 国家/城市/州名称收集。
在本文中,我将讨论一些使用HtmlAgilityPack进行网页抓取的有用技术。HTML Agility Pack 最令人惊讶的功能是它现在支持LINQ。这意味着您可以使用普通的Linq查询来获得结果。如果您需要有关HTML Agility Pack 的更多信息,可以访问其在CodePlex上的文档。
好了,我们现在开始吧。
问题陈述-1
假设我们有以下HTML代码。从带下划线的HTML中,我们只想提取与锚标记相关的链接。

解决方案-1
步骤1:处理原始内容(即HTML)。加载完整的HTML源代码并将其转换为string。通过HTML Web请求和响应,我们从给定链接中获取整个HTML代码。然后使用Stream Reader读取所有内容直到末尾,我们得到HTML源代码的字符串格式。以下是上述过程的代码。
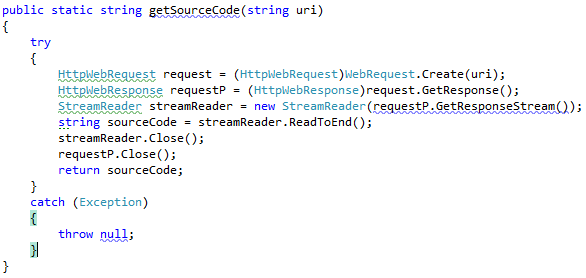
步骤2:返回转换后的string并再次转换为HTML文档类型。


在上面的代码中,我们在WorkerClass类中有一个getSourceCode()方法。此方法加载提供的完整HTML,然后将完整的HTML作为字符串返回。返回的string随后被转换为HtmlDocument并返回。上面的图像显示我们已经准备好了HTML文档。现在我们的内容可以执行LINQ查询以获取我们期望的结果。

这里的primaryDivId是一个布尔变量,如果找到任何ID为divAchors的div,它将为true。这里的anchorsHref保存锚链接的集合,anchorsInnerText保存锚内部文本的集合。
问题陈述-2
假设我们需要下载图像。HTML格式可能如下

解决方案-2
要下载所有图像并获取它们的替代信息文本,我们需要执行以下操作:

SelectNodes上的以下//img标签表示具有ID divImage的div可能包含img标签。如果它在dev的范围内找到任何图像标签,它将获取其源和替代信息文本。我在这里需要提到的是,无论图像标签位于何处,无论图像标签是否嵌套在几个div级别中,此查询都将全部获取。

从上面的代码中,我们将能够在imageSrc列表中获得图像源链接的集合,并在imageInnerText列表中获得它们的alt文本。使用foreach循环,我们可以将图像下载并保存到我们期望的文件夹中。
问题陈述-3
假设我们需要查找具有类名的div的内部文本。此问题的HTML可能如下

解决方案-3
这是此问题陈述的解决方案

innerText string将为您提供一个完整的、未剪辑的string,而innerTextList将为您提供一个内部文本集合的列表。
问题陈述-4
假设我们遇到与上面类似的问题,但有一个细微的改变。改变在于类名在两个类之间切换。我不确定页面渲染时可能存在哪个类名。此问题陈述的HTML可能如下


这里的类名在demoText1和demoText2之间切换。
解决方案-4
这是上述问题陈述的解决方案

解决方案与解决方案-3类似,但查询中有一个额外的或(|)条件。如果您需要,也可以使用和(&)条件。
以上是我工作中遇到的最近一些问题,我通过这种方式解决了它们。我认为这些解决方案将帮助您解决您的问题,因为它涵盖了许多与网页抓取相关的内容。如果您遇到更多问题,请告诉我,我会尽力解决。感谢您的阅读。编码愉快。:)